溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用Python和Keras進行血管分割,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
動機:
醫學圖像的自動分割是提取有用信息的重要步驟,可以幫助醫生進行診斷。例如它可以用于分割視網膜血管,可以代表它們的結構并測量它們的寬度,從而可以幫助診斷視網膜疾病。
在這篇文章中,將實現一個神經基線,將圖像分割應用于視網膜血管圖像。
數據集:
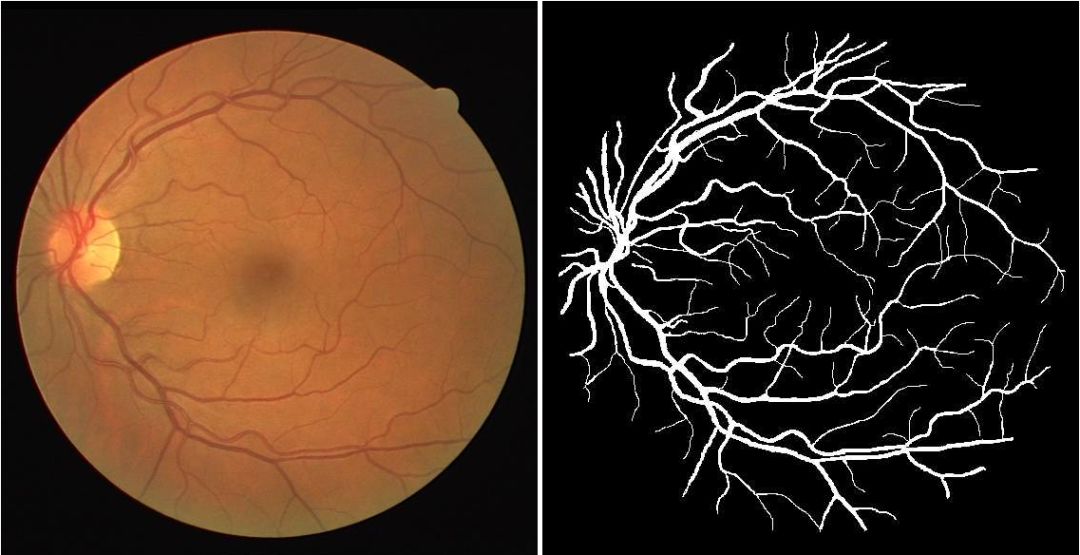
在整個文章中使用DRIVE(數字視網膜圖像用于血管提取)數據集進行所有實驗。它是40個視網膜圖像(20個用于訓練,20個用于測試)的數據集,其中血管在像素級注釋(參見上面的示例)以標記每個血管的存在(1)或不存在(0)。圖像的像素(i,j)。
http://www.isi.uu.nl/Research/Databases/DRIVE/
問題設定:
問題:如果像素是圖像中血管的一部分,希望為每個像素分配“1”標簽,否則為“0”。
直覺 / 假設:相鄰像素值對于對每個像素(i,j)進行預測很重要,因此應該考慮上下文。預測不依賴于圖像上的特定位置,因此分類器應具有一些平移不變性。
解決方案:使用CNN!將使用U-net架構進行血管分割。它是一種廣泛用于語義分割任務的體系結構,尤其是在醫學領域。
型號:
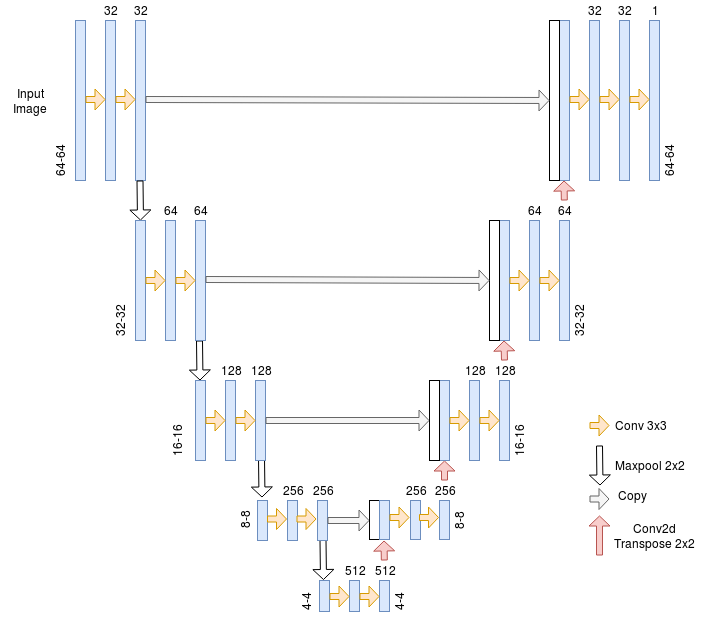
U-Net
