溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“什么是RTMP協議”,在日常操作中,相信很多人在什么是RTMP協議問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”什么是RTMP協議”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
實時消息傳輸協議(Real-Time Messaging Protocol)是目前直播的主要協議,是Adobe公司為Flash播放器和服務器之間提供音視頻數據傳輸服務而設計的應用層私有協議。RTMP協議是目前各大云廠商直線直播業務所公用的基本直播推拉流協議,隨著國內直播行業的發展和5G時代的到來,對RTMP協議有基本的了解,也是我們程序員必須要掌握的基本技能。
本文主要闡述RTMP的基本思想和核心概念,并且輔之以livego的源碼分析,和大家一起深入學習RTMP協議最核心的知識點。
RTMP協議主要的特點有:多路復用,分包和應用層協議。以下將對這些特點進行詳細的描述。
多路復用(multiplex)指的是信號發送端通過一個信道同時傳輸多路信號,然后信號接收端將一個信道中傳遞過來的多個信號分別組合起來,分別形成獨立完整的信號信息,以此來更加有效地使用通信線路。

簡而言之,就是在一個 TCP 連接上,將需要傳遞的Message分成一個或者多個 Chunk,同一個Message 的多個Chunk 組成 ChunkStream,在接收端,再把 ChunkStream 中一個個 Chunk 組合起來就可以還原成一個完整的 Message,這就是多路復用的基本理念。
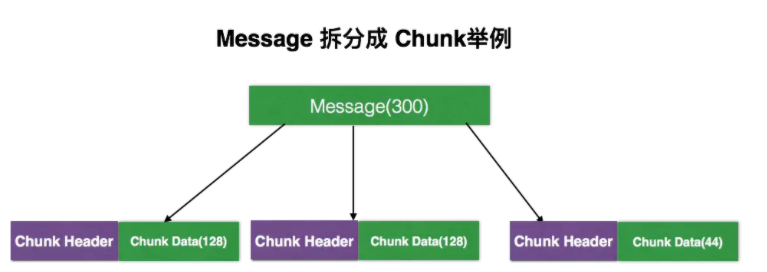
上圖是一個簡單例子,假設需要傳遞一個300字節長的Message,我們可以將其拆分成3個Chunk,每一個Chunk可以分成 Chunk Header 和 Chunk Data。在Chunk Header 里我們可以標記這個Chunk中的一些基本信息,如 Chunk Stream Id 和 Message Type;Chunk Data 就是原始信息,上圖中將 Message 分成128+128+44 =300,這樣就可以完整的傳輸這個Message了。
關于 Chunk Header 和 Chunk Data 的格式,后文會進行詳細介紹。
RTMP協議的第二個大的特性就是分包,與RTSP協議相比,分包是RTMP的一個特點。與普通的業務應用層協議(如:RPC協議)不一樣的是,在多媒體網絡傳輸案例中,絕大多數的多媒體傳輸的音頻和視頻的數據包都相對比較偏大,在TCP這種可靠的傳輸協議之上進行大的數據包傳遞,很有可能阻塞連接,導致優先級更高的信息無法傳遞,分包傳輸就是為了解決這個問題而出現的,具體的分包格式,下文會有介紹。
RTMP最后的一個特性,就是應用層協議。RTMP協議默認基于傳輸層協議TCP而實現,但是在RTMP的官方文檔中,只給定了標準的數據傳輸格式說明和一些具體的協議格式說明,并沒有具體官方的完整實現,這就催生出了很多相關的其他業內實現,例如RTMP over UDP等等相關的私有改編的協議出現,給了大家更多的可擴展的空間,方便大家解決原生RTMP存在的直播時延等問題。
作為一種應用層協議,和其他私有傳輸協議一樣(如RPC協議),RTMP也有一些具體代碼實現,如 nginx-rtmp、livego 和 srs。本文選用基于go語言實現的開源直播服務器 livego 進行源碼級的主流程分析,和大家一起深入學習 RTMP 推拉流的核心流程的實現,幫助大家對RTMP的協議有一個整體的理解。
在進行源碼分析之前,我們會通過類比RPC協議的方式,幫助大家對RTMP協議的格式有一個基本的了解,首先我們可以看一個比較簡單但實用的RPC協議格式,如下圖所示:

我們可以看到這是一個在RPC調用過程中所使用的數據傳輸格式,之所以使用這樣的格式,根本目的還是為了解決"粘包和拆包"的問題。
