溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“分布式協調服務組件Zookeeper的必備知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“分布式協調服務組件Zookeeper的必備知識點有哪些”吧!
Zookeeper是一個開源的分布式協調服務組件。是分布式集群的監控者,能對集群中節點的狀態變更進行及時的反饋。
Zookeeper對分布式一致性的保證:
順序一致性:保證服務端的執行順序是按照客戶端操作的發送順序來執行的
原子性:客戶端操作結果要么成功、要么失敗。
單一視圖:無論客戶端連接到那個服務端,看到的視圖是一致的。
可靠性:客戶端操作請求一定執行成功,則執行結果會一直持久到下一次操作
最終一致性:保證一定時間內客戶端看到的視圖是最新的數據(允許一定時間內看到的數據不是最新的)
Zookeeper默認保證客戶端拿到的視圖是連接到的服務器此時的順序一致性視圖,通過客戶端調用SyncCommand保證是客戶端看到的視圖是此時集群中所有節點的最新強一致性視圖。
注意:最終一致性存在在一段時間內客戶端看到的視圖不一定是最新數據
ZooKeeper -server host:port -client-configuration properties-file cmd args addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE addauth scheme auth close config [-c] [-w] [-s] connect host:port create [-s] [-e] [-c] [-t ttl] path [data] [acl] delete [-v version] path deleteall path [-b batch size] delquota [-n|-b] path get [-s] [-w] path getAcl [-s] path getAllChildrenNumber path getEphemerals path history listquota path ls [-s] [-w] [-R] path printwatches on|off quit reconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*] redo cmdno removewatches path [-c|-d|-a] [-l] set [-s] [-v version] path data setAcl [-s] [-v version] [-R] path acl setquota -n|-b val path stat [-w] path sync path version whoami
Zookeeper數據是存儲在內存中的具有層次結構的命名空間,類似于多級別的文件目錄結構一樣,不同的是每個命名空間可以掛載數據。命名空間不應該使用以下字符:\u0000、\u0001-\u001F、\u007F、\ud800-uF8FF、\uFFF0-uFFFF、保留關鍵字:zookeeper。命名空間都是絕對路徑,不存在相對路徑,以斜杠路徑分隔符劃分層級。
/meta1 /meta2 |-- /meta1/node1 |-- /meta2/node1 |-- /meta1/node2 |--|--/meta2/node2/child |--|-- /meta1/node3/child |-- /meta2/node3 |-- /meta1/node4 |-- /meta2/node4
Zookeeper是Java語言開發的,節點稱為Znode,樹形存儲結構對象為:DataTree,節點存儲對象為:ConcurrentHashMap<String, DataNode> nodes。
