溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了基于Flink的典型ETL場景是怎么實現,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
下面將從數倉誕生的背景、數倉架構、離線與實時數倉的對比著手,綜述數倉發展演進,然后分享基于 Flink 實現典型 ETL 場景的幾個方案。
我們先來回顧一下數據倉庫的概念。

數據倉庫的概念是于90年代由 Bill Inmon 提出, 當時的背景是傳統的 OLTP 數據庫無法很好的支持長周期分析決策場景,所以數據倉庫概念的4個核心點,我們要結合著 OLTP 數據庫當時的狀態來對比理解。
面向主題的:數據倉庫的數據組織方式與 OLTP 面向事務處理不同。因為數據倉庫是面向分析決策的,所以數據經常按分析場景或者是分析對象等主題形式來組織。
集成的:對于數據倉庫來說,經常需要去集合多個分散的、異構的數據源,做一些數據清洗等 ETL 處理,整合成一塊數據倉庫,OLTP 則不需要做類似的集成操作。
相對穩定的:OLTP 數據庫一般都是面向業務的,它主要的作用是把當前的業務狀態精準的反映出來,所以 OLTP 數據庫需要支持大量的增、刪、改的操作。但是對于數據倉庫來說,只要是入倉存下來的數據,一般使用場景都是查詢,因此數據是相對穩定的。
反映歷史變化:數據倉庫是反映歷史變化的數據集合,可以理解成它會將歷史的一些數據的快照存下來。而對于 OLTP 數據庫來說,只要反映當時的最新的狀態就可以了。
以上這4個點是數據倉庫的一個核心的定義。我們也可以看出對于實時數據倉庫來說,傳統數據倉庫也就是離線數據倉庫中的一些定義會被弱化,比如說在反映歷史變化這一點。介紹完數據倉庫的基本概念,簡單說下數據倉庫建模這塊會用到一些經典的建模方法,主要有范式建模、維度建模和 Data Vault。在互聯網大數據場景下,用的最多的是維度建模方法。
然后先看一下離線數倉的經典架構。
這個數倉架構主要是偏向互聯網大數據的場景方案,由上圖可以看出有三個核心環節。
1.第一個環節是數據源部分,一般互聯網公司的數據源主要有兩類:
第1類是通過在客戶端埋點上報,收集用戶的行為日志,以及一些后端日志的日志類型數據源。對于埋點行為日志來說,一般會經過一個這樣的流程,首先數據會上報到 Nginx 然后經過 Flume 收集,然后存儲到 Kafka 這樣的消息隊列,然后再由實時或者離線的一些拉取的任務,拉取到我們的離線數據倉庫 HDFS。
第2類數據源是業務數據庫,而對于業務數據庫的話,一般會經過 Canal 收集它的 binlog,然后也是收集到消息隊列中,最終再由 Camus 拉取到 HDFS。
這兩部分數據源最終都會落地到 HDFS 中的 ODS 層,也叫貼源數據層,這層數據和原始數據源是保持一致的。
2.第二個環節是離線數據倉庫,是圖中藍色的框展示的部分。可以看到它是一個分層的結構,其中的模型設計是依據維度建模思路。
最底層是 ODS 層,這一層將數據保持無信息損失的存放在 HDFS,基本保持原始的日志數據不變。
在 ODS 層之上,一般會進行統一的數據清洗、歸一,就得到了 DWD 明細數據層。這一層也包含統一的維度數據。
然后基于 DWD 明細數據層,我們會按照一些分析場景、分析實體等去組織我們的數據,組織成一些分主題的匯總數據層 DWS。
在 DWS 之上,我們會面向應用場景去做一些更貼近應用的 APP 應用數據層,這些數據應該是高度匯總的,并且能夠直接導入到我們的應用服務去使用。
