溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“什么是SafePoint與Stop The World”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“什么是SafePoint與Stop The World”吧!
在分析線上 JVM 性能問題的時候,我們可能會碰到下面這些場景:
1.GC 本身沒有花多長時間,但是 JVM 暫停了很久,例如下面:
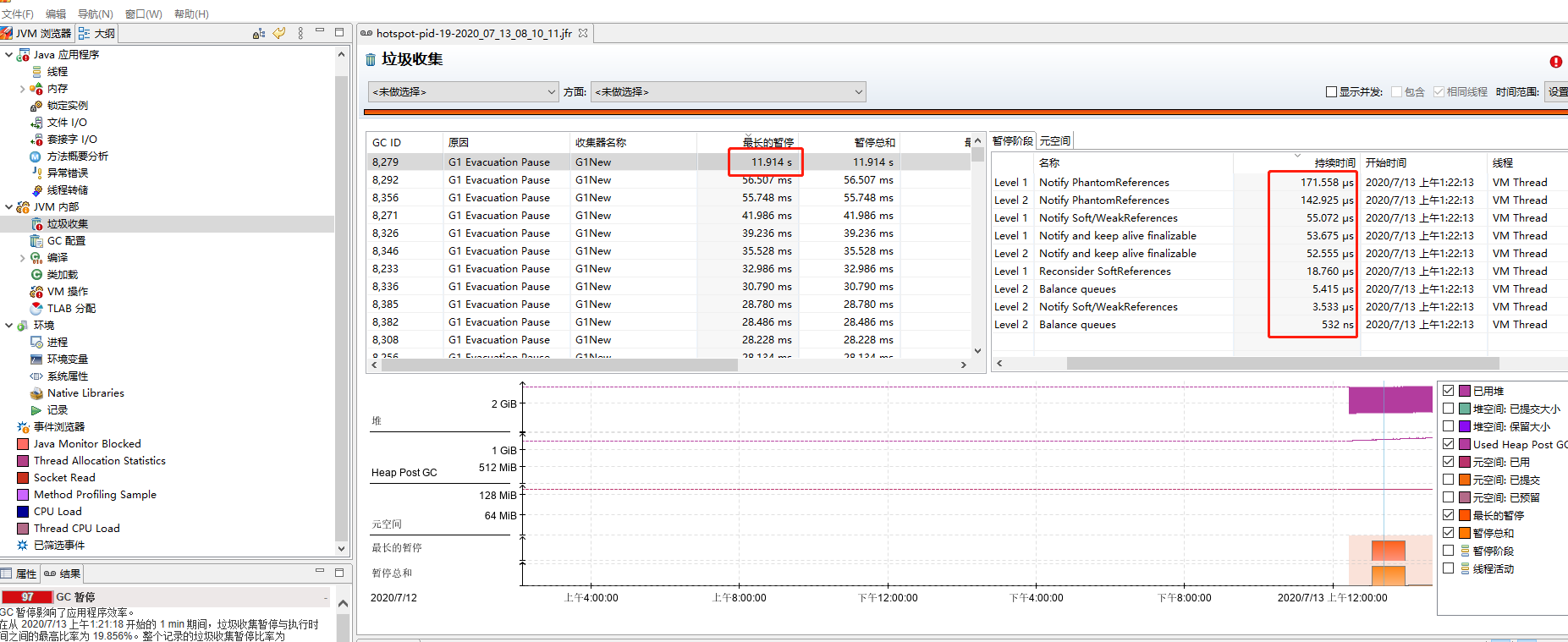
2.JVM 沒有 GC,但是程序暫停了很久,而且這種情況時不時就出現。
這些問題一般和 SafePoint 還有 Stop the World 有關。
我們先來設想下如下場景:
當需要 GC 時,需要知道哪些對象還被使用,或者已經不被使用可以回收了,這樣就需要每個線程的對象使用情況。
對于偏向鎖(Biased Lock),在高并發時想要解除偏置,需要線程狀態還有獲取鎖的線程的精確信息。
對方法進行即時編譯優化(OSR棧上替換),或者反優化(bailout棧上反優化),這需要線程究竟運行到方法的哪里的信息。
對于這些操作,都需要線程的各種信息,例如寄存器中到底有啥,堆使用信息以及棧方法代碼信息等等等等,并且做這些操作的時候,線程需要暫停,等到這些操作完成,否則會有并發問題。這就需要 SafePoint。
Safepoint 可以理解成是在代碼執行過程中的一些特殊位置,當線程執行到這些位置的時候,線程可以暫停。在 SafePoint 保存了其他位置沒有的一些當前線程的運行信息,供其他線程讀取。這些信息包括:線程上下文的任何信息,例如對象或者非對象的內部指針等等。我們一般這么理解 SafePoint,就是線程只有運行到了 SafePoint 的位置,他的一切狀態信息,才是確定的,也只有這個時候,才知道這個線程用了哪些內存,沒有用哪些;并且,只有線程處于 SafePoint 位置,這時候對 JVM 的堆棧信息進行修改,例如回收某一部分不用的內存,線程才會感知到,之后繼續運行,每個線程都有一份自己的內存使用快照,這時候其他線程對于內存使用的修改,線程就不知道了,只有再進行到 SafePoint 的時候,才會感知。
