溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“MySQL中怎么刪庫”,在日常操作中,相信很多人在MySQL中怎么刪庫問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”MySQL中怎么刪庫”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
傳統的高可用架構是不能預防誤刪數據的,因為主庫的一個drop table命令,會通過binlog傳給所有從庫和級聯從庫,進而導致整個集群的實例都會執行這個命令。
雖然我們之前遇到的大多數的數據被刪,都是運維同學或者DBA背鍋的。但實際上,只要有數據操作權限的同學,都有可能踩到誤刪數據這條線。
今天我們就來聊聊誤刪數據前后,我們可以做些什么,減少誤刪數據的風險,和由誤刪數據帶來的損失。
為了找到解決誤刪數據的更高效的方法,我們需要先對和MySQL相關的誤刪數據,做下分類:
使用delete語句誤刪數據行;
使用drop table或者truncate table語句誤刪數據表;
使用drop database語句誤刪數據庫;
使用rm命令誤刪整個MySQL實例。
如果是使用delete語句誤刪了數據行,可以用Flashback工具通過閃回把數據恢復回來。
Flashback恢復數據的原理,是修改binlog的內容,拿回原庫重放。而能夠使用這個方案的前提是,需要確保binlog_format=row 和 binlog_row_image=FULL。
具體恢復數據時,對單個事務做如下處理:
對于insert語句,對應的binlog event類型是Write_rows event,把它改成Delete_rows event即可;
同理,對于delete語句,也是將Delete_rows event改為Write_rows event;
而如果是Update_rows的話,binlog里面記錄了數據行修改前和修改后的值,對調這兩行的位置即可。
如果誤操作不是一個,而是多個,會怎么樣呢?比如下面三個事務:
(A)delete ... (B)insert ... (C)update ...
現在要把數據庫恢復回這三個事務操作之前的狀態,用Flashback工具解析binlog后,寫回主庫的命令是:
(reverse C)update ... (reverse B)delete ... (reverse A)insert ...
也就是說,如果誤刪數據涉及到了多個事務的話,需要將事務的順序調過來再執行。
需要說明的是,我不建議你直接在主庫上執行這些操作。
恢復數據比較安全的做法,是恢復出一個備份,或者找一個從庫作為臨時庫,在這個臨時庫上執行這些操作,然后再將確認過的臨時庫的數據,恢復回主庫。
為什么要這么做呢?
這是因為,一個在執行線上邏輯的主庫,數據狀態的變更往往是有關聯的。可能由于發現數據問題的時間晚了一點兒,就導致已經在之前誤操作的基礎上,業務代碼邏輯又繼續修改了其他數據。所以,如果這時候單獨恢復這幾行數據,而又未經確認的話,就可能會出現對數據的二次破壞。
當然,我們不止要說誤刪數據的事后處理辦法,更重要是要做到事前預防。我有以下兩個建議:
把sql_safe_updates參數設置為on。這樣一來,如果我們忘記在delete或者update語句中寫where條件,或者where條件里面沒有包含索引字段的話,這條語句的執行就會報錯。
代碼上線前,必須經過SQL審計。
你可能會說,設置了sql_safe_updates=on,如果我真的要把一個小表的數據全部刪掉,應該怎么辦呢?
如果你確定這個刪除操作沒問題的話,可以在delete語句中加上where條件,比如where id>=0。
但是,delete全表是很慢的,需要生成回滾日志、寫redo、寫binlog。所以,從性能角度考慮,你應該優先考慮使用truncate table或者drop table命令。
使用delete命令刪除的數據,你還可以用Flashback來恢復。而使用truncate /drop table和drop database命令刪除的數據,就沒辦法通過Flashback來恢復了。為什么呢?
這是因為,即使我們配置了binlog_format=row,執行這三個命令時,記錄的binlog還是statement格式。binlog里面就只有一個truncate/drop 語句,這些信息是恢復不出數據的。
那么,如果我們真的是使用這幾條命令誤刪數據了,又該怎么辦呢?