在中間的離線數據倉庫的生產環節,一般都是采用一些離線生產的架構引擎,比如說 MapReduce、Hive、Spark 等等,數據一般是存在 HDFS 上。
3.經過前兩個環節后,我們的一些應用層的數據會存儲到數據服務里,比如說 HBase 、Redis、Kylin 這樣的一些 KV 的存儲。并且會針對存在這些數據存儲上的一些數據,封裝對應的服務接口,對外提供服務。在最外層我們會去產出一些面向業務的報表、面向分析的數據產品,以及會支持線上的一些業務產品等等。這一層的話,稱之為更貼近業務端的數據應用部分。
以上是一個基本的離線數倉經典架構的介紹。
大家都了解到現在隨著移動設備的普及,我們逐漸的由制造業時代過渡到了互聯網時代。在制造業的時代,傳統的數倉,主要是為了去支持以前的一些傳統行業的企業的業務決策者、管理者,去做一些業務決策。那個時代的業務決策周期是比較長的,同時當時的數據量較小,Oracle、DB2 這一類數據庫就已經足夠存了。
但隨著分布式計算技術的發展、智能化技術發展、以及整體算力的提升、互聯網的發展等等因素,我們現在在互聯網上收集的數據量,已經呈指數級的增長。并且業務不再只依賴人做決策,做決策的主體很大部分已轉變為計算機算法,比如一些智能推薦場景等等。所以這個時候決策的周期,就由原來的天級要求提升到秒級,決策時間是非常短的。在場景上的話,也會面對更多的需要實時數據處理的場景,例如實時的個性化推薦、廣告的場景、甚至一些傳統企業已經開始實時監控加工的產品是否有質量問題,以及金融行業重度依賴的反作弊等等。因此在這樣的一個背景下,實時數倉就必須被提出來了。
首先跟大家介紹一下實時數倉經典架構 - Lambda 架構:
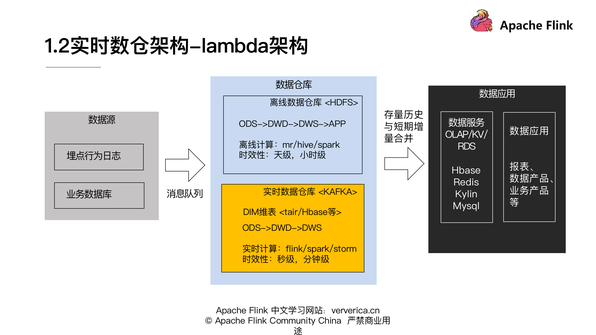
這個架構是 Storm 的作者提出來的,其實 Lambda 架構的主要思路是在原來離線數倉架構的基礎上疊加上實時數倉的部分,然后將離線的存量數據與我們 t+0 的實時的數據做一個 merge,就可以產生數據狀態實時更新的結果。
和上述1.1離線數據倉庫架構圖比較可以明顯的看到,實時數倉增加的部分是上圖黃色的這塊區域。我們一般會把實時數倉數據放在 Kafka 這樣的消息隊列上,也會有維度建模的一些分層,但是在匯總數據的部分,我們不會將 APP 層的一些數據放在實時數倉,而是更多的會移到數據服務側去做一些計算。
然后在實時計算的部分,我們經常會使用 Flink、Spark-streaming 和 Storm 這樣的計算引擎,時效性上,由原來的天級、小時級可以提升到秒級、分鐘級。
大家也可以看到這個架構圖中,中間數據倉庫環節有兩個部分,一個是離線的數據倉庫,一個是實時的數據倉庫。我們必須要運維兩套(實時計算和離線計算)引擎,并且在代碼層面,我們也需要去實現實時和離線的業務代碼。然后在合并的時候,我們需要保證實施和離線的數據一致性,所以但凡我們的代碼做變更,我們也需要去做大量的這種實時離線數據的對比和校驗。其實這對于不管是資源還是運維成本來說都是比較高的。這是 Lamda 架構上比較明顯和突出的一個問題。因此就產生了 Kappa 結構。
Kappa 架構的一個主要的思路就是在數倉部分移除了離線數倉,數倉的生產全部采用實時數倉。從上圖可以看到剛才中間的部分,離線數倉模塊已經沒有了。
關于 Kappa 架構,熟悉實時數倉生產的同學,可能會有一個疑問。因為我們經常會面臨業務變更,所以很多業務邏輯是需要去迭代的。之前產出的一些數據,如果口徑變更了,就需要重算,甚至重刷歷史數據。對于實時數倉來說,怎么去解決數據重算問題?
