溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Hadoop解決了哪些問題”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Hadoop解決了哪些問題”吧!
首先看一下Hadoop解決了什么問題,Hadoop就是解決了大數據(大到一臺計算機無法進行存儲,一臺計算機無法在要求的時間內進行處理)的可靠存儲和處理。
HDFS,在由普通PC組成的集群上提供高可靠的文件存儲,通過將塊保存多個副本的辦法解決服務器或硬盤壞掉的問題。
MapReduce,通過簡單的Mapper和Reducer的抽象提供一個編程模型,可以在一個由幾十臺上百臺的PC組成的不可靠集群上并發地,分布式地處理大量的數據集,而把并發、分布式(如機器間通信)和故障恢復等計算細節隱藏起來。而Mapper和Reducer的抽象,又是各種各樣的復雜數據處理都可以分解為的基本元素。這樣,復雜的數據處理可以分解為由多個Job(包含一個Mapper和一個Reducer)組成的有向無環圖(DAG),然后每個Mapper和Reducer放到Hadoop集群上執行,就可以得出結果。

?用MapReduce統計一個文本文件中單詞出現的頻率的示例WordCount請參見:WordCount - Hadoop Wiki,如果對MapReduce不恨熟悉,通過該示例對MapReduce進行一些了解對理解下文有幫助。
?在MapReduce中,Shuffle是一個非常重要的過程,正是有了看不見的Shuffle過程,才可以使在MapReduce之上寫數據處理的開發者完全感知不到分布式和并發的存在。
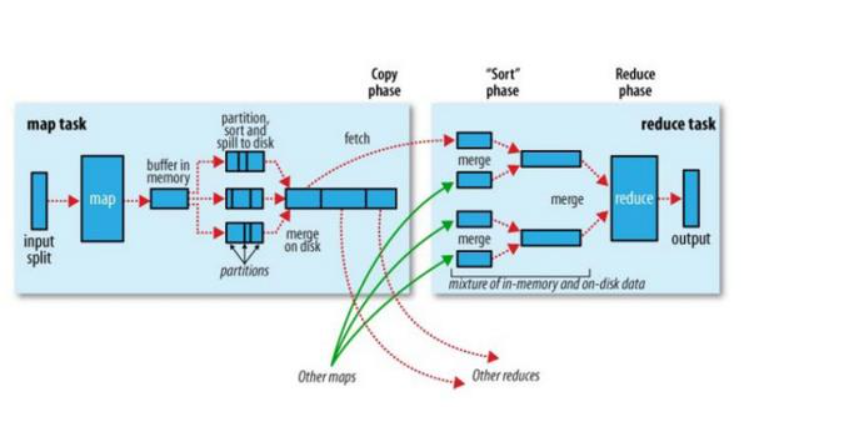
廣義的Shuffle是指圖中在Map和Reuce之間的一系列過程。
但是,MapRecue存在以下局限,使用起來比較困難。
抽象層次低,需要手工編寫代碼來完成,使用上難以上手。
只提供兩個操作,Map和Reduce,表達力欠缺。