這種情況下,要想恢復數據,就需要使用全量備份,加增量日志的方式了。這個方案要求線上有定期的全量備份,并且實時備份binlog。
在這兩個條件都具備的情況下,假如有人中午12點誤刪了一個庫,恢復數據的流程如下:
取最近一次全量備份,假設這個庫是一天一備,上次備份是當天0點;
用備份恢復出一個臨時庫;
從日志備份里面,取出凌晨0點之后的日志;
把這些日志,除了誤刪除數據的語句外,全部應用到臨時庫。
這個流程的示意圖如下所示:
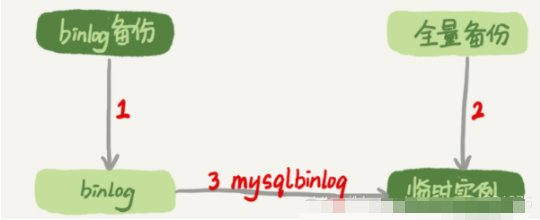
圖1 數據恢復流程-mysqlbinlog方法
關于這個過程,我需要和你說明如下幾點:
為了加速數據恢復,如果這個臨時庫上有多個數據庫,你可以在使用mysqlbinlog命令時,加上一個–database參數,用來指定誤刪表所在的庫。這樣,就避免了在恢復數據時還要應用其他庫日志的情況。
在應用日志的時候,需要跳過12點誤操作的那個語句的binlog:
如果原實例沒有使用GTID模式,只能在應用到包含12點的binlog文件的時候,先用–stop-position參數執行到誤操作之前的日志,然后再用–start-position從誤操作之后的日志繼續執行;
如果實例使用了GTID模式,就方便多了。假設誤操作命令的GTID是gtid1,那么只需要執行set gtid_next=gtid1;begin;commit; 先把這個GTID加到臨時實例的GTID集合,之后按順序執行binlog的時候,就會自動跳過誤操作的語句。
不過,即使這樣,使用mysqlbinlog方法恢復數據還是不夠快,主要原因有兩個:
如果是誤刪表,最好就是只恢復出這張表,也就是只重放這張表的操作,但是mysqlbinlog工具并不能指定只解析一個表的日志;
用mysqlbinlog解析出日志應用,應用日志的過程就只能是單線程。我們前文中介紹的那些并行復制的方法,在這里都用不上。
一種加速的方法是,在用備份恢復出臨時實例之后,將這個臨時實例設置成線上備庫的從庫,這樣:
在start slave之前,先通過執行?
?change replication filter replicate_do_table = (tbl_name) 命令,就可以讓臨時庫只同步誤操作的表;
這樣做也可以用上并行復制技術,來加速整個數據恢復過程。
這個過程的示意圖如下所示。
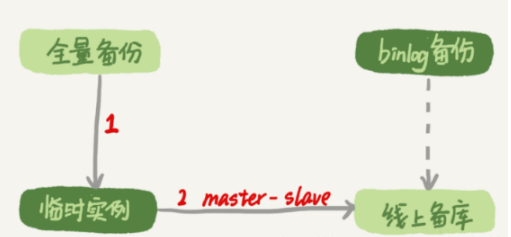
圖2 數據恢復流程-master-slave方法
可以看到,圖中binlog備份系統到線上備庫有一條虛線,是指如果由于時間太久,備庫上已經刪除了臨時實例需要的binlog的話,我們可以從binlog備份系統中找到需要的binlog,再放回備庫中。
假設,我們發現當前臨時實例需要的binlog是從master.000005開始的,但是在備庫上執行show binlogs 顯示的最小的binlog文件是master.000007,意味著少了兩個binlog文件。這時,我們就需要去binlog備份系統中找到這兩個文件。
把之前刪掉的binlog放回備庫的操作步驟,是這樣的:
從備份系統下載master.000005和master.000006這兩個文件,放到備庫的日志目錄下;
打開日志目錄下的master.index文件,在文件開頭加入兩行,內容分別是 “./master.000005”和“./master.000006”;
重啟備庫,目的是要讓備庫重新識別這兩個日志文件;
現在這個備庫上就有了臨時庫需要的所有binlog了,建立主備關系,就可以正常同步了。
不論是把mysqlbinlog工具解析出的binlog文件應用到臨時庫,還是把臨時庫接到備庫上,這兩個方案的共同點是:誤刪庫或者表后,恢復數據的思路主要就是通過備份,再加上應用binlog的方式。
也就是說,這兩個方案都要求備份系統定期備份全量日志,而且需要確保binlog在被從本地刪除之前已經做了備份。
但是,一個系統不可能備份無限的日志,你還需要根據成本和磁盤空間資源,設定一個日志保留的天數。如果你的DBA團隊告訴你,可以保證把某個實例恢復到半個月內的任意時間點,這就表示備份系統保留的日志時間就至少是半個月。
另外,我建議你不論使用上述哪種方式,都要把這個數據恢復功能做成自動化工具,并且經常拿出來演練。為什么這么說呢?