Kappa 架構在這一塊的思路是:首先要準備好一個能夠存儲歷史數據的消息隊列,比如 Kafka,并且這個消息對列是可以支持你從某個歷史的節點重新開始消費的。 接著需要新起一個任務,從原來比較早的一個時間節點去消費 Kafka 上的數據,然后當這個新的任務運行的進度已經能夠和現在的正在跑的任務齊平的時候,你就可以把現在任務的下游切換到新的任務上面,舊的任務就可以停掉,并且原來產出的結果表也可以被刪掉。
隨著我們現在實時 OLAP 技術的一些提升,有一個新的實時架構被提了出來,這里暫且稱為實時 OLAP 變體。
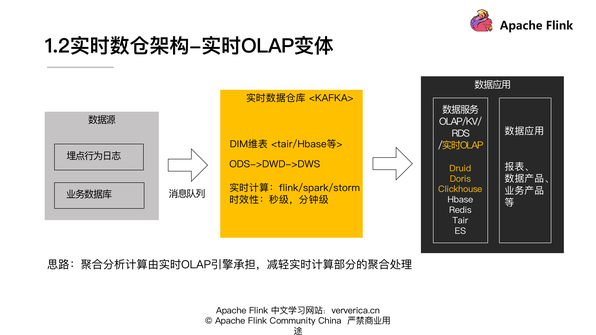
這個思路是把大量的聚合、分析、計算由實時 OLAP 引擎來承擔。在實時數倉計算的部分,我們不需要做的特別重,尤其是聚合相關的一些邏輯,然后這樣就可以保障我們在數據應用層能靈活的面對各種業務分析的需求變更,整個架構更加靈活。
最后我們來整體對比一下,實時數倉的這幾種架構
這是整體三個關于實時數倉架構的一個對比:
從計算引擎角度:Lamda 架構它需要去維護批流兩套計算引擎,Kappa 架構和實時 OLAP 變體只需要維護流計算引擎就好了。
開發成本:對 Lamda 架構來說,因為它需要維護實時離線兩套代碼,所以它的開發成本會高一些。 Kappa 架構和實時 OLAP 變體只用維護一套代碼就可以了。
分析靈活性:實時 OLAP 變體是相對最靈活的。
在實時 OLAP 引擎依賴上:實時 OLAP 變體是強依賴實時 OLAP 變體引擎的能力的,前兩者則不強依賴。
計算資源:Lamda 架構需要批流兩套計算資源,Kappa 架構只需要流計算資源,實時 OLAP 變體需要額外的 OLAP 資源。
邏輯變更重算:Lamda 架構是通過批處理來重算的,Kappa 架構需要按照前面介紹的方式去重新消費消息隊列重算,實時 OLAP 變體也需要重新消費消息隊列,并且這個數據還要重新導入到 OLAP 引擎里,去做計算。
然后我們來看一下傳統數倉和實時數倉整體的差異。

首先從時效性來看:離線數倉是支持小時級和天級的,實時數倉到秒級分鐘級,所以實時數倉時效性是非常高的。
在數據存儲方式來看:離線數倉它需要存在HDFS和RDS上面,實時數倉一般是存在消息隊列,還有一些kv存儲,像維度數據的話會更多的存在kv存儲上。
在生產加工過程方面,離線數倉需要依賴離線計算引擎以及離線的調度。 但對于實時數倉來說,主要是依賴實時計算引擎。
這里我們主要介紹兩大實時 ETL 場景:維表 join 和雙流 join。
維表 join
預加載維表
熱存儲關聯
廣播維表
Temporal table function join
雙流 join
離線join vs. 實時join
Regular join
Interval join
Window join
方案1:
將維表全量預加載到內存里去做關聯,具體的實現方式就是我們定義一個類,去實現 RichFlatMapFunction,然后在 open 函數中讀取維度數據庫,再將數據全量的加載到內存,然后在 probe 流上使用算子 ,運行時與內存維度數據做關聯。
這個方案的優點就是實現起來比較簡單,缺點也比較明顯,因為我們要把每個維度數據都加載到內存里面,所以它只支持少量的維度數據。同時如果我們要去更新維表的話,還需要重啟作業,所以它在維度數據的更新方面代價是有點高的,而且會造成一段時間的延遲。對于預加載維表來說,它適用的場景就是小維表,變更頻率訴求不是很高,且對于變更的及時性的要求也比較低的這種場景。
這里定義了一個 DimFlatMapFunction 來實現 RichFlatMapFunction。其中有一個 Map 類型的 dim,其實就是為了之后在讀取 DB 的維度數據以后,可以用于存放我們的維度數據,然后在 open 函數里面我們需要去連接我們的 DB,進而獲取 DB 里的數據。然后在下面代碼可以看到我們的場景是從一個商品表里面去取出商品的 ID、商品的名字。然后我們在獲取到 DB 里面的維度數據以后會把它存放到 dim 里面。
