溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“什么是h2和r2dbc-h2”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“什么是h2和r2dbc-h2”吧!
什么是H2數據庫呢?
H2是一個Java SQL database,它是一個開源的數據庫,運行起來非常快。
H2流行的原因是它既可以當做一個獨立的服務器,也可以以一個嵌套的服務運行,并且支持純內存形式運行。
H2的jar包非常小,只有2M大小,所以非常適合做嵌套式數據庫。
如果作為嵌入式數據庫,則需要將h3*.jar添加到classpath中。
下面是一個簡單的建立H2連接的代碼:
import java.sql.*;
public class Test {
public static void main(String[] a)
throws Exception {
Connection conn = DriverManager.
getConnection("jdbc:h3:~/test", "sa", "");
// add application code here
conn.close();
}
}如果給定地址的數據庫并不存在,
同時H2還提供了一個簡單的管理界面,使用下面的命令就可以啟動H2管理界面:
java -jar h3*.jar
默認情況下訪問http://localhost:8082就可以訪問到管理界面:
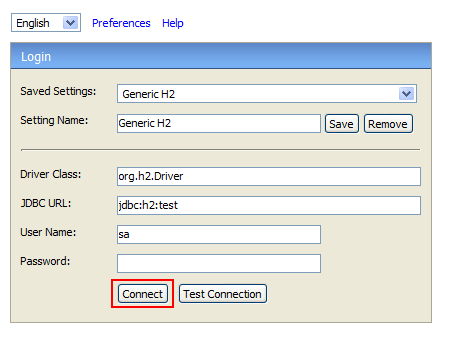
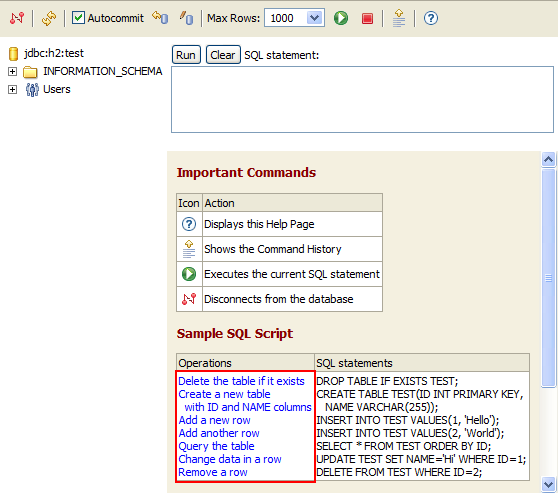
r2dbc-h3是r2dbc spi的一種實現。同樣的使用r2dbc-h3也提供了兩種h3的模式,一種是文件系統,一種是內存。
同時還提供了事務支持,prepared statements和batch statements等特性的支持。
要想使用r2dbc-h3,我們需要添加如下依賴:
<dependency>
<groupId>io.r2dbc</groupId>
<artifactId>r2dbc-h3</artifactId>
<version>${version}</version>
</dependency>如果你體驗snapshot版本,可以添加下面的依賴:
<dependency>
<groupId>io.r2dbc</groupId>
<artifactId>r2dbc-h3</artifactId>
<version>${version}.BUILD-SNAPSHOT</version>
</dependency>
<repository>
<id>spring-libs-snapshot</id>
<name>Spring Snapshot Repository</name>
<url>https://repo.spring.io/libs-snapshot</url>
</repository>h3有兩種連接方式,file和內存,我們分別看一下都是怎么建立連接的:
ConnectionFactory connectionFactory = ConnectionFactories.get("r2dbc:h3:mem:///testdb");
Publisher<? extends Connection> connectionPublisher = connectionFactory.create();ConnectionFactory connectionFactory = ConnectionFactories.get("r2dbc:h3:file//my/relative/path");
Publisher<? extends Connection> connectionPublisher = connectionFactory.create();我們還可以通過ConnectionFactoryOptions來創建更加詳細的連接信息:
ConnectionFactoryOptions options = builder() .option(DRIVER, "h3") .option(PROTOCOL, "...") // file, mem .option(HOST, "…") .option(USER, "…") .option(PASSWORD, "…") .option(DATABASE, "…") .build(); ConnectionFactory connectionFactory = ConnectionFactories.get(options); Publisher<? extends Connection> connectionPublisher = connectionFactory.create(); // Alternative: Creating a Mono using Project Reactor Mono<Connection> connectionMono = Mono.from(connectionFactory.create());
上面的例子中,我們使用到了driver,protocol, host,username,password和database這幾個選項,除此之外H2ConnectionOption中定義了其他可以使用的Option:
public enum H2ConnectionOption {
/**
* FILE|SOCKET|NO
*/
FILE_LOCK,
/**
* TRUE|FALSE
*/
IFEXISTS,
/**
* Seconds to stay open or {[@literal](https://my.oschina.net/u/2966482) -1} to to keep in-memory DB open as long as the virtual machine is alive.