這里的原因,主要包括兩個方面:
雖然“發生這種事,大家都不想的”,但是萬一出現了誤刪事件,能夠快速恢復數據,將損失降到最小,也應該不用跑路了。
而如果臨時再手忙腳亂地手動操作,最后又誤操作了,對業務造成了二次傷害,那就說不過去了。
雖然我們可以通過利用并行復制來加速恢復數據的過程,但是這個方案仍然存在“恢復時間不可控”的問題。
如果一個庫的備份特別大,或者誤操作的時間距離上一個全量備份的時間較長,比如一周一備的實例,在備份之后的第6天發生誤操作,那就需要恢復6天的日志,這個恢復時間可能是要按天來計算的。
那么,我們有什么方法可以縮短恢復數據需要的時間呢?
如果有非常核心的業務,不允許太長的恢復時間,我們可以考慮搭建延遲復制的備庫。這個功能是MySQL 5.6版本引入的。
一般的主備復制結構存在的問題是,如果主庫上有個表被誤刪了,這個命令很快也會被發給所有從庫,進而導致所有從庫的數據表也都一起被誤刪了。
延遲復制的備庫是一種特殊的備庫,通過 CHANGE MASTER TO MASTER_DELAY = N命令,可以指定這個備庫持續保持跟主庫有N秒的延遲。
比如你把N設置為3600,這就代表了如果主庫上有數據被誤刪了,并且在1小時內發現了這個誤操作命令,這個命令就還沒有在這個延遲復制的備庫執行。這時候到這個備庫上執行stop slave,再通過之前介紹的方法,跳過誤操作命令,就可以恢復出需要的數據。
這樣的話,你就隨時可以得到一個,只需要最多再追1小時,就可以恢復出數據的臨時實例,也就縮短了整個數據恢復需要的時間。
雖然常在河邊走,很難不濕鞋,但終究還是可以找到一些方法來避免的。所以這里,我也會給你一些減少誤刪操作風險的建議。
第一條建議是,賬號分離。這樣做的目的是,避免寫錯命令。比如:
我們只給業務開發同學DML權限,而不給truncate/drop權限。而如果業務開發人員有DDL需求的話,也可以通過開發管理系統得到支持。
即使是DBA團隊成員,日常也都規定只使用只讀賬號,必要的時候才使用有更新權限的賬號。
第二條建議是,制定操作規范。這樣做的目的,是避免寫錯要刪除的表名。比如:
在刪除數據表之前,必須先對表做改名操作。然后,觀察一段時間,確保對業務無影響以后再刪除這張表。
改表名的時候,要求給表名加固定的后綴(比如加_to_be_deleted),然后刪除表的動作必須通過管理系統執行。并且,管理系刪除表的時候,只能刪除固定后綴的表。
其實,對于一個有高可用機制的MySQL集群來說,最不怕的就是rm刪除數據了。只要不是惡意地把整個集群刪除,而只是刪掉了其中某一個節點的數據的話,HA系統就會開始工作,選出一個新的主庫,從而保證整個集群的正常工作。
這時,你要做的就是在這個節點上把數據恢復回來,再接入整個集群。
當然了,現在不止是DBA有自動化系統,SA(系統管理員)也有自動化系統,所以也許一個批量下線機器的操作,會讓你整個MySQL集群的所有節點都全軍覆沒。
應對這種情況,我的建議只能是說盡量把你的備份跨機房,或者最好是跨城市保存。
今天,我和你討論了誤刪數據的幾種可能,以及誤刪后的處理方法。
但,我要強調的是,預防遠比處理的意義來得大。
另外,在MySQL的集群方案中,會時不時地用到備份來恢復實例,因此定期檢查備份的有效性也很有必要。
如果你是業務開發同學,你可以用show grants命令查看賬戶的權限,如果權限過大,可以建議DBA同學給你分配權限低一些的賬號;你也可以評估業務的重要性,和DBA商量備份的周期、是否有必要創建延遲復制的備庫等等。
數據和服務的可靠性不止是運維團隊的工作,最終是各個環節一起保障的結果。
在MySQL中有兩個kill命令:一個是kill query +線程id,表示終止這個線程中正在執行的語句;一個是kill connection +線程id,這里connection可缺省,表示斷開這個線程的連接,當然如果這個線程有語句正在執行,也是要先停止正在執行的語句的。
不知道你在使用MySQL的時候,有沒有遇到過這樣的現象:使用了kill命令,卻沒能斷開這個連接。再執行show processlist命令,看到這條語句的Command列顯示的是Killed。
你一定會奇怪,顯示為Killed是什么意思,不是應該直接在show processlist的結果里看不到這個線程了嗎?