以下簡要描述圖中RPC協議的格式:首先用2個字節,MAGIC來表示魔數,標記該協議是對端都能識別的標識,如果接收到的2個字節不是0xbabe的話,則直接丟棄該包;第二個sign占用1個字節,低4位表示消息的類型request/response/heartbeat,高4位表示序列化類型例如json,hessian,protobuf,kyro等等;第三個 status 占用一個字節,表示狀態位;隨后使用8個字節來表示調用的requestId,一般使用低48位(2的48次方)就足夠表示requestId了;接著使用4字節定長的body size來表示Body Content,通過這樣的方式就能夠很快的解析出RPC消息Message的完整請求對象了。
通過分析上述的一個簡單的RPC協議,其實我們能夠發現一個很好的思想,就是最大效率的使用字節,即使用最小的字節數組,來傳輸最多的數據信息。小小的一個字節能夠帶來很多的信息量,畢竟一個字節它有64種不同的變化。在網絡中,如果只需要利用一個字節就能夠傳遞很多有用的信息的話,那么我們就可以使用極其有限的資源來得到最大的資源利用了。RTMP的官方文檔在2012年就出現了,雖然以目前的眼光來看,RTMP協議實現的非常復雜,甚至有些臃腫,但是它在2012年的時候,就能夠有比較先進的思想,的確是我們學習的榜樣。
在當今WebRTC協議橫行的年代里,我們也能夠從WebRTC的設計實現中,看到RTMP的影子,上述的RPC協議我們就可以認為是一個與RTMP具有相似設計理念的簡化版設計。
在分析RTMP源碼之前,我們先對RTMP協議中的幾個核心概念做具體說明,方便我們在宏觀上對RTMP整個協議棧有一個基本的了解,并且在后文源碼分析期間,我們也會通過抓包的方式,更加直觀地幫助我們去分析相關的原理。
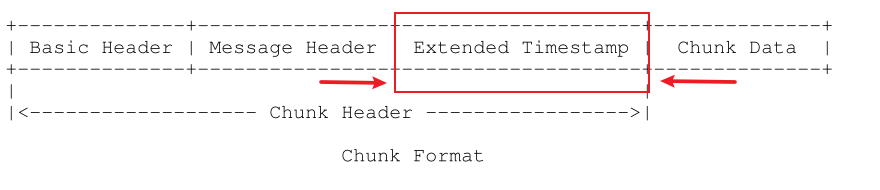
首先,和剛才的RPC協議格式一樣,RTMP實際傳輸的實體對象是Chunk,一個Chunk由Chunk Header和Chunk Body兩個部分組成,如下圖所示。

Chunk Header這個部分和我們前面說過的RPC協議不太一樣,主要是RTMP協議的Chunk Header的長度不是固定的,為什么不是固定的呢?其實還是Adobe公司為了節省數據傳輸開銷。從剛才將一個300字節的Message拆分成3個Chunk的例子中,我們可以看到多路復用其實也是有一個比較明顯的缺點,就是我們需要有一個Chunk Header來標記這個Chunk的基本信息,這樣其實就是在傳輸的時候有了額外字節流傳輸的開銷。所以為了保證傳輸的字節數最少,我們就需要不斷地壓榨著RTMP的Header的大小,確保Header的大小達到最小,這樣才能達到最高的傳輸效率。
首先我們研究一下Chunk Header中Basic Header的部分,Basic Header的長度就是不固定的,可以是1個字節,2個字節或者3個字節,這取決于Chunk Stream Id(縮寫:csid)。
RTMP協議支持的csid的范圍是2~65599,0和1是協議保留值,用戶不可使用。Basic Header至少含有1個字節(低8位),它的長度就是這1個字節決定的,如下圖所示。該字節高2位留給 fmt,fmt的取值決定了 Message Header 的格式,這個在后面會講到。該字節的低6位就是 csid 的值,當低6位的 csid 取值為0時,表示真實 csid 值大到無法用6個bit表示了,需要借助后續的一個字節才行;當低6位的 csid 取值為1時,表示真實 csid 值大到無法用14個bit表示了,需要再借助后續的一個字節才行。于是,整個Basic Header的長度看起來就不是固定的了,完全取決于首字節的低6位的csid的值。
實際應用中,并沒有使用到那么多csid,也就是說一般情況下,Basic Header長度為一個字節,csid取值范圍為 2~63。

剛才說了那么多,才僅僅說了Basic Header,而Basci Header只是Chunk Header的組成部分之一,比較喜歡折騰的RTMP協議的作者,把RTMP的Chunk Header模塊又設計成了動態大小的,簡而言之也是為了節省傳輸空間,這邊能夠方便理解的地方就是Chunk Message Header的長度也分四種情況,這就是前面提到的 fmt 這個值決定的。
Message Header 的四種格式如下圖所示:
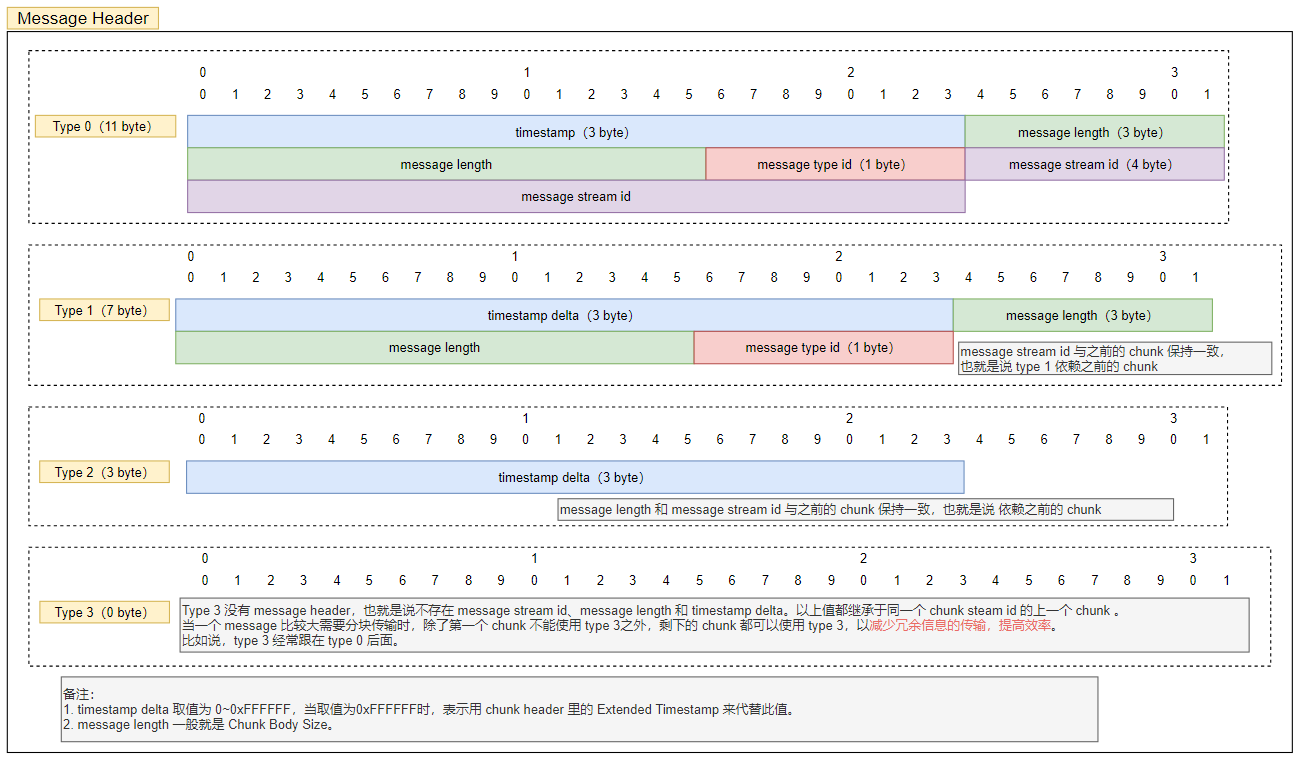
當 fmt 為 0 的時候,Message Header占用11個字節(請注意,這邊的11個字節不包括Basic Header的長度),由3個字節長度的timestamp,3個字節長度的message length,1個字節長度的message type Id,4個字節長度的message stream Id所組成的。
