溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章的內容主要圍繞怎樣淺談分布式ID的實踐與應用進行講述,文章內容清晰易懂,條理清晰,非常適合新手學習,值得大家去閱讀。感興趣的朋友可以跟隨小編一起閱讀吧。希望大家通過這篇文章有所收獲!
在業務系統中很多場景下需要生成不重復的 ID,比如訂單編號、支付流水單號、優惠券編號等都需要使用到。小編將介紹分布式 ID 的產生原因,以及目前業界常用的四種分布式 ID 實現方案,并且詳細介紹其中兩種的實現以及優缺點,
隨著業務數據量的增長,存儲在數據庫中的數據越來越多,當索引占用的空間超出可用內存大小后,就會通過磁盤索引來查找數據,這樣就會極大的降低數據查詢速度。如何解決這樣的問題呢?一般我們首先通過分庫分表來解決,分庫分表后就無法使用數據庫自增 ID 來作為數據的唯一編號,那么就需要使用分布式 ID 來做唯一編號了。
目前,關于分布式 ID ,業界主要有以下四種實現方案:
UUID:使用 JDK 的 UUID#randomUUID() 生成的 ID;
Redis 的原子自增:使用 Jedis#incr(String key) 生成的 ID;
Snowflake 算法:以時間戳機器號和毫秒內并發組成的 64 位 Long 型 ID;
分段步長:按照步長從數據庫讀取一段可用范圍的 ID;
我們總結一下這幾種方案的特點:
| 方案 | 順序性 | 重復性 | 可用性 | 部署方式 | 可用時間 |
|---|---|---|---|---|---|
| UUID | 無序 | 通過多位隨機字符達到極低重復概率,但理論上是會重復的 | 一直可用 | JDK 直接調用 | 永久 |
| Redis | 單調遞增 | RDB 持久化模式下,會出現重復 | Redis 宕機后不可用 | Jedis 客戶端調用 | 永久 |
| Snowflake | 趨勢遞增 | 不會重復 | 發生時鐘回撥并且回撥時間超過等待閾值時不可用 | 集成部署、集群部署 | 69年 |