所以,GC 一定需要所有線程同時進入 SafePoint,并停留在那里,等待 GC 處理完內存,再讓所有線程繼續執。像這種**所有線程進入 SafePoint **等待的情況,就是 Stop the world(此時,突然想起承太郎的:食堂潑辣醬,the world!!!)。
在 SafePoint 位置保存了線程上下文中的任何東西,包括對象,指向對象或非對象的內部指針,在線程處于 SafePoint 的時候,對這些信息進行修改,線程才能感知到。所以,只有線程處于 SafePoint 的時候,才能針對線程使用的內存進行 GC,以及改變正在執行的代碼,例如 OSR (On Stack Replacement,棧上替換現有代碼為JIT優化過的代碼)或者 Bailout(棧上替換JIT過優化代碼為去優化的代碼)。并且,還有一個重要的 Java 線程特性也是基于 SafePoint 實現的,那就是 Thread.interrupt(),線程只有運行到 SafePoint 才知道是否 interrupted。
為啥需要 Stop The World,有時候我們需要全局所有線程進入 SafePoint 這樣才能統計出那些內存還可以回收用于 GC,,以及回收不再使用的代碼清理 CodeCache,以及執行某些 Java instrument 命令或者 JDK 工具,例如 jstack 打印堆棧就需要 Stop the world 獲取當前所有線程快照。
可以這么理解,SafePoint 可以插入到代碼的某些位置,每個線程運行到 SafePoint 代碼時,主動去檢查是否需要進入 SafePoint,這個主動檢查的過程,被稱為 Polling
理論上,可以在每條 Java 編譯后的字節碼的邊界,都放一個檢查 Safepoint 的機器命令。線程執行到這里的時候,會執行 Polling 詢問 JVM 是否需要進入 SafePoint,這個詢問是會有性能損耗的,所以 JIT 會優化盡量減少 SafePoint。
經過 JIT 編譯優化的代碼,會在所有方法的返回之前,以及所有非counted loop的循環(無界循環)回跳之前放置一個 SafePoint,為了防止發生 GC 需要 Stop the world 時,該線程一直不能暫停,但是對于明確有界循環,為了減少 SafePoint,是不會在回跳之前放置一個 SafePoint,也就是:
for (int i = 0; i < 100000000; i++) {
...