接下來在 flatMap 函數里面我們就會使用到 dim,我們在獲取了 probe 流的數據以后,我們會去 dim 里面比較。是否含有同樣的商品 ID 的數據,如果有的話就把相關的商品名稱 append 到數據元組,然后做一個輸出。這就是一個基本的流程。
其實這是一個基本最初版的方案實現。但這個方案也有一個改進的方式,就是在 open 函數里面,可以新建一個線程,定時的去加載維表。這樣就不需要人工的去重啟 job 來讓維度數據做更新,可以實現一個周期性的維度數據的更新。
方案2:
通過 Distributed cash 的機制去分發本地的維度文件到task manager后再加載到內存做關聯。實現方式可以分為三步:
第1步是通過 env.registerCached 注冊文件。
第2步是實現 RichFunction,在 open 函數里面通過 RuntimeContext 來獲取 cache 文件。
第3步是解析和使用這部分文件數據。
這種方式的一個優點是你不需要去準備或者依賴外部數據庫,缺點就是因為數據也是要加載到內存中,所以支持的維表數據量也是比較小。而且如果這個維度數據需要做更新,也需要重啟作業。 因此在正規的生產過程中不太建議使用這個方案,因為其實從數倉角度,希望所有的數據都能夠通過 schema 化方式來管理。把數據放在文件里面去做這樣一個操作,不利于我們做整體數據的管理和規范化。所以這個方式的話,大家在做一些小的 demo 的時候,或者一些測試的時候可以去使用。
那么它適用的場景就是維度數據是文件形式的、數據量比較小、并且更新的頻率也比較低的一些場景,比如說我們讀一個靜態的碼表、配置文件等等。
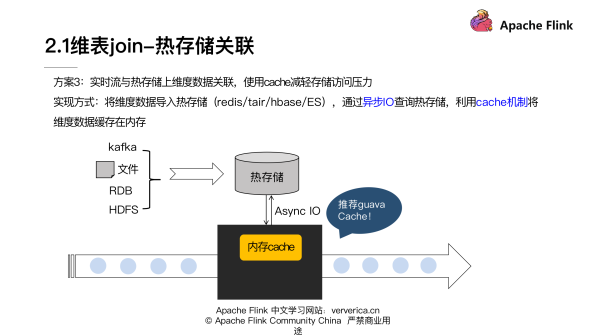
維表 join 里第二類大的實現思路是熱存儲關聯。具體是我們把維度數據導入到像 Redis、Tair、HBase 這樣的一些熱存儲中,然后通過異步 IO 去查詢,并且疊加使用 Cache 機制,還可以加一些淘汰的機制,最后將維度數據緩存在內存里,來減輕整體對熱存儲的訪問壓力。
如上圖展示的這樣的一個流程。在 Cache 這塊的話,比較推薦谷歌的 Guava Cache,它封裝了一些關于 Cache 的一些異步的交互,還有 Cache 淘汰的一些機制,用起來是比較方便的。
剛才的實驗方案里面有兩個重要點,一個就是我們需要用異步 IO 方式去訪問存儲,這里也跟大家一起再回顧一下同步 IO 與異步 IO 的區別:
對于同步 IO 來說,發出一個請求以后,必須等待請求返回以后才能繼續去發新的 request。所以整體吞吐是比較小的。由于實時數據處理對于延遲特別關注,這種同步 IO 的方式,在很多場景是不太能夠接受的。
異步 IO 就是可以并行發出多個請求,整個吞吐是比較高的,延遲會相對低很多。如果使用異步 IO 的話,它對于外部存儲的吞吐量上升以后,會使得外部存儲有比較大的壓力,有時也會成為我們整個數據處理上延遲的瓶頸。所以引入 Cache 機制是希望通過 Cache 來去減少我們對外部存儲的訪問量。
剛才提到的 Cuava Cache,它的使用是非常簡單的,大家可以去嘗試使用。對于熱存儲關聯方案來說,它的優點就是維度數據因為不用全量加載在內存里,所以就不受限于內存大小,維度數據量可以更多。在美團點評的流量場景里面,我們的維度數據可以支持到 10 億量級。另一方面該方案的缺點也是比較明顯的,我們需要依賴熱存儲資源,而且維度的更新反饋到結果是有一定延遲的。 因為我們首先需要把數據導入到熱存儲,然后同時在 Cache 過期的時間上也會有損失。