其中,timestamp 是絕對時間戳,表示的是這個消息發送的時間;message length 表示的是chunk body的長度;message type id 表示的是消息類型,這個在后文會具體講到;message stream id 是消息唯一標識。這邊需要注意的是,如果這個消息的絕對時間戳大于0xFFFFFF,說明這個時間大到無法用3個字節來表示,需要借助擴展時間戳(Extended Timestamp)來表示,擴展時間戳長度為4個字節,默認放在Chunk Header和Chunk Body之間。
當 fmt 為 1的時候,Message Header占用7個字節,與之前的11個字節的chunk header相比,少了一個message stream id,這個chunk是復用之前的chunk stream id,這個一般用于可變長的消息結構。
當 fmt 為 2的時候,Message Header只占用3個字節,就只包含timestamp的三個字節,與之前相比,既少了stream id也少了message length,這種少了message length的,一般用于固定長度但是需要修正時間的消息(如:音頻數據)。
當 fmt 為 3的時候,Chunk Header里就不包含 Message Header 了。一般來說,在拆包的時候,把一個完整的RTMP的Message消息,會拆成第一個是fmt 為 0的Chunk消息,隨后的消息也會拆成fmt為3的消息,這樣的做的方式就是第一個Chunk附帶著最全的Chunk消息信息,后續Chunk信息的Header就會比較小,這樣實現比較簡單,壓縮率也是比較好。當然,如果第一個Message發送成功之后,第二個Message再次發送的時候,就會把第二個Message的第一個Chunk設置成fmt為1類型的Chunk,隨后該Message的Chunk的fmt為3,這樣就能夠進行消息的區分。
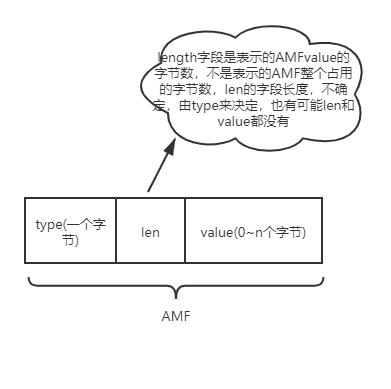
剛才花了很多時間去描述Chunk Header,接下來我們再針對Chunk Body進行簡單的描述。與Chunk Header相比,Chunk Body就比較簡單,沒有那么多變長的控制,結構也比較簡單,這個里面的數據也就是真正有業務含義的數據,長度默認是128個字節(可以通過 set chunk size 命令協商更改)。里面的數據包組織格式一般是AMF或者FLV格式的音視頻數據(不含FLV TAG頭)。AMF組織結構的數據組成如下圖所示,FLV格式本文不做深入描述,感興趣的話可以閱讀 FLV 官方文檔。
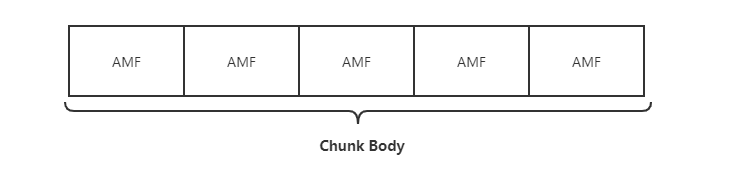
AMF(Action Message Format) 是一種類似JSON,XML的二進制數據序列化格式,Adobe Flash與遠程服務端可通過AMF格式的數據進行數據通信。
AMF具體的格式其實與Map的數據結構很相似,就是在KV鍵值對的基礎上,中間多加了一個Value值的length。AMF的結果基本如下圖所示,有時候len字段就是空,這個是由type來決定的,我們舉例來說,例如我們傳輸的是number類型的AMF格式的數據,那么len字段我們就可以忽略,因為我們默認number類型的字段占用8個字節,我們這邊就可以忽略了。
再舉例來說,AMF如果傳輸的是0x02 string類型的數據的時候,len的長度就默認占據2個字節,因為2個字節足夠表示后面value的最大長度了。以此類推,當然有些時候,len和value的值都不存在,就比如傳遞0x05 傳遞null的時候,len和value我們就都不需要了。
以下列舉一些常用的AMF的type的對應表格,更多信息可以查看官方文檔。

我們可以通過WireShark來抓包,實際來體驗一下具體的AMF0的格式。
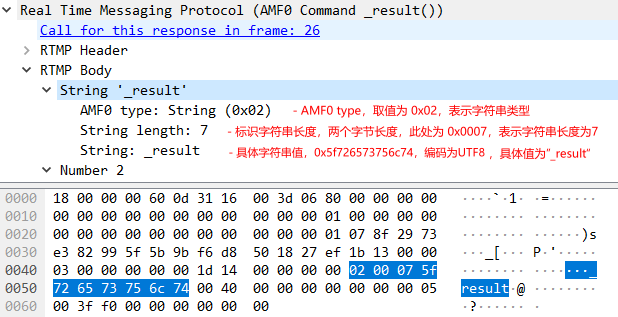
如上圖所示,這是一個非常典型的AMF0類型string結構的抓包。AMF目前有2個主要的版本,分別是AFM0和AMF3,在目前的實際使用場景中,AMF0還是占據主流的地位。那么AMF0和AMF3有什么區別呢,當客戶端給服務器端發送AMF格式Chunk Data數據的時候,服務端在接收到該信息的時候,如何是知道AMF0或者是AMF3呢?實際上RTMP在Chunk Header中使用message type id來進行區分,當消息使用AMF0編碼時,message type id等于20,使用AMF3編碼時message type id等于17。
