溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何快速給Hadoop集群加上彈性”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1. 背景介紹
大數據時代早期,Apache Hadoop是構建具有海量存儲能力數據倉庫的首選方案,許多企業用戶采用在云上購買ECS,自建Hadoop集群來存儲和處理數據。Apache Spark作為一個內存計算框架,具有流處理、批處理,圖計算,機器學習,SQL查詢等多種能力,社區活躍度高,并且Spark天然支持Hadoop數據源,可以完美的融入Hadoop生態,提供高效的計算能力。Hadoop+Spark成為大數據領域的明星,被廣泛用于離線大數據的挖掘。
云上的Hadoop集群通常是以ECS加云盤(或本地盤)配合一系列開源組件組成。隨著業務的增長,對計算能力的需求不斷地提升,尤其是在業務高峰期,數據大量涌入,為保證服務的穩定性和及時性,需要及時的增加節點來滿足業務需求。業務低峰期時,希望能及時的回收多余的計算資源,避免資源的浪費。這就要求Hadoop集群具有一定的彈性能力,能根據業務量及時地擴(縮)容相應的計算資源。彈性能力是云計算的趨勢,可以給用戶帶來更低成本的計算。但是如何快捷穩定地給已有的計算集群增加彈性是一個讓用戶頭痛的問題。
2. 傳統彈性方案的問題
由于歷史原因,用戶的很多數據和業務放在自建Hadoop集群之上。隨著業務發展,或者業務高峰期到來,對集群計算力需求增加,通常用戶會采取擴容Hadoop集群節點,以增加可用計算資源池。雖然擴容機器可以一定程度的滿足計算力的需求,但是會遇到以下的幾個痛點。
· 擴容慢: 通常一個比較大的集群擴容,為了避免對已有線上業務的影響,需要選擇在業務低峰期擴容,且擴容時,由于需要在新的節點上部署各個組件,時間短則十幾分鐘,多則數小時,很難應對業務的變化。
· 縮容難: 由于業務高峰期只是一段時間,我們真正需要額外計算資源的時間也就只有一段時間,或者多出來的業務并不是每時每刻的都在執行,而是按照一定的時間間隔去執行。如果不及時縮容,就造成了計算的不飽和,帶了對計算資源的浪費,增加了企業的成本開銷。而擴容出來的節點,由于已經部署上了許多組件,縮容前需要預先退出這些組件,步驟繁瑣,容易出錯。
· 彈不出: 用戶進行擴容時,按照ECS粒度,買一批ECS節點加入到現有計算集群的資源池。購買的ECS規格往往較大,受云資源碎片化的影響,有時很難滿足用戶對一批大規格ECS資源的請求,導致計算資源彈不出,無法完成對集群的擴容。
3. DLA Spark快速彈性方案