Zookeeper節點本身存儲無大小限制,但是數據序列化傳輸時有限制,默認上限1M,可通過系統屬性:"jute.maxbuffer"配置,詳細可見類:BinaryInputArchive。但是Zookeeper在集群中節點數據傳輸較多,不建議存儲過大的數據,一旦修改該上限,集群中所有節點都要修改。
Zookeeper支持四種類型的節點,節點只能逐個創建:v3.5.3+支持對持久節點設置TTL
臨時節點(EPHEMERAL):節點生命周期綁定客戶端會話,在客戶端結束會話時會自動刪除,節點下不能創建新的節點
臨時有序節點:(EPHEMERAL_SEQUENTIAL):具有臨時節點特點,節點創建后節點名自動追加序號,多次創建序號自增,10位數字
持久節點(PERSISENT):持久落盤保存,重啟不丟失,需要手動調用delete命令刪除
持久有序節點(PERSISTENT_SEQUENTIAL):具有持久節點特點,節點創建后節點名會自動追加序號,多次創建序號自增,10位數字
容器節點(CONTAINER):當其子節點被完全刪除時,該節點會自動刪除
限時節點(TTL):對持久節點增加限時時長,默認禁用該功能,啟用屬性為:zookeeper.extendedTypesEnabled
Zookeeper在分布式協調中遵循ZAB協議,具有過半有效特點,要求集群節點數量符合:2N+1。也就是可以單機部署,集群部署最少3個節點,最多宕機1臺,否則集群不可用(永遠不會過半,也不會轉為單機運行,會報錯),這里也說明Zookeeper保證的是分布式中CAP定理中的CP,一致性和分區容錯性。注意:Zookeeper集群中最少時2臺機器就可以運行了,但是宕機任意一臺集群就不可用。
在Zookeeper啟動同時會啟動一個線程輪詢服務器狀態,每臺集群節點服務只會存在以下狀態:
LOOKING:表示當前集群中不存在Leader節點,集群中所有可參與選舉的節點正在進行Leader節點選舉
LEADING:表示該節點是集群中的領導者leader
leader角色具有對外提供讀寫視圖能力,集群中只有Leader節點能執行事務(增、刪、改)操作,其他節點都需要轉發到Leader來執行
FOLLOWING:表示該節點是集群中的跟隨者follower,說明當前集群中存在某個其他節點已經是Leader節點。
follower角色具有同步視圖數據、轉發事務請求到Leader以及對外提供讀視圖能力,在Zookeeper中配置為participant:參與者
OBSERVING:表示該節點是集群中的觀察者Observer
Observer角色主要擴展集群的非事務處理能力,對外提供讀視圖能力、轉發事務請求到Leader,不具有選舉能力。
observer與Follower統稱為learner
二階段提交是為保證分布式系統中數據的一致性而將事務操作行為分為兩個階段來完成。
第一階段:leader服務節點將該事務請求是否能夠執行通過提議方式詢問集群中的所有Follower節點,各個Follower節點對該提議進行確認ACK。
第二階段:Leader對收到的ACK進行過半判斷,判定成功則進行事務提交,異步通知各Follower節點也進行事務提交。如果判定失敗則進行事務回滾。
事務一般都是通過日志文件的形式來實現的,zookeeper也不例外。第一階段針對事務請求會先進行日志記錄,然后發出詢問。在第二階段收到各Follower節點確認后,根據之前的日志,更新數據庫來完成事務。
主要指2兩種運行狀態,在Leader失聯時進入崩潰恢復狀態,進行Leader選舉,當選舉完成后進入原子廣播協議,Leader節點將事務請求廣播到Follower節點
Zookeeper集群中是必須要一臺Leader角色的節點的,在不存在Leader節點時就需要集群內部自行選舉,這種情況分為兩種:1:集群首次啟動時,2:集群中Leader節點失聯時,二者的選舉流程一致,只是前者時啟動時發現Leader不存在,后者是運行時發現Leader失聯。
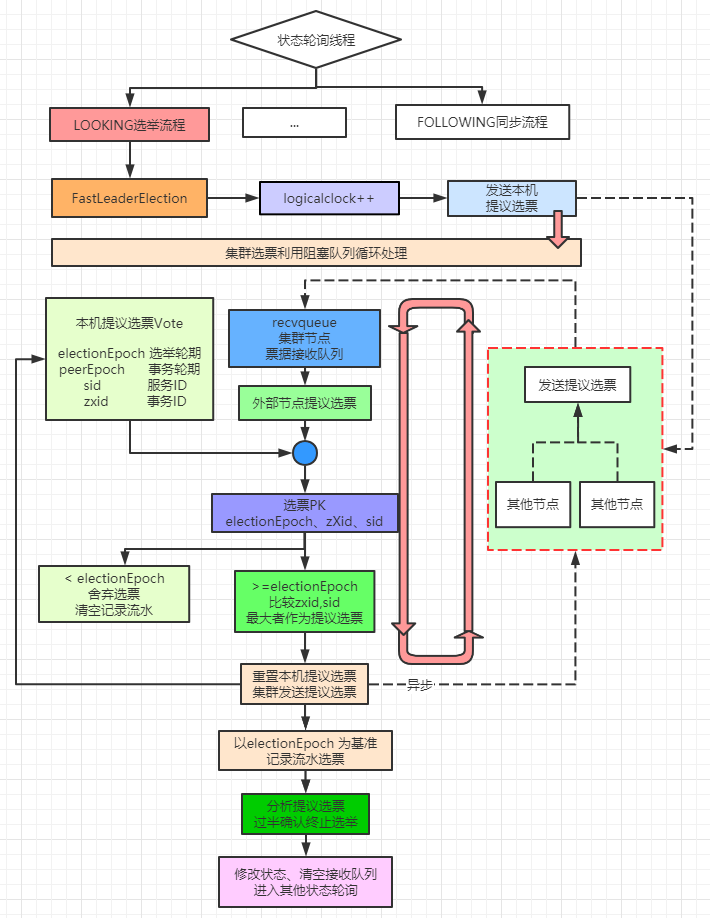