*/
DB_CLOSE_DELAY,
/**
* TRUE|FALSE
*/
DB_CLOSE_ON_EXIT,
/**
* DML or DDL commands on startup, use "\\;" to chain multiple commands
*/
INIT,
/**
* 0..3 (0=OFF, 1=ERROR, 2=INFO, 3=DEBUG)
*/
TRACE_LEVEL_FILE,
/**
* Megabytes (to override the 16mb default, e.g. 64)
*/
TRACE_MAX_FILE_SIZE,
/**
* 0..3 (0=OFF, 1=ERROR, 2=INFO, 3=DEBUG)
*/
TRACE_LEVEL_SYSTEM_OUT,
LOG,
/**
* TRUE|FALSE
*/
IGNORE_UNKNOWN_SETTINGS,
/**
* r|rw|rws|rwd (r=read, rw=read/write)
*/
ACCESS_MODE_DATA,
/**
* DB2|Derby|HSQLDB|MSSQLServer|MySQL|Oracle|PostgreSQL|Ignite
*/
MODE,
/**
* TRUE|FALSE
*/
AUTO_SERVER,
/**
* A port number
*/
AUTO_SERVER_PORT,
/**
* Bytes (e.g. 512)
*/
PAGE_SIZE,
/**
* Number of threads (e.g. 4)
*/
MULTI_THREADED,
/**
* TQ|SOFT_LRU
*/
CACHE_TYPE,
/**
* TRUE|FALSE
*/
PASSWORD_HASH;
}當然還有最直接的database選項:
r2dbc:h3:file//../relative/file/name r2dbc:h3:file///absolute/file/name r2dbc:h3:mem:///testdb
我們還可以通過H2特有的代碼H2ConnectionFactory來創建:
H2ConnectionFactory connectionFactory = new H2ConnectionFactory(H2ConnectionConfiguration.builder()
.inMemory("...")
.option(H2ConnectionOption.DB_CLOSE_DELAY, "-1")
.build());
Mono<Connection> connection = connectionFactory.create();CloseableConnectionFactory connectionFactory = H2ConnectionFactory.inMemory("testdb");
Mono<Connection> connection = connectionFactory.create();在使用prepare statement的時候,我們需要進行參數綁定:
connection
.createStatement("INSERT INTO person (id, first_name, last_name) VALUES ($1, $2, $3)")
.bind("$1", 1)
.bind("$2", "Walter")
.bind("$3", "White")
.execute()除了$符號綁定之外,還支持index綁定,如下所示:
Statement statement = connection.createStatement("SELECT title FROM books WHERE author = $1 and publisher = $2");
statement.bind(0, "John Doe");
statement.bind(1, "Happy Books LLC");我們來看下r2dbc-h3是怎么來進行批處理的:
Batch batch = connection.createBatch();
Publisher<? extends Result> publisher = batch.add("SELECT title, author FROM books")
.add("INSERT INTO books VALUES('John Doe', 'HappyBooks LLC')")
.execute();r2dbc還支持事務和savepoint,我們可以在事務中rollback到特定的savepoint。具體的代碼如下:
Publisher<Void> begin = connection.beginTransaction();
Publisher<Void> insert1 = connection.createStatement("INSERT INTO books VALUES ('John Doe')").execute();
Publisher<Void> savepoint = connection.createSavepoint("savepoint");
Publisher<Void> insert2 = connection.createStatement("INSERT INTO books VALUES ('Jane Doe')").execute();
Publisher<Void> partialRollback = connection.rollbackTransactionToSavepoint("savepoint");
Publisher<Void> commit = connection.commit();感謝各位的閱讀,以上就是“什么是h2和r2dbc-h2”的內容了,經過本文的學習后,相信大家對什么是h2和r2dbc-h2這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