今天,我們就來討論一下這個問題。其實大多數情況下,kill query/connection命令是有效的。比如,執行一個查詢的過程中,發現執行時間太久,要放棄繼續查詢,這時我們就可以用kill query命令,終止這條查詢語句。
還有一種情況是,語句處于鎖等待的時候,直接使用kill命令也是有效的。我們一起來看下這個例子:
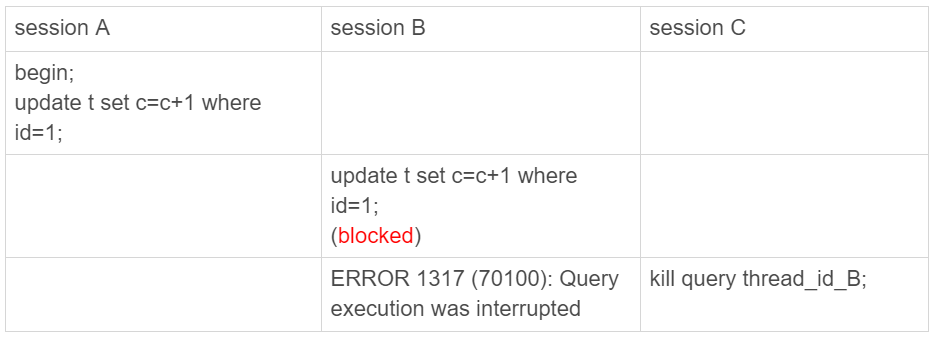
圖1 kill query 成功的例子
可以看到,session C 執行kill query以后,session B幾乎同時就提示了語句被中斷。這,就是我們預期的結果。
但是,這里你要停下來想一下:session B是直接終止掉線程,什么都不管就直接退出嗎?顯然,這是不行的。
當對一個表做增刪改查操作時,會在表上加MDL讀鎖。所以,session B雖然處于blocked狀態,但還是拿著一個MDL讀鎖的。如果線程被kill的時候,就直接終止,那之后這個MDL讀鎖就沒機會被釋放了。
這樣看來,kill并不是馬上停止的意思,而是告訴執行線程說,這條語句已經不需要繼續執行了,可以開始“執行停止的邏輯了”。
其實,這跟Linux的kill命令類似,kill -N pid并不是讓進程直接停止,而是給進程發一個信號,然后進程處理這個信號,進入終止邏輯。只是對于MySQL的kill命令來說,不需要傳信號量參數,就只有“停止”這個命令。
實現上,當用戶執行kill query thread_id_B時,MySQL里處理kill命令的線程做了兩件事:
把session B的運行狀態改成THD::KILL_QUERY(將變量killed賦值為THD::KILL_QUERY);
給session B的執行線程發一個信號。
為什么要發信號呢?