Zookeeper節點啟動時默認的狀態為:LOOKING,即集群中不存在Leader節點,需要進行Leader選舉。對于節點狀態的監控是一個死循環,隨服務啟動而開始,隨服務停止而結束,因此首次啟動會立馬根據選舉算法開始Leader選舉,v3.5+選舉算法只有一個: FastLeaderElection
在Zookeeper的選票中存在四個很重要的數據:myid(集群服務ID)、zxid(事務ID)、peerEpoch(leader輪期)、electionEpoch(選舉輪次)。
myid表示集群節點的服務唯一ID,這是配置文件中配置的ID,是身份識別碼。
zxid表示集群節點中記錄的事務日志ID,是一個64位Long類型數字,其中高32位為epoch,低32位為自增計數器counter。
epoch則表示當前集群中Leader所處的輪期,每次Leader變更都會自增1,是Zxid的高32位。
electionEpoch表示自節點啟動時集群中進行過Leader選舉的輪次,每次Leader選舉內部多個輪次
zxid結構如下
public static long makeZxid(long epoch, long counter) {
return (epoch << 32L) | (counter & 0xffffffffL);
}zxid整體是自增的,Zookeeper通過自增來保證數據的順序性。根據Zookeeper保證的順序一致性:zxid越大則該事務執行的越晚,保存的數據越完整。
Leader選舉前后要保證的就是數據的盡可能一致性,因此Leader選舉的實質就是找出存活的Follower節點中數據保存最完善的那一臺作為Leader。
尋找方式就是比較zxid大小。如果zxid都一致,則說明存活的Follower節點數據保存完整性是一樣的,隨便選一臺都行,Zookeeper默認選中myid最大的那一臺。
尋找算法則是FastLeaderElection的實現過程
在Leader選舉流程中,存在一個阻塞隊列,用來接收其他集群節點中發送的選票,而當前節點也會持有一個選票。選票內容主要包括:myid(集群節點身份識別唯一ID)、zxid(集群節點最大事務日志ID)、peerEpoch(集群節點事務所處輪期)、electionEpoch(集群已進行Leader選舉的次數)。
在選舉流程開始時首先將投向自己的選票(選票內容均指向自身節點信息)發送出去,由于機器中節點在啟動時都會發送一個選票,因此阻塞隊列就會收到其他節點的選票。選票的發送屬于異步發送,方法為:sendNotifications,先把內容ToSend放入阻塞隊列,然后發送線程去逐個發送。
節點使用logicalclock(邏輯時鐘)來記錄當前集群進行Leader選舉的輪次electionEpoch。并在每次投票之后以輪次為基礎進行流水記錄,便于后續分析,節點只記錄最新輪次的投票流水。
當其他節點的electionEpoch大于當前節點的electionEpoch時,說明,當前節點錯過了某輪投票,需要更新logicalclock,并在選票PK之后更新自身持有的投票信息,為數據較為完整的節點投上一票。(說明之前的投票所處輪次已過時,需要為最新輪次重新投一票)
// 選票PK方法 return ((newEpoch > curEpoch)|| ((newEpoch == curEpoch) && ((newZxid > curZxid)|| ((newZxid == curZxid)&& (newId > curId)))));
當其他節點的electionEpoch小于當前節點的electionEpoch時,說明,其他節點錯過了某輪投票,本身之前投票記錄是有效的,其他節點的投票所處輪次是過時,因此舍棄這個過時投票,不參與統計。(本身的票已經投出去了,不需要重復投票)
當其他節點的electionEpoch等于當前節點的electionEpoch時,說明,兩者節點都是正常投票,則進行選票PK,比較本節點的zxid、myid和選票節點的對應值大小。哪個節點的值大則說明哪個節點記錄的數據較為完整,此時需要更新選票信息,為數據較為完整的節點投上一票。(說明之前的投票的節點數據不是集群中記錄最完整的,需要重新投一票)
