溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關hive中join數據傾斜的實例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
set mapred.reduce.tasks = 30;insert overwrite directory 'xxx' select cus.idA,cus.name,addr.bb from tableA as cus join tableB as addr on cus.idA = addr.idB
很簡單的一個hql語句,優化的空間也不是很大(例子中的addr數據量比cus小,應該講addr放在前面驅動join)。tableA的量級為億級,tableB的量級為幾百萬級別。就這么一個簡單的sql,尼瑪從上午十點半開始跑,跑到下午三點半還沒有跑完。實在受不了了,kill掉了。
首先上個查詢過程中的圖
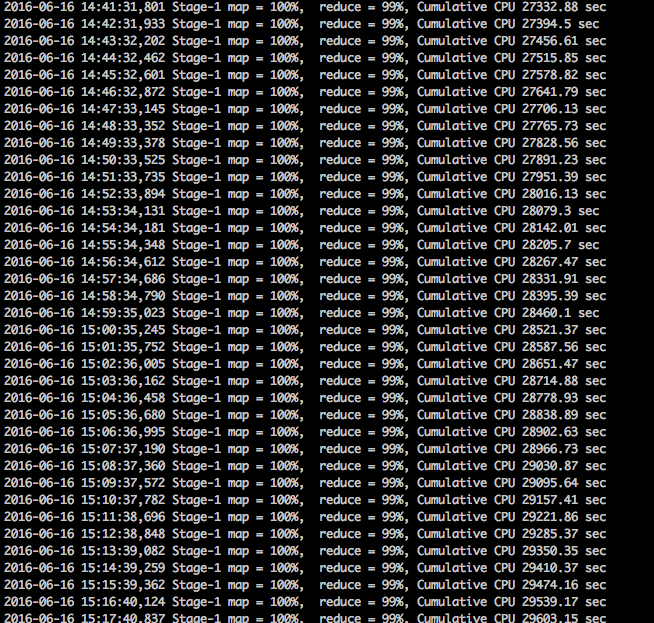
看到這種情況,稍微有點經驗的同學第一反應肯定就是:臥槽,這尼瑪肯定是數據傾斜了。沒錯,map早就完工了,reduce階段一直卡在99%,而且cumulative cpu的時間還一直在增長,說明整個job還在后臺跑著。這種情況下,99%的可能性就是數據發生了傾斜,整個查詢任務都在等某個節點完成。。。
問題既然已經定位了,那接下來就是需要解決問題了。正好不巧的是,集群這幾天還出了一些狀況。so,首先為了確認到底是集群本身的問題,還是代碼的問題,先找了另外兩個表,都是億級數據。這兩個表不存在數據傾斜的情況,join一把試了試,兩分鐘之內結果就出來了。萬幸,說明這會集群已經沒有問題了,還是查查數據跟代碼吧。
代碼本身很簡單,那就沿著數據傾斜的方向查查吧。因為上面的兩個表是根據id關聯的,那如果傾斜的話,肯定就是id傾斜了哇。
set mapred.reduce.tasks = 5;select idA,count(*) as num from tableA group by idAdistribute by idA sort by num desc limit 10
結果為:
192928 58285292000000000496592833 240628918000 17060314000288 13863242000000003624295444 12011782000000001720892923 10294752000000002292880478 9912992000000000736661289 8819542000000000740899183 8734872000000000575115116 803250
對于有上億數據的一個表來說,這數據也算不上傾斜多厲害嘛。最多的一個key也就五百多萬不到六百萬。好吧,先不管了,再查一把另外一個表
set mapred.reduce.tasks = 5;select idB,count(*) as num from tableB group by idB distribute by idB sort by num desc limit 10
結果也很快出來
192928 38341218000 60318617279581 2302851010262 46434000286 35282000000000575115116 32181366173280 30124212339 29722000000002025620390 27042000000001312577574 2622
這數據傾斜,也不是特別嚴重嘛。
不過再把這兩個結果一對比,尼瑪恍然大悟。兩個表里最多的一個key都是192928,一個出現了將近600萬次,一個出現了將近40萬次。這兩個表再一join,尼瑪這一個key就是600萬*40萬的計算量。最要命的是,這計算量都分配給了一個節點。我數學不太好,600萬*40萬是多少,跪求數學好的同學幫忙計算一下。不過根據經驗來看的話,別說5個小時,再添個0也未必能算得完。。。
既然找到了數據傾斜的位置,那解決起來也就好辦了。因為本博主的真正需求并不是真正要算兩個表的笛卡爾積(估計實際中也極少有真正的需求算600萬*40萬數據的笛卡爾積。如果有,那畫面太美我不敢看),所以最easy的解決方案,就是將這些key給過濾掉完事:
set mapred.reduce.tasks = 30;insert overwrite directory 'xxx' select cus.idA,cus.name,addr.bb from tableA as cus join tableB as addr on cus.idA = addr.idB where cus.idA not in (192928,2000000000496592833,18000,4000288,2000000003624295444,2000000001720892923,2000000002292880478,2000000000736661289,2000000000740899183,2000000000575115116,617279581,51010262,4000286,1366173280,2000000002025620390,2000000001312577574)
將此代碼重新提交,5min時間,job跑完收工!
感謝各位的閱讀!關于“hive中join數據傾斜的實例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





