溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何構建萬級Kubernetes集群場景下的etcd監控平臺,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
隨著 Kubernetes 成為容器編排領域的霸主,越來越多的業務大規模在生產環境使用 Kubernetes 來部署、管理服務。騰訊云TKE正是基于原生 Kubernetes,提供以容器為核心的、高度可擴展的高性能容器管理服務,自從2017年推出后,隨著 Kubernetes 的火熱,我們的集群規模也增長到萬級,在這過程中我們的各基礎組件,尤其是etcd面臨了以下挑戰:
如何通過一套監控系統,采集萬級的TKE集群的etcd等組件 metrics 監控數據?
如何高效治理萬級集群、主動發現故障及潛在隱患?
如何快速感知異常,實現快速處置、乃至自愈?
為了解決以上挑戰,我們基于 Kubernetes 的擴展機制,實現了一套含etcd集群管理、調度、遷移、監控、備份、巡檢于一體的可視化的etcd平臺,本篇文章重點和你分享的是我們etcd監控平臺是如何解決以上挑戰的。
面對大規模監控數據采集問題,我們的解決方案從TKE誕生之初的單 Prometheu 實例、到基于 Promethes-Operator動態構建多 Prometheus 實例、添加監控 Target, 再到基于 TKE云原生 Prometheus 產品實現水平可擴展的監控系統,成功為萬級 Kubernetes 集群提供穩定的 etcd 存儲服務和監控能力,etcd 監控平臺治理的 Kubernetes 集群數也實現了從個位數、到千級、萬級的突破。目前數據規模上,單位時間內 Prometheus Target 高達數萬個,單地域指標數據量 Series 千萬級,面對大規模監控數據,監控數據可用性仍能保持在99.99%以上。
面對復雜分布式環境中,各種可能出現的不可控人為操作失誤、硬件、軟件故障,我們基于 Kubernetes 擴展機制、豐富 的etcd 知識與經驗積累構建了多維度、可擴展的的巡檢系統,幫助我們高效治理萬級集群、主動發現潛在隱患。
面對監控數據龐大,告警泛濫,我們基于高可用的監控數據,結合運營場景,建立標準化的數據運營體系,大幅減少無效告警,提高告警準確性,并進一步引入多維度的SLO,收斂告警指標,為業務方提供直觀的服務水平指標。通過標準化的數據運營體系、告警分類、告警跟進、上升機制、簡單場景的自愈策略等,實現故障快速處置、乃至自愈。
下面,我們就和你詳細介紹下,我們是如何解決以上三個挑戰,快速構建可擴展的業務監控系統。
首先是第一個問題,如何通過一套監控系統,采集萬級的TKE集群的etcd組件 metrics 監控數據?
大家都知道,etcd是一個開源的分布式 key-value 存儲系統,它是 Kubernetes 的元數據存儲,etcd的不穩定會直接導致上層服務不可用,因此etcd的監控至關重要。
2017年,TKE誕生之初,集群少,因此一個單 Prometheu 實例就可以搞定監控問題了。
2018年,Kubernetes 越來越被大家認可,我們的 TKE 集群數也越來越多,因此我們引入了 Promtheus-Operator 來實現動態管理 Prometheus 實例、通過多 Prometheus 實例,我們基本扛住了數千的 Kubernetes 集群監控需求,下面是其架構圖。
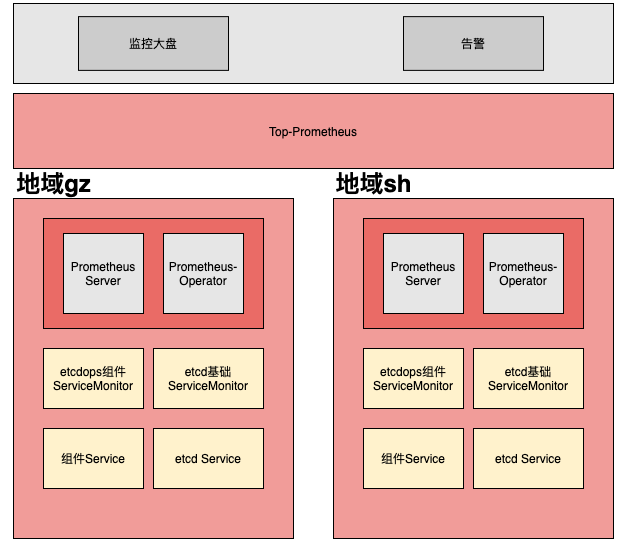
我們在每個地區部署了 Prometheus-Operator, 針對不同業務類型創建了不同的 Prometheus 實例,每新增一個 Kubernetes/etcd 集群的時候,我們會通過 API 創建 ServiceMonitor 資源,告知 Prometheus 采集新集群監控數據。
然而在這套方案中,隨著 Kubernetes/etcd 集群越來越多,etcd監控告警的穩定性受到挑戰,監控鏈路不穩定,監控曲線出現斷點,告警泛濫,虛告警多,難以跟進。
具體有哪些問題呢?
