溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Kafka和ClickHouse中的應用分析”,在日常操作中,相信很多人在Kafka和ClickHouse中的應用分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Kafka和ClickHouse中的應用分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Sparse Index
在以數據庫為代表的存儲系統中,索引(index)是一種附加于原始數據之上的數據結構,能夠通過減少磁盤訪問來提升查詢速度,與現實中的書籍目錄異曲同工。索引通常包含兩部分,即索引鍵(≈章節)與指向原始數據的指針(≈頁碼),如下圖所示。
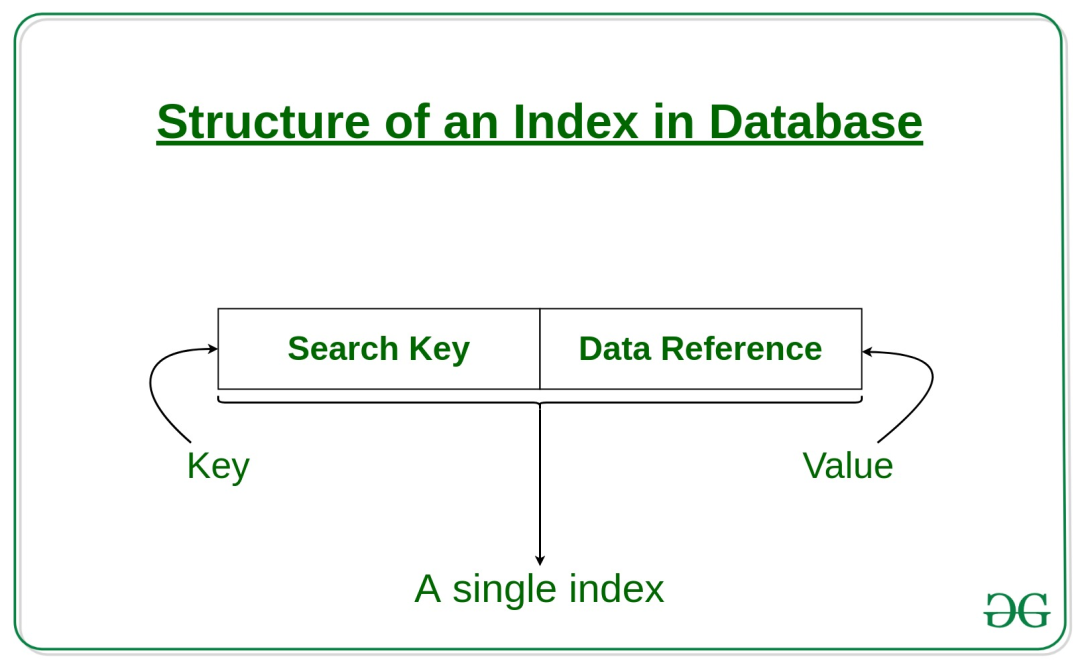
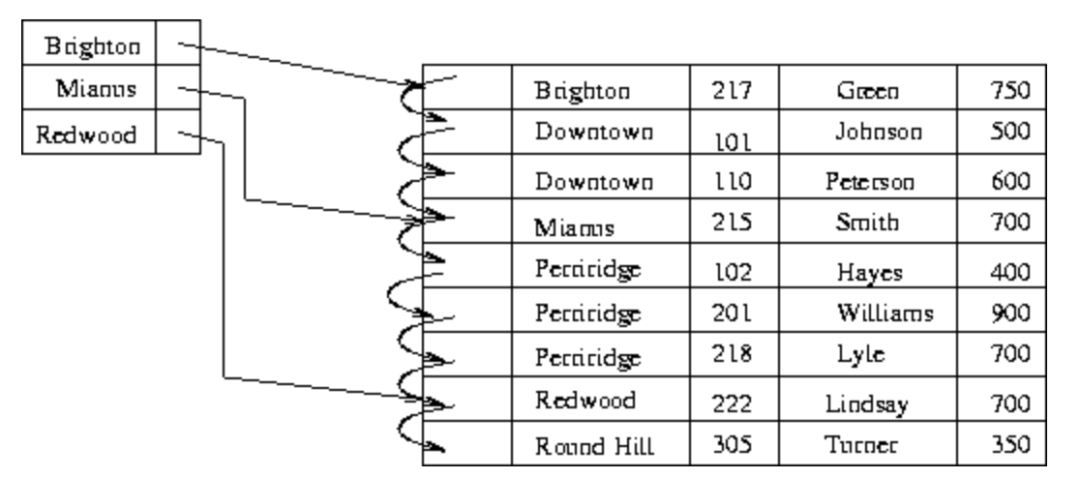
索引的組織形式多種多樣,本文要介紹的稀疏索引(sparse index)是一種簡單而常用的有序索引形式——即在數據主鍵有序的基礎上,只為部分(通常是較少一部分)原始數據建立索引,從而在查詢時能夠圈定出大致的范圍,再在范圍內利用適當的查找算法找到目標數據。如下圖所示,為3條原始數據建立了稀疏索引。
相對地,如果為所有原始數據建立索引,就稱為稠密索引(dense index),如下圖。
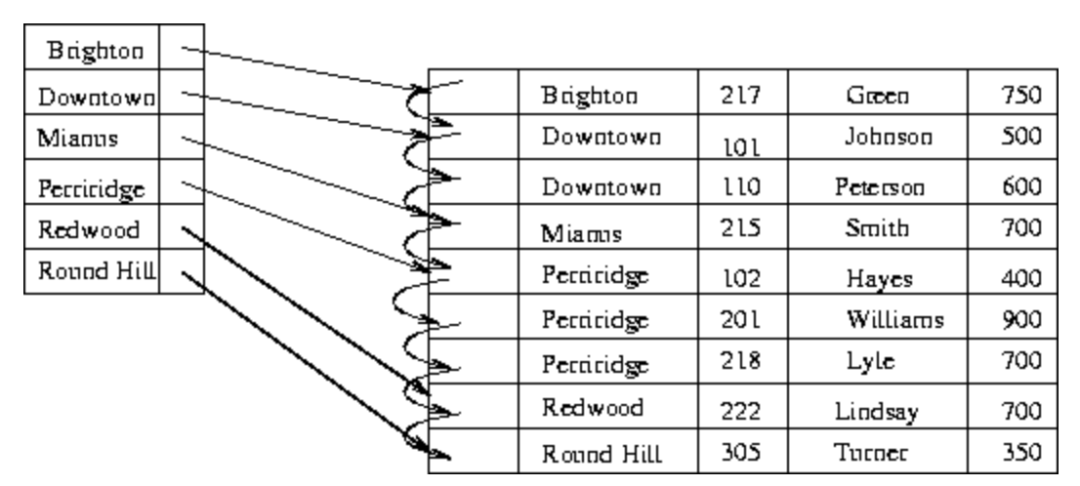
稠密索引和稀疏索引其實就是空間和時間的trade-off。在數據量巨大時,為每條數據都建立索引也會耗費大量空間,所以稀疏索引在特定場景非常好用。以下舉兩個例子。
我們知道,單個Kafka的TopicPartition中,消息數據會被切分成段(segment)來存儲,擴展名為.log。log文件的切分時機由大小參數log.segment.bytes(默認值1G)和時間參數log.roll.hours(默認值7天)共同決定。數據目錄中存儲的部分文件如下。
.
├── 00000000000190089251.index
├── 00000000000190089251.log
├── 00000000000190089251.timeindex
├── 00000000000191671269.index
├── 00000000000191671269.log
├── 00000000000191671269.timeindex
├── 00000000000193246592.index
├── 00000000000193246592.log
├── 00000000000193246592.timeindex
├── 00000000000194821538.index