因為像圖1的我們例子里面,session B處于鎖等待狀態,如果只是把session B的線程狀態設置THD::KILL_QUERY,線程B并不知道這個狀態變化,還是會繼續等待。發一個信號的目的,就是讓session B退出等待,來處理這個THD::KILL_QUERY狀態。
上面的分析中,隱含了這么三層意思:
一個語句執行過程中有多處“埋點”,在這些“埋點”的地方判斷線程狀態,如果發現線程狀態是THD::KILL_QUERY,才開始進入語句終止邏輯;
如果處于等待狀態,必須是一個可以被喚醒的等待,否則根本不會執行到“埋點”處;
語句從開始進入終止邏輯,到終止邏輯完全完成,是有一個過程的。
到這里你就知道了,原來不是“說停就停的”。
接下來,我們再看一個kill不掉的例子,也就是我們在前面提到的 innodb_thread_concurrency 不夠用的例子。
首先,執行set global innodb_thread_concurrency=2,將InnoDB的并發線程上限數設置為2;然后,執行下面的序列:
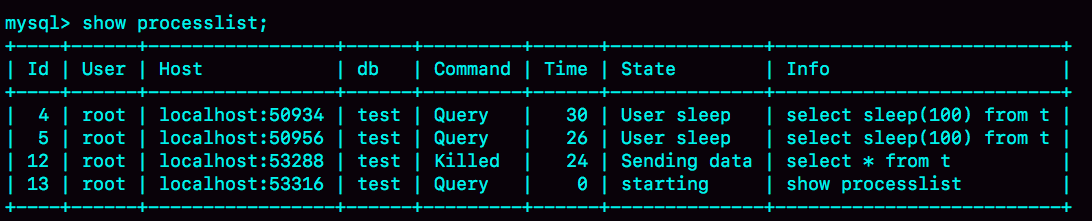
圖 3 kill connection之后的效果
這時候,id=12這個線程的Commnad列顯示的是Killed。也就是說,客戶端雖然斷開了連接,但實際上服務端上這條語句還在執行過程中。
為什么在執行kill query命令時,這條語句不像第一個例子的update語句一樣退出呢?
在實現上,等行鎖時,使用的是pthread_cond_timedwait函數,這個等待狀態可以被喚醒。但是,在這個例子里,12號線程的等待邏輯是這樣的:每10毫秒判斷一下是否可以進入InnoDB執行,如果不行,就調用nanosleep函數進入sleep狀態。
也就是說,雖然12號線程的狀態已經被設置成了KILL_QUERY,但是在這個等待進入InnoDB的循環過程中,并沒有去判斷線程的狀態,因此根本不會進入終止邏輯階段。
而當session E執行kill connection 命令時,是這么做的,
把12號線程狀態設置為KILL_CONNECTION;
關掉12號線程的網絡連接。因為有這個操作,所以你會看到,這時候session C收到了斷開連接的提示。
那為什么執行show processlist的時候,會看到Command列顯示為killed呢?其實,這就是因為在執行show processlist的時候,有一個特別的邏輯:
如果一個線程的狀態是KILL_CONNECTION,就把Command列顯示成Killed。
所以其實,即使是客戶端退出了,這個線程的狀態仍然是在等待中。那這個線程什么時候會退出呢?
答案是,只有等到滿足進入InnoDB的條件后,session C的查詢語句繼續執行,然后才有可能判斷到線程狀態已經變成了KILL_QUERY或者KILL_CONNECTION,再進入終止邏輯階段。
到這里,我們來小結一下。
這個例子是kill無效的第一類情況,即:線程沒有執行到判斷線程狀態的邏輯。跟這種情況相同的,還有由于IO壓力過大,讀寫IO的函數一直無法返回,導致不能及時判斷線程的狀態。
另一類情況是,終止邏輯耗時較長。這時候,從show processlist結果上看也是Command=Killed,需要等到終止邏輯完成,語句才算真正完成。這類情況,比較常見的場景有以下幾種:
超大事務執行期間被kill。這時候,回滾操作需要對事務執行期間生成的所有新數據版本做回收操作,耗時很長。
大查詢回滾。如果查詢過程中生成了比較大的臨時文件,加上此時文件系統壓力大,刪除臨時文件可能需要等待IO資源,導致耗時較長。
DDL命令執行到最后階段,如果被kill,需要刪除中間過程的臨時文件,也可能受IO資源影響耗時較久。
之前有人問過我,如果直接在客戶端通過Ctrl+C命令,是不是就可以直接終止線程呢?