一個Job只有Map和Reduce兩個階段(Phase),復雜的計算需要大量的Job完成,Job之間的依賴關系是由開發者自己管理的。
處理邏輯隱藏在代碼細節中,沒有整體邏輯
中間結果也放在HDFS文件系統中
ReduceTask需要等待所有MapTask都完成后才可以開始
時延高,只適用Batch數據處理,對于交互式數據處理,實時數據處理的支持不夠
對于迭代式數據處理性能比較差
比如說,用MapReduce實現兩個表的Join都是一個很有技巧性的過程,如下圖所示:
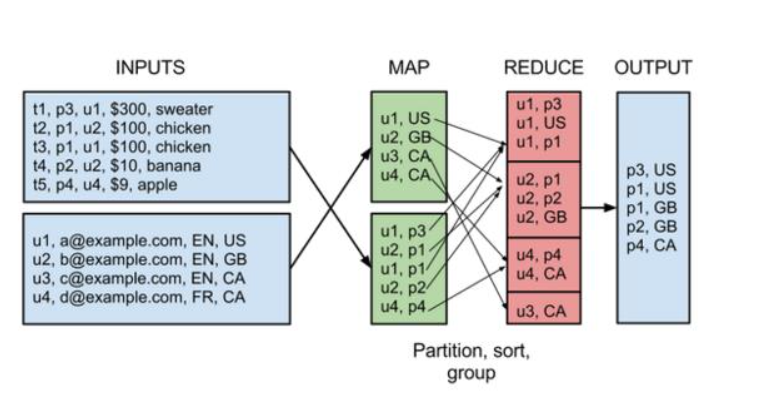
因此,在Hadoop推出之后,出現了很多相關的技術對其中的局限進行改進,如Pig,Cascading,JAQL,OOzie,Tez,Spark等。
Apache Pig也是Hadoop框架中的一部分,Pig提供類SQL語言(Pig Latin)通過MapReduce來處理大規模半結構化數據。而Pig Latin是更高級的過程語言,通過將MapReduce中的設計模式抽象為操作,如Filter,GroupBy,Join,OrderBy,由這些操作組成有向無環圖(DAG)。例如如下程序:
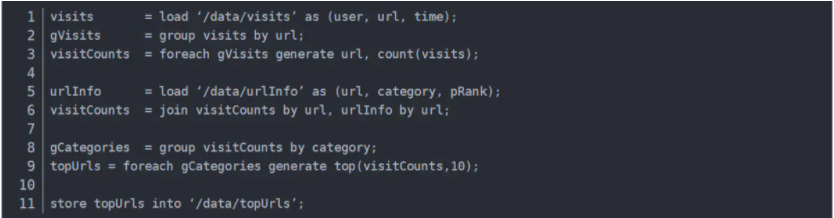
描述了數據處理的整個過程。
?而Pig Latin又是通過編譯為MapReduce,在Hadoop集群上執行的。上述程序被編譯成MapReduce時,會產生如下圖所示的Map和Reduce:
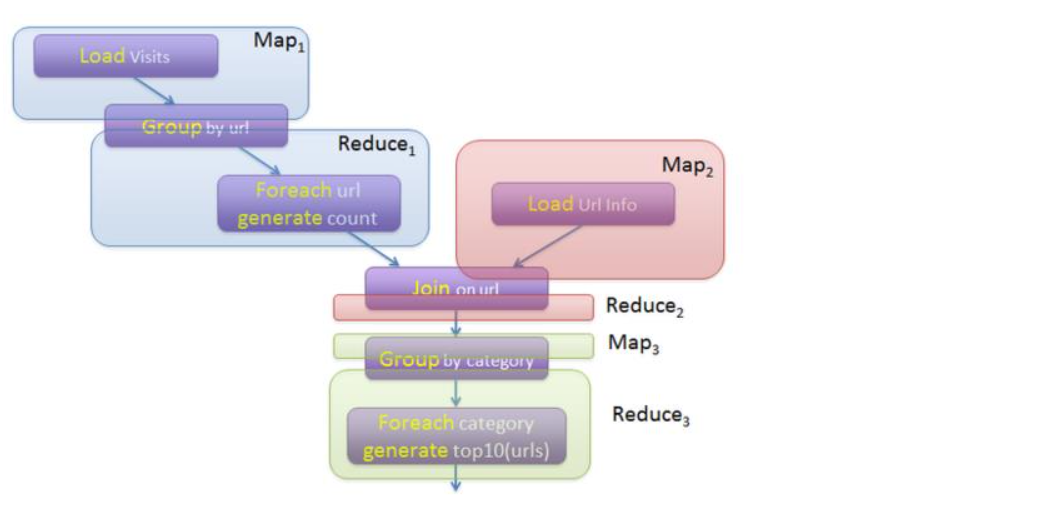
Apache Pig解決了MapReduce存在的大量手寫代碼,語義隱藏,提供操作種類少的問題。類似的項目還有Cascading,JAQL等。
Apache Tez,Tez是HortonWorks的Stinger Initiative的的一部分。作為執行引擎,Tez也提供了有向無環圖(DAG),DAG由頂點(Vertex)和邊(Edge)組成,Edge是對數據的移動的抽象,提供了One-To-One,BroadCast,和Scatter-Gather三種類型,只有Scatter-Gather才需要進行Shuffle。