├── 00000000000194821538.log
├── 00000000000194821538.timeindex
├── 00000000000196397456.index
├── 00000000000196397456.log
├── 00000000000196397456.timeindex
├── 00000000000197971543.index
├── 00000000000197971543.log
├── 00000000000197971543.timeindex
......
log文件的文件名都是64位整形,表示這個log文件內存儲的第一條消息的offset值減去1(也就是上一個log文件最后一條消息的offset值)。每個log文件都會配備兩個索引文件——index和timeindex,分別對應偏移量索引和時間戳索引,且均為稀疏索引。
可以通過Kafka提供的DumpLogSegments小工具來查看索引文件中的信息。
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
offset: 197971551 position: 5207
offset: 197971558 position: 9927
offset: 197971565 position: 14624
offset: 197971572 position: 19338
offset: 197971578 position: 23509
offset: 197971585 position: 28392
offset: 197971592 position: 33174
offset: 197971599 position: 38036
offset: 197971606 position: 42732
......
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
timestamp: 1593230317565 offset: 197971551
timestamp: 1593230317642 offset: 197971558
timestamp: 1593230317979 offset: 197971564
timestamp: 1593230318346 offset: 197971572
timestamp: 1593230318558 offset: 197971578
timestamp: 1593230318579 offset: 197971582
timestamp: 1593230318765 offset: 197971592
timestamp: 1593230319117 offset: 197971599
timestamp: 1593230319442 offset: 197971606
......