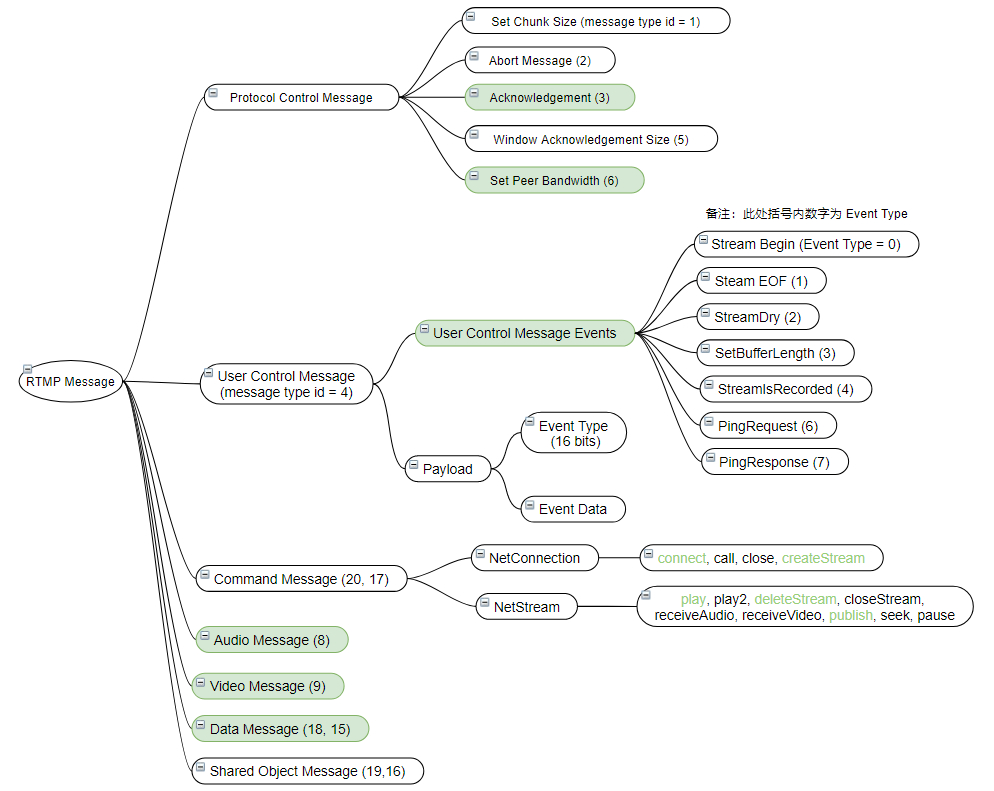
首先,用一句話來總結一下Chunk和Message的關系,一個Message是由多個Chunk組成,多個Chunk Stream id一樣的Chunk稱之為Chunk Stream,接收端可以重新合并解析為完整的Message。RTMP相比于RPC消息來說,消息類型多了很多,前文講的RPC消息類型歸根結底就request,response和heartbeat這三種類型,但是RTMP協議的消息類型就比較豐富。RTMP消息主要分為以下三大類型:協議控制消息,數據消息和命令消息。
**協議控制消息:**Message Type ID = 1~6,主要用于協議內的控制。
**數據消息:**Message Type ID = 8 9
188: Audio 音頻數據
9: Video 視頻數據1
8: Metadata 包括音視頻編碼、視頻寬高等音視頻元數據。
命令消息 Command Message (20, 17):此類型消息主要有 NetConnection 和 NetStream 兩類,兩類分別有多個函數,該消息的調用,可理解為遠程函數調用。
總覽圖如下,后續在源碼解析章節,會進行具體介紹,其中著色部分為常用消息。
網絡協議的學習是一個枯燥的過程,我們嘗試結合 RTMP協議原文和WireShark抓包的方式,盡量形象地給大家描述 RTMP 協議中的核心流程,包括握手,連接,createStream,推流和拉流。本節所有的抓包數據的基本環境是:livego作為RTMP服務器(服務端口為1935),OBS作為推流應用,VLC作為拉流應用。
作為一個應用層協議解析來說,首先,我們要注意的就是主體流程的把握,對于每一個 RTMP 服務器來說,每一個推流和拉流從代碼層面來說,都是一個網絡鏈接,針對每一個連接,我們要進行對應的工序進行處理,我們可以看到livego中源碼中所展示的一樣,有一個handleConn方法,顧名思義,就是用來處理每一個連接,按照主流程來說,分為第一部分的握手,第二個核心模塊的依據RTMP包協議,進行Chunk header和Chunk body的解析,后續再根據解析出來的Chunk header和Chunk body再做具體的處理。
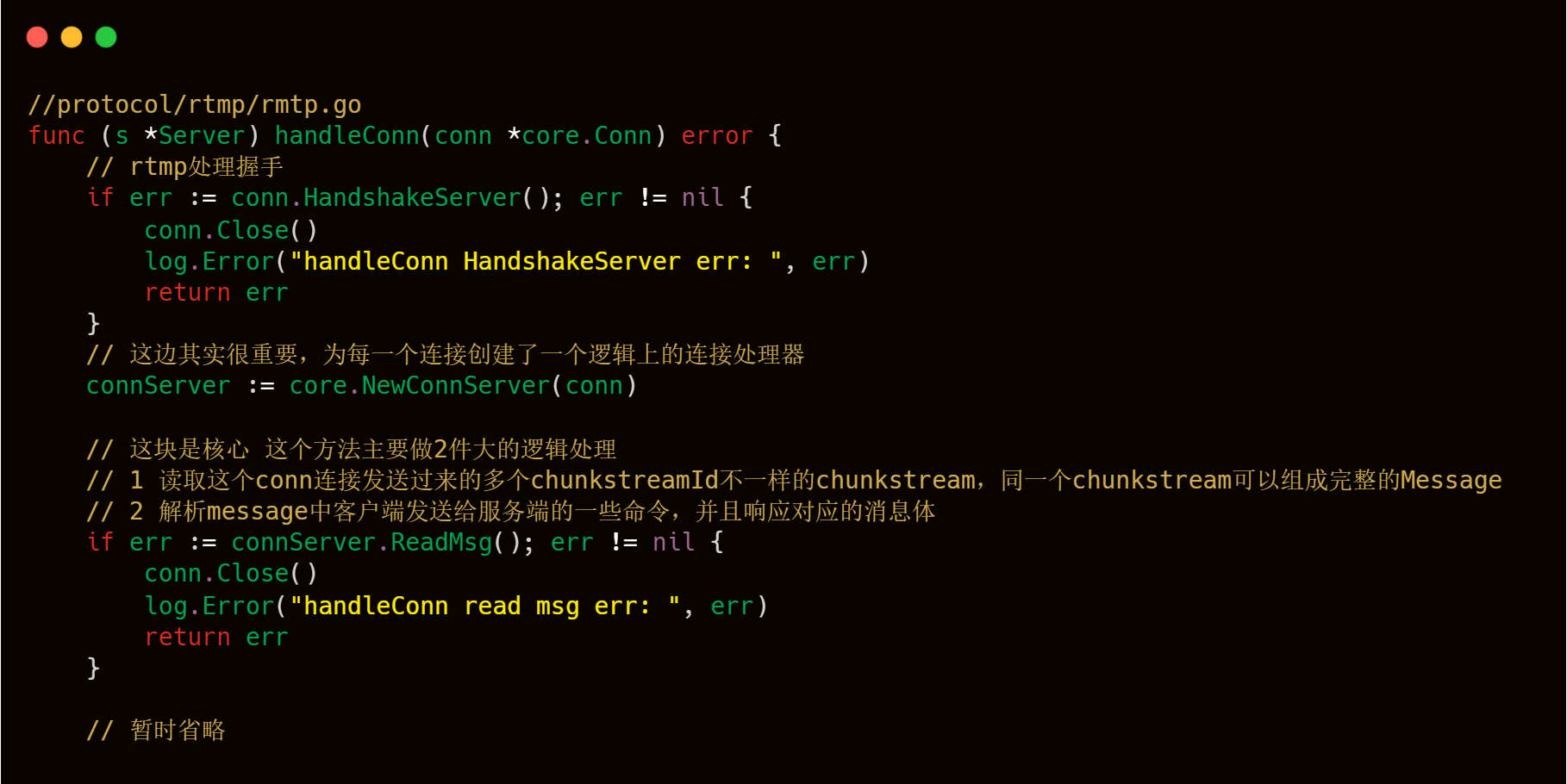
可以看到上述代碼塊,主要有2個核心方法:一個是HandshakeServer,主要處理握手邏輯;另一個是ReadMsg方法,主要處理Chunk header和Chunk body信息的讀取。
協議原文的5.2.5節詳細介紹了 RTMP 握手的過程,圖示如下:
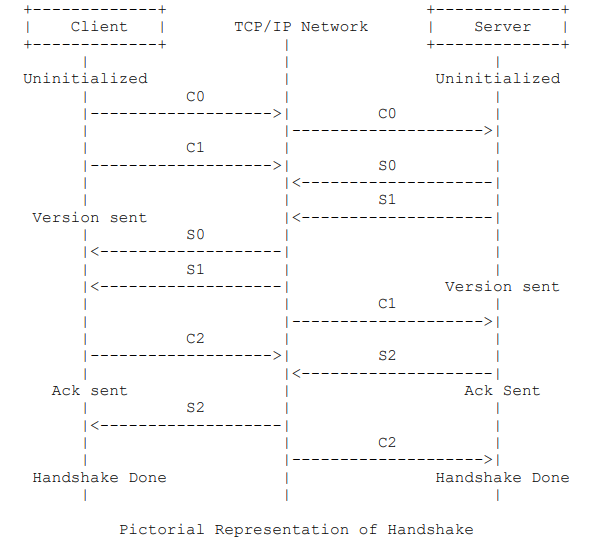
乍一看,可能會覺得此過程有些復雜。所以,我們還是先用 WireShark 抓包來整體看看過程吧。
WireShark 抓包的 Info 能夠為我們解讀 RTMP 包的含義,從下圖可以看出,握手主要涉及到3個包。其中第16號包是客戶端向服務端發送 C0 和 C1 消息,18號包是服務端向客戶端發送 S0,S1 和 S2 消息,20號包是客戶端向服務端發送 C2 消息。如此,客戶端和服務端就完成了握手過程。
通過 WireShark 抓包可以看出,握手過程還是非常簡潔的,有點類似 TCP 三次握手的過程,所以從實際抓包來說,與RTMP協議原文的5.2.5節介紹的還是有些出入的,整體流程變得很簡潔。

現在可以回頭看看上面那個比較復雜的握手流程圖了。圖中將客戶端和服務端分為四種狀態,分別是:未初始化,已發送版本號,已發送 ACK,握手完成。
未初始化:客戶端和服務端無任何交流階段;
已發送版本號:發送了 C0 或者 S0;
已發送 ACK:發送了 C2 或者 S2;
握手完成:接收到了 S2 或者 C2。
RTMP 協議規范并沒有限定死 C0,C1,C2 和 S0,S1,S2 的順序,但是制定了以下規則:
客戶端必須收到服務端發來的 S1 后才能發送 C2;
客戶端必須收到服務端發來的 S2 后才能發送其他數據;
服務端必須收到客戶端發來的 C0 后才能發送 S0 和 S1;