以如下SQL為例:

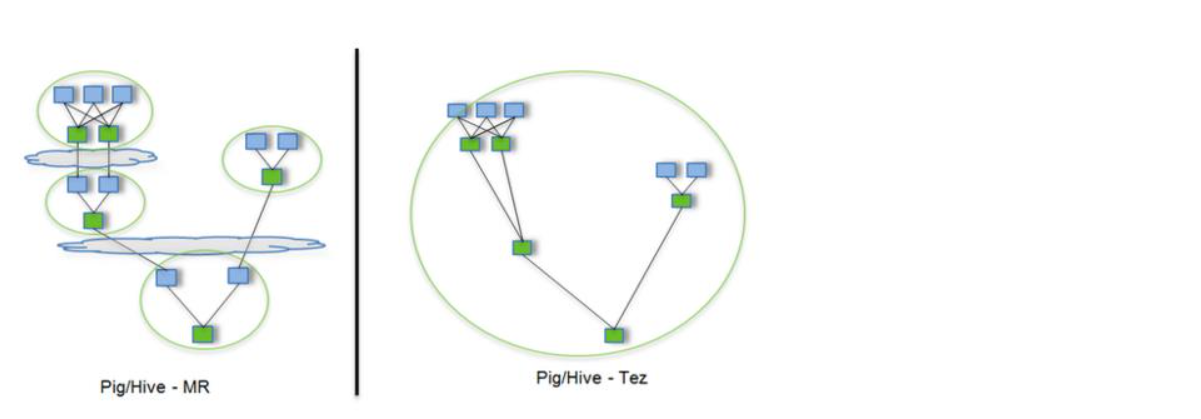
途中藍色方塊表示Map,綠色方塊表示Reduce,云狀表示寫屏障(write barrier,一種內核機制,可以理解為持久的寫),Tez的優化主要體現在:去除了連續兩個作業之間的寫屏障去除了每個工作流中多余的Map階段(Stage)
通過提供DAG語義和操作,提供了整體的邏輯,通過減少不必要的操作,Tez提升了數據處理的執行性能。
Apache Spark是一個新興的大數據處理的引擎,主要特點是提供了一個集群的分布式內存抽象,以支持需要工作集的應用。
?這個抽象就是RDD(Resilient Distributed Dataset),RDD就是一個不可變的帶分區的記錄集合,RDD也是Spark中的編程模型。Spark提供了RDD上的兩類操作,轉換和動作。轉換是用來定義一個新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等,動作是返回一個結果,包括collect, reduce, count, save, lookupKey。
Spark的API非常簡單易用,Spark的WordCount的示例如下所示:

其中的file是根據HDFS上的文件創建的RDD,后面的flatMap,map,reduceByKe都創建出一個新的RDD,一個簡短的程序就能夠執行很多個轉換和動作。
在Spark中,所有RDD的轉換都是是惰性求值的。RDD的轉換操作會生成新的RDD,新的RDD的數據依賴于原來的RDD的數據,每個RDD又包含多個分區。那么一段程序實際上就構造了一個由相互依賴的多個RDD組成的有向無環圖(DAG)。并通過在RDD上執行動作將這個有向無環圖作為一個Job提交給Spark執行。
例如,上面的WordCount程序就會生成如下的DAG
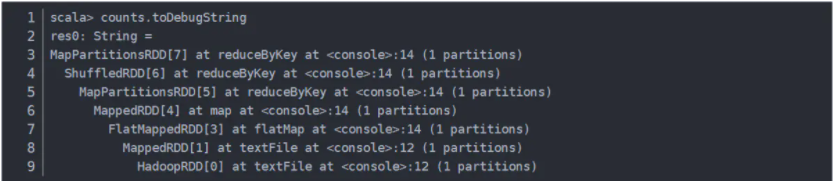
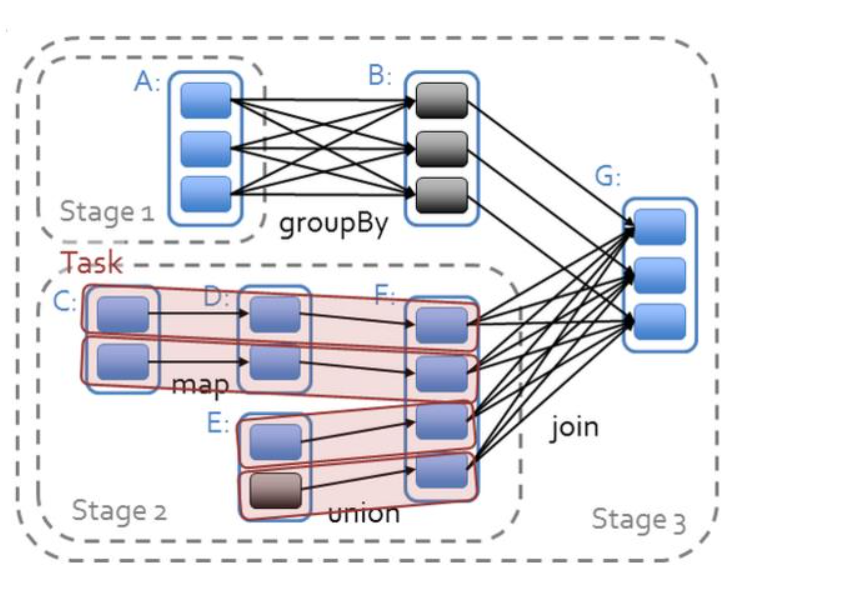