這里我們從監控不穩定和運維成本兩個角度和你分析下。
監控組件不穩定:過大的監控數據經常會造成 Prometheus 實例出現OOM,同時由于納管etcd過程中會對 Prometheus 實例進行變更,頻繁的變更會觸發 Prometheus 的卡死。
監控與業務耦合:為避免數據量過大造成OOM,需要人工拆分Prometheus實現數據分片,這樣不僅增加維護成本,同時由于存在自動納管的機制,納管機制與人工分片強耦合,不利于后期運營和功能拓展。
監控鏈路不穩定:監控鏈路主要由 Prometheus-Operator 和 Top-Prometheus 構成,由于與其他業務共享 Top-Prometheus,Top-Prometheus 面臨大量數據,時常會出現OOM重啟,同時由于本地盤存儲數據量大,啟動加載慢,重啟耗時長,進一步擴大了影響,經常會造成較長時間的數據斷點。
監控組件需要自維護:監控數據分片需要人工拆分監控實例,監控組件需要自運維保活,確保監控可用性。
告警規則維護難度大:告警規則大量依賴對 etcd 名稱的正則匹配,規則維護難度大,對于新增告警規則的場景,需要了解現有的規則配置情況,在添加新規則前需對現有規則增加特定 etcd 集群的反選邏輯,新增操作時常會出現影響現有告警的情況。
告警難跟進:指標繁多,告警量大,無法準確反映業務問題,告警指標不具備業務特性,業務難以直接理解,無法將告警信息直接返回業務方,告警跟進難度大。
另外基于開源的 Prometheus,在添加監控 Target 時,會導致 Prometheus 異常,服務重啟,出現數據斷點,同時由于監控數據量大導致經常OOM,監控服務可用性較低。
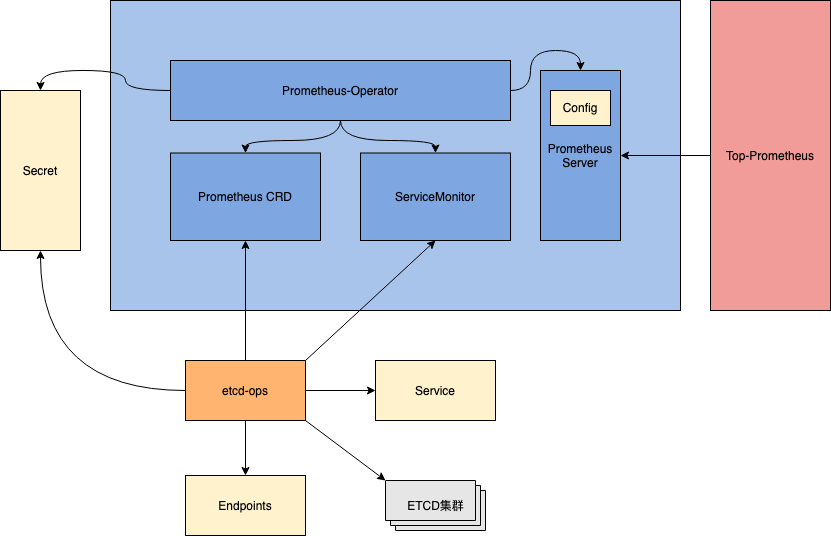
如上圖所示,監控服務主要由下層 Prometheus Server 和上層 Top-Prometheus 組成。
變更為什么會卡死?
如上圖所示,Secret 資源由etcd 集群產生,Prometheus-Operator 會根據 Secret,Prometheus CRD和ServiceMonitor生成 Prometheus 實例的 static_config 文件,Prometheus 實例最終依賴 config 文件實現數據的拉取。
etcd增加 => Secret增多,Prometheus CRD更新 => static_config更新頻繁 => Prometheus 的拉取配置頻繁變動導致 Prometheus 無法正常工作。
容量問題從何而來?