以輪次為基礎,為數據較為完整的節點投上一票后,阻塞隊列就又接收到了新一批選票,然后再次比較,依次循環下去
Leader選舉就是選出數據最完整的那臺節點,因此選舉流程不會一直循環PK下去,會在流水記錄符合過半確認時終止循環。而這個判斷條件是在為可能完整節點投票后,以服務ID為表示,記錄集群中為該服務節點投票信息,當集群中過半節點都對該節點投了票時就認定該節點有資格成為Leader節點,從而結束Leader選舉。
圖示如下
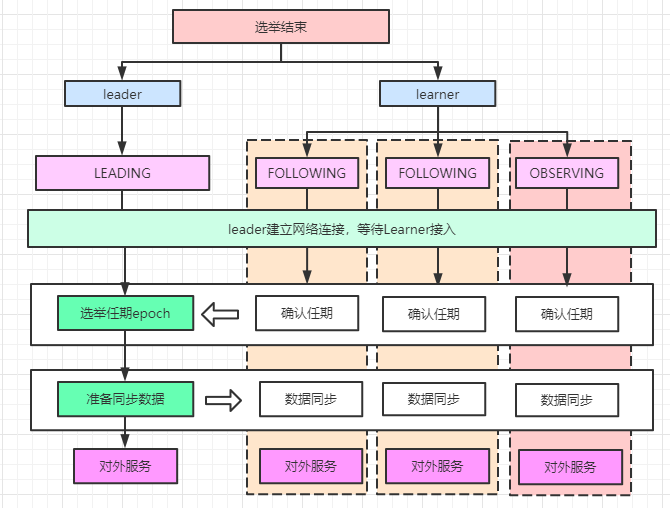
Zookeeper集群中選舉出Leader節點后,Leader節點會進行LEADING狀態。Follower節點則會進行FOLLOWING狀態,開啟Leader確認、同步流程。而observer節點則進入OBSERVING狀態,同樣準備進入同步流程。
預選Leader節點會先與Learner節點建立網絡連接,等待Follower、Observer節點接入。
cnxAcceptor = new LearnerCnxAcceptor(); // 這是一個連接線程 cnxAcceptor.start();
這個網絡連接十分重要,每個Leader會構建一個LearnerCnxAcceptorHandler的處理器,核心過程如下
BufferedInputStream is = new BufferedInputStream(socket.getInputStream()); LearnerHandler fh = new LearnerHandler(socket, is, Leader.this); fh.start();
這個LearnerHandler處理所有Leader與learner的網絡IO交互
public class QuorumPacket implements Record {
private int type;
private long zxid;
private byte[] data;
private java.util.List<org.apache.zookeeper.data.Id> authinfo;
}Follower節點進入FOLLOWING狀態后,首先會去查找Leader地址,然后建立網絡連接
QuorumServer leaderServer = findLeader(); connectToLeader(leaderServer.addr, leaderServer.hostname);
建立連接之后便發出type=FOLLOWERINFO的消息包,xid=ZxidUtils.makeZxid(self.getAcceptedEpoch(), 0),data=LearnerInfo
主要功能就是將當前節點的epoch發送(所有連接節點都會發送INFO信息來給Leader提供集群中最大的epoch,以便確認Leader的最新任期:lastAcceptedEpoch + 1,Leader節點會阻塞等待Follower節點接入直至滿足過半確認時獲取最大的epoch)
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
消息發出后等待Leader節點指示
Follower發出的FOLLOWERINFO消息包會在LearnerHandler被接收轉為:learnerInfoData,獲取Follower提供的zxid中的epoch
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
然后參與到新任Leader的epoch選舉中
long newEpoch = learnerMaster.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
Leader接收到過半Follower提供的epoch后,發送最終epoch確認消息包
