溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了MySQL InnoDB的select和update形成表級鎖實例分析的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇MySQL InnoDB的select和update形成表級鎖實例分析文章都會有所收獲,下面我們一起來看看吧。
InnoDB 的細粒度行鎖以及事務支持一度是 MySQL 最吸引人的特性之二。但是在多種情況下,InnoDB 的行級鎖會變成表級鎖。使用不當,給我們帶來的危害極大!
如果 InnoDB 的查詢沒有命中索引,也將退化為表鎖。InnoDB 的細粒度鎖,是實現在索引記錄上的。
InnoDB 的索引有兩類。聚集索引(Clustered Index)與普通索引(Secondary Index)。
InnoDB 的每一個表都會有聚集索引。如果你沒手動創建,InnoDB 也會默認的幫你創建聚集索引。
聚集索引以下面三種形式存在:
如果表定義了 PK,則 PK 就是聚集索引;
如果表沒有定義 PK,則第一個非空 unique 列是聚集索引;
否則,InnoDB 會創建一個隱藏的 row-id 作為聚集索引。
我們知道索引的結構是 B+ 樹,這里不展開 B+ 樹的細節,先說幾個結論:
在索引結構中,非葉子節點存儲 key,葉子節點存儲 value;
聚集索引,葉子節點存儲行記錄(row);
普通索引,葉子節點存儲了 PK 的值。
由于上面我們說過的 InnoDB 的每一個表都會有聚集索引,索引結構中葉子節點存儲 value,而聚集索引的葉子節點還會存儲行記錄(row)。所以,InnoDB 索引和記錄是存儲在一起的,而 MyISAM 的索引和記錄是分開存儲的。
所以,InnoDB 的普通索引,實際上會掃描兩遍:第一遍,由普通索引找到 PK;第二遍,由PK找到行記錄;
關于索引結構,我這里不展開去講,后面我查詢更多資料后,將給大家詳細的講講 InnoDB/MyISAM 的索引結構,如果大家感興趣的話。
下面我們通過一個例子來說明。假設存在一個下面結構的 InnoDB 表:
1 |
|
表中有四條記錄:
1 2 3 4 |
|
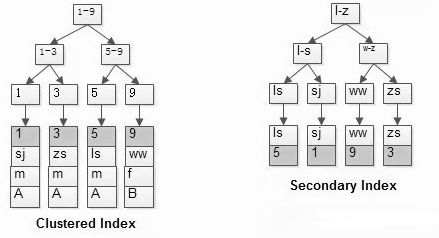
從上圖中可以看到:
第一幅圖,id PK的聚集索引,葉子存儲了所有的行記錄;
第二幅圖,name上的普通索引,葉子存儲了PK的值;
當執行查詢 select * from t where name=’shenjian’; 語句時,會發生下面的過程:
會先在 name 普通索引上查詢到PK=1;
再在聚集索引衫查詢到(1,shenjian, m, A)的行記錄;
再回到文章開頭部分,我們說過“InnoDB 的查詢沒有命中索引,也將退化為表鎖。InnoDB 的細粒度鎖,是實現在索引記錄上的。”由于這里的 name 并沒有創建索引,所以它會變成表鎖。至于時讀鎖和寫鎖,它們都是鎖。InnoDB 的鎖,與索引類型,事務的隔離級別相關。
關于“MySQL InnoDB的select和update形成表級鎖實例分析”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“MySQL InnoDB的select和update形成表級鎖實例分析”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