| 分段步長 | 趨勢遞增 | 不會重復 | 如果數據庫宕機并且獲取步長內的 ID 用完后不可用 | 集成部署、集群部署 | 永久 |
前面兩種實現方案的用法以及實現大家日常了解較多,就不在此贅述...本文我們會詳細介紹 Snowflake 算法以及分段步長方案。
Snowflake 算法可以做到分配好機器號后就可以使用,不依賴任何第三方服務實現本地 ID 生成,依賴的第三方服務越少可用性越高,那么我們先來介紹一下 Snowflake 算法。
長整型數字(即 Long 型數字)的十進制范圍是 -2^64 到 2^64-1。
Snowflake 使用的是無符號長整型數字,即從左到右一共 64 位二進制組成,但其第一位是不使用的。所以,在 Snowflake 中使用的是 63bit 的長整型無符號數字,它們由時間戳、機器號、毫秒內并發序列號三個部分組成 :
時間戳位:當前毫秒時間戳與新紀元時間戳的差值(所謂新紀元時間戳就是應用開始使用 Snowflake 的時間。如果不設置新紀元時間,時間戳默認是從1970年開始計算的,設置了新紀元時間可以延長 Snowflake 的可用時間)。41 位 2 進制轉為十進制是 2^41,除以(365 天 * 24 小時 * 3600 秒 * 1000 毫秒),約等于 69年,所以最多可以使用 69 年;
機器號:10 位 2 進制轉為十進制是 2^10,即 1024,也就是說最多可以支持有 1024 個機器節點;
毫秒內并發序列號:12 位 2 進制轉為十進制是 2^12,即 4096,也就是說一毫秒內在一個機器節點上并發的獲取 ID,最多可以支持 4096 個并發;
下面我們來看一下各個分段的使用情況:
| 二進制分段 | [1] | [2, 42] | [43, 52] | [53, 64] |
|---|---|---|---|---|
| 說明 | 最高符號位不使用 | 一共41位,是毫秒時間戳位 | 一個10位,是機器號位 | 一共12位,是毫秒內并發序列號,當前請求的時間戳如果和上一次請求的時間戳相同,那么就將毫秒內并發序列號加一 |