在TKE集群不斷增長和產品化 etcd 上線的背景下,etcd 數目不斷增加,etcd 自身指標量大,同時為了高效治理集群,提前發現各種隱患,引入巡檢策略,指標數據量高達數百萬。
Top-Prometheus 除采集 etcd 指標外,還需要采集其他支撐服務,因此,Top-Prometheus 經常出現 OOM 導致監控服務不可用。
如何解決以上痛點呢?
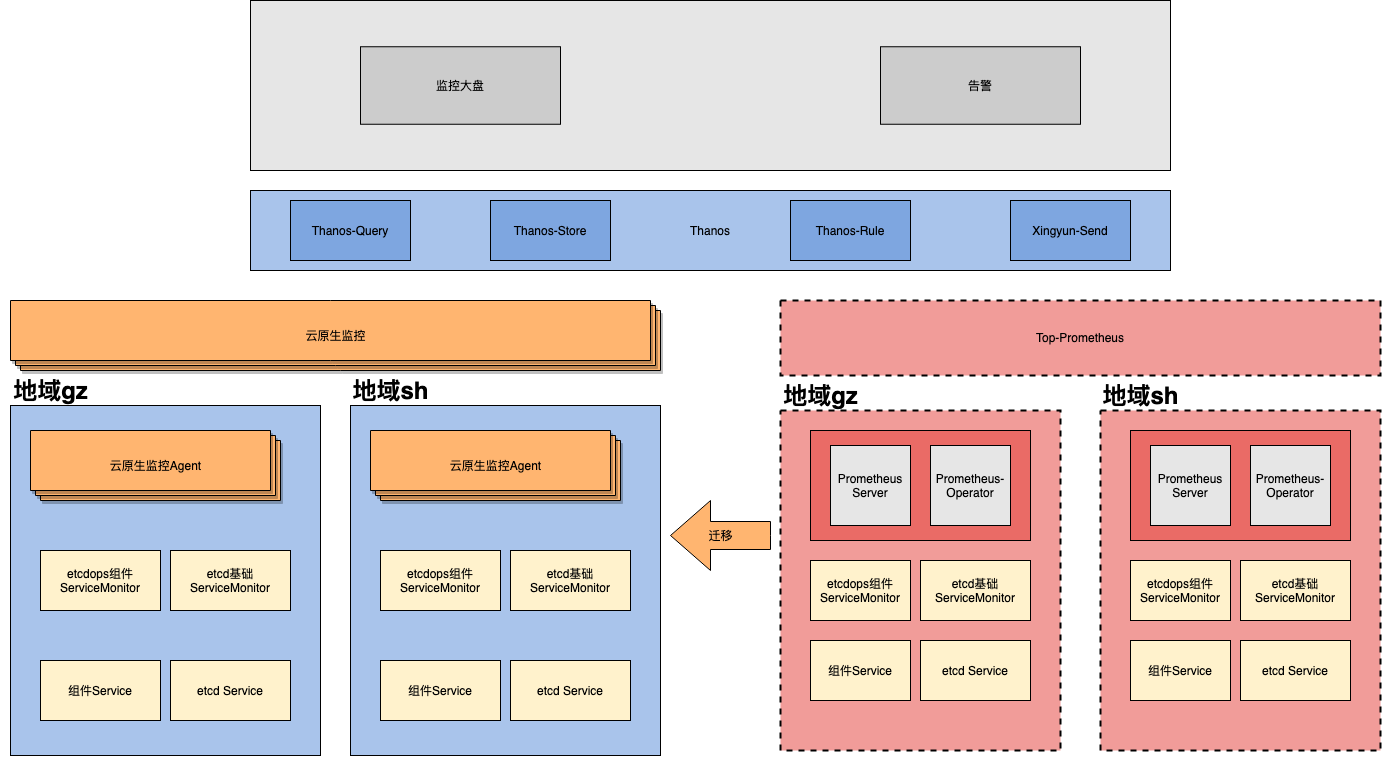
TKE團隊推出的云原生 Prometheus 正是為了解決大規模數據場景下的痛點而誕生的,為了解決以上痛點,保證數據標準化運營底座的穩定性,提供高可用的監控服務,我們決定將 etcd 監控平臺全面遷移到TKE云原生 Prometheus 進行監控系統中。
TKE云原生Prometheus監控引入 file-sync 服務實現配置文件的的熱更新,避免變更導致 Prometheus 重啟,成功解決了我們核心場景過程中的痛點。
同時TKE云原生Prometheus通過Kvass實現對監控數據彈性分片,有效分流大量數據,實現千萬級數據的穩定采集。
最重要的是,Kvass 項目已開源,下面是其架構圖,更多可參考文《如何用Prometheus監控十萬container的Kubernetes集群》和GitHub源碼。
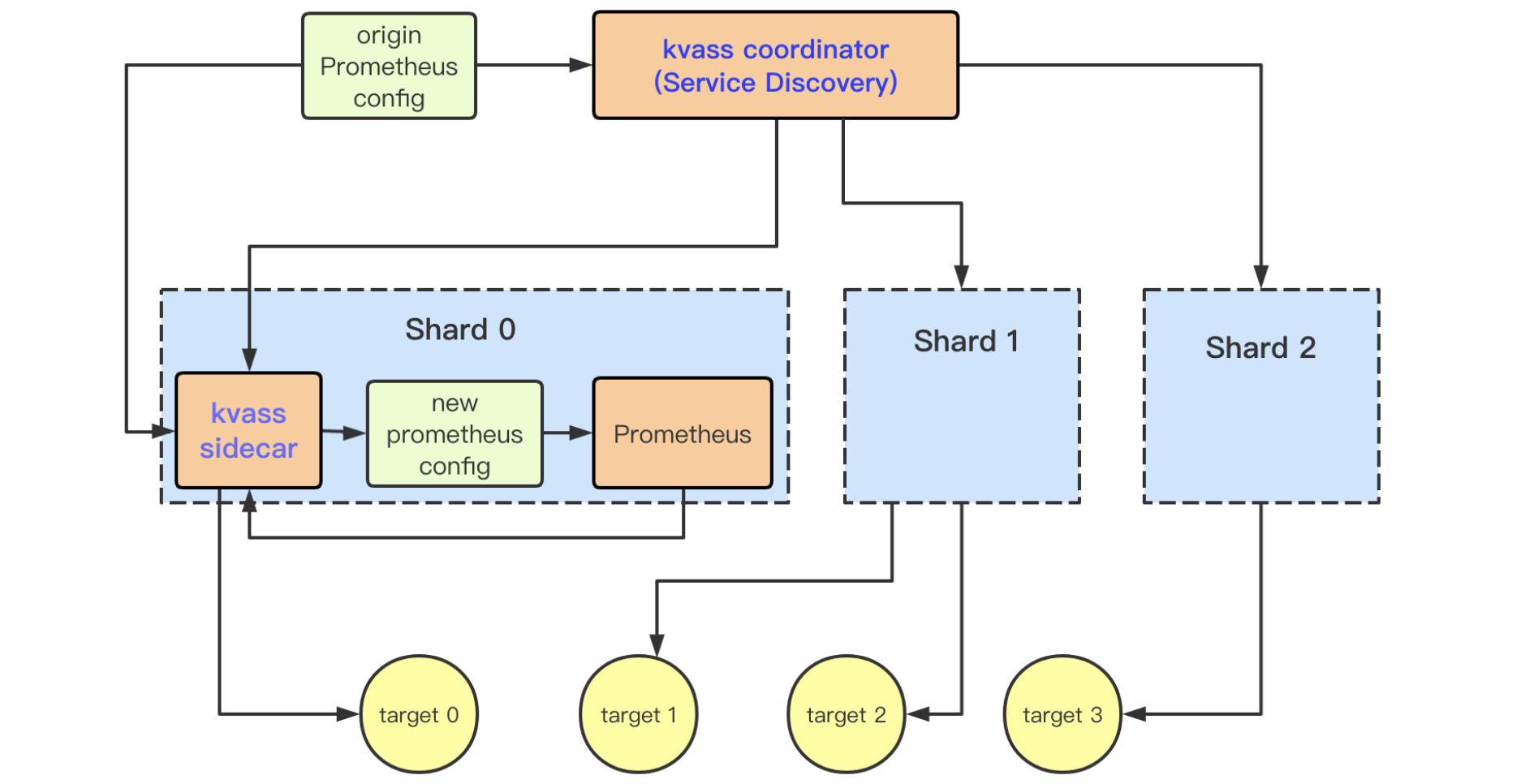
上圖是我們基于可擴展的TKE云原生 Prometheus 架構圖,下面我簡單為你介紹下各個組件。