Spark對于有向無環圖Job進行調度,確定階段(Stage),分區(Partition),流水線(Pipeline),任務(Task)和緩存(Cache),進行優化,并在Spark集群上運行Job。RDD之間的依賴分為寬依賴(依賴多個分區)和窄依賴(只依賴一個分區),在確定階段時,需要根據寬依賴劃分階段。根據分區劃分任務。
?Spark支持故障恢復的方式也不同,提供兩種方式,Linage,通過數據的血緣關系,再執行一遍前面的處理,Checkpoint,將數據集存儲到持久存儲中。
Spark為迭代式數據處理提供更好的支持。每次迭代的數據可以保存在內存中,而不是寫入文件。
Spark的性能相比Hadoop有很大提升,2014年10月,Spark完成了一個Daytona Gray類別的Sort Benchmark測試,排序完全是在磁盤上進行的,與Hadoop之前的測試的對比結果如表格所示:
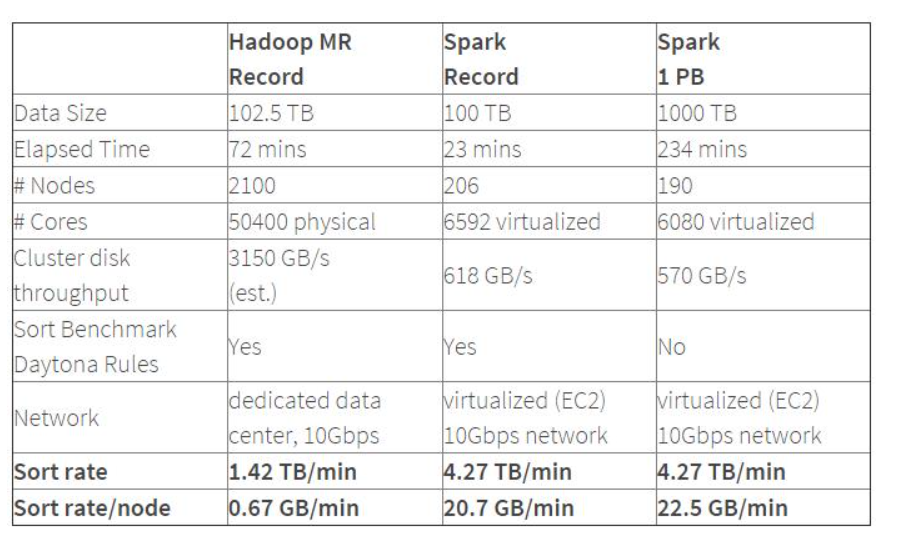
從表格中可以看出排序100TB的數據(1萬億條數據),Spark只用了Hadoop所用1/10的計算資源,耗時只有Hadoop的1/3。
Spark的優勢不僅體現在性能提升上的,Spark框架為批處理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),機器學習(MLlib),圖計算(GraphX)提供一個統一的數據處理平臺,這相對于使用Hadoop有很大優勢。
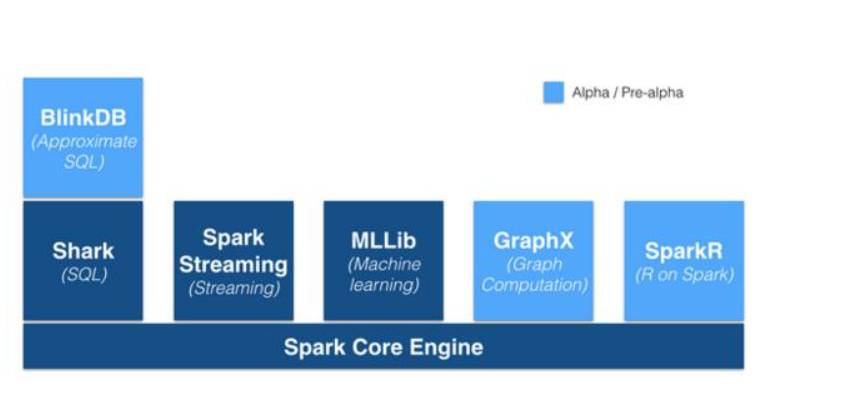
按照Databricks的連城的說法是One Stack To Rule Them All
特別是在有些情況下,你需要進行一些ETL工作,然后訓練一個機器學習的模型,最后進行一些查詢,如果是使用Spark,你可以在一段程序中將這三部分的邏輯完成形成一個大的有向無環圖(DAG),而且Spark會對大的有向無環圖進行整體優化。
例如下面的程序:

這段程序的第一行是用Spark SQL 查尋出了一些點,第二行是用MLlib中的K-means算法使用這些點訓練了一個模型,第三行是用Spark Streaming處理流中的消息,使用了訓練好的模型。