DLA團隊將Serverless、云原生、Spark技術優勢深度整合到一起,提供Serverless Spark產品,可以無縫連接用戶Hadoop集群,快捷穩定地為傳統Hadoop集群增加彈性算力。下面我們將介紹DLA Serverless Spark是如何解決用戶上述痛點問題的。
· 免運維的虛擬計算集群
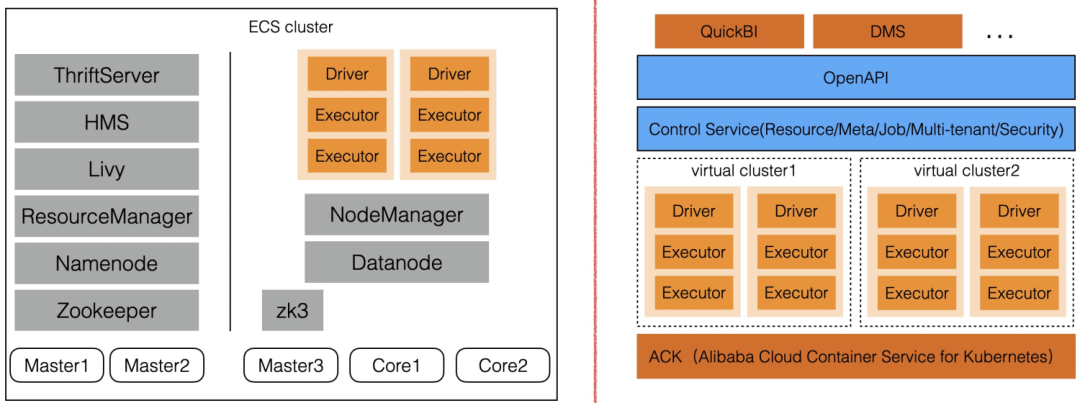
上圖是傳統的Hadoop集群中的Spark與DLASpark的架構對比。圖中左邊部分是傳統Spark集群,由多個ECS組成,集群內部擁有一套完整的Spark管控,計算進程和管控進程部署在各個ECS上,每個集群的計算資源池相對固定,如果需要更多的計算資源則需要擴容更多的計算節點,需要縮容則需要關閉對應ECS上的服務,然后釋放ECS資源。
圖中右邊是DLA Spark,相對于傳統的集群模式,DLA Spark抽象出一個虛擬集群的概念,虛擬集群并沒有實際的計算資源,它只是承載用戶對作業進行控制的一些配置,包括計算資源的配置、作業通用參數的配置等。創建虛擬集群不需要任何費用,用戶簡單地選擇虛擬集群內存和CPU的上限后,即可快速的創建一個虛擬集群,并往虛擬集群提交作業。DLA Spark是多租戶化的,每個用戶可擁有多個自己的虛擬集群,無需用戶進行運維。
· 計算進程級別的彈性粒度
DLA Spark基于AliyunKubernetes云原生技術深度定制, 實現了計算進程級別的彈性粒度,可更高效地應對云資源碎片化問題。用戶通過作業指定的資源規格彈性拉起計算進程,計算進程運行安全容器中。安全容器是基于阿里云的底座ECS&ACK&ECI,與阿里云IAAS資源大池打通,本Region跨可用區資源調度,保障計算資源的供給, 支持1分鐘內彈300個安全容器。
· 快速擴縮容
由于DLASpark虛擬集群化的設計,計算進程在作業啟動過程中動態拉起,用戶可以很方便地對虛擬集群的規格進行擴縮容,只需要在控制臺上進行資源配置即可。值得注意的是,虛擬集群中的計算進程使用完畢后就會自動釋放,無需用戶關心計算資源的生命周期。虛擬集群是按量付費,即只有作業真正的提交到虛擬集群運行之后,才開始按照資源使用時間計費,作業運行完畢即停止收費,不存在對計算資源的浪費。
· 無縫打通用戶Hadoop集群
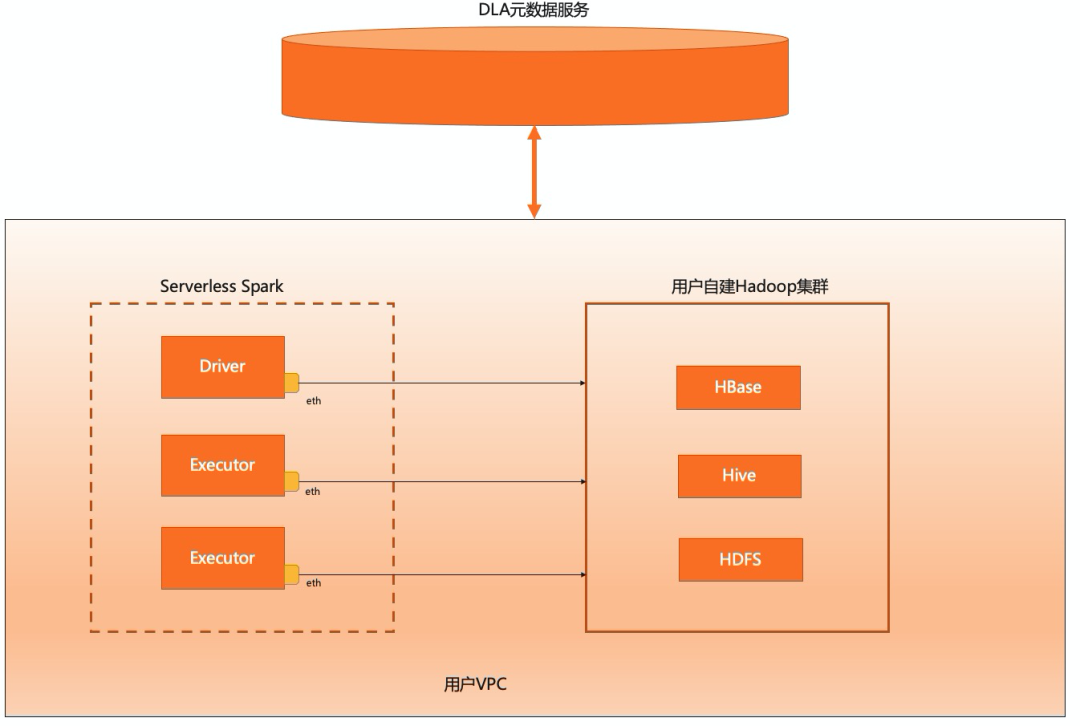
如上圖所示,DLA Spark可以通過掛載用戶VPC空間下的彈性網卡,無縫對接用戶自建Hadoop集群。DLA Spark的Driver和Executor運行在安全容器中,該容器實例動態掛載用戶VPC空間下的虛擬網卡,來訪問用戶VPC下的服務(如 HBase,Hive,HDFS等)。掛載了彈性網卡的容器實例就如同運行在用戶自建Hadoop集群中的ECS實例一樣,網絡帶寬同樣是VPC內網帶寬。虛擬網卡的生命周期跟Spark進程的生命周期一致,作業結束后,所有網卡也會相應釋放。