}里面是不會放置 SafePoint 的,這也導致了后面會提到的一些性能優化的問題。注意,僅針對 int 有界循環,例如里面的 int i 換成 long i 就還是會有 SafePoint;
SafePoint 實現相關源代碼: safepoint.cpp
可以看出,針對 SafePoint,線程有 5 種情況;假設現在有一個操作觸發了某個 VM 線程所有線程需要進入 SafePoint(例如現在需要 GC),如果其他線程現在:
運行字節碼:運行字節碼時,解釋器會看線程是否被標記為 poll armed,如果是,VM 線程調用 SafepointSynchronize::block(JavaThread *thread)進行 block。
運行 native 代碼:當運行 native 代碼時,VM 線程略過這個線程,但是給這個線程設置 poll armed,讓它在執行完 native 代碼之后,它會檢查是否 poll armed,如果還需要停在 SafePoint,則直接 block。
運行 JIT 編譯好的代碼:由于運行的是編譯好的機器碼,直接查看本地 local polling page 是否為臟,如果為臟則需要 block。這個特性是在 Java 10 引入的 JEP 312: Thread-Local Handshakes 之后,才是只用檢查本地 local polling page 是否為臟就可以了。
處于 BLOCK 狀態:在需要所有線程需要進入 SafePoint 的操作完成之前,不許離開 BLOCK 狀態
處于線程切換狀態或者處于 VM 運行狀態:會一直輪詢線程狀態直到線程處于阻塞狀態(線程肯定會變成上面說的那四種狀態,變成哪個都會 block 住)。
定時進入 SafePoint:每經過-XX:GuaranteedSafepointInterval 配置的時間,都會讓所有線程進入 Safepoint,一旦所有線程都進入,立刻從 Safepoint 恢復。這個定時主要是為了一些沒必要立刻 Stop the world 的任務執行,可以設置-XX:GuaranteedSafepointInterval=0關閉這個定時,我推薦是關閉。
由于 jstack,jmap 和 jstat 等命令,也就是 Signal Dispatcher 線程要處理的大部分命令,都會導致 Stop the world:這種命令都需要采集堆棧信息,所以需要所有線程進入 Safepoint 并暫停。
偏向鎖取消(這個不一定會引發整體的 Stop the world,參考JEP 312: Thread-Local Handshakes):Java 認為,鎖大部分情況是沒有競爭的(某個同步塊大多數情況都不會出現多線程同時競爭鎖),所以可以通過偏向來提高性能。即在無競爭時,之前獲得鎖的線程再次獲得鎖時,會判斷是否偏向鎖指向我,那么該線程將不用再次獲得鎖,直接就可以進入同步塊。但是高并發的情況下,偏向鎖會經常失效,導致需要取消偏向鎖,取消偏向鎖的時候,需要 Stop the world,因為要獲取每個線程使用鎖的狀態以及運行狀態。
Java Instrument 導致的 Agent 加載以及類的重定義:由于涉及到類重定義,需要修改棧上和這個類相關的信息,所以需要 Stop the world
Java Code Cache相關:當發生 JIT 編譯優化或者去優化,需要 OSR 或者 Bailout 或者清理代碼緩存的時候,由于需要讀取線程執行的方法以及改變線程執行的方法,所以需要 Stop the world
GC:這個由于需要每個線程的對象使用信息,以及回收一些對象,釋放某些堆內存或者直接內存,所以需要 Stop the world
JFR 的一些事件:如果開啟了 JFR 的 OldObject 采集,這個是定時采集一些存活時間比較久的對象,所以需要 Stop the world。同時,JFR 在 dump 的時候,由于每個線程都有一個 JFR 事件的 buffer,需要將 buffer 中的事件采集出來,所以需要 Stop the world。
其他的事件,不經常遇到,可以參考源碼 vmOperations.hpp
#define VM_OPS_DO(template) \ template(None) \ template(Cleanup) \ template(ThreadDump) \ template(PrintThreads) \ template(FindDeadlocks) \ template(ClearICs) \ template(ForceSafepoint) \ template(ForceAsyncSafepoint) \ template(DeoptimizeFrame) \ template(DeoptimizeAll) \ template(ZombieAll) \ template(Verify) \ template(PrintJNI) \ template(HeapDumper) \ template(DeoptimizeTheWorld) \ template(CollectForMetadataAllocation) \ template(GC_HeapInspection) \ template(GenCollectFull) \ template(GenCollectFullConcurrent) \ template(GenCollectForAllocation) \ template(ParallelGCFailedAllocation) \ template(ParallelGCSystemGC) \ template(G1CollectForAllocation) \ template(G1CollectFull) \ template(G1Concurrent) \ template(G1TryInitiateConcMark) \ template(ZMarkStart) \ template(ZMarkEnd) \ template(ZRelocateStart) \ template(ZVerify) \ template(HandshakeOneThread) \ template(HandshakeAllThreads) \ template(HandshakeFallback) \ template(EnableBiasedLocking) \ template(BulkRevokeBias) \ template(PopulateDumpSharedSpace) \ template(JNIFunctionTableCopier) \ template(RedefineClasses) \ template(UpdateForPopTopFrame) \ template(SetFramePop) \ template(GetObjectMonitorUsage) \ template(GetAllStackTraces) \ template(GetThreadListStackTraces) \ template(GetFrameCount) \ template(GetFrameLocation) \ template(ChangeBreakpoints) \ template(GetOrSetLocal) \ template(GetCurrentLocation) \ template(ChangeSingleStep) \ template(HeapWalkOperation) \ template(HeapIterateOperation) \ template(ReportJavaOutOfMemory) \ template(JFRCheckpoint) \ template(ShenandoahFullGC) \ template(ShenandoahInitMark) \ template(ShenandoahFinalMarkStartEvac) \ template(ShenandoahInitUpdateRefs) \ template(ShenandoahFinalUpdateRefs) \ template(ShenandoahDegeneratedGC) \ template(Exit) \ template(LinuxDllLoad) \ template(RotateGCLog) \ template(WhiteBoxOperation) \ template(JVMCIResizeCounters) \ template(ClassLoaderStatsOperation) \ template(ClassLoaderHierarchyOperation) \ template(DumpHashtable) \ template(DumpTouchedMethods) \ template(PrintCompileQueue) \ template(PrintClassHierarchy) \ template(ThreadSuspend) \ template(ThreadsSuspendJVMTI) \ template(ICBufferFull) \ template(ScavengeMonitors) \ template(PrintMetadata) \ template(GTestExecuteAtSafepoint) \ template(JFROldObject) \
Stop the world 階段可以簡單分為(這段時間內,JVM 都是出于所有線程進入 Safepoint 就 block 的狀態):
某個操作,需要 Stop the world(就是上面提到的哪些情況下會讓所有線程進入 SafePoint, 即發生 Stop the world 的那些操作)
向 Signal Dispatcher 這個 JVM 守護線程發起 Safepoint 同步信號并交給對應的模塊執行。
對應的模塊,采集所有線程信息,并對每個線程根據狀態做不同的操作以及標記(根據之前源代碼那一塊的描述,有5種情況)
所有線程都進入 Safepoint 并 block。
做需要發起 Stop the world 的操作。
操作完成,所有線程從 Safepoint 恢復。
基于這些階段,導致 Stop the world 時間過長的原因有:
階段 4 耗時過長,即等待所有線程中的某些線程進入 Safepoint 的時間過長,這個很可能和有 大有界循環與JIT優化 有關,也很可能是 OpenJDK 11 引入的獲取調用堆棧的類StackWalker的使用導致的,也可能是系統 CPU 資源問題或者是系統內存臟頁過多或者發生 swap 導致的。
階段 5 耗時過長,需要看看是哪些操作導致的,例如偏向鎖撤銷過多, GC時間過長等等,需要想辦法減少這些操作消耗的時間,或者直接關閉這些事件(例如關閉偏向鎖,關閉 JFR 的 OldObjectSample 事件采集)減少進入,這個和本篇內容無關,這里不贅述。
階段2,階段3耗時過長,由于 Signal Dispatcher 是單線程的,可以看看當時 Signal Dispatcher 這個線程在干什么,可能是 Signal Dispatcher 做其他操作導致的。也可能是系統 CPU 資源問題或者是系統內存臟頁過多或者發生 swap 導致的。
已知:只有線程執行到 Safepoint 代碼才會知道Thread.intterupted()的最新狀態 ,而不是線程的本地緩存。
我們來看下面一段代碼:
static int algorithm(int n) {
int bestSoFar = 0;
for (int i=0; i<n; ++i) {
if (Thread.interrupted()) {
System.out.println("broken by interrupted");
break;
}
//增加pow計算,增加計算量,防止循環執行不超過1s就結束了
bestSoFar = (int) Math.pow(i, 0.3);
}
return bestSoFar;
}
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
Instant start = Instant.now();
int bestSoFar = algorithm(1000000000);
double durationInMillis = Duration.between(start, Instant.now()).toMillis();
System.out.println("after "+durationInMillis+" ms, the result is "+bestSoFar);
};
//延遲1ms之后interrupt
Thread t = new Thread(task);
t.start();
Thread.sleep(1);
t.interrupt();
//延遲10ms之后interrupt
t = new Thread(task);
t.start();
Thread.sleep(10);
t.interrupt();
//延遲100ms之后interrupt
t = new Thread(task);
t.start();
Thread.sleep(100);
t.interrupt();
//延遲1s之后interrupt
//這時候 algorithm 里面的for循環調用次數應該足夠了,會發生代碼即時編譯優化并 OSR
t = new Thread(task);
t.start();
Thread.sleep(1000);
//發現線程這次不會對 interrupt 有反應了
t.interrupt();
}之后利用 JVM 參數 -Xlog:jit+compilation=debug:file=jit_compile%t.log:uptime,level,tags:filecount=10,filesize=100M 打印 JIT 編譯日志到另一個文件,便于觀察。最后控制臺輸出:
broken by interrupted broken by interrupted after 10.0 ms, the result is 27 after 1.0 ms, the result is 10 broken by interrupted after 99.0 ms, the result is 69 after 29114.0 ms, the result is 501