那么 Snowflake 生成的 ID 長什么樣子呢?下面我們來舉幾個例子(假設我們的時間戳新紀元是 2020-12-31 00:00:00):
| 時間 | 機器號 | 毫秒并發 | 十進制 Snowflake ID |
|---|---|---|---|
| 2021-01-01 08:33:11 | 1 | 10 | 491031363588106 |
| 2021-01-02 13:11:12 | 2 | 25 | 923887730696217 |
| 2021-01-03 21:22:01 | 3 | 1 | 1409793654796289 |
Snowflake 可以使用三種不同的部署方式來部署,集成分布式部署方式、中心集群式部署方式、直連集群式部署方式。下面我們來分別介紹一下這幾種部署方式。
當使用 ID 的應用節點比較少時,比如 200 個節點以內,適合使用集成分布式部署方式。每個應用節點在啟動的時候決定了機器號后,運行時不依賴任何第三方服務,在本地使用時間戳、機器號、以及毫秒內并發序列號生成 ID。
下圖展示的是應用服務器通過引入 jar 包的方式實現獲取分布式 ID 的過程。每一個使用分布式 ID 的應用服務器節點都會分配一個拓撲網絡內唯一的機器號。這個機器號的管理存放在 MySQL 或者 ZooKeeper 上。
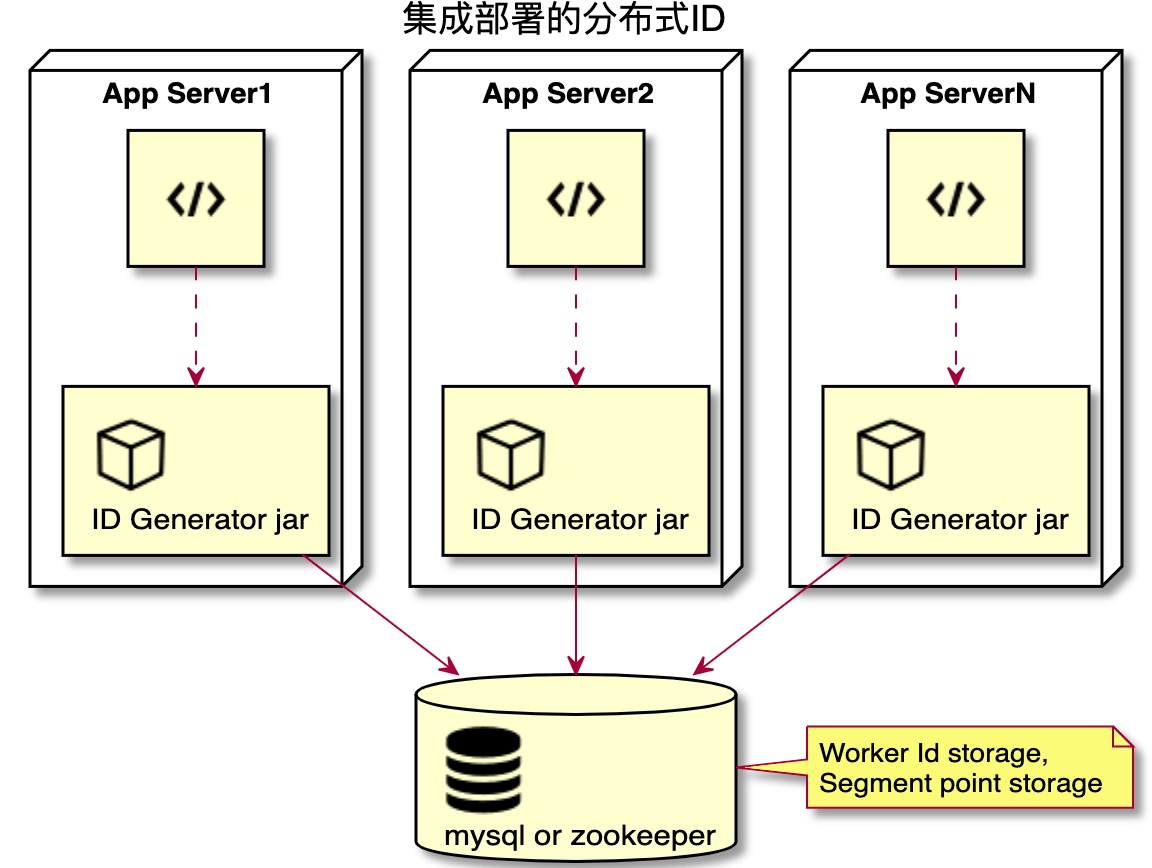
當拓撲網絡內使用分布式 ID 的機器節點很多,例如超過 1000 個機器節點時,使用集成部署的分布式 ID 就不合適了,因為機器號位一共是 10 位,即最多支持 1024 個機器號。當機器節點超過 1000 個機器節點時,可以使用下面要介紹的中心集群式部署方式。
中心集群式部署需要新增用來做請求轉發的 ID 網關,比如使用 nginx 反向代理(即下圖中的 ID REST API Gateway)。