總體來說這個方法適用的場景是維度數據量比較大,又能夠接受維度更新有一定延遲的情況。
第三個大的思路是廣播維表,主要是利用 broadcast State 將維度數據流廣播到下游 task 做 join。
實現方式:
將維度數據發送到 Kafka 作為廣播原始流 S1
定義狀態描述符 MapStateDescriptor。調用 S1.broadcast(),獲得 broadCastStream S2
調用非廣播流 S3.connect(S2),得到 BroadcastConnectedStream S4
在 KeyedBroadcastProcessFunction/BroadcastProcessFunction 實現關聯處理邏輯,并作為參數調用 S4.process()
這個方案,它的優點是維度的變更可以及時的更新到結果。然后缺點就是數據還是需要保存在內存中,因為它是存在 state 里的,所以支持維表數據量仍然不是很大。適用的場景就是我們需要時時的去感知維度的變更,且維度數據又可以轉化為實時流。
下面是一個小的 demo:

我們這里面用到的廣播流 pageStream,它其實是定義了一個頁面 ID 和頁面的名稱。對于非廣播流 probeStream,它是一個 json 格式的 string,里面包含了設備 ID、頁面的 ID、還有時間戳,我們可以理解成用戶在設備上做 PV 訪問的行為記錄。
整個實現來看,就是遵循上述4個步驟:
第1步驟是要定義廣播的狀態描述符。
第2步驟我們這里去生成 broadCastStream。
第3步驟的話我們就需要去把兩個 stream 做 connect。
第4步最主要的一個環節就是需要實現 BroadcastProcessFunction。第1個參數是我們的 probeStream,第2個參數是廣播流的數據,第3個參數就是我們的要輸出的數據,可以看到主要的數據處理邏輯是在processElement里面。
在數據處理過程中,我們首先通過 context 來獲取我們的 broadcastStateDesc,然后解析 probe 流的數據,最終獲取到對應的一個 pageid。接著就在我們剛才拿到了 state 里面去查詢是否有同樣的 pageid,如果能夠找到對應的 pageid 話,就把對應的 pagename 添加到我們整個 json stream 去做輸出。
介紹完了上面的方法以后,還有一種比較重要的方法是用 Temporal table function join。首先說明一下什么是 Temporal table?它其實是一個概念:就是能夠返回持續變化表的某一時刻數據內容的視圖,持續變化表也就是 changingtable,可以是一個實時的 changelog 的數據,也可以是放在外部存儲上的一個物化的維表。
它的實現是通過 UDTF 去做 probe 流和 Temporal table 的 join,稱之 Temporal table function join。這種 join 的方式,它適用的場景是維度數據為 changelog 流的形式,而且我們有需要按時間版本去關聯的訴求。
首先來看一個例子,這里使用的是官網關于匯率和貨幣交易的一個例子。對于我們的維度數據來說,也就是剛剛提到的 changelog stream,它是 RateHistory。它反映的是不同的貨幣相對于日元來說,不同時刻的匯率。
第1個字段是時間,第2個字段是 currency 貨幣。第3個字段是相對日元的匯率,然后在我們的 probe table 來看的話,它定義的是購買不同貨幣的訂單的情況。比如說在 10:15 購買了兩歐元,該表記錄的是貨幣交易的一個情況。在這個例子里面,我們要求的是購買貨幣的總的日元交易額,如何通 Temporal table function join 來去實現我們這個目標呢?