可以看出,最后一次循環直接運行結束了,并沒有看到線程已經 interrupted 了。并且 JIT 編譯日志可以看到,在最后一線程執行循環的時候發生了發生代碼即時編譯優化并 OSR:
[0.782s][debug][jit,compilation] 460 % 3 com.test.TypeTest::algorithm @ 4 (44 bytes) [0.784s][debug][jit,compilation] 468 3 com.test.TypeTest::algorithm (44 bytes) [0.794s][debug][jit,compilation] 486 % 4 com.test.TypeTest::algorithm @ 4 (44 bytes) [0.797s][debug][jit,compilation] 460 % 3 com.test.TypeTest::algorithm @ 4 (44 bytes) made not entrant [0.799s][debug][jit,compilation] 503 4 com.test.TypeTest::algorithm (44 bytes)
3 還有 4 表示編譯級別,% 表示是 OSR 棧上替換方法,也就是 for 循環還在執行的時候,進行了執行代碼的機器碼替換。在這之后,線程就看不到線程已經 interrupted 了,這說明,** JIT 優化后的代碼,for 循環里面的 Safepoint 會被拿掉**。
這樣帶來的問題,也顯而易見了,當需要 Stop the world 的時候,所有線程都會等著這個循環執行完,因為這個線程只有執行完這個大循環,才能進入 Safepoint。
那么,如何優化呢?
第一種方式是修改代碼,將 for int 的循環變成 for long 類型:
for (long i=0; i<n; ++i) {
if (Thread.interrupted()) {
System.out.println("broken by interrupted");
break;
}
//增加pow計算,增加計算量,防止循環執行不超過1s就結束了
bestSoFar = (int) Math.pow(i, 0.3);
}第二種是通過-XX:+UseCountedLoopSafepoints參數,讓 JIT 優化代碼的時候,不會拿掉有界循環里面的 SafePoint
用這兩種方式其中一種之后的控制臺輸出:
broken by interrupted broken by interrupted after 0.0 ms, the result is 0 after 10.0 ms, the result is 29 broken by interrupted after 100.0 ms, the result is 73 broken by interrupted after 998.0 ms, the result is 170
目前,在 OpenJDK 11 版本,主要有兩種 SafePoint 相關的日志。一種基本上只在開發時使用,另一種可以在線上使用持續采集。
第一個是-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1,這個會定時采集,但是采集的時候會觸發所有線程進入 Safepoint,所以,線程一般不打開(之前我們對于定時讓所有線程進入 Safepoint 都要關閉,這個就更不可能打開了)。并且,在 Java 12 中已經被移除,并且接下來的日志配置基本上可以替代這個,所以這里我們就不贅述這個了。
另外是通過-Xlog:safepoint=trace:stdout:utctime,level,tags,對于 OpenJDK 的日志配置,可以參考我的另一篇文章詳細解析配置的格式,這里我們直接用。
我們這里配置了所有的 safepoint 相關的 JVM 日志都輸出到控制臺,一次 Stop the world 的時候,就會像下面這樣輸出:
[2020-07-14T07:08:26.197+0000][debug][safepoint] Safepoint synchronization initiated. (112 threads) [2020-07-14T07:08:26.197+0000][info ][safepoint] Application time: 12.4565068 seconds [2020-07-14T07:08:26.197+0000][trace][safepoint] Setting thread local yield flag for threads [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c494b30 [0x61dc] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c497f30 [0x4ff8] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 ......省略一些處于 _at_poll_safepoint 的線程 [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.348+0000][trace][safepoint] Thread: 0x0000022c10bfe560 [0x5038] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.197+0000][debug][safepoint] Waiting for 1 thread(s) to block [2020-07-14T07:08:29.348+0000][info ][safepoint] Entering safepoint region: G1CollectForAllocation [2020-07-14T07:08:29.350+0000][info ][safepoint] Leaving safepoint region [2020-07-14T07:08:29.350+0000][info ][safepoint] Total time for which application threads were stopped: 3.1499371 seconds, Stopping threads took: 3.1467255 seconds
首先,階段 1 會打印日志,這個是 debug 級別的,代表要開始全局所有線程 Safepoint 了,這時候,JVM 就開始無法響應請求了,也就是 Stop the world 開始:
[2020-07-14T07:08:29.347+0000][debug][safepoint] Safepoint synchronization initiated. (112 threads)