使用 ID 網關組網后,應用服務器通過 HTTP 或 RPC 請求 ID 網關獲取分布式 ID。這樣相比于上面的集成分布式部署方式,就可以支撐更多的應用節點使用分布式 ID 了。
如圖所示,機器號的分配只是分配給下圖中的 ID Generator node 節點,應用節點是不需要分配機器號的。
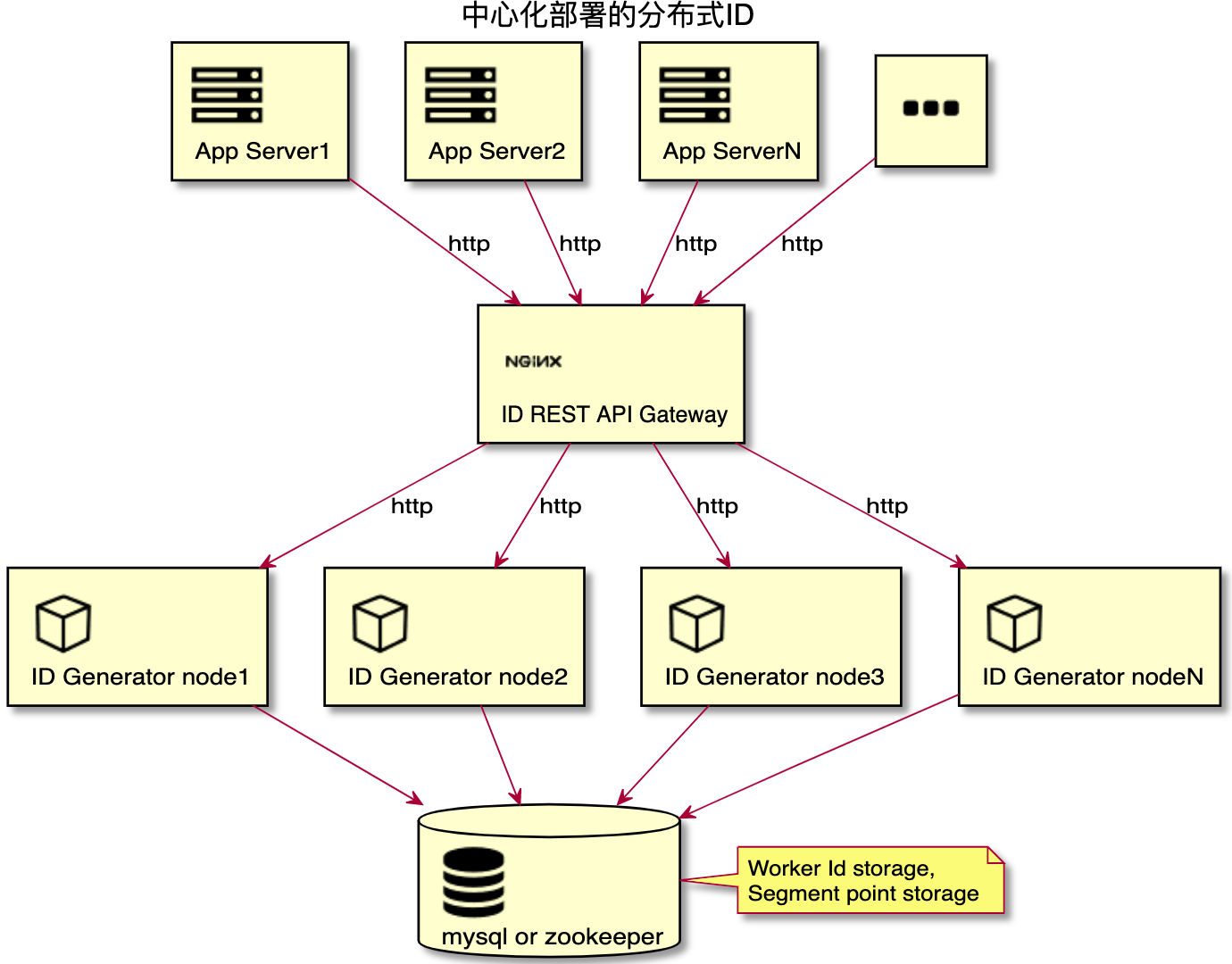
使用中心集群式部署方式需要引入新的 nginx 反向代理做網關,增加了系統的復雜性,降低了服務的可用性。那么我們下面再介紹一種不需要引入 nginx 又可以支持超過 1000 個應用節點的直連集群部署方式。
相比于中心集群部署方式,直連集群部署方式可以去掉中間的 ID 網關,提高服務的可用性。
在使用 ID 網關的時候,我們需要把 ID generator node 的服務地址配置在 ID 網關中。而在使用直連集群式部署方式時,ID generator node 的服務地址可以配置在應用服務器本地配置文件中,或者配置在配置中心。應用服務器獲取到服務地址列表后,需要實現服務路由,直連 ID 生成器獲取 ID。
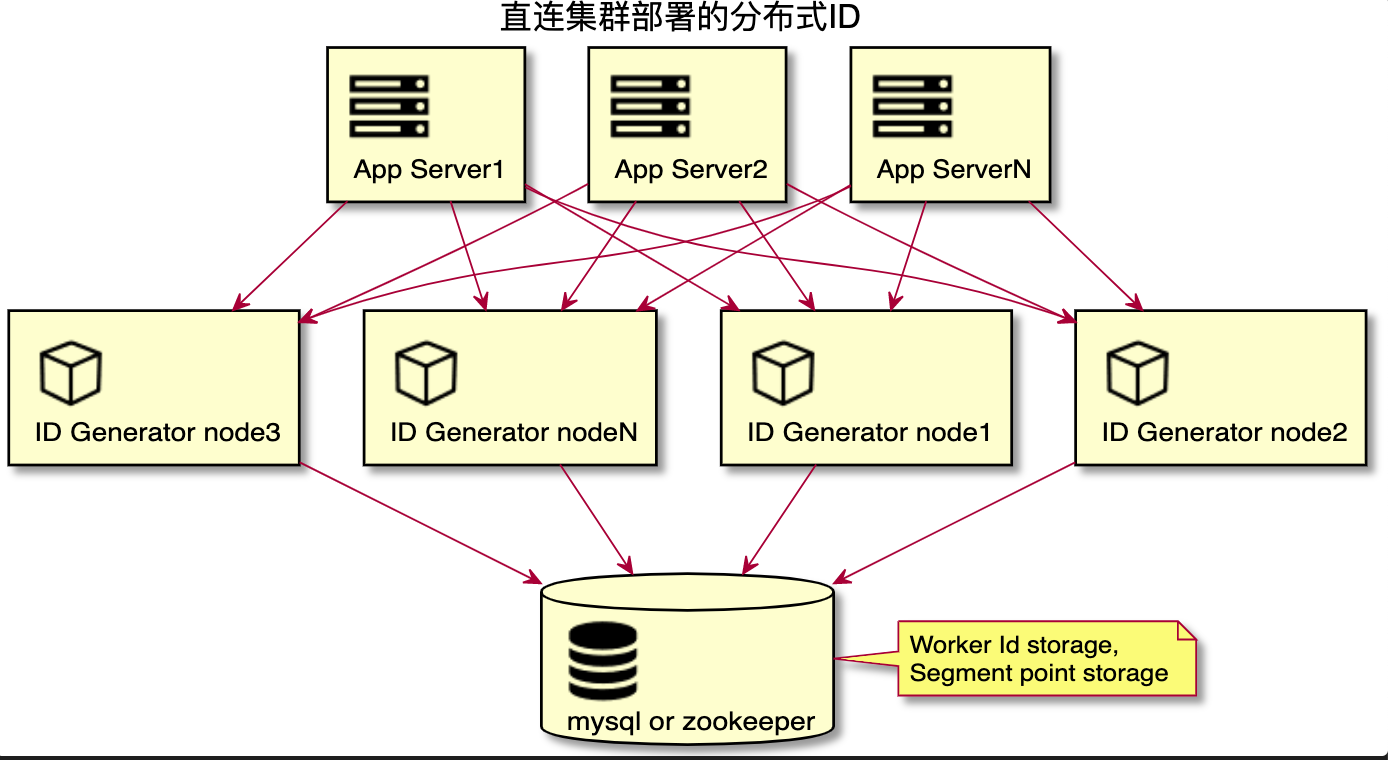
Snowflake 算法是強依賴時間戳的算法,如果一旦發生時鐘回撥就會產生 ID 重復的問題。那么時鐘回撥是怎么產生的,我們又需要怎么去解決這個問題呢?
NTP(Network Time Protocol)服務自動校準可能導致時鐘回撥。我們身邊的每一臺計算機都有自己本地的時鐘,這個時鐘是根據 CPU 的晶振脈沖計算得來的,然而隨著運行時間的推移,這個時間和世界時間的偏差會越來越大,那么 NTP 就是用來做時鐘校準的服務。
一般情況下發生時鐘回撥的概率也非常小,因為一旦出現本地時間相對于世界時間需要校準,但時鐘偏差值小于 STEP 閾值(默認128毫秒)時,計算機會選擇以 SLEW 的方式進行同步,即以 0.5 毫秒/秒的速度差調整時鐘速度,保證本地時鐘是一直連續向前的,不產生時鐘回撥,直到本地時鐘和世界時鐘對齊。
