溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何使用MQTT與函數計算做熱力圖”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1. 數據通道的連接能力:數據通道隨著業務的擴展,機器人的投放也會同步增加,對于數據通道有足夠的擴展靈活性,可以按需進行擴展,同時連接的級別能夠支持10W+級別的擴展。
2. 簡潔數據清洗的能力:對于數據的處理,本質上就是對數據的歸納統計,邏輯實現上并不復雜。對于數據本身的峰谷變化,能有最簡單有效的匹配擴縮處理能力即可,在清洗上不希望為此引入復雜的傳統大數據級別的笨重方案。
3. 彈性數據訪問的能力:這里提到的的熱力圖信息,以后會考慮開放給終端用戶訪問,訪問量都是動態變化的,隨著不同的時間、節日、突發事件等都會有不可預知的幅度變化,所以在此業務中要求有彈性的訪問能力。業務方不希望通過限流方式來實現,因為會對業務量本身造成影響。
4. 性能優越的存儲能力:此場景下,數據寫入與讀取并發量都高,客戶希望使用NoSQL的方式進行存儲。NoSQL 類型能最好支持排序的功能,本文介紹的方案中使用Redis,不再做更多的分析介紹。
數據通道的連接能力
自建Kafka
優點:
Kafka作為通用的數據收集信息通道,使用面廣泛,接入方式多樣化。社區完善,學習成本低。
Kafka本身搭建容易,與下游的大數據處理產品協調方案成熟。
缺點:
動態處理Kafka的擴容復雜。
需要搭建額外處理集群的穩定性配套方案。
外網網絡流量管理需要配合額外的方案。
主流方案是作為連接應用的收集能力,對于終端的連接能力沒有規模級別的案例驗證。
優點:
支持百萬級別的連接,完成可以覆蓋業務發展的訴求,為業務留足了擴展空間。
MQTT的協議非常簡潔,在端與服務間的傳輸中有優勢。支持各種消息觸達的QoS質量。
支持各種客戶端接入實現語言。
可實時觀測客戶端的連接情況,方便發現異常情況。
缺點:
處理大數據的實踐沒有Kafka成熟,下游產品選型受一定的限制。
彈性數據清洗的能力
大數據方案(Storm、Spark、Flink等)
優點:
開源的通用方案,資料眾多,方案成熟。
缺點:
搭建運維復雜,需要提供額外的監控與恢復手段。
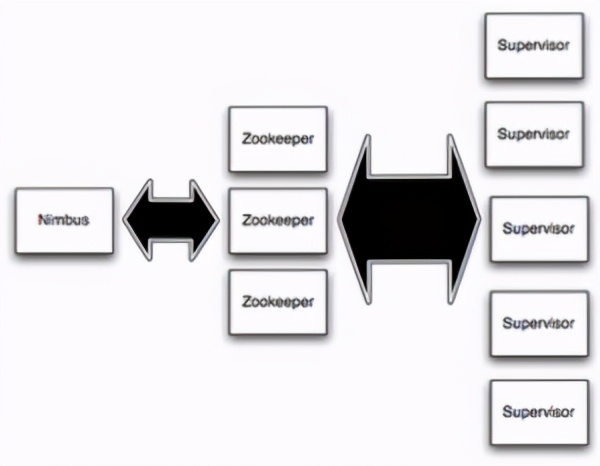