U-net架構是編碼器 - 解碼器,在編碼器和解碼器之間具有一些跳過連接。該架構的主要優點是能夠在對像素進行預測時考慮更廣泛的上下文。這要歸功于上采樣操作中使用的大量通道。
輸入圖像處理:
在將其反饋到CNN之前應用這一系列處理步驟。
歸一化:將像素強度除以255,因此它們在0-1范圍內。
裁剪:由于匯集操作,網絡期望輸入圖像的每個維度可被2整除,因此從每個圖像中隨機裁剪64 * 64。
數據增強:隨機翻轉(水平或垂直或兩者),隨機剪切,隨機平移(水平或垂直或兩者),隨機縮放。僅在訓練期間執行。
訓練三種不同的模型:
預先訓練ImageNet VGG編碼器+數據增強。
從頭開始訓練+數據擴充。
從頭開始訓練而不增加數據。
將使用AUC ROC度量比較這三個模型,將僅在評估中考慮視網膜掩模內的像素(意味著圖像圓周圍的黑色邊緣將不計算)。
結果:
預先訓練的編碼器+數據增強AUC ROC:0.9820
從頭開始訓練+數據增加AUC ROC:0.9806
從頭開始訓練而不增加AUC ROC:0.9811
三種變化的性能接近,但在這種情況下,預訓練似乎沒有幫助,而數據增加有一點點。
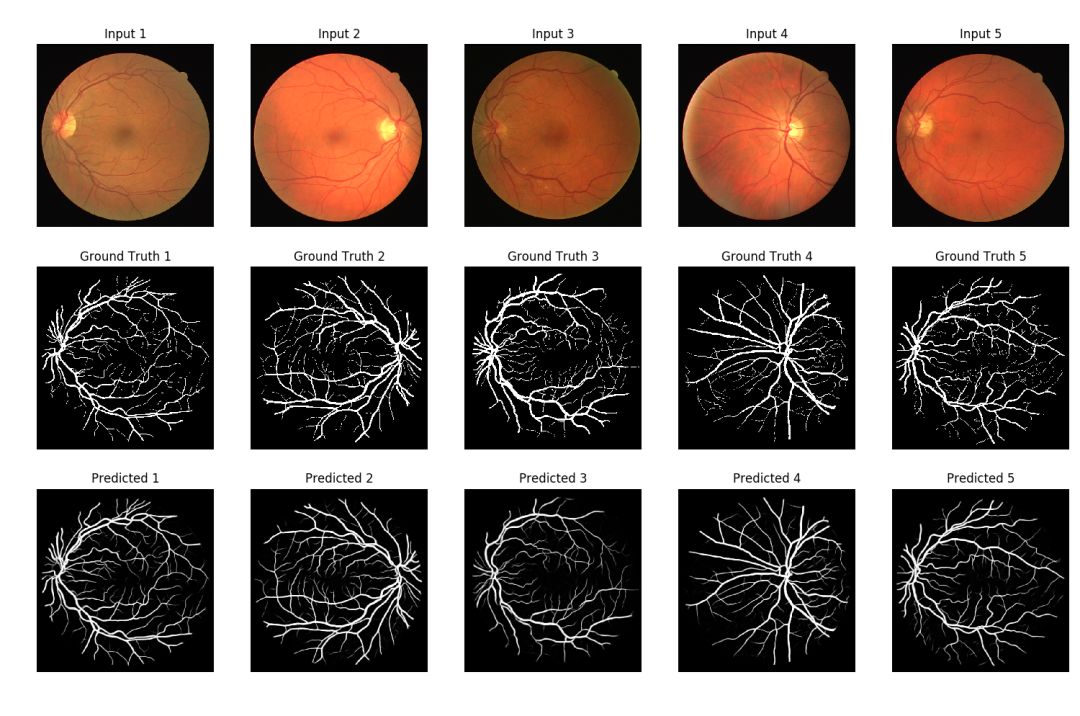
最佳模型預測
上圖中的預測看起來很酷!
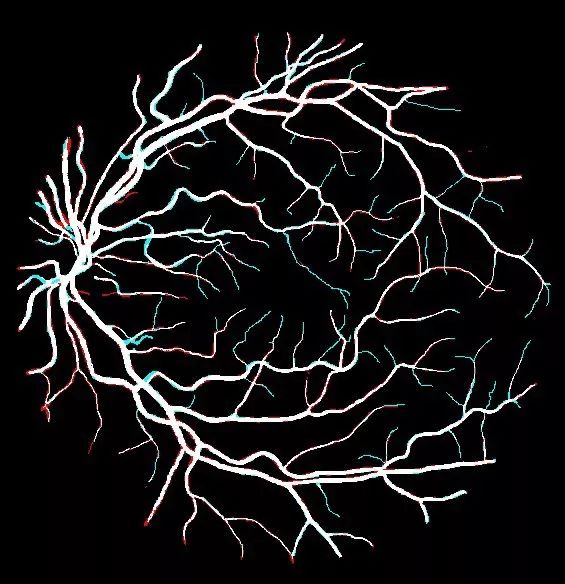
在基本事實之上的預測
還繪制了預測和基本事實之間的差異:藍色的假陰性和紅色的假陽性。可以看到該模型在預測僅一或兩個像素寬的細血管方面存在一些困難。
關于“如何使用Python和Keras進行血管分割”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