服務端必須收到客戶端發來的 C1 后才能發送 S2;
服務端必須收到客戶端發來的 C2 后才能發送其他數據。
從 WireShark 抓包分析可以看出,整個握手過程的確是遵循了以上規定。現在問題來了,C0,C1,C2,S0,S1 和 S2 這些消息到底是些什么玩意?其實,RTMP 協議規范里面明確定義了它們的數據格式。
C0 和 S0:1個字節長度,該消息指定了 RTMP 版本號。取值范圍 0~255,我們只需要知道 3 才是我們需要的就行。其他取值含義感興趣的話可以閱讀協議原文。
C1 和 S1:1536個字節長度,由 時間戳+零值+隨機數據 組成,握手過程的中間包。
C2 和 S2:1536個字節長度,由 時間戳+時間戳2+隨機數據回傳 組成,基本上是 C1 和 S1 的 echo 數據。一般在實現上,會令 S2 = C1,C2 = S1。
下面我們結合 livego 源碼來加強對握手過程的理解。
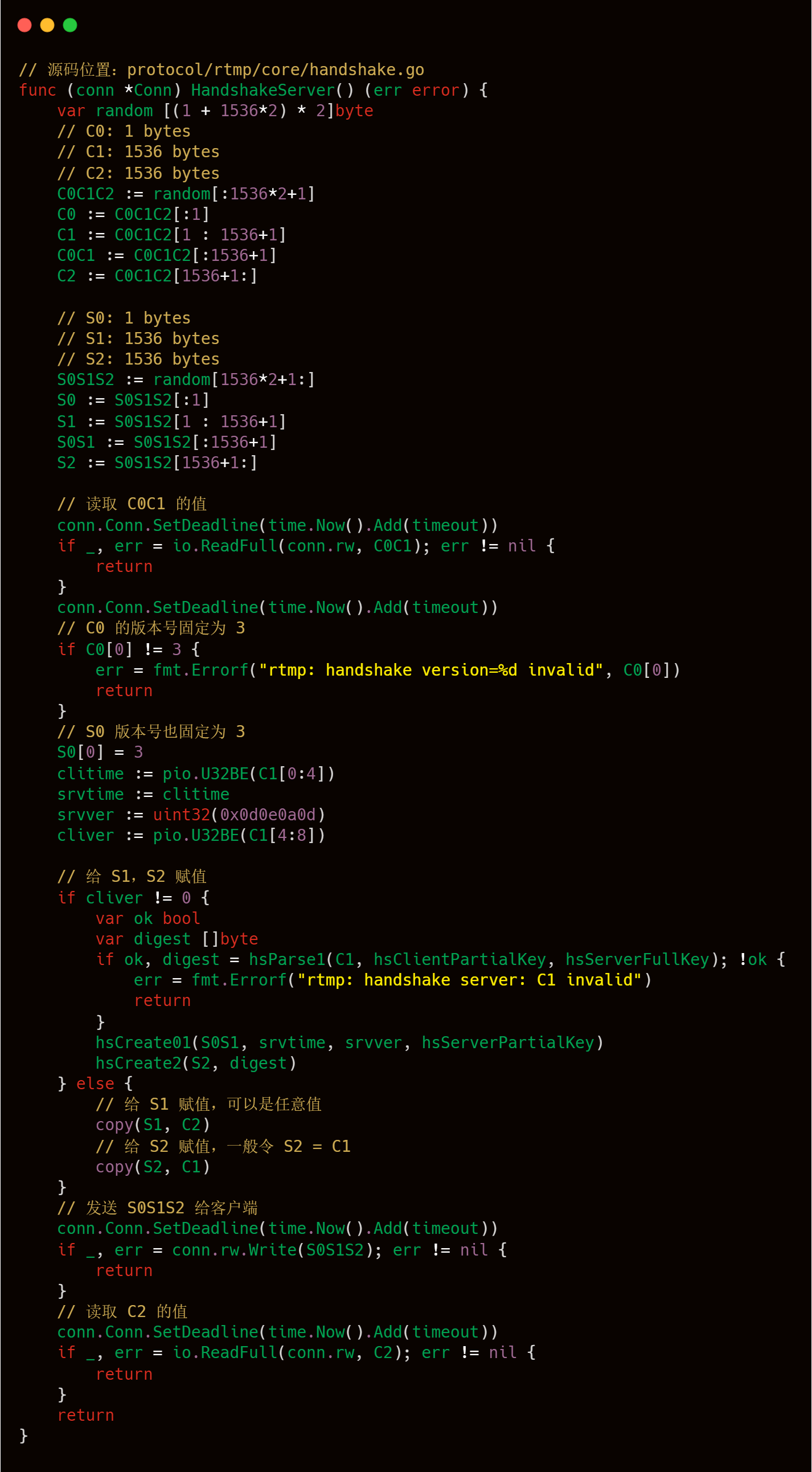
到此為止,最簡單的握手流程就到此結束了,可以看出整個握手流程還是比較清晰的,處理邏輯也是比較簡單,也比較便于理解。
3.2.2.1 解析RTMP協議的Chunk信息
握手之后,就要做開始做連接等相關的事情處理了,再做此信息處理之前,工欲善其事必先利其器。
我們先要按照RTMP協議的規范來解析Chunk Header和Chunk body了,將網絡傳輸的字節包數據轉換成我們可識別的信息處理,再根據這些可識別的信息數據,再做對應流程的處理,這塊是源碼解析的關鍵核心,涉及的知識點非常多,大家可以結合上文一起看,可以方便大家理解ReadMsg這塊核心邏輯的理解。

上述的代碼塊邏輯很清晰,主要是讀取每一個conn連接中,進行對應的編解碼,獲取到一個個Chunk,并且將相同ChunkStreamId的Chunk再次進行合并,合并成對應的Chunk Stream,最后一個個完整的Chunk Stream就是Message了。
這塊代碼就是和我們之前理論部分知識介紹的chunkstreamId那塊知識比較接近的地方了,大家可以結合起來一起看,大家在腦海中,要注意就是一個conn連接,會傳遞多個Message,例如連接Message,createStreamMessage等等,每一個Message就是Chunk Stream,也就是多個csid相同的Chunk,所以livego的作者使用map這樣的數據結構進行存儲,key就是csid,value就是chunkstream,這樣就可以將向rtmp服務器發送過來的信息能夠全部保存下來。
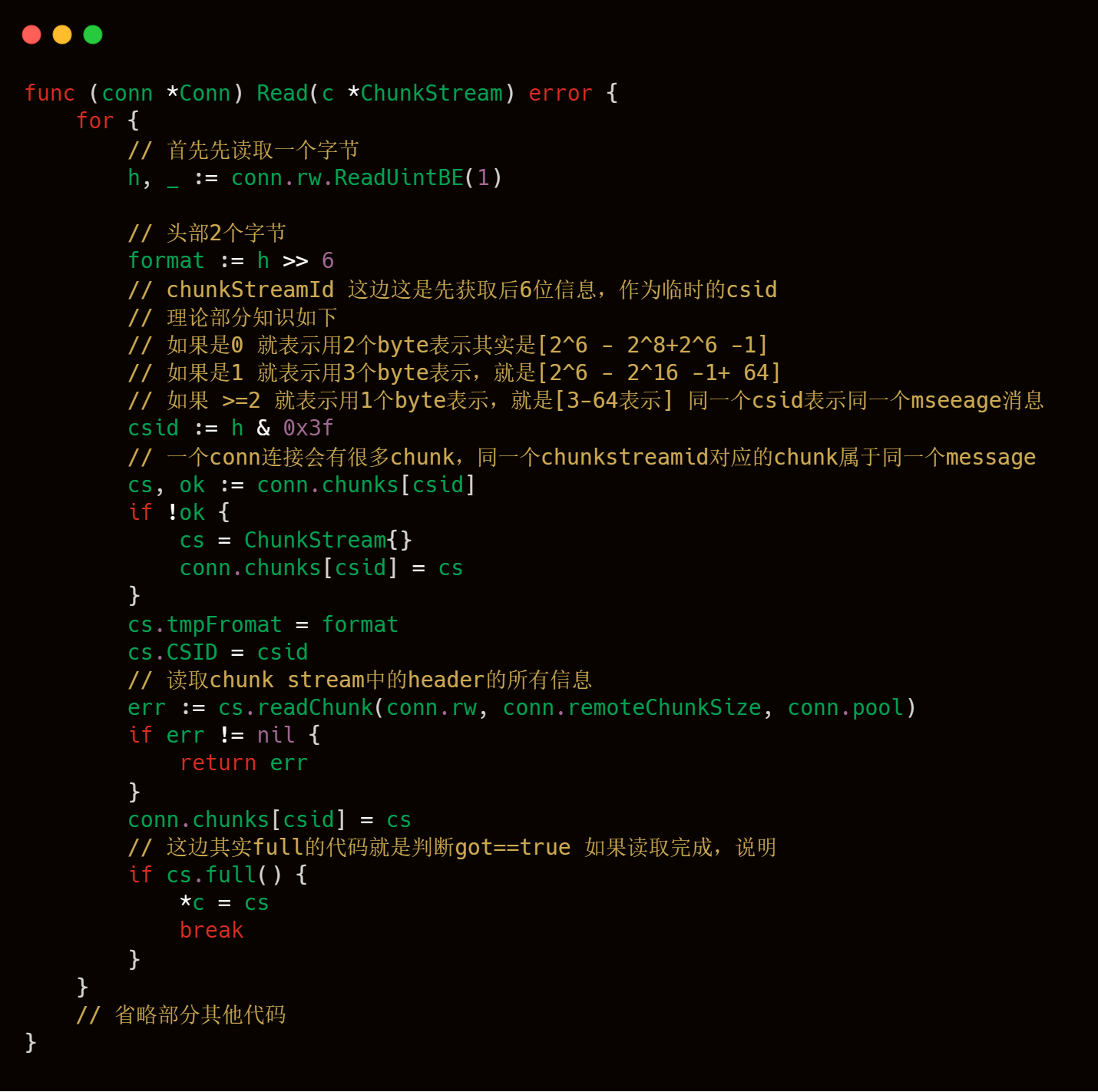
readChunk代碼的具體邏輯實現分成如下幾個部分:
1)csid的修正,至于理論部分參照上述邏輯,這塊其實是basic header的處理。
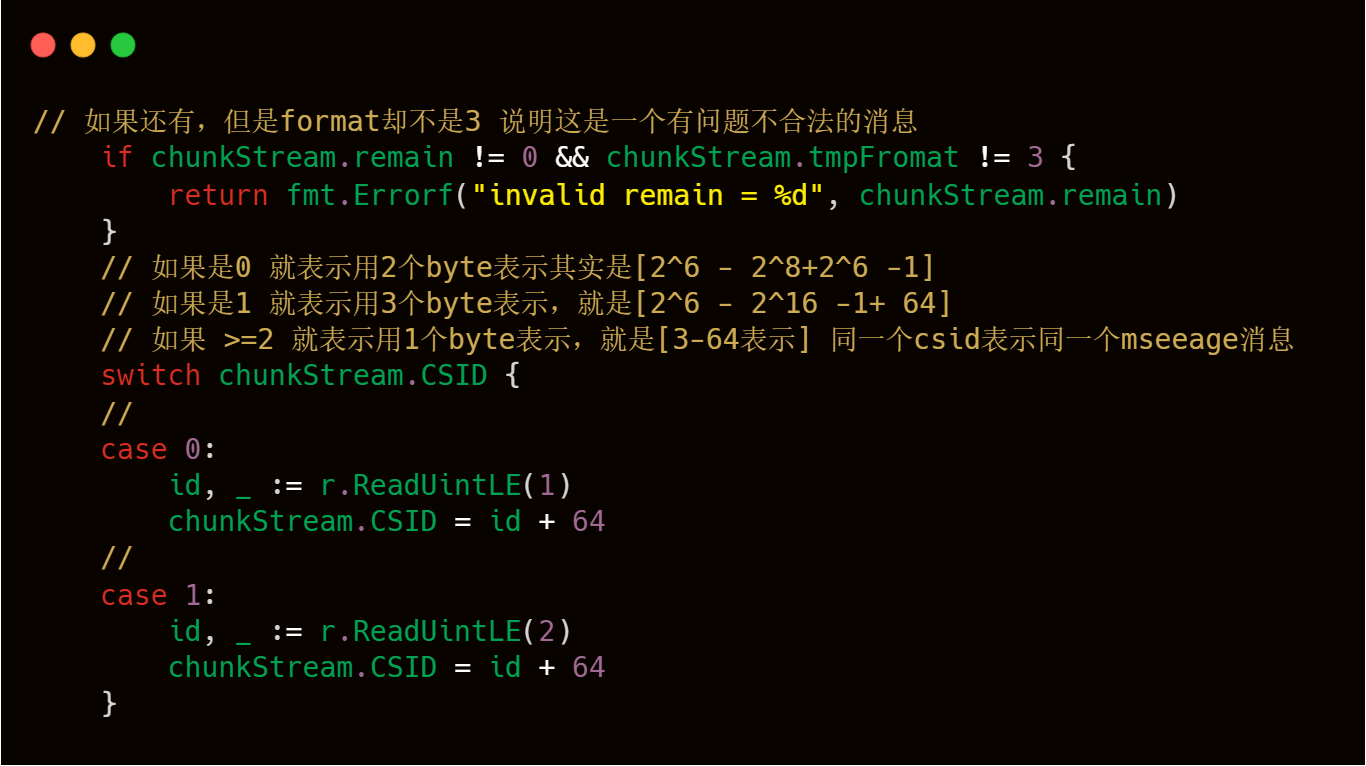
2)Chunk Header按照format的數值進行對應的解析處理,上文理論部分也已經介紹過了,下文也有具體的注釋解釋,有兩個技術點需要注意第一就是timestramp時間戳的處理,第二個注意點是chunk.new(pool)這行代碼,也是需要大家注意,代碼注釋中也寫的比較清楚。
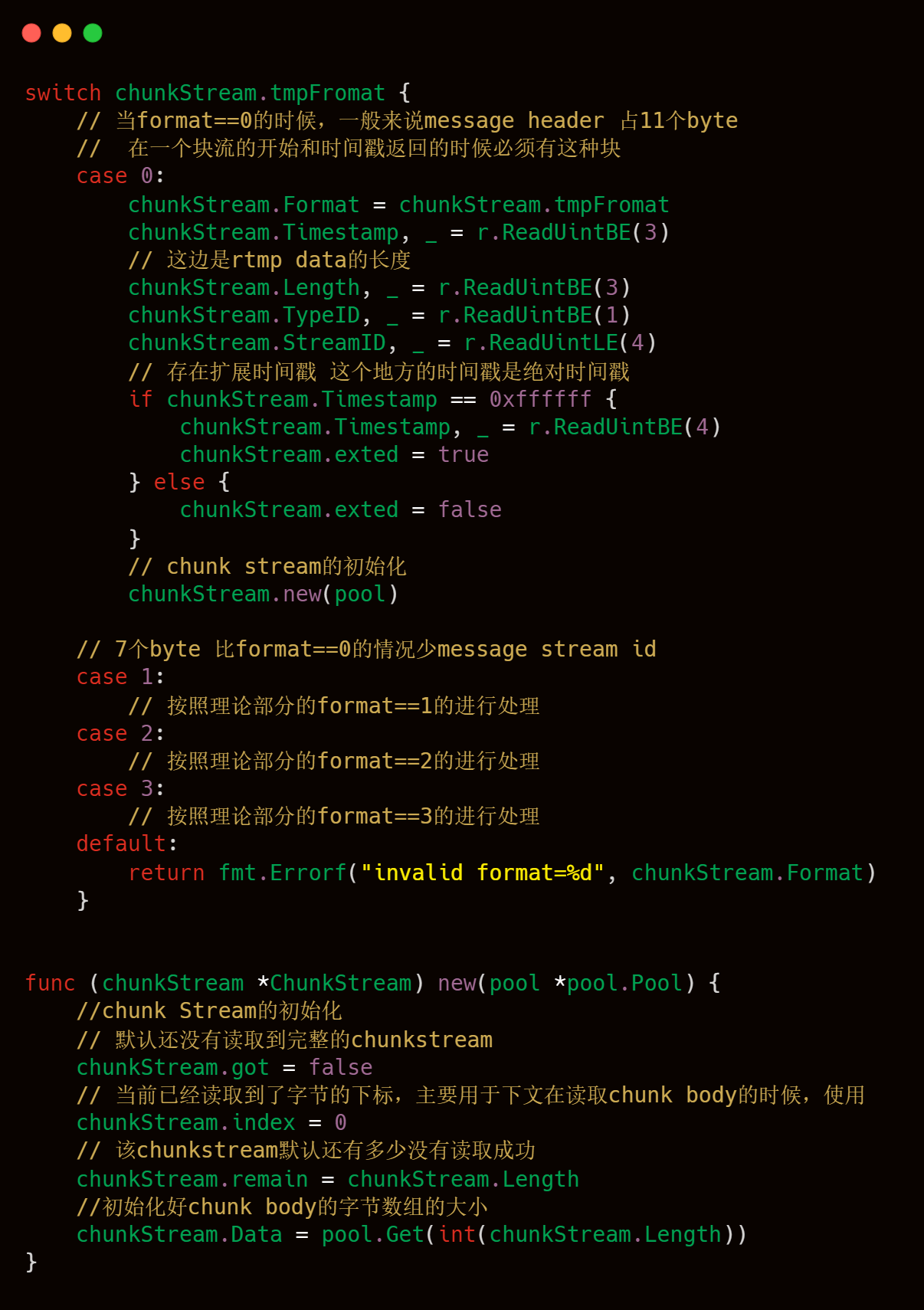
3)Chunk Body的讀取處理,上文理論部分說過,Chunk header中當fmt 為 0 的時候,會有一個message length字段,這個字段會控制Chunk Body的大小,依據這個字段,我們可以很輕松地讀取到Chunk body信息的讀取,整體邏輯如下。
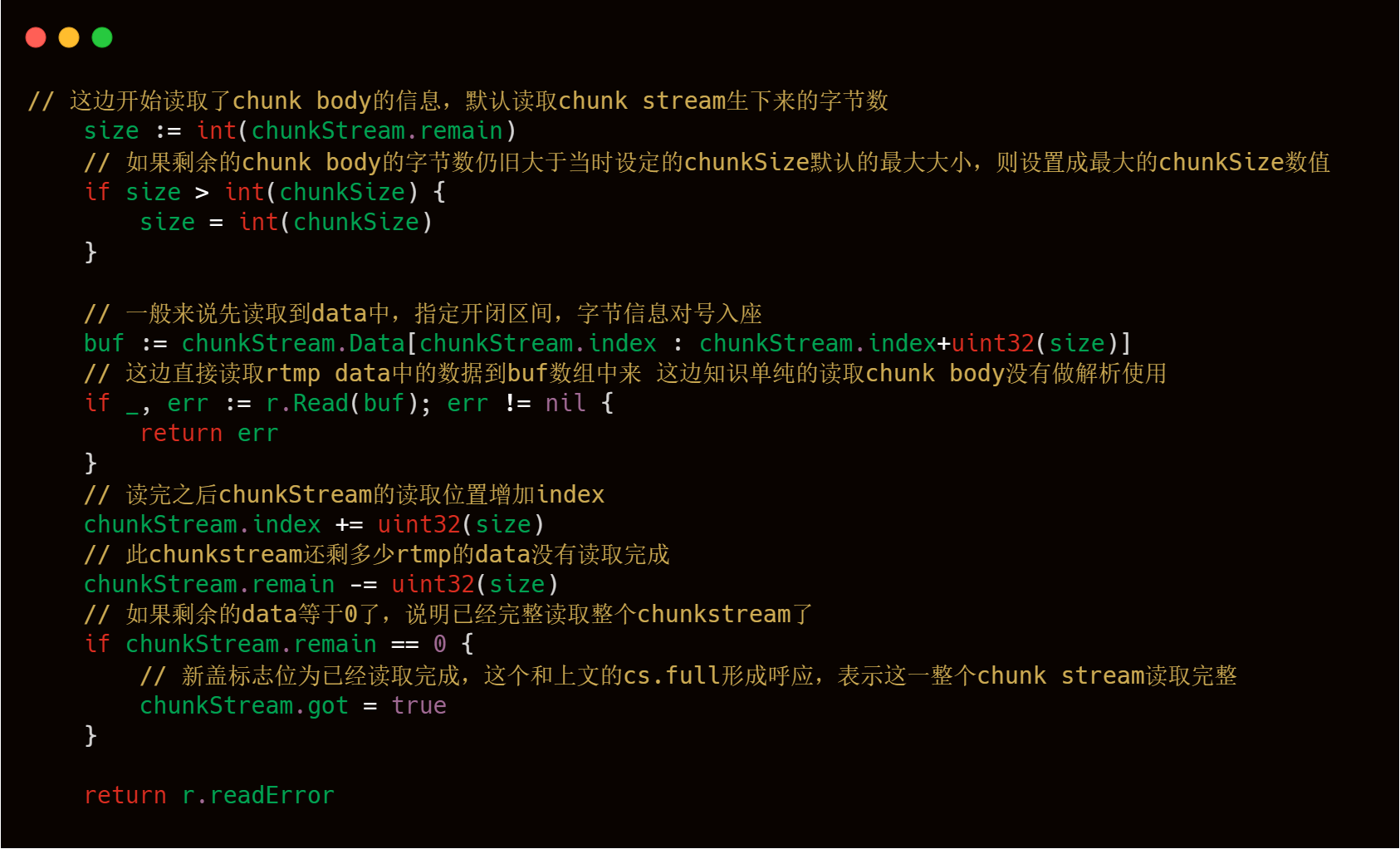
到此為止,我們已經成功解析了Chunk Header,讀取了Chunk Body,注意我們只是讀取了Chunk Body還沒有按照AMF格式對Chunk Body進行解析,針對Chunk Body部分的邏輯處理,在下文會進行詳細的源碼介紹,不過現在我們已經解析到了一個連接發送過來的ChunkStream了,接下來我們就可以回到主流程的分析了。
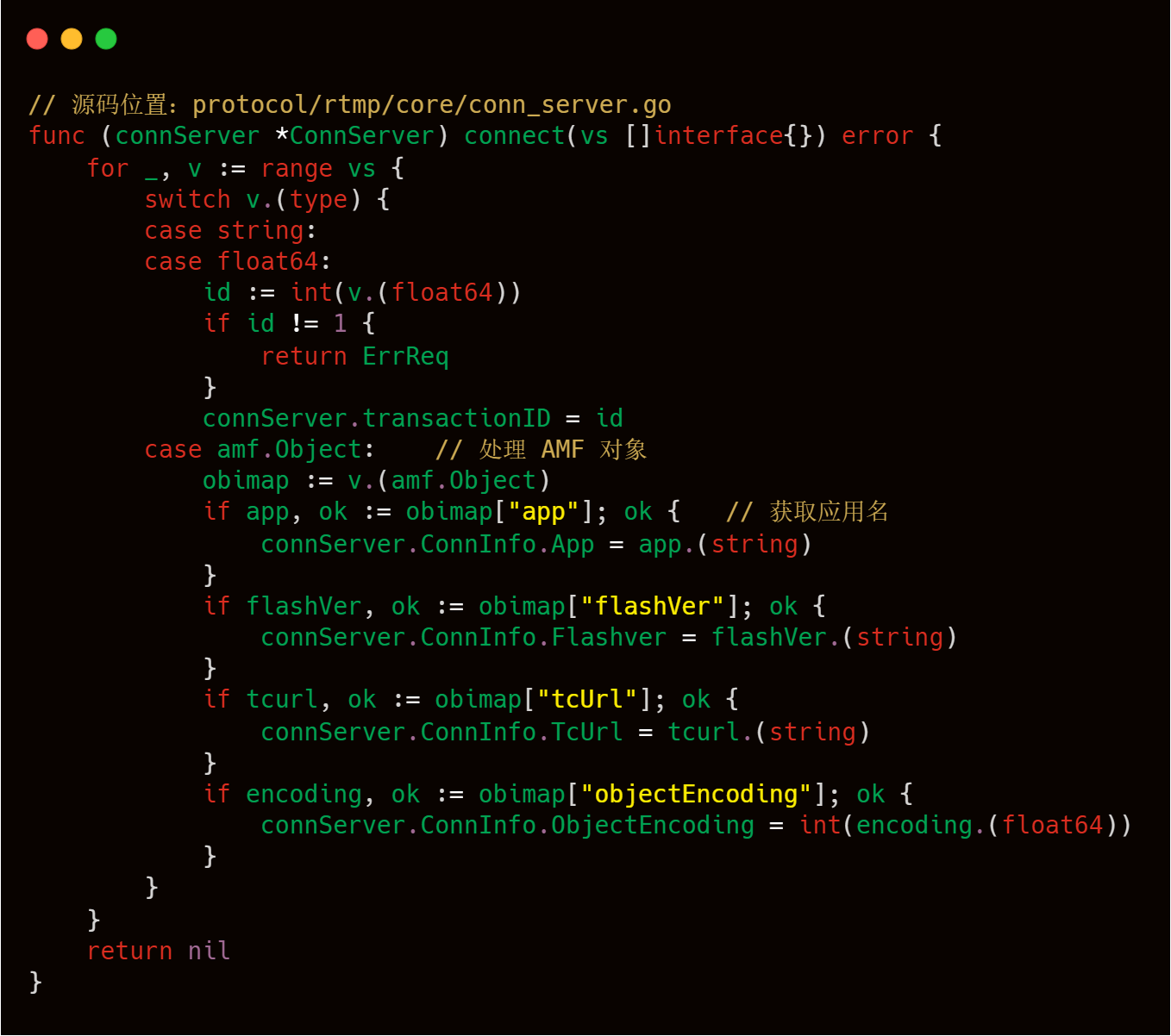