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, newLeaderZxid, ver, null);
等待Follower確認最終的epoch
learnerMaster.waitForEpochAck(this.getSid(), ss);
Follower之前阻塞在registerWithLeader中的INFO信息發送后,此時接收到Leader指示獲取Leader的epoch和zxid,發出確認接收消息
QuorumPacket ackNewEpoch = new QuorumPacket(Leader.ACKEPOCH, lastLoggedZxid, epochBytes, null);
在接收到Leader給的zxid后,將自身狀態設為同步狀態,開啟數據同步流程,等待Leader的同步數據。
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION); syncWithLeader(newEpochZxid);
Leader接收到足夠的Follower的epoch確認消息后,將自身狀態設為數據同步狀態,與各個Learner開啟數據同步,阻塞等待Learner數據同步完成然后執行自身的Leading
waitForNewLeaderAck(self.getId(), zk.getZxid());
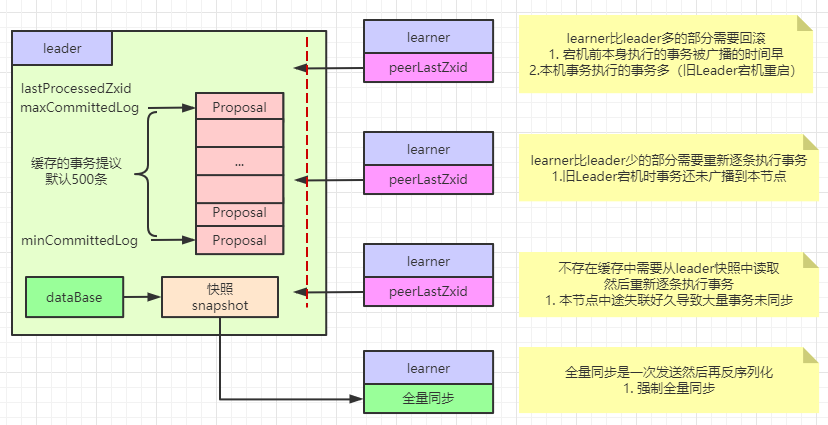
數據同步發生在各個Leader建立的網絡連接中:LearnerHandler,在確認到Learner接收了最新epoch消息后,立馬開啟數據同步流程
boolean needSnap = syncFollower(peerLastZxid, learnerMaster);
同步過程使用重入讀寫鎖:ReentrantReadWriteLock。并且獲取此Leader節點的lastProcessedZxid、minCommittedLog、maxCommittedLog
同步類型:DIFF:差異同步、TRUNC:回滾同步、SNAP: 全量同步,主要是TRUNC+DIFF,也就是learner上事務日志比leader上多的zxid進行回滾,少的從leader接收進行重做。
只有系統變量:zookeeper.forceSnapshotSync 配置了強制全量同步時,會使用快照文件開啟全量同步。
到底是learner的事務日志多還是leader節點的事務日志多,是通過兩個節點的zxid比較的。事務日志是會落盤形成快照的,節點會緩存一定條數的事務日志,那部分具有minCommittedLog、maxCommittedLog的范圍屬性。在此范圍的數據可以直接發送,否則需要從磁盤讀取快照文件再次發送。
系統變量:zookeeper.snapshotSizeFactor 配置每次從磁盤讀取的快照數據所占快照總數的比例,默認0.33即三分之一
系統變量:zookeeper.commitLogCount 配置節點緩存的事務日志數量,默認500條
Follower節點阻塞在syncWithLeader中等待Leader同步的數據,Leader同步數據主要就三種,DIFF、TRUNC、SNAP。其中DIFF是逐條的執行提議,Follower節點接收后會執行,TRUNC接收到Follower則直接截斷日志文件到指定位置即可,對于SNAP則清空dataTree根據傳輸的日志文件反序列即可。處理完畢則發送確認消息,正式對外提供服務。Leader節點接收到Follower的同步結束消息后,結束waitForNewLeaderAck,也會正式對外提供服務。
同步數據主流程如圖所示
數據同步細節如圖所示
Zookeeper支持客戶端對數據節點Znode注冊Watch監聽,當節點發生變化會及時反饋給該客戶端。Watch機制是Zookeeper分布式鎖、對外Leader選舉功能的基礎。
