溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了xPath注入的基礎語法有哪些,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
首先什么是xPath:xPath是一種在xml查找信息的語言
在xPath中,有七種元素的節點:元素、屬性、文本、命名空間、處理指令、注釋以及文檔(根節點)。xml文檔被當作文檔樹來解析,樹的根被稱為文檔節點或者根節點。

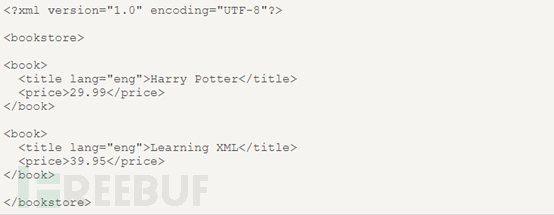
這是一份基本的xml文檔的源碼,從這份xml源碼中可以看出,bookstore為文檔節點(根節點),book、title、author、year、price是元素節點。其中book節點擁有四個子元素節點:title、author、year、price,title節點有三個同胞:author、year、price。title這個元素節點擁有一個屬性和文本節點,屬性節點是lang,值為en,文本節點的值是HarryPotter。
下面還有一些xml節點關系的描述(類似于數據結構中的樹):
父:book節點的父為bookstore,book節點是title、author、year、price節點的父。(每個節點只能有一個父)。
子:book是bookstore的子,book節點的子是title、author、year、price的子。
(元素節點可以有零個、一個或者多個子)。
同胞:擁有相同父的節點,類似于樹結構的兄弟節點,title的同胞是author、year、price。(節點可以有零個、一個或者多個同胞)。
先輩:節點的父、父的父、父的父的父(無限循環),title元素節點的先輩就是book、bookstore。
后代:節點的子、子的子、子的子的子(無線循環),bookstore文檔節點的后代就是book、title、author、year、price、lang。
知道了xml的節點關系還不夠,還需要知道它是如何進行查詢的,xPath通過路徑表達式來選取文檔中的節點或者節點集。節點是沿著路徑或者步來選取的。
XPath 使用路徑表達式在 XML 文檔中選取節點。節點是通過沿著路徑或者 step 來選取的。 下面列出了最有用的路徑表達式:
nodename:選取此節點的所有接待你
/:從根節點選取
//:從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置
.:選取當前節點
..:選取當前節點的父節點
@:選取屬性
下面直接來通過js使用xpath查詢語法來進行查詢
首先寫一份關于xpath調用的html(調用的代碼寫到js中)文件模板,然后準備好一份xml文件用來查詢。
js模板的源代碼如下:
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
挨個看一下這份html文件中的js代碼(因為只有js代碼)
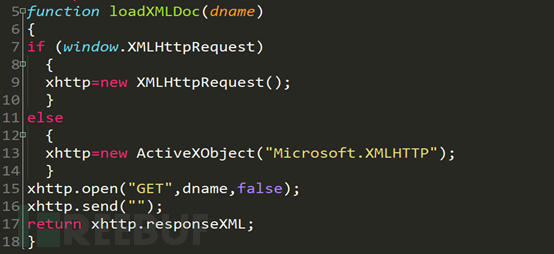
這是js的一個異步調用函數,重要的代碼在第15行和第17行,第15行由函數傳入的dname函數是xml的路徑,第17行返回得到的xml文件。
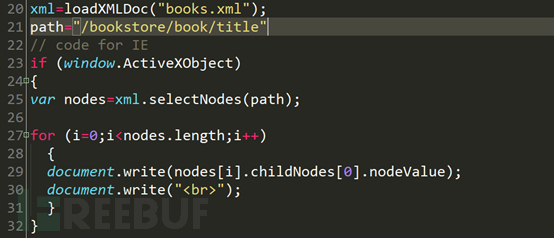
再看第20行,xml變量獲得loadXMLDOC函數執行得到的xml文件。21行path變量為xpath的查詢語法。第一個if語句,判斷是否是IE6及以下瀏覽器,如果是IE6或以下瀏覽器,獲得對應的查詢的到的節點數組之后,將數組中的值遍歷輸出到頁面中。
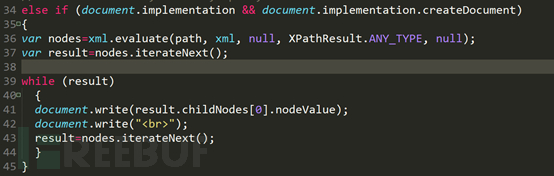
第二個if語句對于非IE6及以下瀏覽器,執行的過程一樣,只是語法稍有不同,非IE6及以下瀏覽器通過evaluate函數進行查詢,格式基本固定,實踐一下剛才的幾個語法。
查詢語法的替換只需要修改path的值就行。

先列出需要查詢的語法:
注:假如路徑起始于正斜杠( / ),則此路徑始終代表到某元素的絕對路徑!
bookstore:選取 bookstore 元素的所有子節點。
/bookstore:選取根元素 bookstore。
bookstore/book:選取屬于 bookstore 的子元素的所有 book 元素。
//book:選取所有 book 子元素,而不管它們在文檔中的位置。
bookstore//book:選擇屬于 bookstore 元素的后代的所有 book 元素,而不管它們位于 bookstore:之下的什么位置。
//@lang:選取名為 lang 的所有屬性。
但是只有這些單個的查詢有的還不能得到想要的查詢結果,需要將它們還有其他的查詢語法組合起來才可以。以下是需要配合的一些語法:
謂語(用方括號,為了得到更精確的查詢結果):
/bookstore/book[1]:選取屬于 bookstore 子元素的第一個 book 元素。
/bookstore/book[last()]:選取屬于 bookstore 子元素的最后一個 book 元素。
/bookstore/book[last()-1]:選取屬于 bookstore 子元素的倒數第二個 book 元素。
/bookstore/book[position()<3]:選取最前面的兩個屬于 bookstore 元素的子元素的 book 元素。
//title[@lang]:選取所有擁有名為 lang 的屬性的 title 元素。
//title[@lang='eng']:選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。
/bookstore/book[price>35.00]:選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大于 35.00。
/bookstore/book[price>35.00]/title:選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大于 35.00。
選取未知節點:
*:匹配任何元素節點。
@*:匹配任何屬性節點。
node():匹配任何類型的節點。
例如:
/bookstore/*:選取 bookstore 元素的所有子元素。
//*:選取文檔中的所有元素。
//title[@*]:選取所有帶有屬性的 title 元素。
選取若干路徑:
//book/title | //book/price:選取 book 元素的所有 title 和price 元素。
//title | //price:選取文檔中的所有 title 和 price 元素。
/bookstore/book/title | //price:選取屬于 bookstore 元素的 book 元素的所有 title 元素,以及文檔中所有的 price 元素
看幾個查詢的例子:
查詢第二個book的title值:/bookstore/book[1]/title

查詢所有book的title的值:/bookstore/book//title

查詢所有帶lang屬性的title的值:/bookstore/book//title[@lang]

感謝你能夠認真閱讀完這篇文章,希望小編分享的“xPath注入的基礎語法有哪些”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





