溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python如何爬取網易云音樂,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
代碼如下:
import os
from lxml import etree
import requests
# 設置頭部信息,防止被檢測出是爬蟲
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
url = "https://music.163.com/discover/toplist?id=3778678"
base_url = 'http://music.163.com/song/media/outer/url?id='
# 新建一個字典用于存儲最終所需要的數據
d = dict()
re = requests.get(url=url, headers=headers).text
# 構造了一個XPath解析對象并對HTML文本進行自動修正
html = etree.HTML(re)
# XPath使用路徑表達式來選取
x = html.xpath('//a[contains(@href,"/song?")]')
# 對取到的數據進行篩選
for data in x:
# 獲取到音樂url
href = data.xpath('./@href')[0]
id = href.split("=")[1]
href = base_url + "%s.mp3">效果如下:
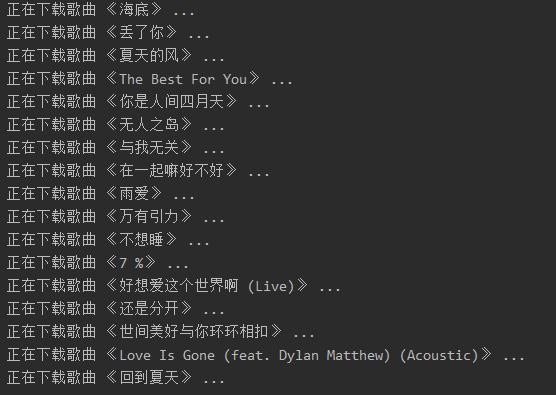
以上是“Python如何爬取網易云音樂”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