Lambda Architecture是一個大數據處理平臺的參考模型,如下圖所示:
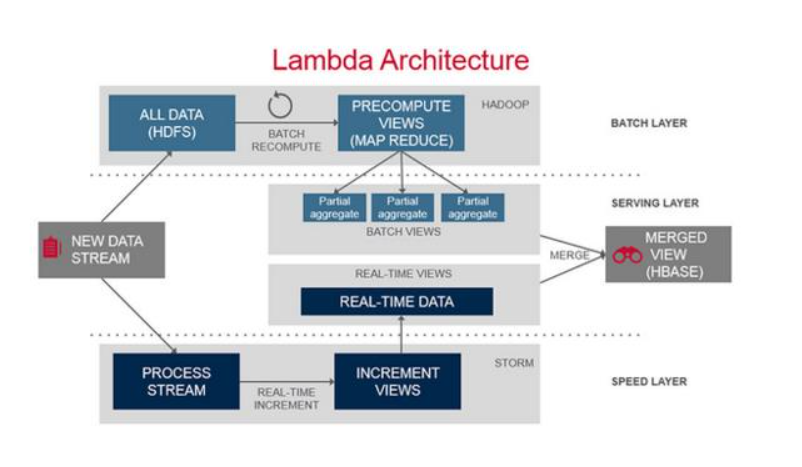
其中包含3層,Batch Layer,Speed Layer和Serving Layer,由于Batch Layer和Speed Layer的數據處理邏輯是一致的,如果用Hadoop作為Batch Layer,而用Storm作為Speed Layer,你需要維護兩份使用不同技術的代碼。
而Spark可以作為Lambda Architecture一體化的解決方案,大致如下:
Batch Layer,HDFS+Spark Core,將實時的增量數據追加到HDFS中,使用Spark Core批量處理全量數據,生成全量數據的視圖。,
Speed Layer,Spark Streaming來處理實時的增量數據,以較低的時延生成實時數據的視圖。
Serving Layer,HDFS+Spark SQL(也許還有BlinkDB),存儲Batch Layer和Speed Layer輸出的視圖,提供低時延的即席查詢功能,將批量數據的視圖與實時數據的視圖合并。
如果說,MapReduce是公認的分布式數據處理的低層次抽象,類似邏輯門電路中的與門,或門和非門,那么Spark的RDD就是分布式大數據處理的高層次抽象,類似邏輯電路中的編碼器或譯碼器等。
RDD就是一個分布式的數據集合(Collection),對這個集合的任何操作都可以像函數式編程中操作內存中的集合一樣直觀、簡便,但集合操作的實現確是在后臺分解成一系列Task發送到幾十臺上百臺服務器組成的集群上完成的。最近新推出的大數據處理框架Apache Flink也使用數據集(Data Set)和其上的操作作為編程模型的。
由RDD組成的有向無環圖(DAG)的執行是調度程序將其生成物理計劃并進行優化,然后在Spark集群上執行的。Spark還提供了一個類似于MapReduce的執行引擎,該引擎更多地使用內存,而不是磁盤,得到了更好的執行性能。