然而如果本地時鐘和世界時鐘相差大于 STEP 閾值時,就會發生時鐘回撥。這個 STEP 閾值是可以修改的,但是修改的越大,在 SLEW 校準的時候需要花費的校準時間就越長,例如 STEP 閾值設置為 10 分鐘,即本地時鐘與世界時鐘偏差在 10 分鐘以內時都會以 SLEW 的方式進行校準,這樣最多會需要 14 天才會完成校準。
為了避免時鐘回撥導致重復 ID 的問題,可以使用 128 毫秒的 STEP 閾值,同時在獲取 SnowflakeID 的時候與上一次的時間戳相比,判斷時鐘回撥是否在 1 秒鐘以內,如果在 1 秒鐘以內,那么等待 1 秒鐘,否則服務不可用,這樣可以解決時鐘回撥 1 秒鐘的問題。
Snowflake 由于是將時間戳作為長整形的高位,所以導致生成的最小數字也非常大。比如超過時間新紀元 1 秒鐘,機器號為 1,毫秒并發序列為 1 時,生成的 ID 就已經到 4194308097 了。那么有沒有一種方法能夠實現在初始狀態生成數字較小的 ID 呢?答案是肯定的,下面來介紹一下分段步長 ID 方案。
使用分段步長來生成 ID 就是將步長和當前最大 ID 存在數據庫中,每次獲取 ID 時更新數據庫中的 ID 最大值增加步長。
數據庫核心表結構如下所示:
CREATE TABLE `segment_id` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `biz_type` varchar(64) NOT NULL DEFAULT '', // 業務類型 `max` bigint(20) DEFAULT '0', // 當前最大 ID 值 `step` bigint(20) DEFAULT '10000', // ID 步長 PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
在獲取 ID 時,使用開啟事務,利用行鎖保證讀取到當前更新的最大 ID 值:
start transaction; update segment_id set max = max + step where biz_type = 'ORDER'; select max from segment_id where biz_type = 'ORDER'; commit
分段步長 ID 生成方案的優缺點:
優點:ID 生成不依賴時間戳,ID 生成初始值可以從 0 開始逐漸增加;
缺點:當服務重啟時需要將最大 ID 值增加步長,頻繁重啟的話就會浪費掉很多分段。
上文介紹了 Snowflake 算法以及分段步長方案,他們各有優缺點,針對他們各自的情況我們在本文也給出相應的優化方案。
為了提高 SnowflakeID 的并發性能和可用性,可以使用 ID 緩沖環(即 ID Buffer Ring)。提高并發性提現在通過使用緩沖環能夠充分利用毫秒時間戳,提高可用性提現在可以相對緩解由時鐘回撥導致的服務不可用。緩沖環是通過定長數組加游標哈希實現的,相比于鏈表會不需要頻繁的內存分配。
在 ID 緩沖環初始化的時候會請求 ID 生成器將 ID 緩沖環填滿,當業務需要獲取 ID 時,從緩沖環的頭部依次獲取 ID。當 ID 緩沖環中剩余的 ID 數量少于設定的閾值百分比時,比如剩余 ID 數量少于整個 ID 緩沖環的 30% 時,觸發異步 ID 填充加載。異步 ID 填充加載會將新生成的 ID 追加到 ID 緩沖環的隊列末尾,然后按照哈希算法映射到 ID 緩沖環上。另外有一個單獨的定時器異步線程來定時填充 ID 緩沖環。
下面的動畫展示了 ID 緩沖環的三個階段:ID 初始化加載、ID 消費、ID 消費后填充:
Buffer Ring Initialize load,ID 緩沖環初始化加載:從 ID generator 獲取到 ID 填充到 ID 緩沖環,直到 ID 緩沖環被填滿;
Buffer Ring consume,ID 緩沖環消費:業務應用從 ID 緩沖環獲取 ID;