Thanos主要由兩個服務構成:thanos-query 和 thanos-rule。thanos-query 實現對監控數據的查詢,thanos-rule 對監控數據進行聚合實現告警。
thanos-query:thanos-query 通過配置 store 字段可實現多個 Prometheus 數據查詢任務,利用查詢能力實現 TKE 云原生 Prometheus 或原有 Prometheus 的數據聚合,同時也為上層監控大盤和告警提供統一的數據源,起到收斂數據查詢入口的作用。
thanos-rule:thanos-rule 依賴 query 采集的數據,對數據進行聚合,并根據配置的告警規則實現告警,告警能力的收斂和中心化的告警配置使得下層 Prometheus 服務無論如何變動,告警鏈路的穩定性都得以保證。
TKE云原生 Prometheus 完全兼容開源的 Prometheus-Operator 方案,因此在遷移過程,原有 Prometheus-Operator 相關配置可以全部保留,僅需要添加對應標簽便于TKE云原生 Prometheus 識別即可。但是由于指標暴露由集群內遷移至外部TKE云原生 Prometheus,對集群內外依賴監控指標的服務有所影響。
對外暴露:通過引入中心化 thanos-query,各個地域指標均通過 thanos-query 對外暴露,憑借上層中心化的 query,底層遷移TKE云原生 Prometheus 或者對其進行平行拓展,對于依賴監控指標的外部服務如監控大盤和告警等均無感知。