階段 2 不會打印日志,階段 3 會打印:
[2020-07-14T07:08:26.197+0000][info ][safepoint] Application time: 12.4565068 seconds [2020-07-14T07:08:26.197+0000][trace][safepoint] Setting thread local yield flag for threads [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c494b30 [0x61dc] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c497f30 [0x4ff8] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 ......省略一些處于 _at_poll_safepoint 的線程 [2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.348+0000][trace][safepoint] Thread: 0x0000022c10bfe560 [0x5038] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0 [2020-07-14T07:08:26.197+0000][debug][safepoint] Waiting for 1 thread(s) to block
Application time: 12.4565068 seconds 代表上次全局 Safepoint 與這次 Safepoint 間隔了多長時間。后面 trace 的日志表示每個線程的狀態,其中沒有處于 Safepoint 的只有一個:
Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0
這里有詳細的線程號,可以通過 jstack 知道這個線程是干啥的。
最后的Waiting for 1 thread(s) to block也代表到底需要等待幾個線程走到 Safepoint。
階段 4 執行完,開始階段 5 的時候,會打印:
[2020-07-14T07:08:29.348+0000][info ][safepoint] Entering safepoint region: G1CollectForAllocation
階段 5 執行完之后,會打印:
[2020-07-14T07:08:29.350+0000][info ][safepoint] Leaving safepoint region
最后階段 6 開始的時候,會打印:
[2020-07-14T07:08:29.350+0000][info ][safepoint] Total time for which application threads were stopped: 3.1499371 seconds, Stopping threads took: 3.1467255 seconds
Total time for which application threads were stopped是這次階段1到階段6開始,一共過了多長時間,也就是 Stop the world 多長時間。后面的Stopping threads took是這次等待線程走進 Safepoint 過了多長時間,一般除了 階段 5 執行觸發 Stop the world 以外,都是由于 等待線程走進 Safepoint 時間長。這是就要看 trace 的線程哪些沒有處于 Safepoint,看他們干了什么,是否有大循環,或者是使用了StackWalker這個類.
JFR 相關的配置以及說明以及如何通過 JFR 分析 SafePoint 相關事件,可以參考我的另一個系列JFR全解系列
常見的 SafePoint 調優參數以及講解
建議關閉定時讓所有線程進入 Safepoint
對于微服務高并發應用,沒必要定時進入 Safepoint,所以關閉 -XX:+UnlockDiagnosticVMOptions -XX:GuaranteedSafepointInterval=0
建議取消偏向鎖
在高并發應用中,偏向鎖并不能帶來性能提升,反而因為偏向鎖取消帶來了很多沒必要的某些線程進入Safepoint 或者 Stop the world。所以建議關閉:-XX:-UseBiasedLocking
建議打開循環內添加 Safepoint 參數
防止大循環 JIT 編譯導致內部 Safepoint 被優化省略,導致進入 SafePoint 時間變長:-XX:+UseCountedLoopSafepoints
建議打開 debug 級別的 safepoint 日志(和第五個選一個)
debug 級別雖然看不到每次是哪些線程需要等待進入 Safepoint,但是整體每階段耗時已經很清楚了。如果是 trace 級別,每次都能看到是那些線程,但是這樣每次進入 safepoint 時間就會增加幾毫秒。
-Xlog:safepoint=debug:file=safepoint.log:utctime,level,tags:filecount=50,filesize=100M
建議打開 JFR 關于 safepoint 的采集(和第四個選一個)
修改,或者新建 jfc 文件:
<event name="jdk.SafepointBegin"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.SafepointStateSynchronization"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.SafepointWaitBlocked"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.SafepointCleanup"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.SafepointCleanupTask"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.SafepointEnd"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event> <event name="jdk.ExecuteVMOperation"> <setting name="enabled">true</setting> <setting name="threshold">10 ms</setting> </event>
感謝各位的閱讀,以上就是“什么是SafePoint與Stop The World”的內容了,經過本文的學習后,相信大家對什么是SafePoint與Stop The World這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