值得一提的是,彈性網卡,是一種免費的技術,用戶使用彈性網卡訪問Hadoop集群數據不需要花費額外的費用。打通用戶Hadoop集群配置簡單,用戶運行作業時,如需為Serverless Spark計算進程掛載虛擬網卡,只需要在作業配置中配置上屬于該VPC的安全組和虛擬交換機即可。更方便地,如果用戶某個ECS本來就可以訪問目標數據,那么讓DLA Spark配置該ECS所在的安全組和虛擬交換機即可。
4. DLA Spark的性價比優勢
· 性能相當,資源利用率高

如上圖,我們通過運行典型的ETL場景,1TB數據TeraSort,來開箱測試社區版Spark和DLA Serverless Spark的性能,需要說明的是,本測試中DLA Serverless Spark通過彈性網卡直接讀寫用戶Hadoop集群的數據,社區版Spark部署在與Hadoop集群相同的ECS上。從上圖中可以看到,兩者性能基本持平。
由于DLASpark是按照計算進程拉起的,運行在安全容器中,用戶只需要關心作業進程的規格和個數即可,拉起的資源全部用于DLA Spark的運行。而自建Hadoop集群由于是ECS級別的,需要預留一定資源用于運行NodeManager等組件,會存在一定的資源冗余。我們可以看到自建Hadoop集群要滿足Driver 需要4核16G,20個2核8G的Executor的配置需要購買6臺8核32G的ECS。因此相比之下DLA Spark的資源利用率更高。
· 快速彈性,節省用戶成本
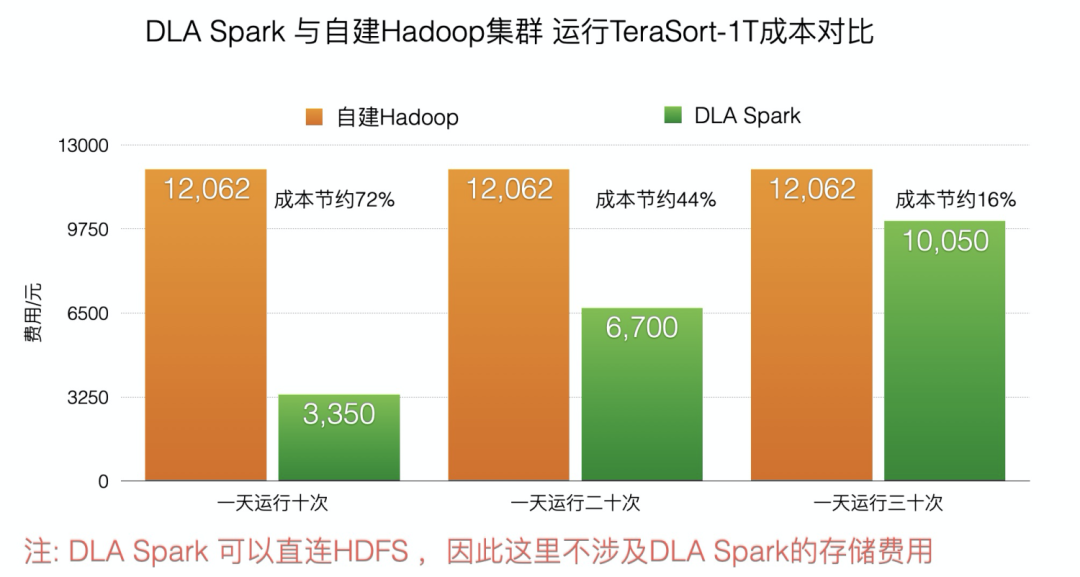
一般而言,用戶的業務量是隨著時間變化的,當自建Hadoop集群計算資源不足時,用戶可以提交作業到虛擬集群中,快速拉起DLASpark進行計算,當業務低谷時,虛擬機群停止接收作業,不收取任何費用。我們還是以上述TeraSort為例,用戶自建集群包月,DLA Spark按量付費的情況。DLA Saprk比起自建Hadoop集群,一天運行十次TeraSort時,成本可節約72%,一天運行三十次TeraSort時,成本可節約16%。用戶可以將自建Hadoop集群與DLA Spark混合使用,在性能不降低的情況下做到對計算資源的快速彈性伸縮,降低用戶計算成本。
“如何快速給Hadoop集群加上彈性”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