內部依賴:集群內 custom-metrics 服務依賴監控指標,由于采用 TKE 云原生 Prometheus,指標無法再依賴內部Service 采集,為此,在云原生 Prometheus 所在集群創建對應的內網LB,使得可被支撐環境內部訪問,通過內網 LB 對 custom-metrics 進行配置,從而實現監控指標的采集。
監控可用性:TKE 云原生 Prometheus 基于 Prometheus 對外暴露指標以衡量自身監控服務的可用性,常用指標有 prometheus_tsdb_head_series 和 up 等,prometheus_tsdb_head_series 用于衡量采集總體監控數據量,up 指標反應采集任務是否健康,通過這兩個指標能夠對監控服務可用性有整體的感知。
數據采集成功率:作為業務側,我們更關心具體業務指標采集的成功率,為有效衡量可用性,對業務指標進行采樣落地數據化。以15s為間隔分別采集遷移前后的數據,結合理論數據量判斷數據掉點率,以此反映監控服務可用性。經過統計,具體近30天數據如下圖所示:
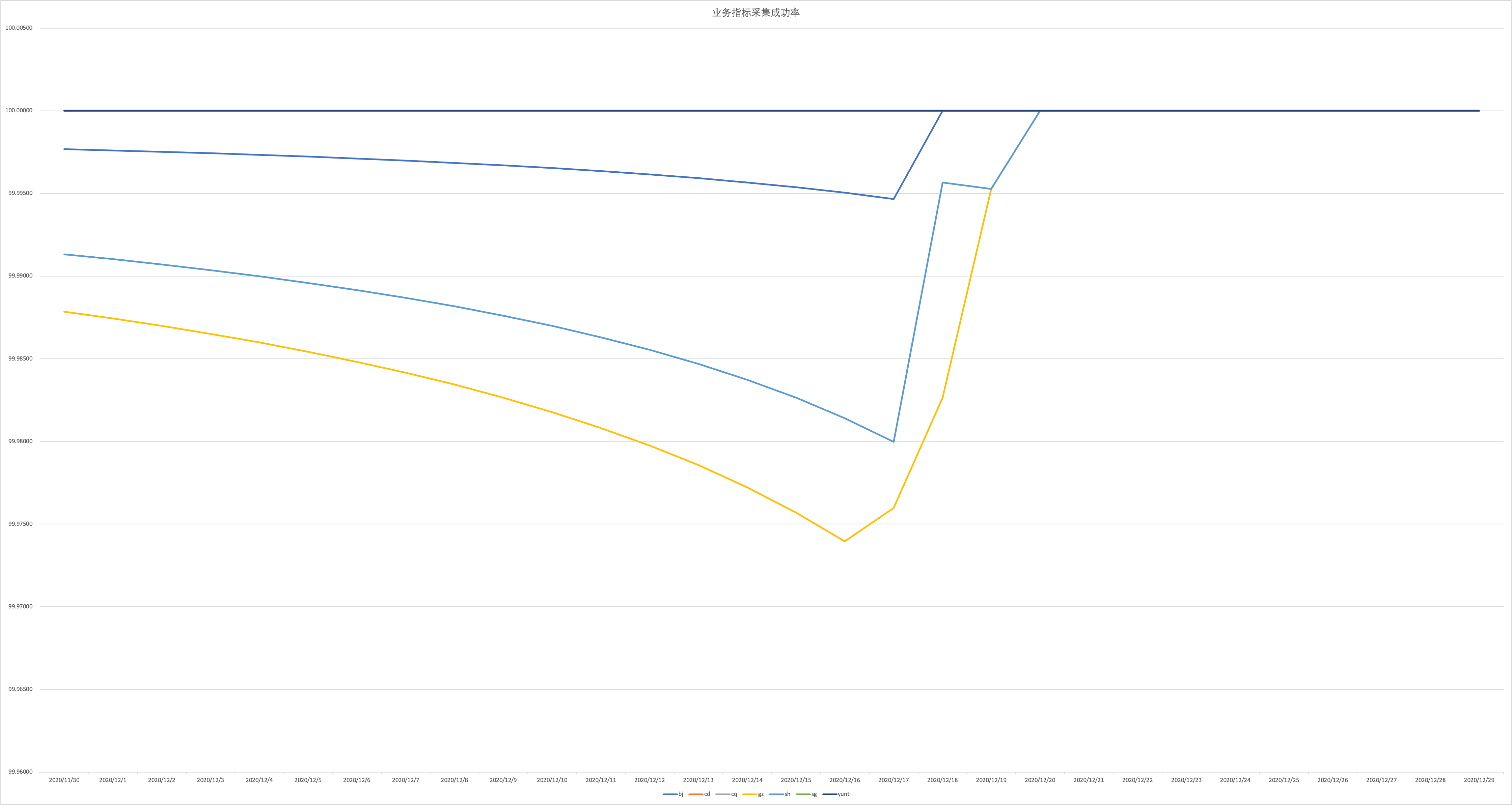
引入 TKE 云原生 Prometheus 后,監控數據總量一直高達數千萬,監控告警鏈路穩定,巡檢數據覆蓋率在70%以上,由于對 etcd 服務平臺進行過改造造成成功率在短時間內所波動,除此外,監控指標拉取成功率均在99.99%以上,近7天數據保持在100%,監控服務保持著高可用性。
