溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Flink任務調優的方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Flink任務調優的方法是什么”吧!
Flink 提供的 Metrics 可以在 Flink 內部收集一些指標,通過這些指標讓開發人員更好地理解作業或集群的狀態。由于集群運行后很難發現內部的實際狀況,跑得慢或快,是否異常等,開發人員無法實時查看所有的 Task 日志,比如作業很大或者有很多作業的情況下,該如何處理?此時 Metrics 可以很好的幫助開發人員了解作業的當前狀況。
我們通過上述的指標定位問題時,基本可以通過延遲與吞吐指標可以對任務的性能進行精準的判斷,精確的找到問題發生的代碼位置。 一般這些位置會出現以下錯誤:
Operator的并發數(parallelism)不合理
CPU(core)不合理
堆內存(heap_memory)等參數設置不合理
并行度的設置不合理
State的設置不合理
checkpoint的設置不合理
我們在設置這些參數時要注意:
并行度(parallelism):保證足夠的并行度,并行度也不是越大越好,太多會加重數據在多個solt/task manager之間數據傳輸壓力,包括序列化和反序列化帶來的壓力。
CPU:CPU資源是task manager上的solt共享的,注意監控CPU的使用。
內存:內存是分solt隔離使用的,注意存儲大state的時候,內存要足夠。