v3.6.0之前:watch是一次性注冊,一旦反饋后會刪除,如果需要重復監聽,則需要重復注冊
v3.6.0+ :支持配置監聽模式:STANDARD(標準類型)、PERSISTENT(持久類型)、PERSISTENT_RECURSIVE(持久遞歸類型)。標準類型就是之前版本的一次性注冊類型;持久類型則是自動重復注冊類型;持久遞歸類型則是持久類型的加強版本,不僅重復監聽指定節點,還重復監聽節點的子節點。后兩種模式需要主動移除Watch才能取消監聽。
支持Watch的API:exist、getData、getChildren、addWatch
移除Watch的API:removeWatches
觸發Watch的API:setData、delete、create
只有注冊了Watch監聽的客戶端才會收到反饋通知
客戶端收到的反饋通知順序與服務端節點處理順序一致
Watch依賴網絡連接的一次性通知,客戶端重連期間可能會導致Wacth丟失
標準Watch是一次性,多次觸發的Watch如果客戶端沒有來得及重置,會導致后續Watch通知丟失
標準Watch是一次性,持久Wach是服務端自動注冊的,實質還是一次性通知
持久Watch如果不主動移除會一直通知下去
客戶端對指定節點注冊Watch
服務保存Watch,一旦觸發事件則發送消息通知
客戶端回調watch事件,進一步處理
Watch監聽注冊對象在Zookeeper中為WatchRegistration,不同API對應的注冊對象不同
// getData、getConfig ---> DataWatchRegistration
public class GetDataRequest implements Record {
private String path;
private boolean watch;
}
// exists ---> ExistsWatchRegistration
public class ExistsRequest implements Record {
private String path;
private boolean watch;
}
// getChildren --> ChildWatchRegistration
public class GetChildrenRequest implements Record {
private String path;
private boolean watch;
}
// @since 3.6.0 addWatch --> AddWatchRegistration
public class AddWatchRequest implements Record {
private String path;
private int mode;
}這個請求又一個很明顯特點:watch是一個布爾類型,也就是說只標識是否watch
watch注冊
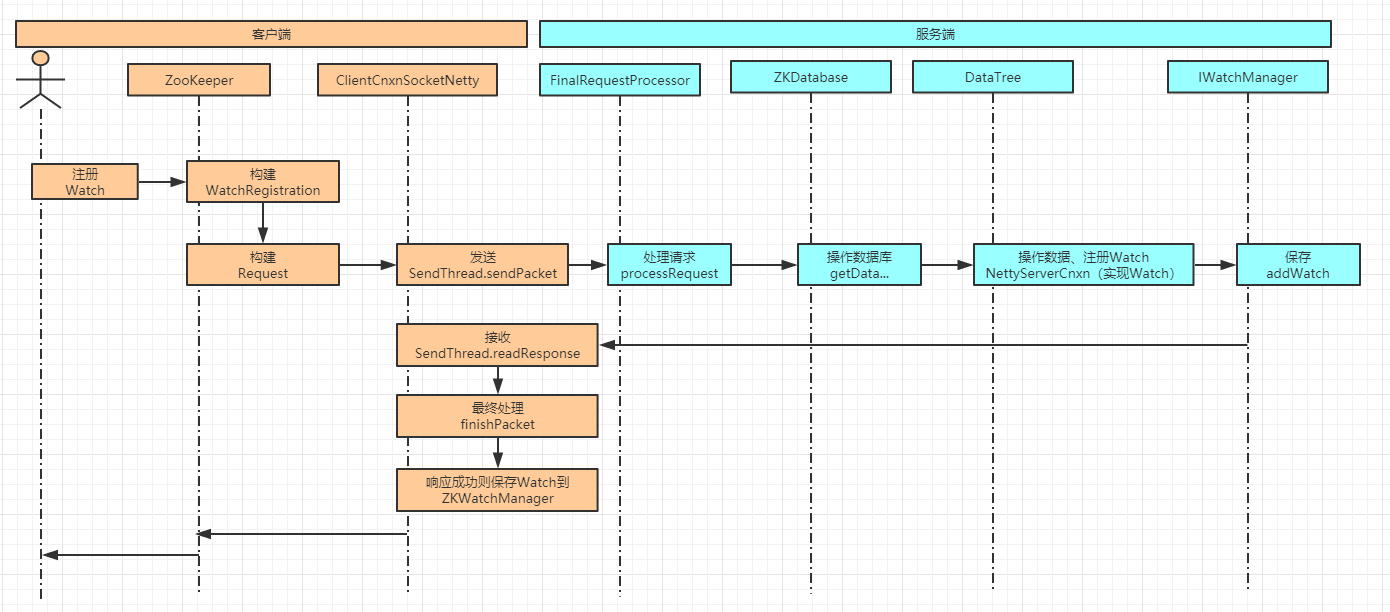
1.--> 客戶端:在發起API請求時構建queuePacket對象。該對象主要包含RequestHeader、ReplyHeader、Record(Request)、Record(Response)、WatchRegistration等。其中RequestHeader標記本次請求的操作類型 type 和事務zxid。服務端根據操作類型會有不同的解析流程。在queuePacket的構造方法中會把queuePacket放入到一個阻塞隊列中outgoingQueue,該隊列會有專用的線程sendThread#clientCnxnSocket#doTransport從隊列中讀取元素并處理。如果是事務請求則把zxid++,然后序列化RequestHeader和Request,只把這兩者發送出去。queuePacket會放到pendingQueue中等待服務器返回,也就是說WatchRegistration并沒有發送出去,只是發送了操作標識、zxi、path、watch標志。