第1步首先我們要在 changelog 流上面去定義 TemporalTableFunction,這里面有兩個關鍵的參數是必要的。第1個參數就是能夠幫我們去識別版本信息的一個 time attribute,第2個參數是需要去做關聯的組件,這里的話我們選擇的是 currency。
接著的話我們在 tableEnv 里面去注冊 TemporalTableFunction 的名字。
然后我們來看一下我們注冊的 TemporalTableFunction,它能夠起到什么樣的效果。
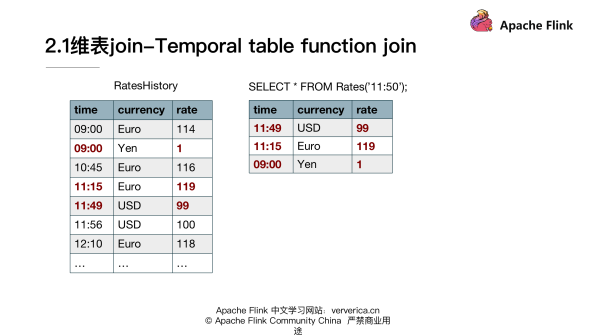
比如說如果我們使用 rates 函數,去獲取11:50的狀態。可以看到對于美元來說,它在11:50的狀態其實落在11:49~11:56這個區間的,所以選取的是99。然后對于歐元來說,11:50的時刻是落在11:15和12:10之間的,所以我們會選取119這樣的一條數據。它其實實現的是我們在一剛開始定義的 TemporalTable 的概念,能夠獲取到 changelog 某一時刻有效數據。定義好 TemporalTableFunction 以后,我們就要需要使用這個 Function,具體實現業務邏輯。
大家注意這里需要去指定我們具體需要用到的 join key。比如說因為兩個流都是在一直持續更新的,對于我們的 order table 里面 11:00 的這一條記錄來說,關聯到的就是歐元在 10:45 這一條狀態,然后它是 116,所以最后的結果就是 232。
剛才介紹的就是 Temporal table function join 的用法。
然后來整體回顧一下在維表 join 這塊,各個維度 join 的一些差異,便于我們更好的去理解各個方法適用的場景。
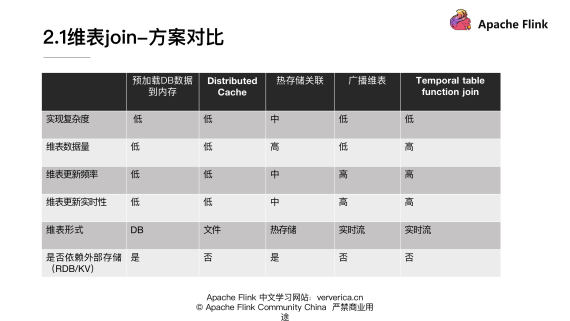
在實現復雜度上面的:除了熱存儲關聯稍微復雜一些,其它的實現方式基本上復雜度是比較低的。
在維表數據量上:熱存儲關聯和 Temporal table function join 兩種方式可以支持比較多的數據量。其它的方式因為都要把維表加載到內存,所以就受限內存的大小。
在維表更新頻率上面:因為預加載 DB 數據到內存和 Distributed Cache 在重新更新維表數據的時候都需要重啟,所以它們不適合維表需要經常變更的場景。而對于廣播維表和 Temporal table function join 來說,可以實時的更新維表數據并反映到結果,所以它們可以支持維表頻繁更新的場景。
對維表更新實時性來說:在廣播維表和 Temporal table function join,它們可以達到比較快的實時更新的效果。熱存儲關聯在大部分場景也是可以滿足業務需求的。
在維表形式上面:可以看到第1種方式主要是支持訪問 DB 存儲少量數據的形式,Distributed Cache 支持文件的形式,熱存儲關聯需要訪問 HBase 和 Tair 等等這種熱存儲。廣播維表和 Temporal table function join 都需要維度數據能轉化成實時流的形式。
在外部存儲上面:第1種方式和熱存儲關聯都是需要依賴外部存儲的。
在維表 join 這一塊,我們就先介紹這幾個基本方法。可能有的同學還有一些其他方案,之后可以反饋交流,這里主要提了一些比較常用的方案,但并不限于這些方案。
首先我們來回顧一下,批處理是怎么去處理兩個表 join的?一般批處理引擎實現的時候,會采用兩個思路。