Async reload,異步加載填充 ID 緩沖環:定時器線程負責異步的從 ID generator 獲取 ID 添加到 ID 緩沖隊列,同時按照哈希算法映射到 ID 緩沖環上,當 ID 緩沖環被填滿時,異步加載填充結束;
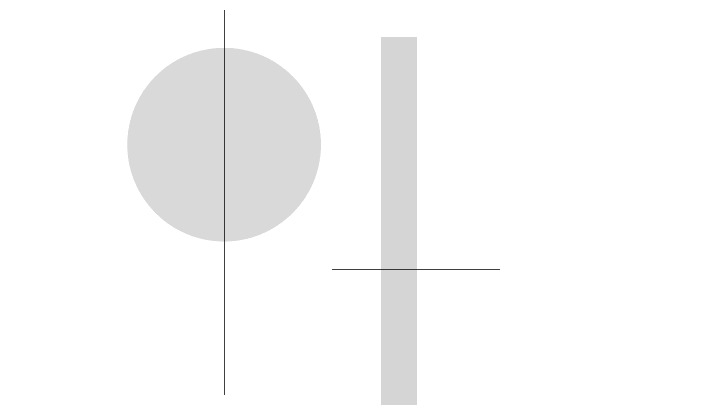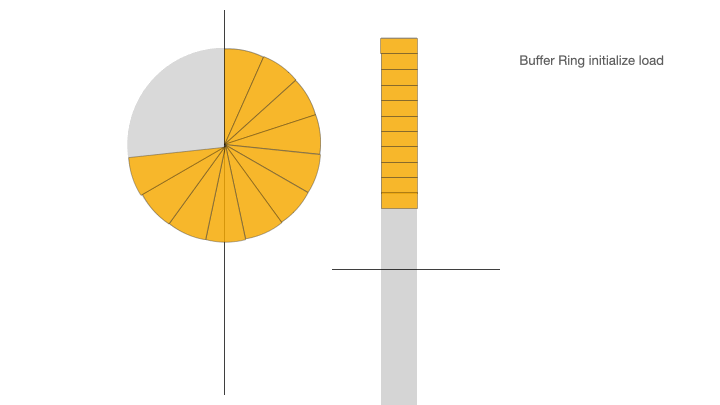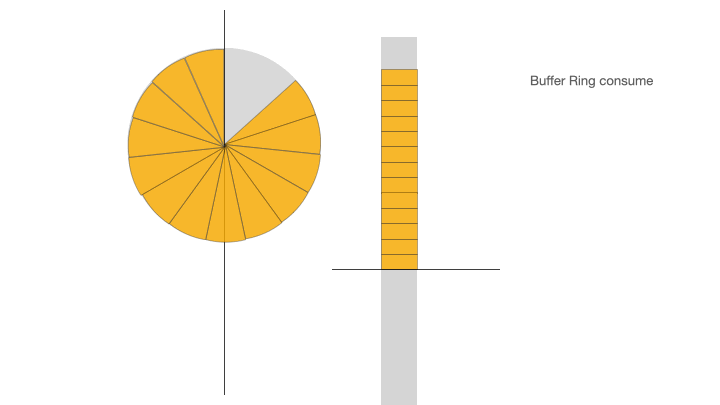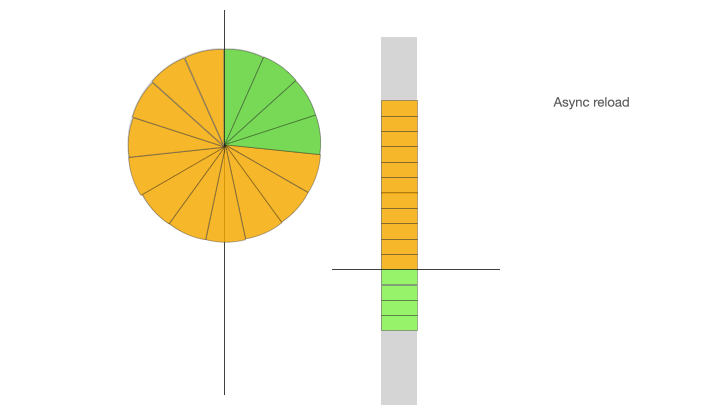
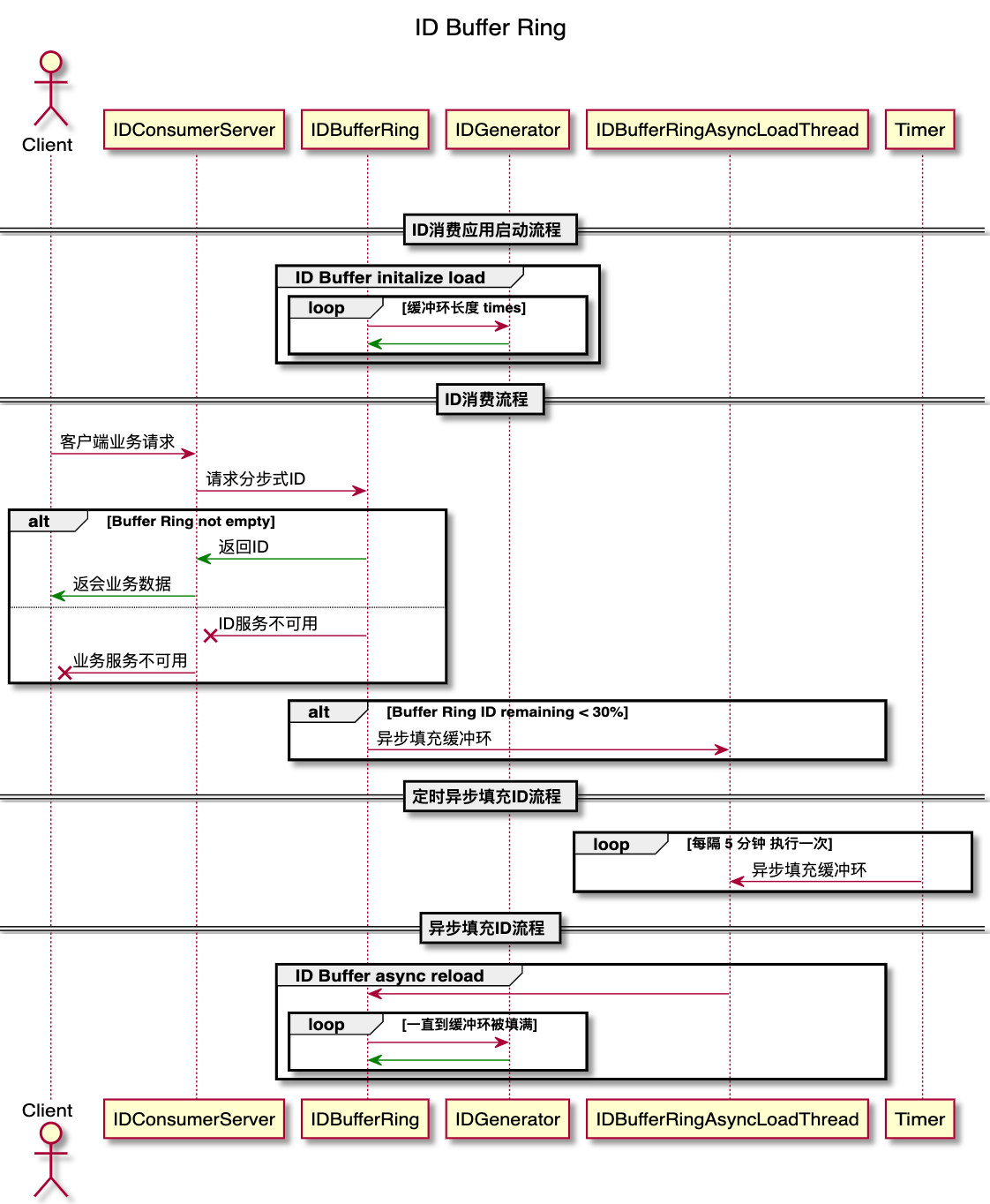
下面的流程圖展示了 ID 緩沖環的運行的整個生命周期,其中:
IDConsumerServer:表示使用分布式 ID 的業務系統;
IDBufferRing:ID 緩沖環;
IDGenerator:ID 生成器;
IDBufferRingAsyncLoadThread:異步加載 ID 到緩沖環的線程;
Timer:負責定時向異步加載線程添加任務來裝載 ID;
ID 消費流程:即 上面提到的 Buffer Ring consume;
整體流程:客戶端業務請求到應用服務器,應用服務器從 ID 緩沖環獲取 ID,如果 ID 緩沖環內空了那么拋出服務不可用;如果 ID 緩沖環內存有 ID 那么就消費一個 ID 。同時在消費 ID 緩沖環中的 ID 時,如果發現 ID 緩沖環中存留的 ID 數量少于整個 ID 緩沖環容量的 30% 時觸發異步加載填充 ID 緩沖環。
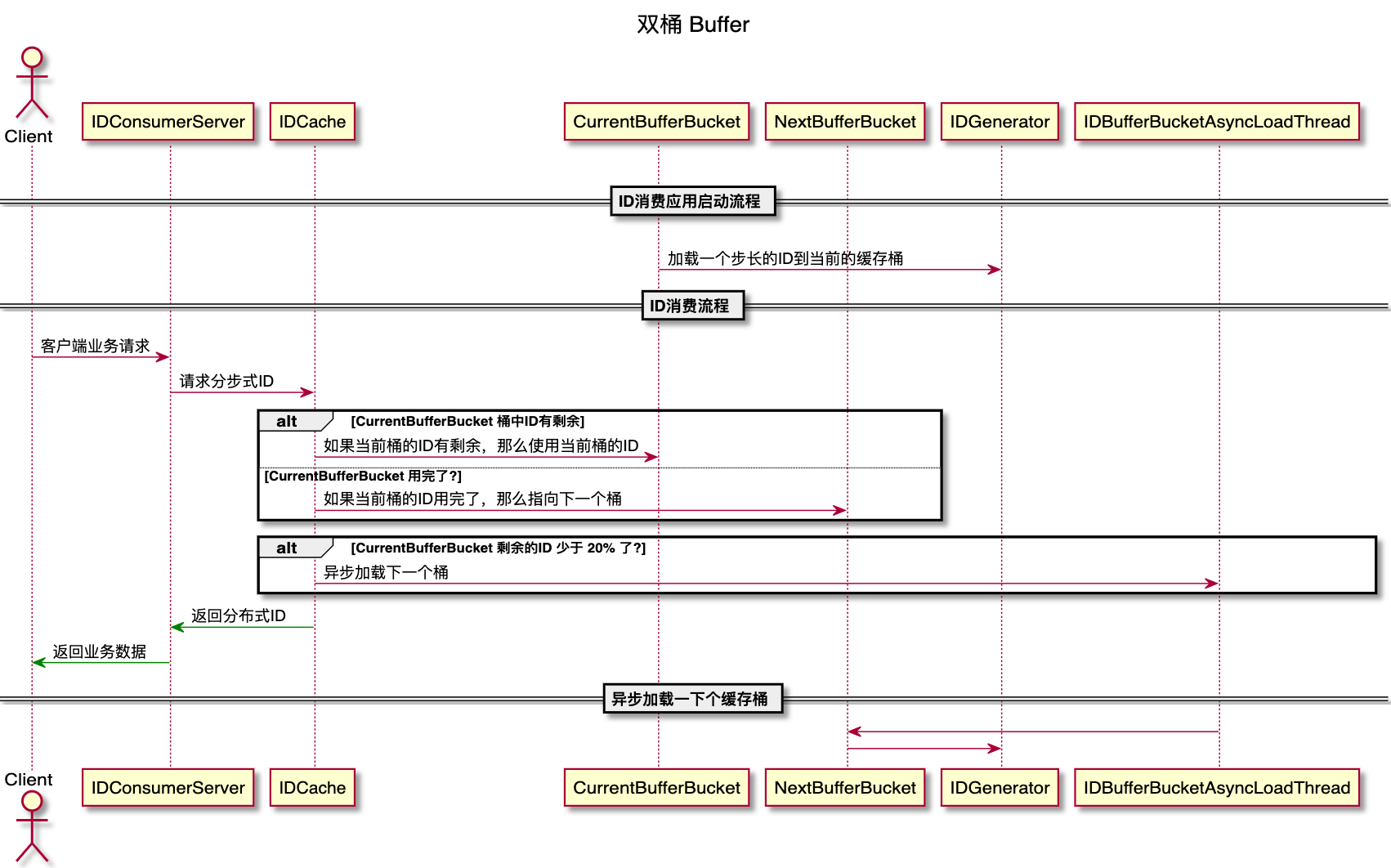
在使用分段步長 ID 時,如果該分段的 ID 用完了,需要更新數據庫分段最大值再繼續提供 ID 生成服務,為了減少數據庫更新查詢可能帶來的延時對 ID 服務的性能影響,可以使用雙桶緩存方案來提高 ID 生成服務的可用性。
其主要原理:設計兩個緩存桶:currentBufferBucket 和 nextBufferBucket,每個桶都存放一個步長這么多的 ID,如果當前緩存桶的 ID 用完了,那么就將下一個緩存桶設置為當前緩存桶。