2.--> 服務端:在Zookeeper啟動時會通過startServerCnxnFactory開啟服務端連接,此時會開啟AcceptThread來處理客戶端的連接,客戶端建立連接時會在這里處理,在接入時會構建SelectorThread來通過handleIO處理客戶端的IO請求,然后將以此IO交互抽象為IOWorkRequest交給線程池去異步處理doWork-->doIO,然后開始解析網絡消息包readPayload,然后解析消息包processPacket,解析之后放到阻塞隊列submittedRequests中,隊列請求在RequestThrottler中處理,然后submitRequestNow交給ZkServer的處理鏈去鏈式處理。處理鏈初始化時指定了FinalRequestProcessor會處理與數據庫的交互。根據操作標識type不同有不同的解析流程并反序列化數據構建對應的Request。如果Request中存儲watch標識則在DataTree中通過IWatchManager添加記錄,記錄包含監聽的路徑Path和客戶端的連接ServerCnxn等,這步就是服務端注冊,這里IWatchManager區分為當前節點和子節點2種。
private IWatchManager dataWatches; private IWatchManager childWatches;
將Request處理完畢就寫入Response中,構建ReplyHeader、操作標識、響應狀態stat等返回了
3.--> 客戶端:在SendThread#readResponse中接收服務端的響應,此時阻塞隊列pendingQueue中取出之前outgoingQueue中保存的queuePacket對象,處理好響應內容就finishPacket,此時客戶端就完成Watch注冊和對應API功能的響應。finishPacket接收的是queuePacket對象,會處理其中的WatchRegistration,調用其register方法。register首先會拿到客戶端的ZKWatchManager中對應類型的存儲列表。其中ZKWatchManager存儲以下列表
private final Map<String, Set<Watcher>> dataWatches = new HashMap<>(); private final Map<String, Set<Watcher>> existWatches = new HashMap<>(); private final Map<String, Set<Watcher>> childWatches = new HashMap<>(); private final Map<String, Set<Watcher>> persistentWatches = new HashMap<>(); private final Map<String, Set<Watcher>> persistentRecursiveWatches = new HashMap<>();
不同Map存儲不同類型的Watcher,register方法就是將WatchRegistration的實例存儲到HashMap中。這就是客戶端注冊。
圖示如下
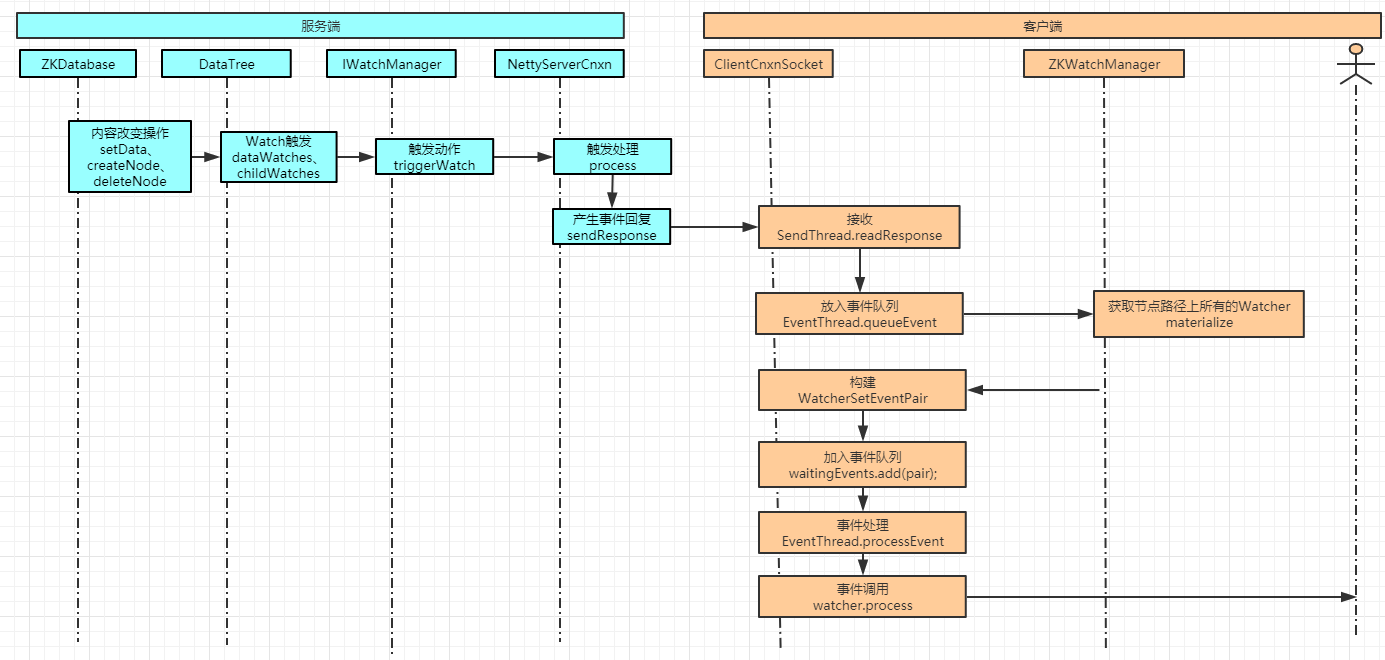
Watch觸發
1.--> 客戶端:當節點發送NodeCreated,NodeDeleted、NodeDataChanged、NodeChildrenChanged事件時,會觸發Watch反饋,對應API為:create、delete、setData。
2.--> 服務端:在以上API操作DataTree數據時,會觸發IWatchManager#triggerWatch,不同API觸發的事件類型不同。triggerWatch會查詢相關Watch并調用其process放啊,當然這是服務端的watch,也就是在服務端注冊的與操作節點Path相關的ServerCnxn。此時ServerCnxn會構建一個notification類型客戶端響應并發送給客戶端。如果WatchMode是默認類型則觸發一次就移除了Watch標識,否則會持續觸發。