一個是基于排序的 Sort-Merge join。另外一個是轉化為 Hash table 加載到內存里做 Hash join。這兩個思路對于雙流 join 的場景是否還同樣適用?在雙流 join 場景里面要處理的對象不再是這種批數據、有限的數據,而是是無窮數據集,對于無窮數據集來說,我們沒有辦法排序以后再做處理,同樣也沒有辦法把無窮數據集全部轉成 Cache 加載到內存去做處理。 所以這兩種方式基本是不能夠適用的。同時在雙流 join 場景里面,我們的 join 對象是兩個流,數據也是不斷在進入的,所以我們 join 的結果也是需要持續更新的。
那么我們應該有什么樣的方案去解決雙流 join 的實現問題?Flink 的一個基本的思路是將兩個流的數據持續性的存到 state 中,然后使用。因為需要不斷的去更新 join 的結果,之前的數據理論上如果沒有任何附加條件的話是不能丟棄的。但是從實現上來說 state 又不能永久的保存所有的數據,所以需要通過一些方式將 join 的這種全局范圍局部化,就是說把一個無限的數據流,盡可能給它拆分切分成一段一段的有線數據集去做 join。
其實基本就是這樣一個大的思路,接下來去看一下具體的實現方式。
接下來我們以 inner join 為例看一下,
左流是黑色標出來的這一條,右流是藍色標出來的,這條兩流需要做 inner join。首先左流和右流在元素進入以后,需要把相關的元素存儲到對應的 state 上面。除了存儲到 state 上面以外,左流的數據元素到來以后需要去和右邊的 Right State 去做比較看能不能匹配到。同樣右邊的流元素到了以后,也需要和左邊的 Left State 去做比較看是否能夠 match,能夠 match 的話就會作為 inner join 的結果輸出。這個圖是比較粗的展示出來一個 inner join 的大概細節。也是讓大家大概的體會雙流 join 的實現思路。
我們首先來看一下第1類雙流 join 的方式,Regular join。這種 join 方式需要去保留兩個流的狀態,持續性地保留并且不會去做清除。兩邊的數據對于對方的流都是所有可見的,所以數據就需要持續性的存在state里面,那么 state 又不能存的過大,因此這個場景的只適合有界數據流。它的語法可以看一下,比較像離線批處理的 SQL:

在上圖頁面里面是現在 Flink 支持 Regular join 的一些寫法,可以看到和我們普通的 SQL 基本是一致的。
在雙流 join 里面 Flink支持的第2類 join 就是 Interval join 也叫區間 join。它是什么意思呢?就是加入了一個時間窗口的限定,要求在兩個流做 join 的時候,其中一個流必須落在另一個流的時間戳的一定時間范圍內,并且它們的 join key 相同才能夠完成 join。加入了時間窗口的限定,就使得我們可以對超出時間范圍的數據做一個清理,這樣的話就不需要去保留全量的 State。
Interval join 是同時支持 processing time 和 even time去定義時間的。如果使用的是 processing time,Flink 內部會使用系統時間去劃分窗口,并且去做相關的 state 清理。如果使用 even time 就會利用 Watermark 的機制去劃分窗口,并且做 State 清理。
Flink 的作者之前有一個內容非常直觀的分享,這里就直接復用了他這部分的一個示例:
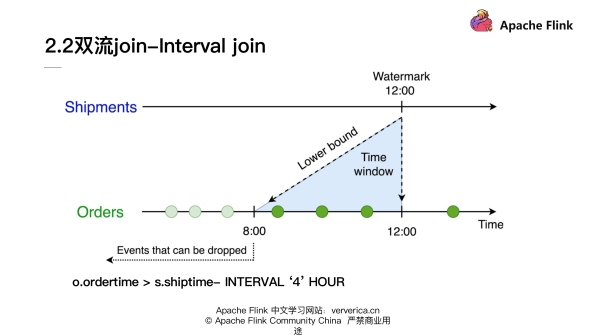
我們可以看到對于 Interval join 來說:它定義一個時間的下限,就可以使得我們對于在時間下限之外的數據做清理。比如在剛才的 SQL 里面,其實我們就限定了 join 條件是 ordertime 必須要大于 shiptime 減去4個小時。 對于 Shipments 流來說,如果接收到12:00 點的 Watermark,就意味著對于 Orders 流的數據小于 8:00 點之前的數據時間戳就可以去做丟棄,不再保留在 state 里面了。