剛才說了握手完成后,并且我們也解析到了ChunkStream信息了,接下來我們就要依據ChunkStream的typeId和Chunk Body中的AMF數據進行對應的工序流程處理了,具體思路大家可以這樣理解,客戶端A發送xxxCmd命令,RTMP服務端根據typeId和AMF信息解析出xxxCmd命令,并給以對應命令的響應。

上述代碼塊中的handleCmdMsg中也是這個RTMP服務端處理客戶端命令的代碼精髓了,可以看出livego是支持AMF3和AMF0的,AMF3和AMF0的區別,上文也已經介紹過了,下文的代碼注釋寫的也比較清楚,然后就是解析AMF格式的Chunk Body的數據,解析出來的結果也是按照Slice格式進行存儲。
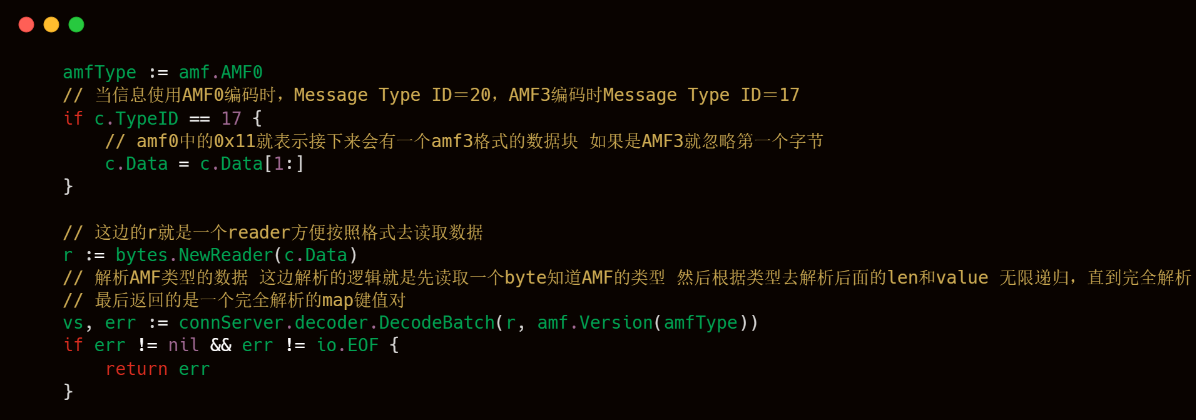
解析好typeId和AMF,接下來就是水到渠成的對各個命令進行處理了。
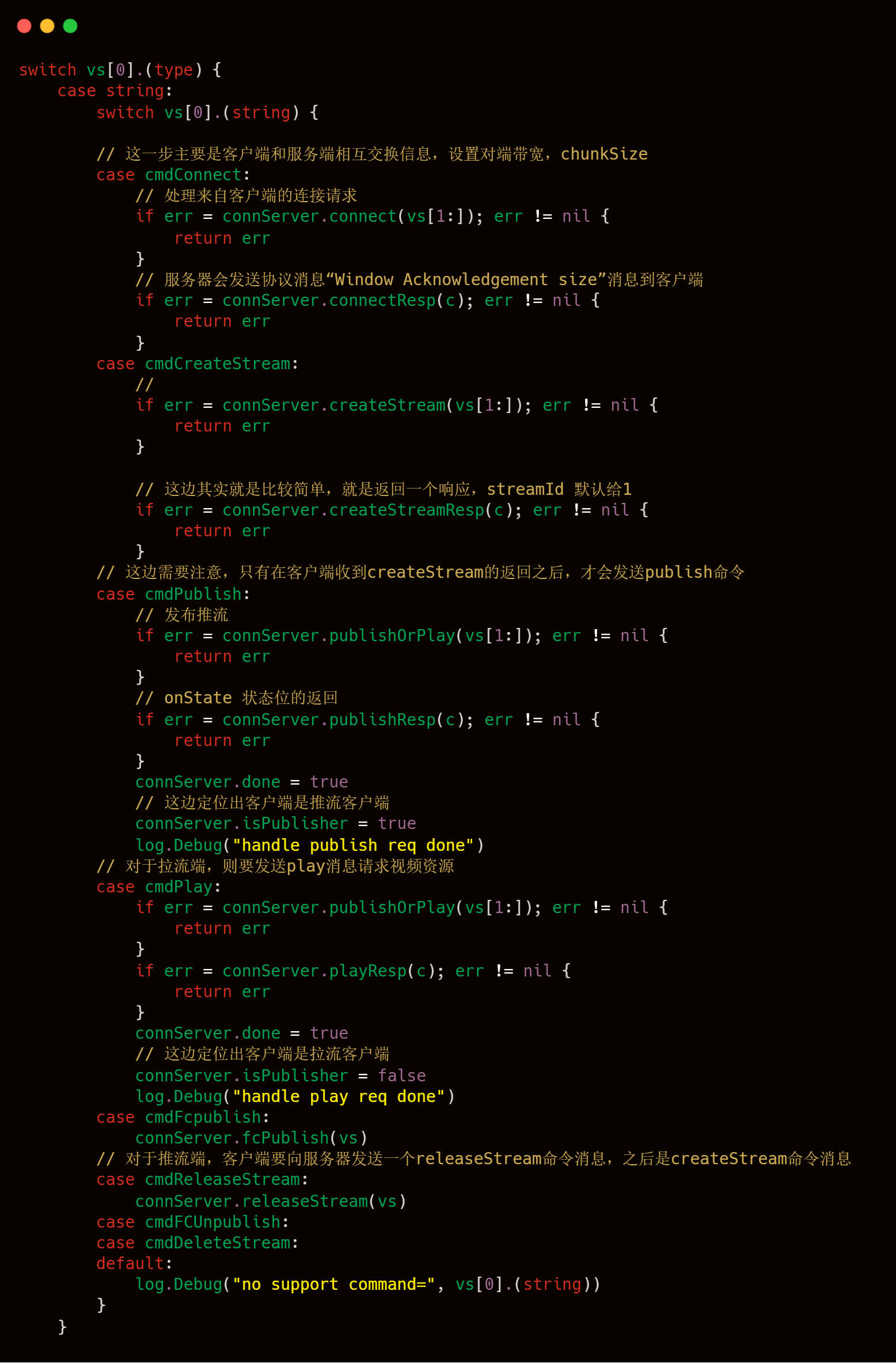
接下來是針對每一個客戶端命令的處理了。
3.2.2.2 連接
連接(Connect)命令處理過程:連接過程客戶端和服務端會完成窗口大小,傳輸塊大小和帶寬大小的確認,RTMP 協議原文詳細介紹了連接過程,如下圖所示:

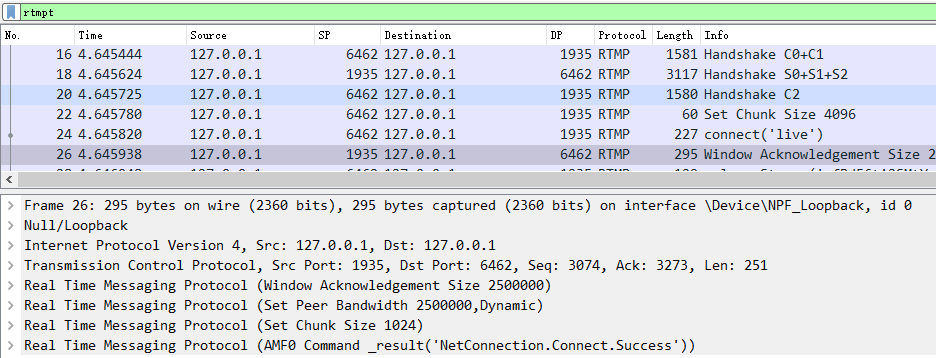
同樣,我們這里用 WireShark 抓包分析:
從抓包可以看出,連接過程只用了3個包就完成了:
22 號包:客戶端告訴服務端,我想要設置 chunk size 為 4096;
24 號包:客戶端告訴服務端,我想要連接叫 “live” 的應用;
26 號包:服務端響應客戶端的連接請求,確定窗口大小,帶寬大小和 chunk size,以及返回 “_result” 表示響應成功。這些都是通過一個 TCP 包來完成的。
那么客戶端和服務端是如何知道這些包的含義的呢?這就是 RTMP 協議規范所制定的規則了,我們可以通過閱讀規范來了解,當然也可以通過 wrieshark 來幫助我們快速解析。以下是 22 號包的詳細解析,我們重點關注 RTMP 協議解析信息就行。
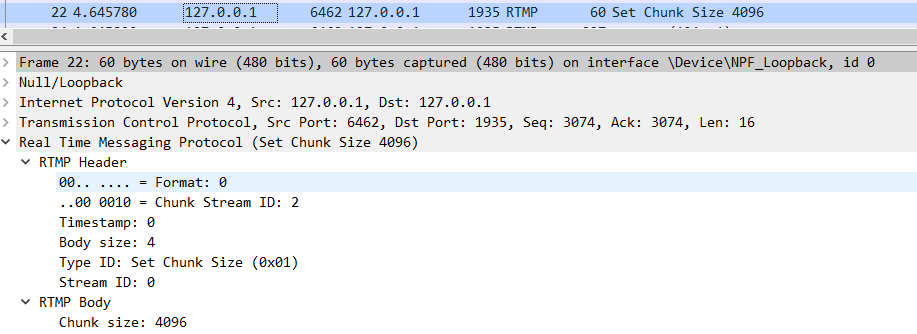
從圖中可以看出, RTMP Header 包含有 Format 信息,Chunk Stream ID 信息,Timestamp 信息,Body size 信息,Message Type ID 信息和 Messgae Stream ID 信息。Type ID 的十六進制值為 0x01,含義為 Set Chunk Size,屬于協議控制消息(Protocol Control Messages)。
RTMP 協議規范5.4節規定了,對于協議控制消息,Chunk Stream ID 必須設為 2,Message Stream ID 必須設為 0,時間戳直接忽略。從 WireShark 抓包解析出的信息可知,22號包的確是符合 RTMP 規范的。
現在我們來看看 24 號包的詳細解析。
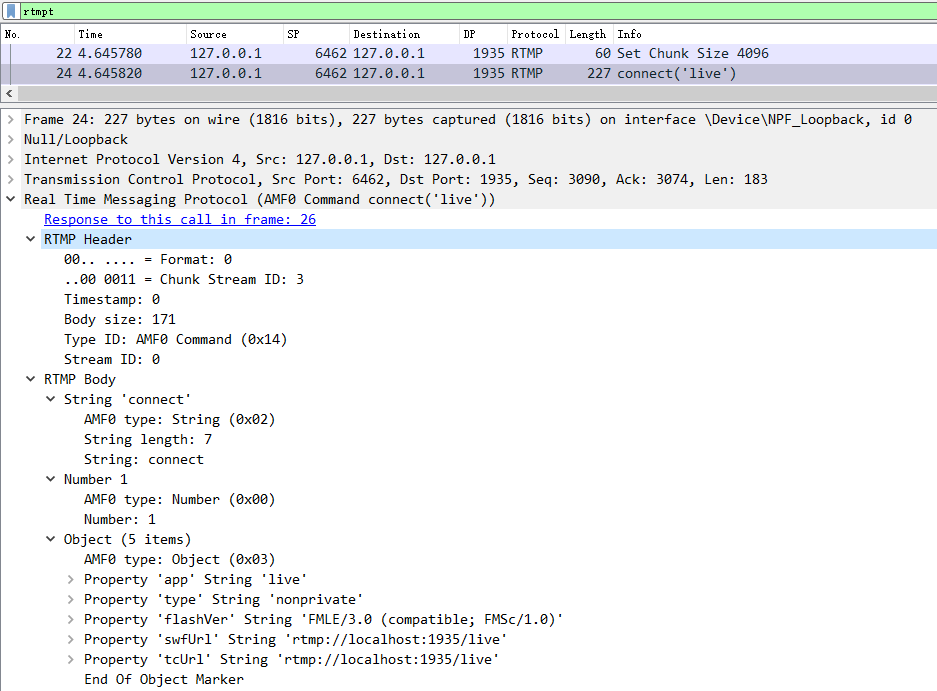
24 號包也是客戶端發出的,可以看到它設置Message Stream ID 為 0,Message Type ID 為 0x14(即十進制的20),含義為 AMF0 命令。AMF0 屬于 RTMP 命令消息(RTMP Command Messages),RTMP 協議規范并沒有規定連接過程必須要使用的 Chunk Stream ID,因為真正起作用的是 Message Type ID,服務端根據 Message Type ID 來做相應的響應。連接過程發送的 AMF0 命令攜帶的是 Object 類型的數據,會告訴服務端要連接的應用名和播放地址等信息。
以下代碼是 livego 處理客戶端請求連接的過程。
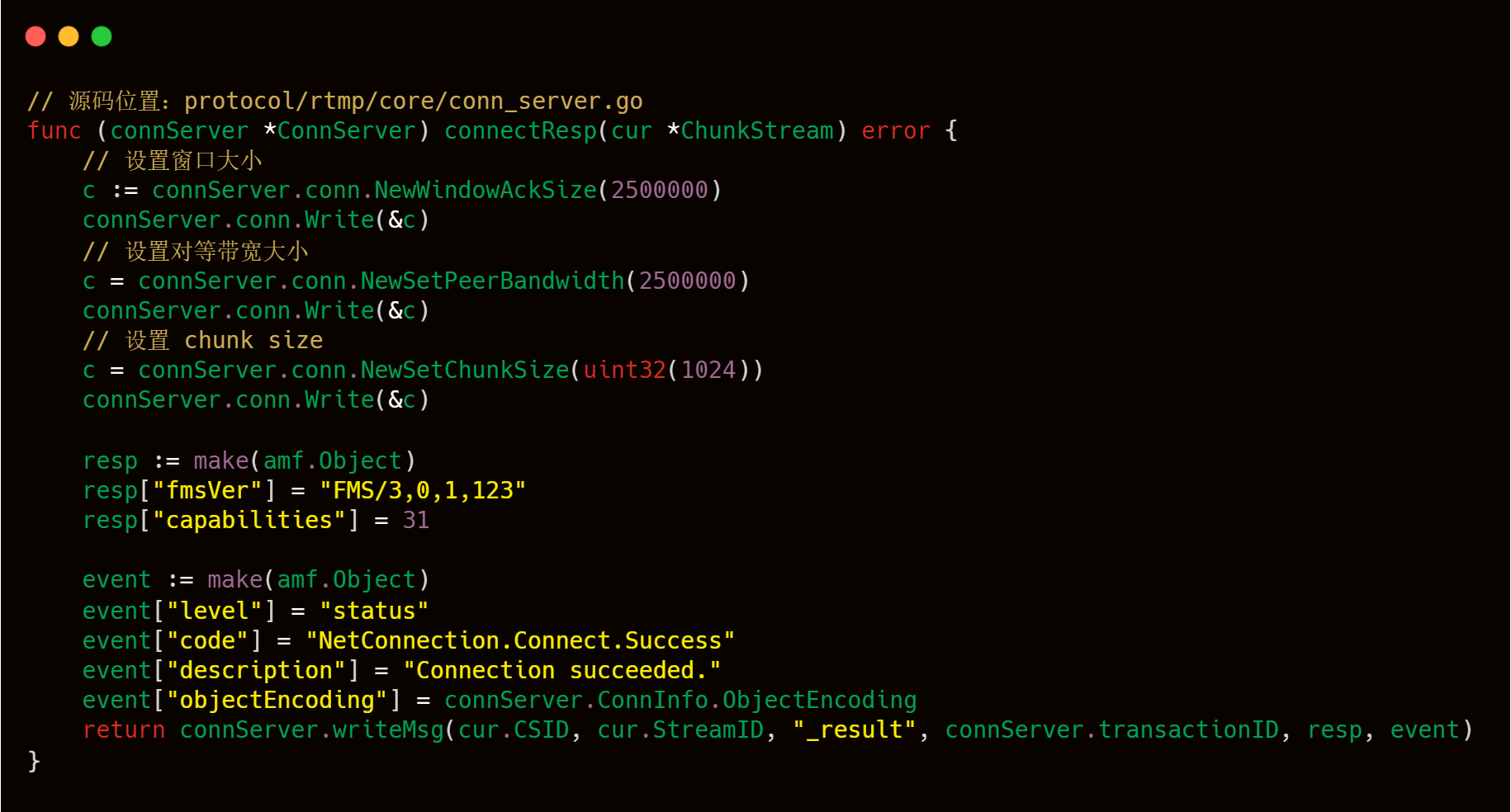
收到客戶端連接應用的請求后,服務端需要作出相應響應給客戶端,也就是 WireShark 抓取的 26 號包的內容,詳細內容如下圖所示,可以看到服務端在一個包里面做了好幾件事情。
我們可以結合 livego 源碼來深入學習該過程。
3.2.2.3 createStream
連接完成后,就可以創建流了。創建流的過程相對來說比較簡單,只需要兩個包就能夠實現,如下所示:

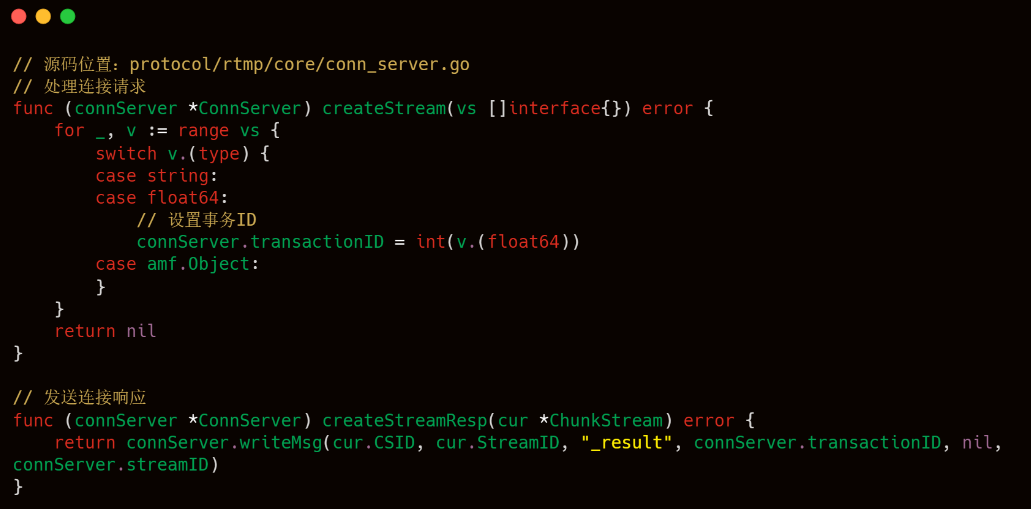