public static final WatcherMode DEFAULT_WATCHER_MODE = WatcherMode.STANDARD;
3.--> 客戶端:同樣在SendThread#readResponse中接收服務端的響應,解析是發現是notification類型響應,則構建一個WatcherEvent,通過eventThread.queueEvent(we)構建事件和對應Watch列表的WatcherSetEventPair對象,然后放入阻塞隊列waitingEvents。構建WatcherSetEventPair時會查找所有在客戶端ZKWatchManager中注冊的對指定事件感興趣的客戶端Watch。EventThread則不斷從waitingEvents取出事件,如果是WatcherSetEventPair則遍歷調用Watch的process方法,該方法就是客戶端需要重新的Watch監聽處理方法。這樣就完成了整個Watch觸發機制
圖示如下
在V3.2.0+ 添加了 Chroot 特性,該特性允許每個客戶端為自己設置一個命名空間。這樣客戶端的所有操作都會在改命名空間下面,生成數據隔離。
Zookeeper支持對每個節點配置ACL權限,其中添加認證用戶命令為:addauth scheme auth ,auth格式為:<username>:<passwprd>
ACL權限方案
方案 | 描述 | 設置命令 |
world | 只有一個用戶:anyone,代表所有人(默認) | setAcl path world:anyobe:acl |
ip | 使用IP地址認證 | setAcl path ip:<ip>:acl |
auth | 使用已添加認證的用戶認證 | setAcl path auth:<username>:acl |
digest | 使用“用戶名:密碼”方式認證 | setAcl path digest:<username>:<passwprd>:acl |
ACL權限標識
權限 | ACL簡寫 | 描述 |
CREATE | c | 可以創建子節點(只能逐級創建,不能跨級別創建節點) |
DELETE | d | 可以刪除子節點(僅下一級節點) |
READ | r | 可以讀取節點數據及顯示子節點列表 |
WRITE | w | 可以設置節點數據 |
ADMIN | a | 可以設置節點訪問控制列表權限 |
集群數量符合2N+1原則,當集群宕機數量少于1/2時,仍然能對外服務
v3.5.0+ 支持集群動態配置,在主配置文件開啟屬性reconfigEnabled=true,配置屬性為:dynamicConfigFile= basePath/fileName ,動態配置文件名格式為:configFilename.dynamic[.version]。 內容只支持server、group 、 weight屬性,其中server配置格式為
server.<positive id> = <address1>:<port1>:<port2>[:role];[<client port address>:]<client port>
角色role可選值為:participant(參與者,運行中為follower,默認值)、observer(觀察者)。修改后需要調用客戶端命令reconfig
v3.6.0+ 支持度量指標監控,可配合Prometheus.io通過Jetty服務器對外輸出。訪問地址為:http://hostname:httPort/metrics。此時可以使用grafana進行可視化監控。
感謝各位的閱讀,以上就是“分布式協調服務組件Zookeeper的必備知識點有哪些”的內容了,經過本文的學習后,相信大家對分布式協調服務組件Zookeeper的必備知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