同時對于 shiptime 來說,其實它也設定了一個時間的下限,就是它必須要大于 ordertime。對于 Orders 流來說如果接收到了一個10:15點的 Watermark, 那么 Shipments 的 state 10:15 之前的數據就可以拋棄掉。 所以 Interval join 使得我們可以對于一部分歷史的 state 去做清理。
最后來說一下雙流 join 的第3種 Window join:它的概念是將兩個流中有相同 key 和處在相同 window 里的元素去做 join。它的執行的邏輯比較像 Inner join,必須同時滿足 join key 相同,而且在同一個 window 里元素才能夠在最終結果中輸出。具體使用的方式是這樣的:

目前 Window join 只支持 Datastream 的 API,所以這里使用方式也是 Datastream 的一個形式。可以看到我們首先把兩流去做 join,然后在 where 和 equalTo 里面去定義 join key 的條件,然后在 window 中需要去指定 window 劃分的方式 WindowAssigner,最后要去定義 JoinFunction 或者是 FlatJoinFunction,來實現我們匹配元素的具體處理邏輯。
因為 window 其實劃分為三類,所以我們的 Window join 這里也會分為三類:
第1類 Tumbling Window join:它是按照時間區間去做劃分的 window。
可以看到這個圖里面是兩個流(綠色的流年和黃色的流)。在這個例子里我們定義的是一個兩毫秒的窗口,每一個圈是我們每個流上一個單個元素,上面的時間戳代表元素對應的時間,所以我們可以看到它是按照兩毫秒的間隔去做劃分的,window 和 window 之間是不會重疊的。 對于第1個窗口我們可以看到綠色的流有兩個元素符合,然后黃色流也有兩個元素符合,它們會以 pair 的方式組合,最后輸入到 JoinFunction 或者是 FlatJoinFunction 里面去做具體的處理。
第2類 window 是 Sliding Window Join:這里用的是 Sliding Window。

sliding window 是首先定義一個窗口大小,然后再定義一個滑動時間窗的大小。如果滑動時間窗的大小小于定義的窗口大小,窗口和窗口之間會存在重疊的情況。就像這個圖里顯示出來的,紅色的窗口和黃色窗口是有重疊的,其中綠色流的0元素同時處于紅色的窗口和黃色窗口,說明一個元素是可以同時處于兩個窗口的。然后在具體的 Sliding Window Join 的時候,可以看到對于紅色的窗口來說有兩個元素,綠色0和黃色的0,它們兩個元素是符合 window join 條件的,于是它們會組成一個0,0的 pair。 然后對于黃色的窗口符合條件的是綠色的0與黃色0和1兩位數,它們會去組合成0,1、0,0和1,0兩個pair,最后會進入到我們定義的 JoinFunction 里面去做處理。
第3類是 SessionWindow join:這里面用到的 window 是 session window。
session window 是定義一個時間間隔,如果一個流在這個時間間隔內沒有元素到達的話,那么它就會重新開一個新的窗口。在上圖里面我們可以看到窗口和窗口之間是不會重疊的。我們這里定義的Gap是1,對于第1個窗口來說,可以看到有綠色的0元素和黃色的1、2元素都是在同一個窗口內,所以它會組成在1 ,0和2,0這樣的一個pair。剩余的也是類似,符合條件的pair都會進入到最后 JoinFunction 里面去做處理。
上述內容就是基于Flink的典型ETL場景是怎么實現,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