其中 32 號包是客戶端發起 createStream 請求,34 號包是服務端響應,以下是 livego 處理客戶端連接請求的源碼。
3.2.2.4 推流
創建流完成后,就可以開始推流或者拉流了,RTMP 協議規范的7.3.1節也有給出推流示意圖,如下圖所示。其中連接和創建流的過程上文已經詳細介紹過了,我們重點看發布內容(Publishing Content)的過程就行。

使用 livego 推流前,需要先獲取推流的 channelkey。我們可以通過如下命令獲取頻道為 “movie” 的 channelKey。響應內容中的 Content 的 data 字段值就是推流需要的 channelKey。
$ curl http://localhost:8090/control/get?room=movie
StatusCode : 200
StatusDescription : OK
Content : {"status":200,"data":"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575K
LkIZ9PYk"}
RawContent : HTTP/1.1 200 OK
Content-Length: 72
Content-Type: application/json
Date: Tue, 09 Feb 2021 09:19:34 GMT
{"status":200,"data":"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575K
LkIZ9PYk"}
Forms : {}
Headers : {[Content-Length, 72], [Content-Type, application/json], [Date
, Tue, 09 Feb 2021 09:19:34 GMT]}
Images : {}
InputFields : {}
Links : {}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 72使用OBS推流到 livego 服務器中應用名為 live 的 movie 頻道,推流地址為:rtmp://localhost:1935/live/rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk。同樣,我們還是先看一下WireShark 的抓包內容吧。
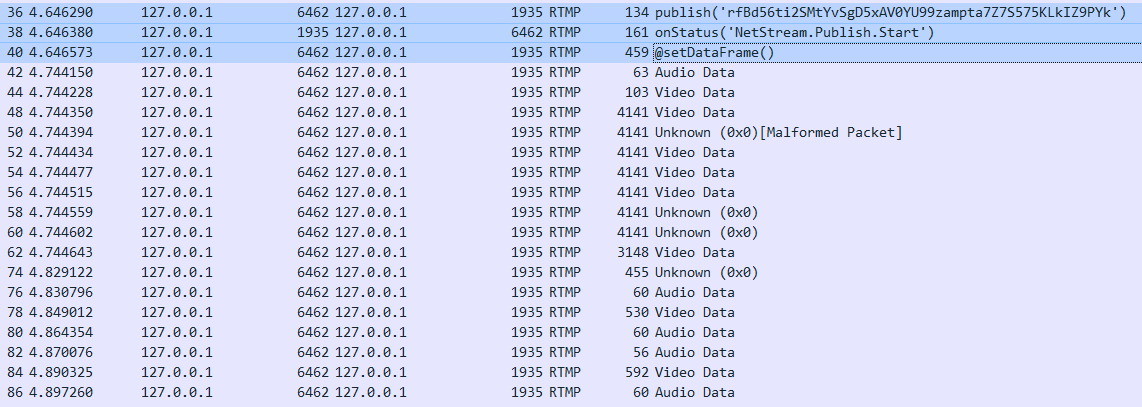
推流初期,客戶端發起 publish 請求,也就是36號包的內容,該請求中需要帶上頻道名,在這個包里面就是"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk"。
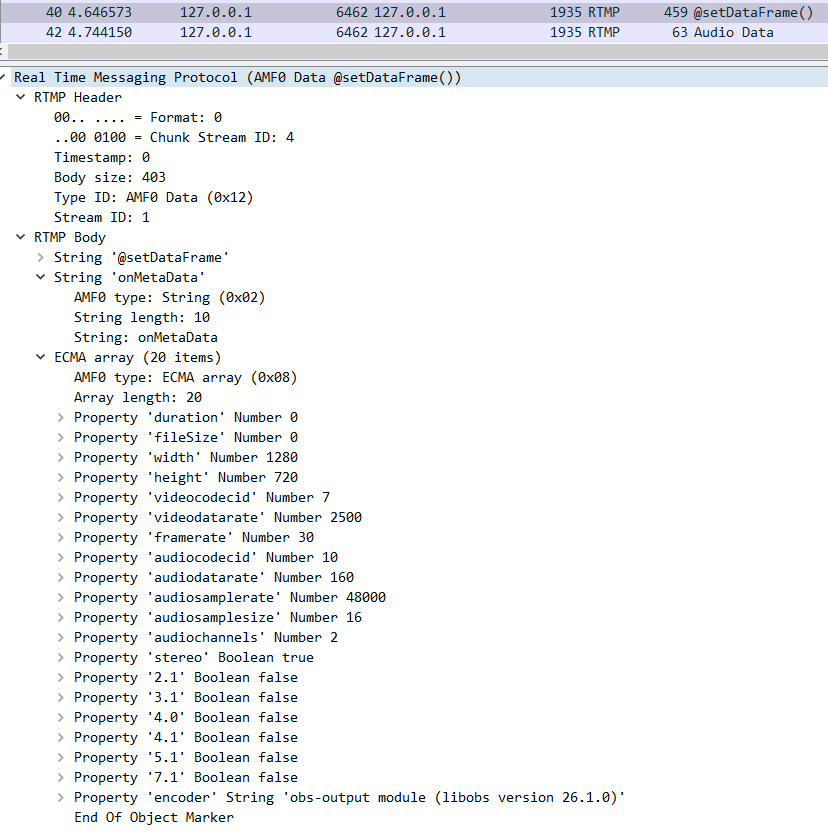
服務端會首先會檢測這個頻道名是否存在以及檢查這個推流名是否被使用中,如果不存在或者在使用的話就會拒絕客戶端的推流請求。由于我們在推流前已經生成了該頻道名,客戶端可以合法使用,于是服務端在38號包中回應的是 "NetStream.Publish.Start",也就是告訴客戶端可以開始推流了。客戶端在推流音視頻數據前需要先把音視頻的的元數據發給服務端,也就是40號包所做的事情,我們可以看一下該包的詳細內容。從下圖可以看出,發送元數據信息比較多,包含有視頻分辨率,幀率,音頻采樣率和音頻聲道等關鍵信息。
告訴服務端音視頻元數據后,客戶端就可以開始發送有效的音視頻數據了,服務端會一直接收這些數據,直到客戶端發出 FCUnpublish 和 deleteStream 命令為止。stream.go 的 TransStart() 方法主要邏輯為接收推流客戶端的音視頻數據,然后在本地緩存最新的一個數據包,最后將音視頻數據發給各個拉流端。其中讀取推流客戶單音視頻數據主要是使用到 rtmp.go 中的 VirReader.Read() 方法,相關代碼和注釋如下所示。
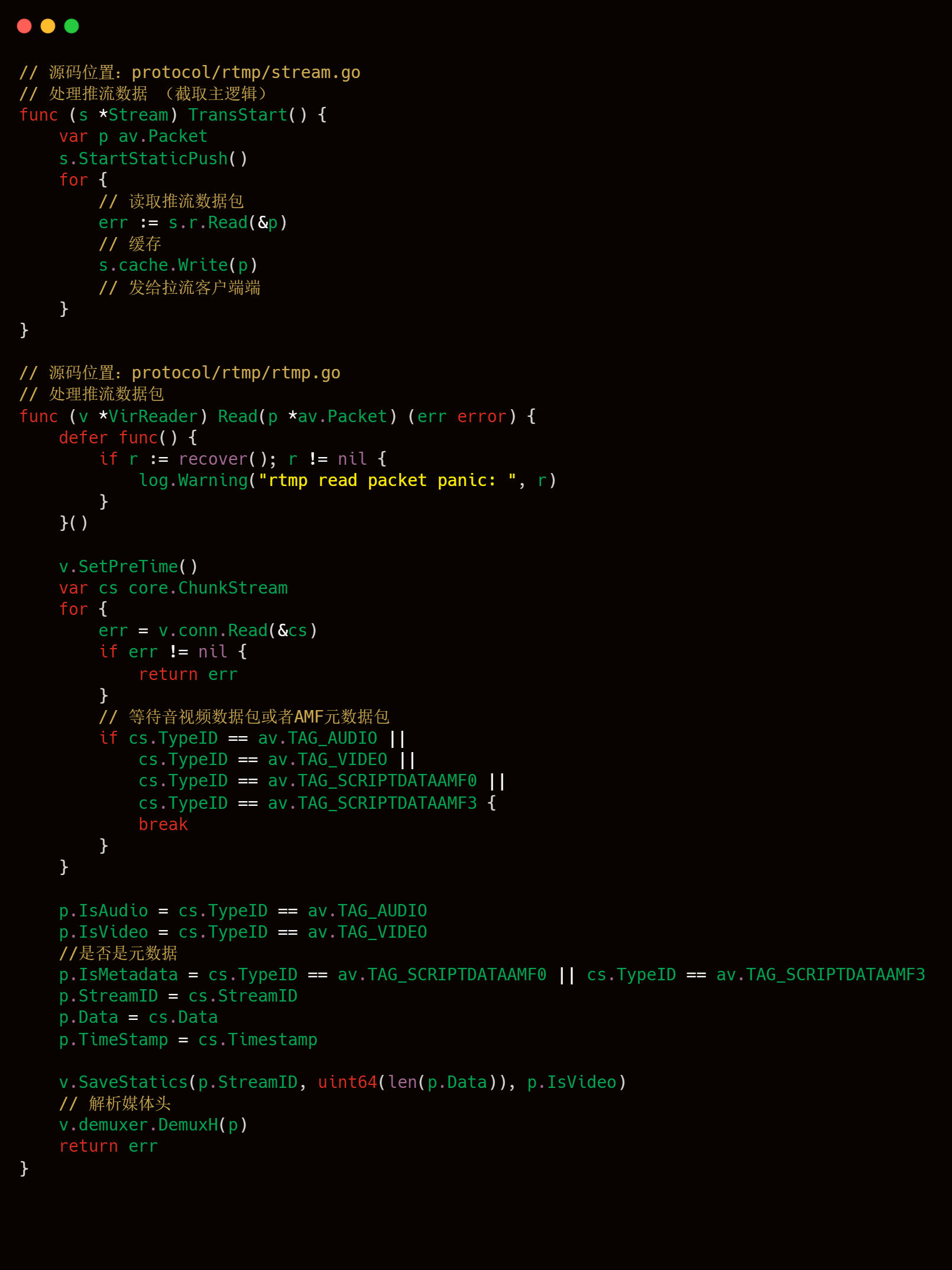
附媒體頭信息解析的部分源碼分析。
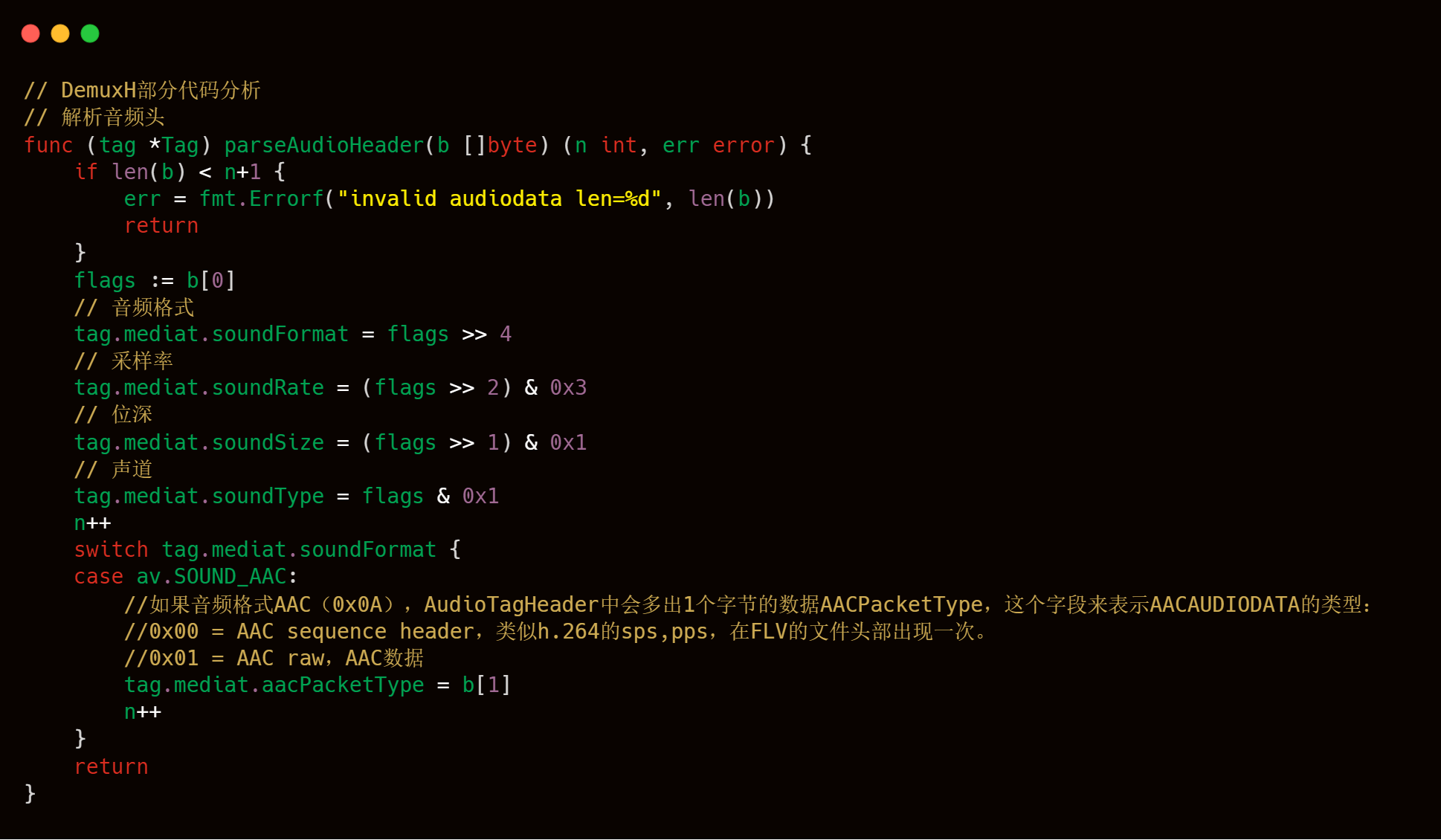
解析音頻頭
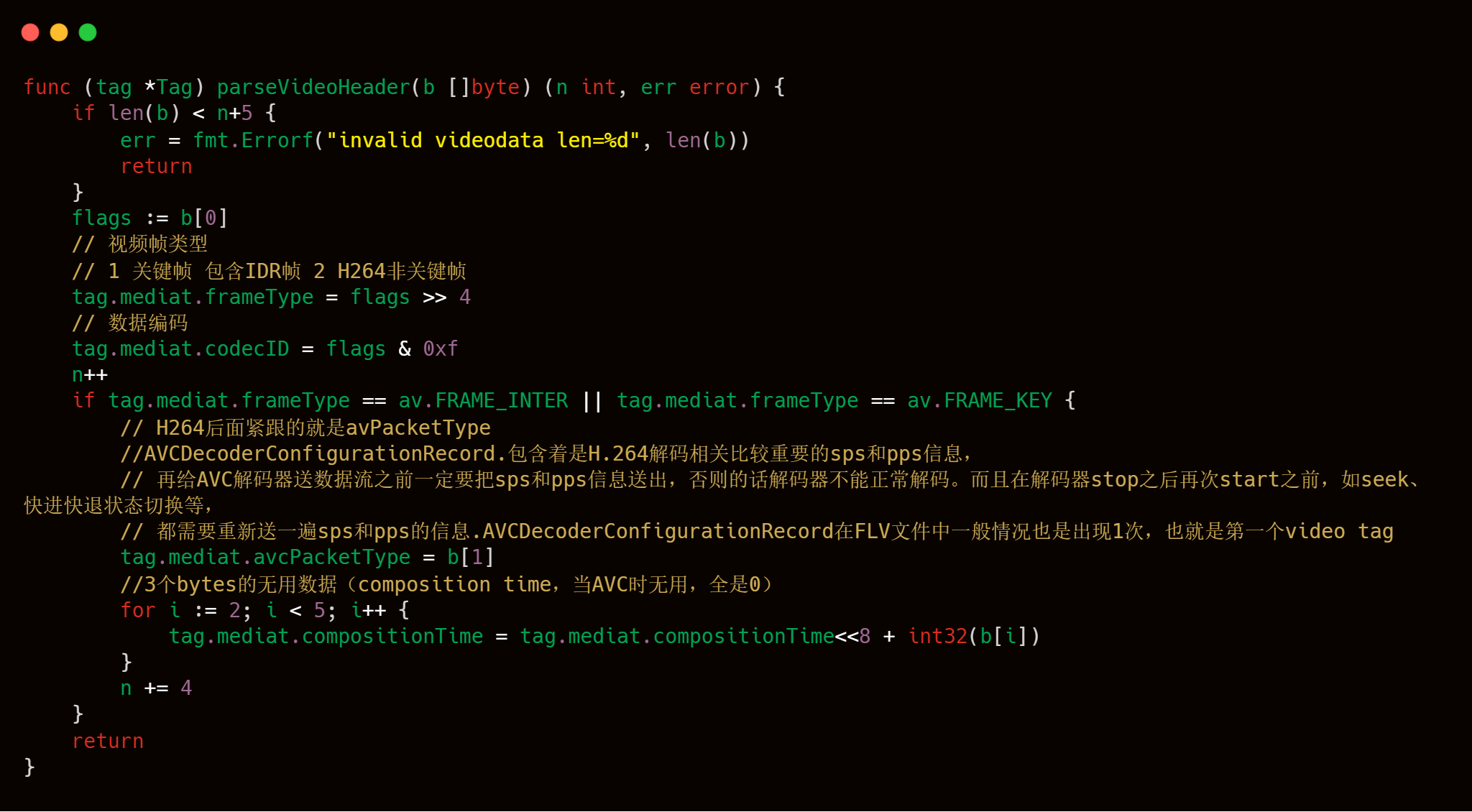
解析視頻頭
3.2.2.5 拉流