可見,index文件中存儲的是offset值與對應數據在log文件中存儲位置的映射,而timeindex文件中存儲的是時間戳與對應數據offset值的映射。有了它們,就可以快速地通過offset值或時間戳定位到消息的具體位置了。并且由于索引文件的size都不大,因此很容易將它們做內存映射(mmap),存取效率很高。
以index文件為例,如果我們想要找到offset=197971577的消息,流程是:
通過二分查找,在index文件序列中,找到包含該offset的文件(00000000000197971543.index);
通過二分查找,在上一步定位到的index文件中,找到該offset所在區間的起點(197971592);
從上一步的起點開始順序查找,直到找到目標offset。
最后,稀疏索引的粒度由log.index.interval.bytes參數來決定,默認為4KB,即每隔log文件中4KB的數據量生成一條索引數據。調大這個參數會使得索引更加稀疏,反之則會更稠密。
在ClickHouse中,MergeTree引擎表的索引列在建表時使用ORDER BY語法來指定。而在官方文檔中,用了下面一幅圖來說明。

這張圖示出了以CounterID、Date兩列為索引列的情況,即先以CounterID為主要關鍵字排序,再以Date為次要關鍵字排序,最后用兩列的組合作為索引鍵。marks與mark numbers就是索引標記,且marks之間的間隔就由建表時的索引粒度參數index_granularity來指定,默認值為8192。
ClickHouse MergeTree引擎表中,每個part的數據大致以下面的結構存儲。
.
├── business_area_id.bin
├── business_area_id.mrk2
├── coupon_money.bin
├── coupon_money.mrk2
├── groupon_id.bin
├── groupon_id.mrk2
├── is_new_order.bin
├── is_new_order.mrk2
......
├── primary.idx
......
其中,bin文件存儲的是每一列的原始數據(可能被壓縮存儲),mrk2文件存儲的是圖中的mark numbers與bin文件中數據位置的映射關系。另外,還有一個primary.idx文件存儲被索引列的具體數據。另外,每個part的數據都存儲在單獨的目錄中,目錄名形如20200708_92_121_7,即包含了分區鍵、起始mark number和結束mark number,方便定位。
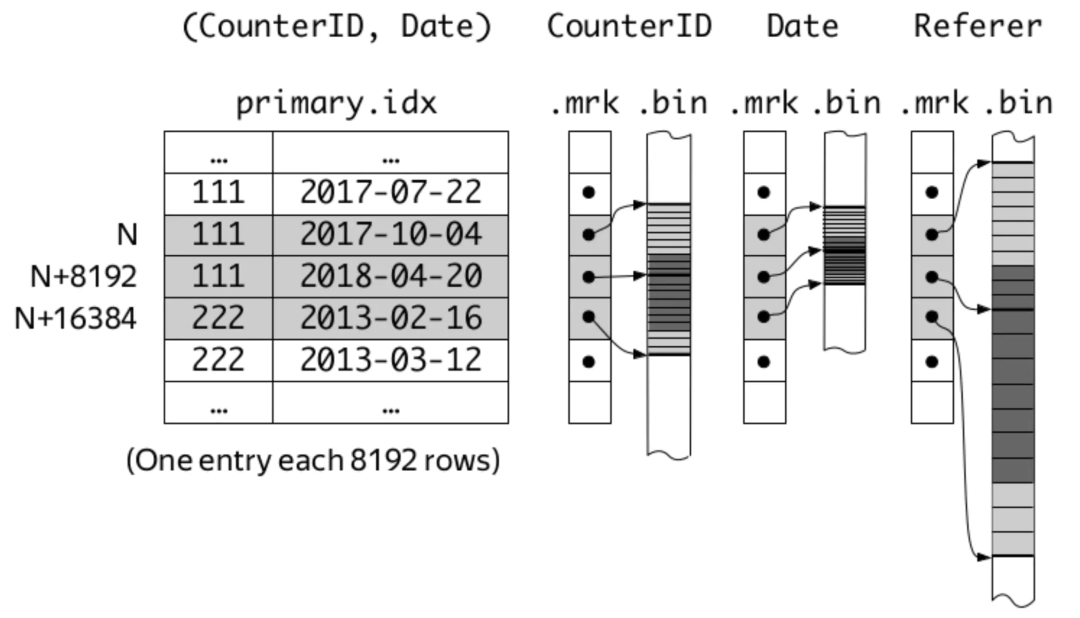
這樣,每一列都通過ORDER BY列進行了索引。查詢時,先查找到數據所在的parts,再通過mrk2文件確定bin文件中數據的范圍即可。
不過,ClickHouse的稀疏索引與Kafka的稀疏索引不同,可以由用戶自由組合多列,因此也要格外注意不要加入太多索引列,防止索引數據過于稀疏,增大存儲和查找成本。另外,基數太小(即區分度太低)的列不適合做索引列,因為很可能橫跨多個mark的值仍然相同,沒有索引的意義了。
到此,關于“Kafka和ClickHouse中的應用分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