網絡:大數據處理,flink節點之間數據傳輸會很多,服務器網卡盡量使用萬兆網卡。
Flink 內部是基于 producer-consumer 模型來進行消息傳遞的,Flink的反壓設計也是基于這個模型。Flink 使用了高效有界的分布式阻塞隊列,就像 Java 通用的阻塞隊列(BlockingQueue)一樣。下游消費者消費變慢,上游就會受到阻塞。
在實踐中,很多情況下的反壓是由于數據傾斜造成的,這點我們可以通過 Web UI 各個 SubTask 的 Records Sent 和 Record Received 來確認,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一個分析數據傾斜的有用指標。
Flink 1.11 版本中對于 Flink 反壓問題本身做了一些優化,例如使用Unaligned Checkpoint + rocksdb生成Checkpoint,使用rocksdb緩存checkpoint, 并且從原來的全量生成改為增量生成的方式, 速度更快。
另外還需要注意的是,用戶代碼的執行效率問題(頻繁被阻塞或者性能問題)和TaskManager 的內存以及 GC 問題。
官網給出的參數如下:
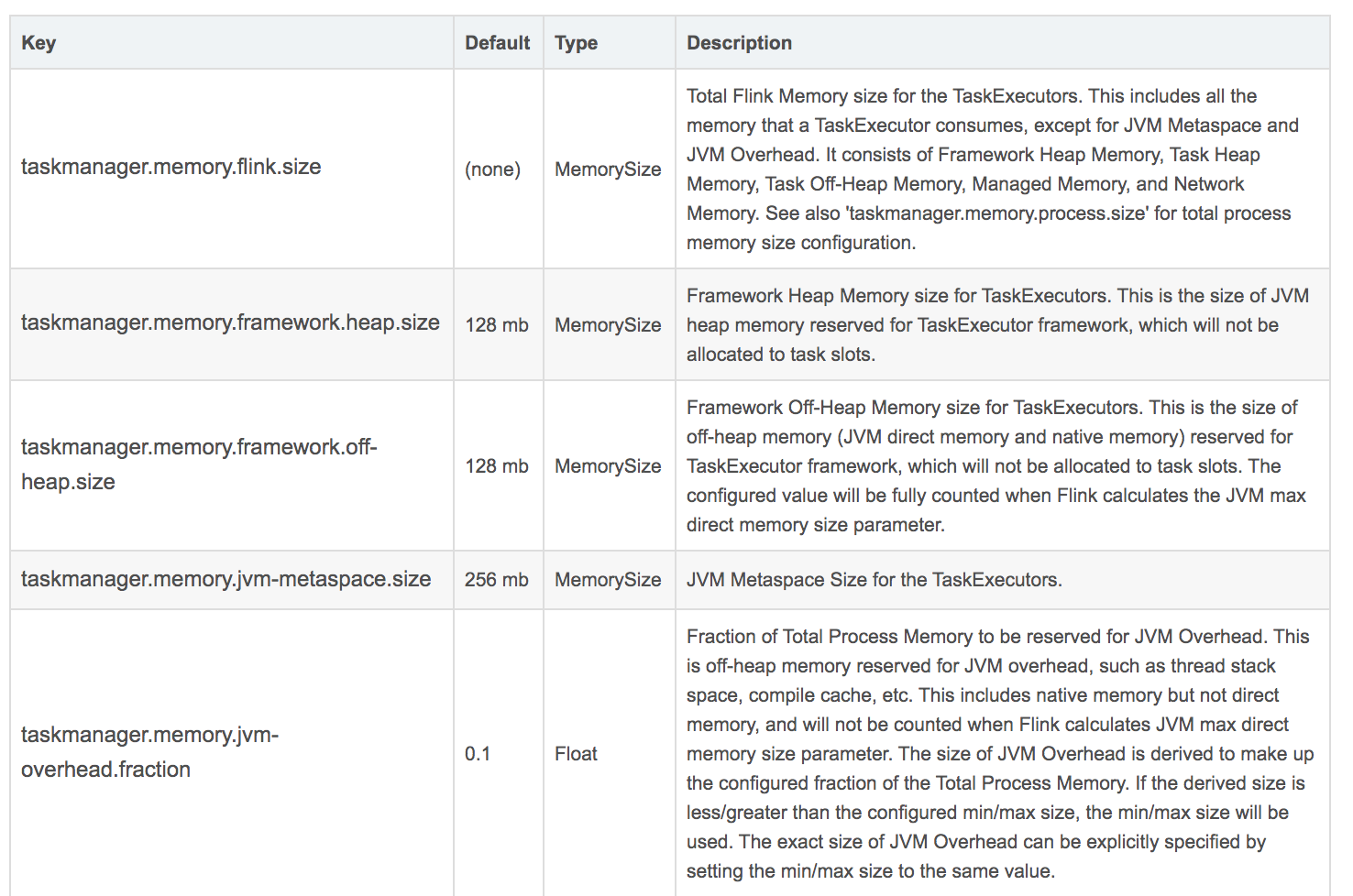
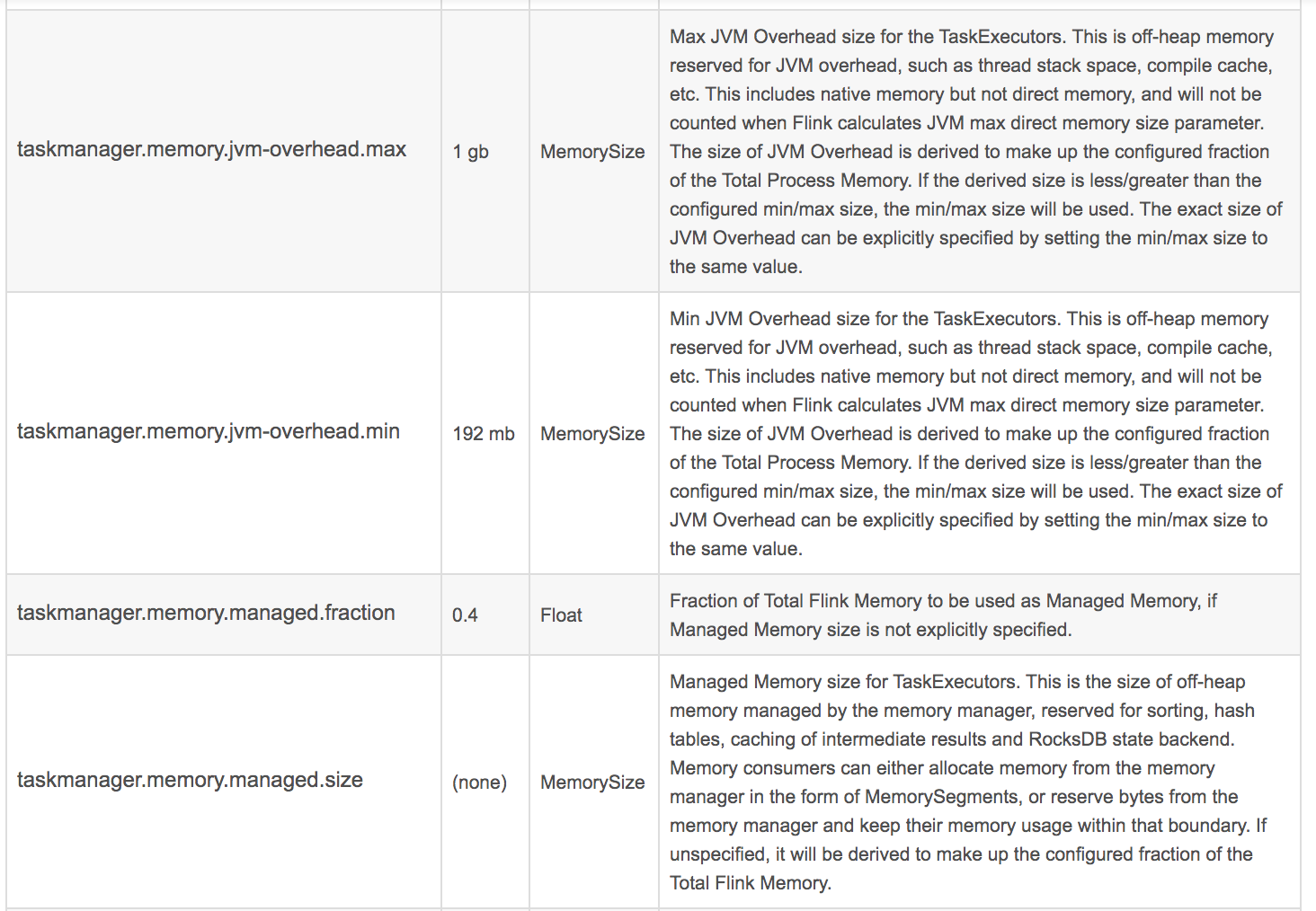
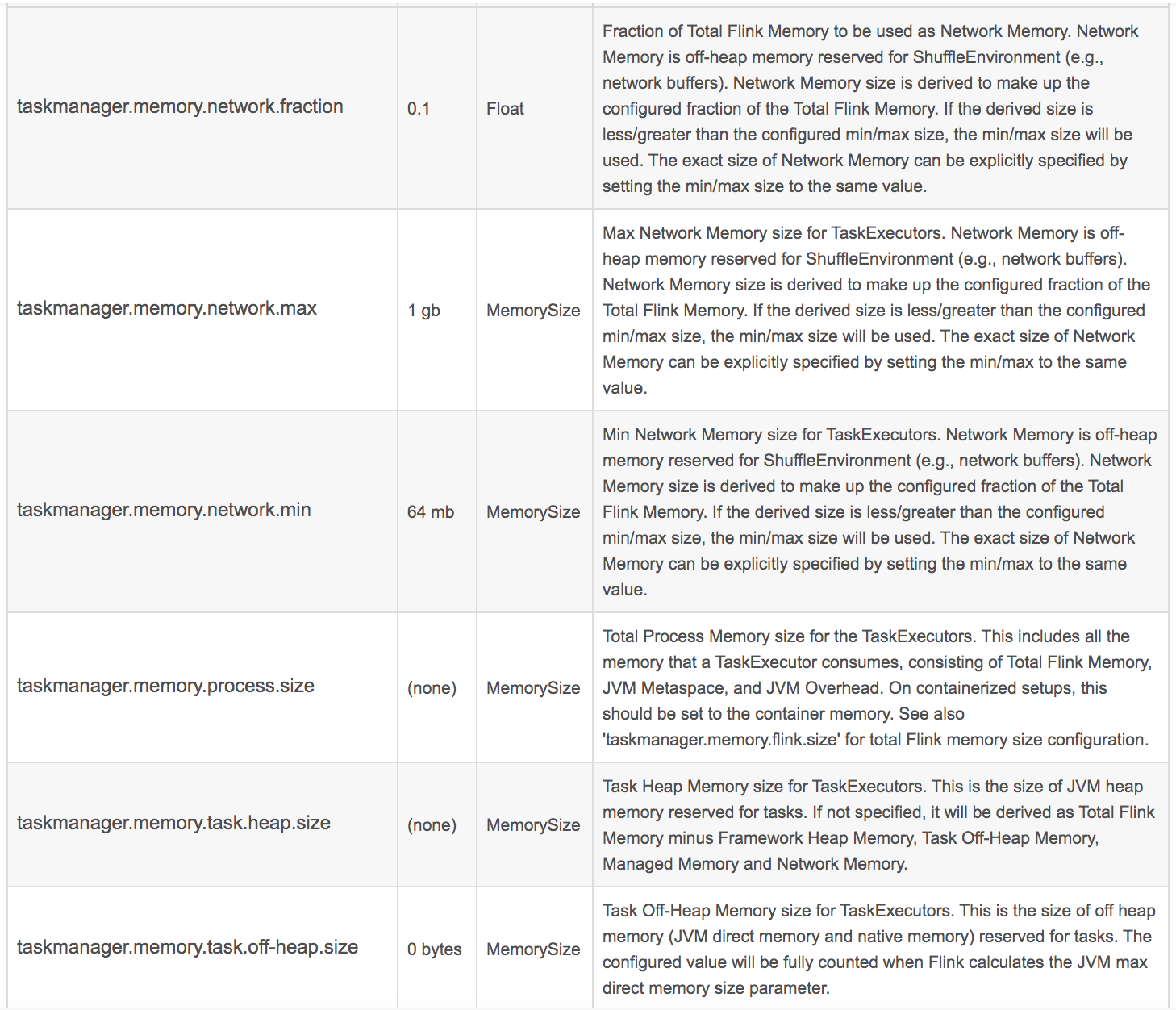
這里面最重要的幾個:
taskmanager.memory.process.size: 512m taskmanager.memory.framework.heap.size: 64m taskmanager.memory.framework.off-heap.size: 64m taskmanager.memory.jvm-metaspace.size: 64m taskmanager.memory.jvm-overhead.fraction: 0.2 taskmanager.memory.jvm-overhead.min: 16m taskmanager.memory.jvm-overhead.max: 64m taskmanager.memory.network.fraction: 0.1 taskmanager.memory.network.min: 1mb taskmanager.memory.network.max: 256mb
他們各自的意思,需要大家去查詢以下官方文檔。
JVM本身配置的主要參數無非以下這些:
堆設置 -Xms :初始堆大小 -Xmx :最大堆大小 -XX:NewSize=n :設置年輕代大小 -XX:NewRatio=n: 設置年輕代和年老代的比值。如:為3,表示年輕代與年老代比值為1:3,年輕代占整個年輕代年老代和的1/4 -XX:SurvivorRatio=n :年輕代中Eden區與兩個Survivor區的比值。注意Survivor區有兩個。如:3,表示Eden:Survivor=3:2,一個Survivor區占整個年輕代的1/5 -XX:MaxPermSize=n :設置持久代大小 收集器設置 -XX:+UseSerialGC :設置串行收集器 -XX:+UseParallelGC :設置并行收集器 -XX:+UseParalledlOldGC :設置并行年老代收集器 -XX:+UseConcMarkSweepGC :設置并發收集器 垃圾回收統計信息 -XX:+PrintHeapAtGC GC的heap詳情 -XX:+PrintGCDetails GC詳情 -XX:+PrintGCTimeStamps 打印GC時間信息 -XX:+PrintTenuringDistribution 打印年齡信息等 -XX:+HandlePromotionFailure 老年代分配擔保(true or false) 并行收集器設置 -XX:ParallelGCThreads=n :設置并行收集器收集時使用的CPU數。并行收集線程數。 -XX:MaxGCPauseMillis=n :設置并行收集最大暫停時間 -XX:GCTimeRatio=n :設置垃圾回收時間占程序運行時間的百分比。公式為1/(1+n) 并發收集器設置 -XX:+CMSIncrementalMode :設置為增量模式。適用于單CPU情況。 -XX:ParallelGCThreads=n :設置并發收集器年輕代收集方式為并行收集時,使用的CPU數。并行收集線程數
我們可以利用一些簡單的JVM日志分析工具看出JVM設置的參數問題出在哪里。
感謝各位的閱讀,以上就是“Flink任務調優的方法是什么”的內容了,經過本文的學習后,相信大家對Flink任務調優的方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