有了推流客戶端的持續推流,拉流客戶端就可以通過服務器持續拉取到音視頻數據了。RTMP 協議規范的7.2.2.1節對拉流過程進行了詳細描述。其中,握手、連接和創建流的過程前文已經講述過了,我們重點關注下 play 命令的過程就行。
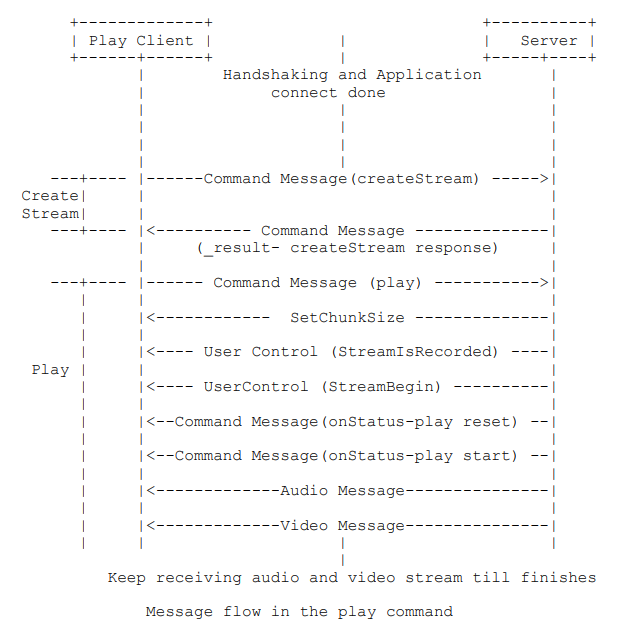
同樣,我們先用 WireShark 抓包來分析下。客戶端通過 640 號包告訴服務器,我想要播放叫 “movie” 的頻道。

此處為什么是叫 “movie” 而不是推流時候用的“rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk”,其實這兩個指向的是同一個頻道,只不過一個用于推流一個用于拉流,我們可以從 livego 的源碼來印證這一點。
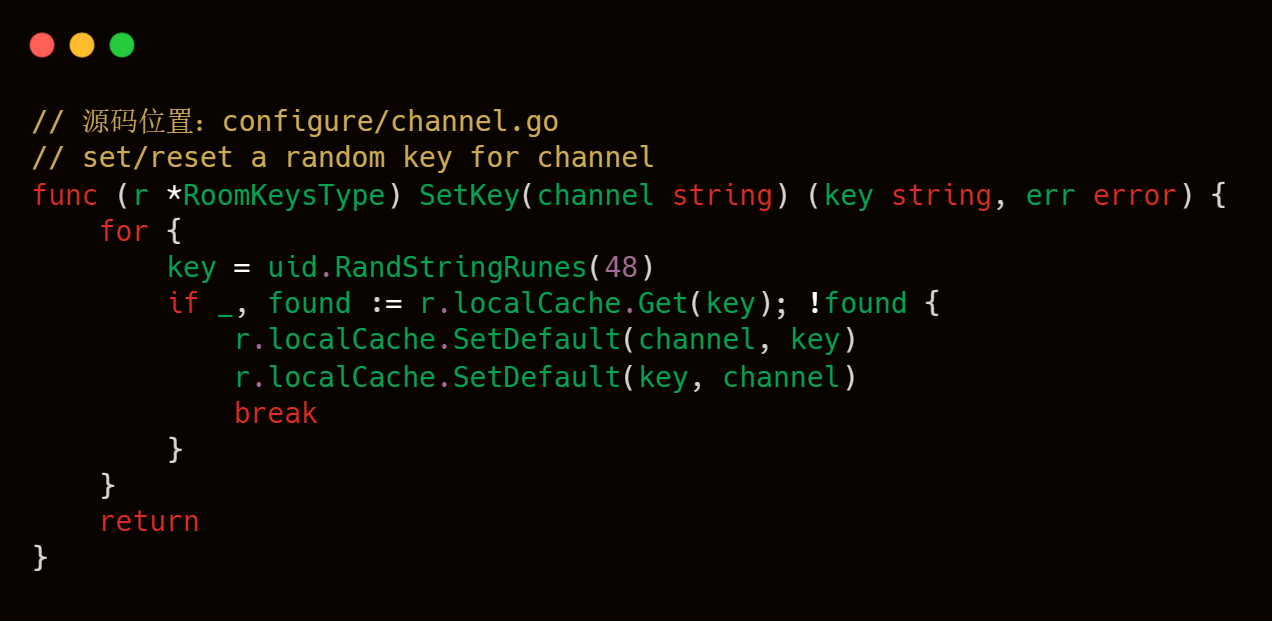
服務端收到拉流客戶端的 play 請求后,會做出響應 "NetStream.Play.Reset","NetStream.Play.Start" ,"NetStream.Play.PublishNotify" 和音視頻元數據。這些工作做完后,就可以持續發送音視頻數據給拉流客戶端了。我們可以通過 livego 源碼來加深一下對此過程的理解。
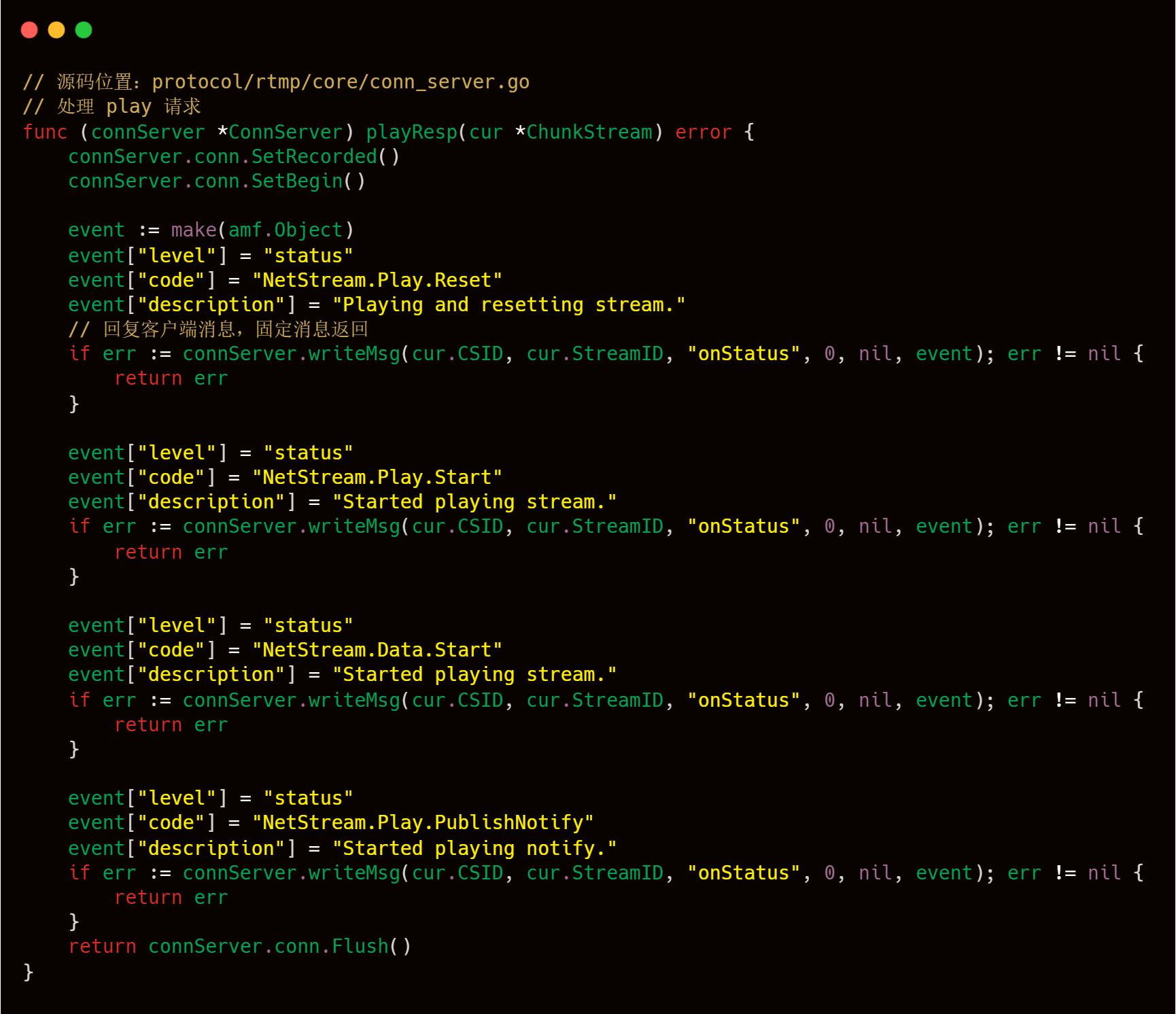
通過 chan 讀取推流數據,然后發給拉流客戶端。
到此為止整個RTMP的主體流程就是這樣了,這邊不涉及FLV,HLS等具體傳輸協議或者格式轉換的源碼說明,也就是說RTMP服務器怎么收到推流客戶端的音視頻包也會原封不動地分發給拉流客戶端,并沒有做額外的處理,不過現在各大云廠商拉流端都支持http-flv,hls等傳輸協議的支持,并且也支持音視頻的錄制回放點播功能,這塊livego其實也是支持的。
因為篇幅限制,這邊就不再展開介紹,后續有機會,再單獨一起學習分享介紹livego關于這塊邏輯的處理。
目前基于RTMP協議的直播是國內直播的基準協議,也是各大云廠商都兼容的直播協議,它的多路復用,分包等優秀特性也是各大廠商選擇它的一個重要原因。在這個基礎之上,也是因為它是應用層協議,騰訊,阿里,聲網等大型云廠商,也會對其協議的細節,進行源碼的改造,例如實現多路音視頻流的混流,單路的錄制等功能。
但是RTMP也有它自己本身的缺點,時延較高就是RTMP一個最大的問題,在實際的生產過程中,即使在比較健康的網絡環境中,RTMP的時延也會有3~8s,這與各大云廠商給出的1~3s理論時延值還是有較大出入的。那么時延會帶來哪些問題呢?我們可以想象如下的一些場景:
在線教育,學生提問,老師都講到下一個知識點了,才看到學生上一個提問。
電商直播,詢問寶貝信息,主播“視而不理”。
打賞后遲遲聽不到主播的口播感謝。
在別人的吶喊聲知道球進了,你看的還是直播嗎?
特別是現在直播已經形成產業鏈的大環境下,很多主播都是將其作為一個職業,很多主播使用在公司同一個網絡下進行直播,在公司網絡的出口帶寬有限的情況下,RTMP和FLV格式的延遲會更加嚴重,高時延的直播影響了用戶和主播的實時互動,也阻礙了一些特殊直播場景的落地,例如帶貨直播,教育直播等。
以下是使用RTMP協議常規的解決方案:
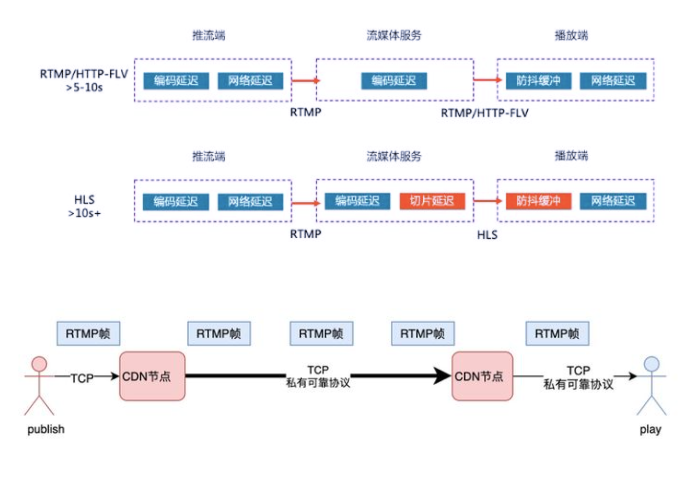
根據實際的網絡情況和推流的一些設置,例如關鍵幀間隔,推流碼率等等,時延一般會在8秒左右,時延主要來自于2個大的方面:
CDN鏈路延遲, 這分為兩部分,一部分是網絡傳輸延遲。CDN內部有四段網絡傳輸,假設每段網絡傳輸帶來的延遲是20ms,那這四段延遲便是100ms;此外,使用RTMP幀為傳輸單位,意味著每個節點都要收滿一幀之后才能啟動向下游轉發的流程;CDN為了提升并發性能,會有一定的優化發包策略,會增加部分延遲。在網絡抖動的場景下,延遲就更加無法控制了,可靠傳輸協議下,一旦有網絡抖動,后續的發送流程都將阻塞,需要等待前序包的重傳。
播放端buffer,這個是延遲的主要來源。公網環境千差萬別,推流、CDN傳輸、播放接收這幾個環節任何一個環節發生網絡抖動,都會影響到播放端。為了對抗前邊鏈路的抖動,播放器的常規策略是保留6s 左右的媒體buffer。
到此,關于“什么是RTMP協議”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