其次是第二個問題,如何高效治理萬級集群、主動發現故障及潛在隱患?
在第一個問題中,我們已經解決了大規模 etcd 集群的 metrics 采集問題,通過 metrics 我們可以發現部分隱患,但是它還不夠滿足我們高效治理 etcd 集群的訴求。
為什么這樣說呢?
在大規模使用 etcd 過程中,我們可能會遇到各種各樣的隱患和問題,比如常見如下:
etcd集群因重啟進程、節點等出現數據不一致
業務寫入大 key-value 導致 etcd 性能驟降
業務異常寫入大量key數,穩定性存在隱患
業務少數 key 出現寫入 QPS 異常,導致 etcd 集群出現限速等錯誤
重啟、升級 etcd 后,需要人工從多維度檢查集群健康度
變更 etcd 集群過程中,操作失誤可能會導致 etcd 集群出現分裂
......
因此為了實現高效治理etcd集群,我們將這些潛在隱患總結成一個個自動化檢查項,比如:
如何高效監控 etcd 數據不一致性?
如何及時發現大 key-value?
如何及時通過監控發現 key 數異常增長?
如何及時監控異常寫入 QPS?
如何從多維度的對集群進行自動化的健康檢測,更安心變更?
......
如何將這些 etcd 的最佳實踐策略反哺到現網大規模 etcd 集群的治理中去呢?
答案就是巡檢。
我們基于 Kubernetes 擴展機制、豐富的 etcd 知識與經驗積累構建了多維度、可擴展的的巡檢系統,幫助我們高效治理萬級集群、主動發現潛在隱患。
為什么我們基于 Kubernetes 擴展機制構建 etcd 平臺呢?