需要學習接受各種組件方式(下圖是以Storm為例)。
提前評估資源使用情況,無法按照實時數據量進行相應的擴縮使用。
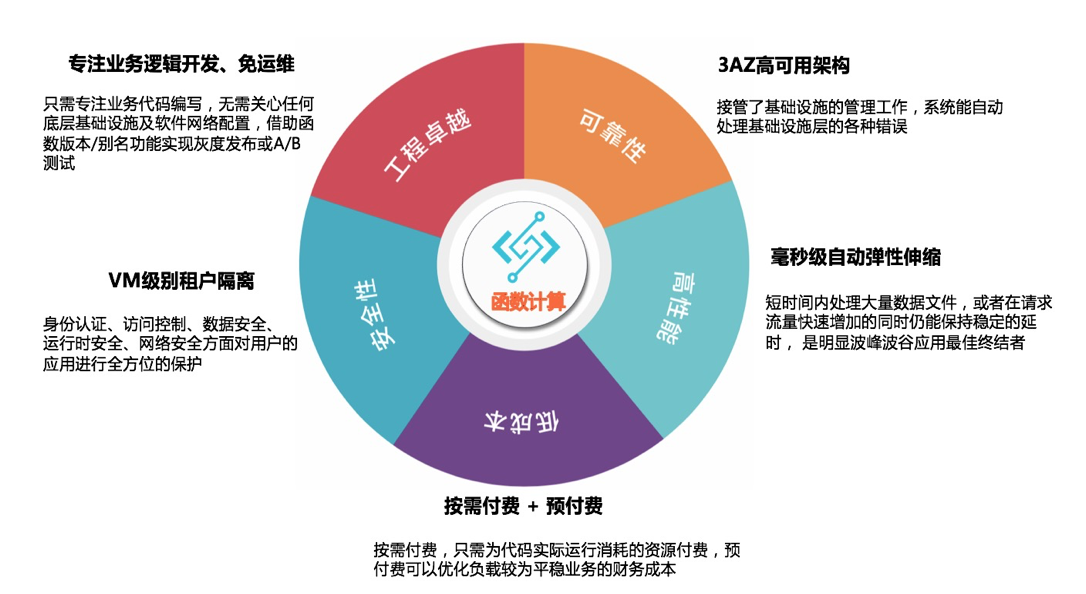
優點:
按需進行擴縮,百毫秒級的伸縮能力,適合數據量的脈沖峰谷變化。
不需要進行清洗環境的管理。
概念簡單,學習成本低。
其它優點參考下圖:
缺點:
函數計算是各個云廠商的產品。要求一定需要在云上運行。
優點:
作為業務的一部分嵌在某個應用實現中,技術成熟,學習成本低。
缺點:
需要自實現根據業務請求量來進行彈縮處理,或者很多時候采用評估的方式進行資源冗余處理。
優點:
根據客戶的請求量實時進行彈縮處理。按需使用,不為高峰時段煩惱,不會閑置付費。
自動附帶專業的訪問監控大盤。
缺點:
需要少量的學習成本。
在這個熱力圖信息收集清選與訪問業務中,可以參考使用下圖的解決方案完美實現。
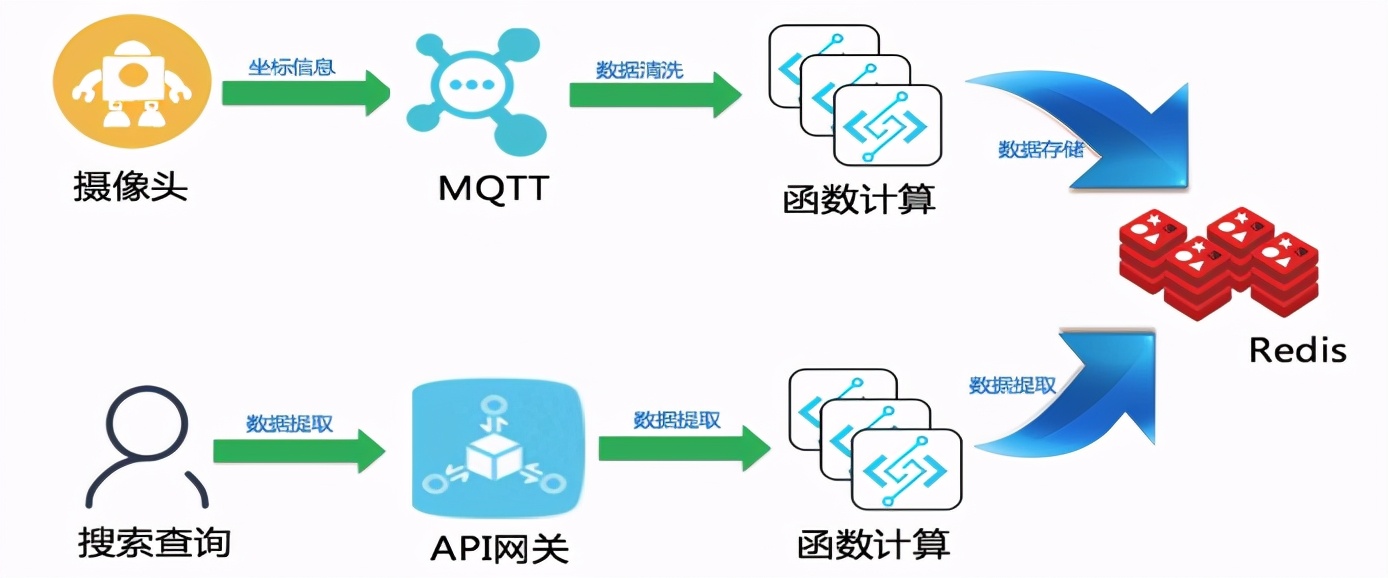
MQTT到函數計算的介紹
請參考函數計算的微消息隊列MQTT服務集成方案。

詳情請參考API網關函數觸發實例。
以Node.js為例:
module.exports.handler = function(event, context, callback) {
var event = JSON.parse(event); var content = {
path: event.path,
method: event.method,
headers: event.headers,
queryParameters: event.queryParameters,
pathParameters: event.pathParameters,
body: event.body // 您可以在這里編寫您自己的邏輯。
// 從Redis提取數據的邏輯
} var response = {
isBase64Encoded: false,
statusCode: '200',
headers: { 'x-custom-header': 'header value'},
body: content
};
callback(null, response)
};“如何使用MQTT與函數計算做熱力圖”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