下面的動畫展示了雙桶緩存初始化、異步加載預備桶和將預備桶切換成當前桶的全過程:
Current bucket initial load:初始化當前的緩存桶,即更新 max = max + step,然后獲取更新后的 max 值,比如步長是 1000,更新后的 max 值是 1000,那么桶的高度就是步長即 1000,桶 min = max - step + 1 = 1,max = 1000;
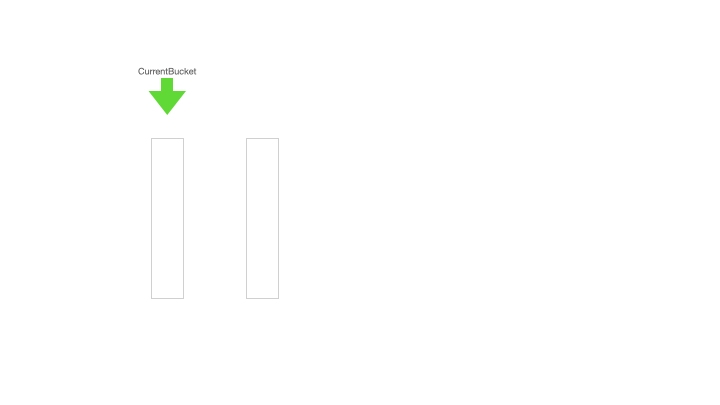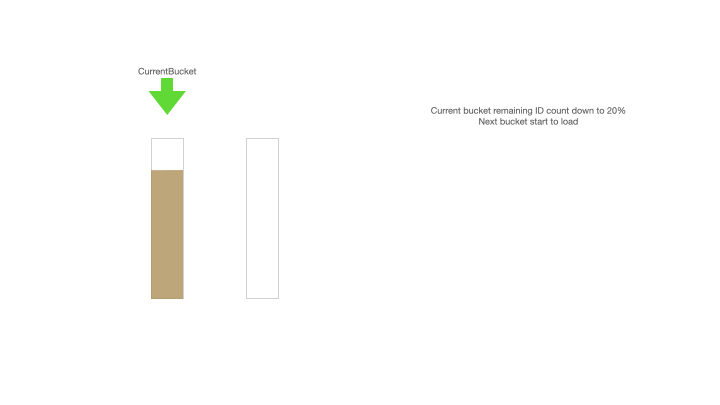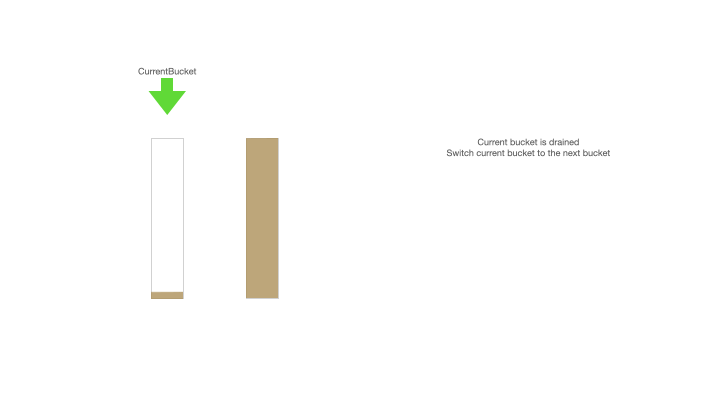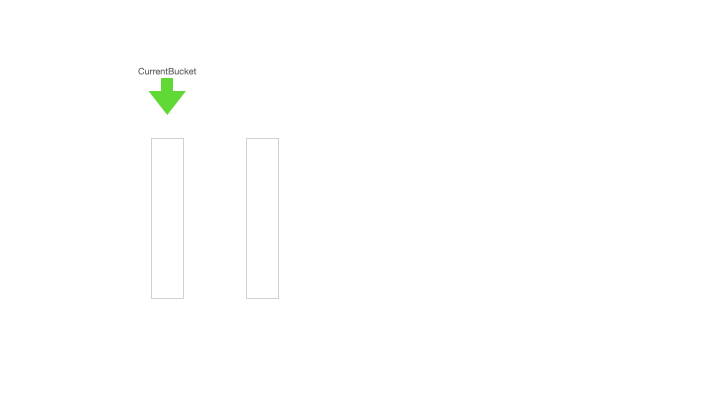
Current bucket remaining id count down to 20%,Next bucket start to load。當前緩存桶的 ID 剩余不足 20% 的時候可以加載下一個緩存桶,即更新 max = max + step,后獲取更新后的 max 值,此時更新后的 max 值是 2000,min = max - step + 1 = 1001, max = 2000;
Current bucket is drained,Switch current bucket to the next bucket,如果當前桶的 ID 全部用完了,那么就將下一個 ID 緩存桶設置為當前桶;
下面是雙桶 Buffer 的流程圖:
感謝你的閱讀,相信你對“怎樣淺談分布式ID的實踐與應用”這一問題有一定的了解,快去動手實踐吧,如果想了解更多相關知識點,可以關注億速云網站!小編會繼續為大家帶來更好的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