為了解決我們業務中一系列痛點,我們 etcd 云原生平臺設計目標如下:
可觀測性。集群創建、遷移流程支持可視化,隨時可查看當前進展,支持暫停、回滾、灰度、批量等。
高開發效率。充分復用社區已有基礎設施組件和平臺,聚焦業務,快速迭代,高效開發。
高可用。 各組件無單點,可平行擴容,遷移模塊通過分布式鎖搶占任務,可并發遷移。
可擴展性。遷移對象、遷移算法、集群管理、調度策略、巡檢策略等抽像化、插件化,以支持多種 Kubernetes 集群類型、多種遷移算法、多種集群類型(CVM/容器等)、多種遷移策略、多種 Kubernetes 版本、多種巡檢策略。
回顧我們設計目標,可觀測性、高開發效率跟 Kubernetes 和其聲明式編程特別匹配,詳情如下。
可觀測性。基于 Event 做遷移實時進展功能,通過 kubectl、可視化的容器控制臺都可以查看、啟動、暫停各類任務
高開發效率。Kubernetes中REST API設計優雅,定義自定義 API 后,SDK 全自動生成,大大減少了開發工作量,可專注業務領域系統開發,同時自動化監控、備份模塊可以基于 Kubernetes 社區已有的組件,進行定制擴展性開發,來滿足我們的功能,解決痛點。
Kubernetes 是個高度可擴展和配置的分布式系統,各個模塊都有豐富的擴展模式和點。在選擇基于 Kubernetes 編程模式后,我們需要將 etcd 集群、遷移任務、監控任務、備份任務、遷移策略等抽象成 Kubernetes 自定義資源,實現對應的控制器即可。
下面是etcd云原生平臺的架構圖。
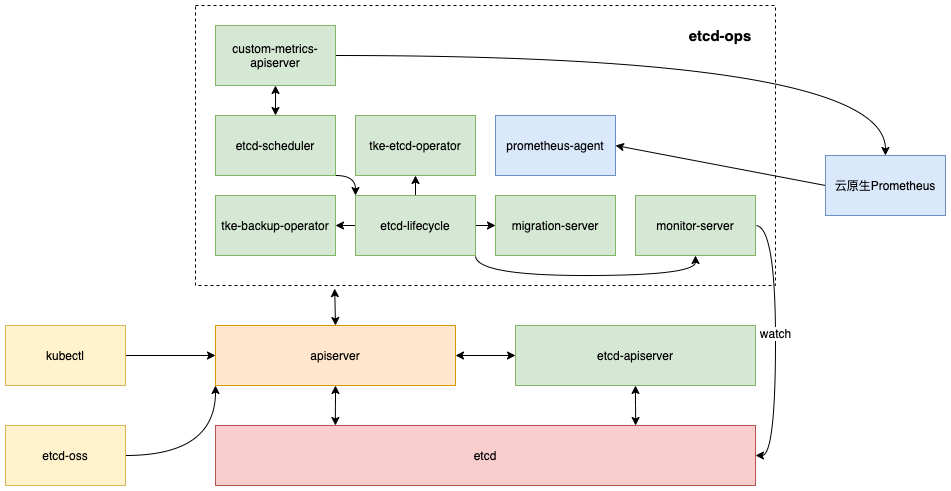
下面以 etcd 集群的創建和分配為例,為你簡單介紹下 etcd 平臺的原理:
通過 kubectl 或者可視化 Web 系統創建 etcd 集群,本質上是提交一個 EtcdCluster 自定義資源
etcd-apiserver 將CRD寫入到獨立的etcd存儲,etcd-lifecycle operator 監聽到新集群后,根據EtcdCluster聲明的后端 Provider, 選擇基于 CVM Provider 還是容器化創建 etcd 集群。
集群創建完成后,etcd-lifecycle operator 還會添加一系列備份策略、監控策略、巡檢策略,它們本質上也是一系列 CRD資源。
當業務需要分配 etcd 集群的時候,調度服務經過篩選流程后,得到一系列滿足業務條件的候選集群,那如何從中返回最佳的etcd集群給用戶呢? 這里,我們支持多種評優策略,比如按最小連接數,它會通過 Kubernetes 的 API 從 Prometheus 中獲取集群的連接數,優先將最小連接數的集群,返回給業務使用,也就是剛剛創建的集群,馬上就會被分配出去。
如何給巡檢系統添加一個巡檢一個規則呢?