抽象層次低,需要手工編寫代碼來完成,使用上難以上手。
=>基于RDD的抽象,實數據處理邏輯的代碼非常簡短。
只提供兩個操作,Map和Reduce,表達力欠缺。
=>提供很多轉換和動作,很多基本操作如Join,GroupBy已經在RDD轉換和動作中實現。
一個Job只有Map和Reduce兩個階段(Phase),復雜的計算需要大量的Job完成,Job之間的依賴關系是由開發者自己管理的。
=>一個Job可以包含RDD的多個轉換操作,在調度時可以生成多個階段(Stage),而且如果多個map操作的RDD的分區不變,是可以放在同一個Task中進行。
處理邏輯隱藏在代碼細節中,沒有整體邏輯
=>在Scala中,通過匿名函數和高階函數,RDD的轉換支持流式API,可以提供處理邏輯的整體視圖。代碼不包含具體操作的實現細節,邏輯更清晰。
中間結果也放在HDFS文件系統中
=>中間結果放在內存中,內存放不下了會寫入本地磁盤,而不是HDFS。
ReduceTask需要等待所有MapTask都完成后才可以開始
=> 分區相同的轉換構成流水線放在一個Task中運行,分區不同的轉換需要Shuffle,被劃分到不同的Stage中,需要等待前面的Stage完成后才可以開始。
時延高,只適用Batch數據處理,對于交互式數據處理,實時數據處理的支持不夠
=>通過將流拆成小的batch提供Discretized Stream處理流數據。
對于迭代式數據處理性能比較差
=>通過在內存中緩存數據,提高迭代式計算的性能。
因此,Hadoop MapReduce會被新一代的大數據處理平臺替代是技術發展的趨勢,而在新一代的大數據處理平臺中,Spark目前得到了最廣泛的認可和支持,從參加Spark Summit 2014的廠商的各種基于Spark平臺進行的開發就可以看出一二。
感謝各位的閱讀,以上就是“Hadoop解決了哪些問題”的內容了,經過本文的學習后,相信大家對Hadoop解決了哪些問題這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