答案是,不可以。
這里有一個誤解,其實在客戶端的操作只能操作到客戶端的線程,客戶端和服務端只能通過網絡交互,是不可能直接操作服務端線程的。
而由于MySQL是停等協議,所以這個線程執行的語句還沒有返回的時候,再往這個連接里面繼續發命令也是沒有用的。實際上,執行Ctrl+C的時候,是MySQL客戶端另外啟動一個連接,然后發送一個kill query 命令。
所以,你可別以為在客戶端執行完Ctrl+C就萬事大吉了。因為,要kill掉一個線程,還涉及到后端的很多操作。
在實際使用中,我也經常會碰到一些同學對客戶端的使用有誤解。接下來,我們就來看看兩個最常見的誤解。
第一個誤解是:如果庫里面的表特別多,連接就會很慢。
有些線上的庫,會包含很多表(我見過最多的一個庫里有6萬個表)。這時候,你就會發現,每次用客戶端連接都會卡在下面這個界面上。
而如果db1這個庫里表很少的話,連接起來就會很快,可以很快進入輸入命令的狀態。因此,有同學會認為是表的數目影響了連接性能。
從開始你就知道,每個客戶端在和服務端建立連接的時候,需要做的事情就是TCP握手、用戶校驗、獲取權限。但這幾個操作,顯然跟庫里面表的個數無關。
但實際上,正如圖中的文字提示所說的,當使用默認參數連接的時候,MySQL客戶端會提供一個本地庫名和表名補全的功能。為了實現這個功能,客戶端在連接成功后,需要多做一些操作:
執行show databases;
切到db1庫,執行show tables;
把這兩個命令的結果用于構建一個本地的哈希表。
在這些操作中,最花時間的就是第三步在本地構建哈希表的操作。所以,當一個庫中的表個數非常多的時候,這一步就會花比較長的時間。
也就是說,我們感知到的連接過程慢,其實并不是連接慢,也不是服務端慢,而是客戶端慢。
圖中的提示也說了,如果在連接命令中加上-A,就可以關掉這個自動補全的功能,然后客戶端就可以快速返回了。
這里自動補全的效果就是,你在輸入庫名或者表名的時候,輸入前綴,可以使用Tab鍵自動補全表名或者顯示提示。
實際使用中,如果你自動補全功能用得并不多,我建議你每次使用的時候都默認加-A。
其實提示里面沒有說,除了加-A以外,加–quick(或者簡寫為-q)參數,也可以跳過這個階段。但是,這個–quick是一個更容易引起誤會的參數,也是關于客戶端常見的一個誤解。
你看到這個參數,是不是覺得這應該是一個讓服務端加速的參數?但實際上恰恰相反,設置了這個參數可能會降低服務端的性能。為什么這么說呢?
MySQL客戶端發送請求后,接收服務端返回結果的方式有兩種:
一種是本地緩存,也就是在本地開一片內存,先把結果存起來。如果你用API開發,對應的就是mysql_store_result 方法。
另一種是不緩存,讀一個處理一個。如果你用API開發,對應的就是mysql_use_result方法。
MySQL客戶端默認采用第一種方式,而如果加上–quick參數,就會使用第二種不緩存的方式。
采用不緩存的方式時,如果本地處理得慢,就會導致服務端發送結果被阻塞,因此會讓服務端變慢。關于服務端的具體行為,我會在下一篇文章再和你展開說明。
那你會說,既然這樣,為什么要給這個參數取名叫作quick呢?這是因為使用這個參數可以達到以下三點效果:
第一點,就是前面提到的,跳過表名自動補全功能。
第二點,mysql_store_result需要申請本地內存來緩存查詢結果,如果查詢結果太大,會耗費較多的本地內存,可能會影響客戶端本地機器的性能;
第三點,是不會把執行命令記錄到本地的命令歷史文件。
所以你看到了,–quick參數的意思,是讓客戶端變得更快。
到此,關于“MySQL中怎么刪庫”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