一個巡檢規則其實對應的就是一個 CRD 資源,如下面 yaml 文件所示,它就表示給集群 gz-qcloud-etcd-03 添加一個數據差異化的巡檢策略。
apiVersion: etcd.cloud.tencent.com/v1beta1 kind: EtcdMonitor metadata: creationTimestamp: "2020-06-15T12:19:30Z" generation: 1 labels: clusterName: gz-qcloud-etcd-03 region: gz source: etcd-life-cycle-operator name: gz-qcloud-etcd-03-etcd-node-key-diff namespace: gz spec: clusterId: gz-qcloud-etcd-03 metricName: etcd-node-key-diff metricProviderName: cruiser name: gz-qcloud-etcd-03 productName: tke region: gz status: records: - endTime: "2021-02-25T11:22:26Z" message: collectEtcdNodeKeyDiff,etcd cluster gz-qcloud-etcd-03,total key num is 122143,nodeKeyDiff is 0 startTime: "2021-02-25T12:39:28Z" updatedAt: "2021-02-25T12:39:28Z"
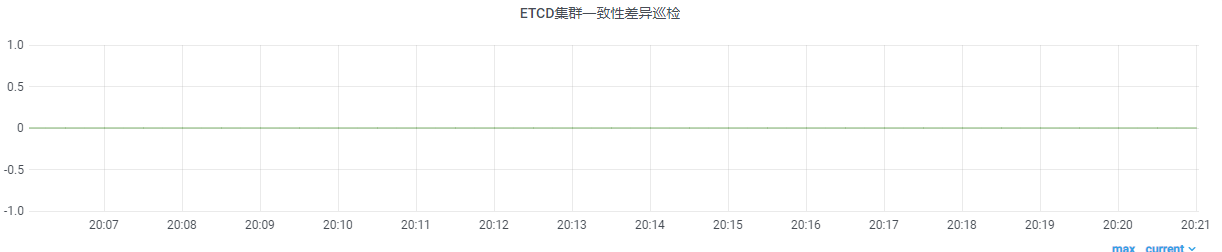
創建此 yaml 文件后,巡檢服務就會執行此巡檢策略,并暴露相關 metrics 對外給 Prometheus 服務采集,最終實現效果如下。
基于穩定的 TKE 云原生 Prometheus 監控鏈路以及較完善的巡檢能力,etcd 平臺已經能夠提供 etcd 集群可用性相關的各類監控指標,但是由于集群數較多,指標眾多,用戶使用場景眾多,部署環境又復雜,難以快速定位異常原因,實現快速處置,即時恢復。
為提高感知異常的能力,實現快速處置及自愈,主要面臨以下幾個問題。
面對各種規格的etcd集群,繁雜的業務應用場景,如何標準化監控以及告警?
etcd 的業務場景與運營場景是有所出入的,基于運營需求,對 etcd 集群的接入進行標準化,提供運營所需標準化監控指標。依據標準化后的業務以及 etcd 規格進一步落地告警標準化,從而實現監控告警的運營標準化。
面對海量指標,如何有效收斂,快速衡量 etcd 集群可用性,感知異常?
etcd 可用性異常,關聯的監控往往不同,沒有單一指標能夠衡量其可用性,為此引入 SLO,有效反應 etcd 服務可用性,并圍繞 SLO 構建多維度的監控體系實現快速的異常感知和問題定位,從而進一步快速恢復。
以下將針對上述問題逐一解決,構建高效的數據運營體系,實現異常的快速感知。
etcd運維信息接入CRD:etcd 的持續運維通過CRD進行配置,完全遵循 Kubernetes 規范,Spec 中定義etcd 基礎信息,服務信息以 Annotation 的形式進行拓展,一個 CRD 囊括了 etcd 運維所有需要的信息。
云原生的數據解決方案:開源 Prometheus 通過配置 Static Config 實現采集任務的配置,TKE 云原生 Prometheus 則充分利用開源 Prometheus-Operator 提供的 ServiceMonitor 資源配置采集任務,僅需配置幾個篩選標簽即可實現組件 Metrics 的自動化接入。etcd 本身作為數據存儲一般運行于運營管理集群之外,為實現對 etcd 自身監控指標的采集,利用 Kubernetes 中的No Selector Service實現,通過直接配置對應 etcd 節點的 Endpoints 采集 etcd 自身 Metrics。
標準化規范:etcd 監控指標通過 ServiceMonitor 的 Relabel 能力引入產品,場景和規格三類標簽實現運營信息的標準化。產品標簽反應 etcd 服務對象所屬產品類別,場景標簽通過對 etcd 的應用場景進行劃分而得 ,規格根據 etcd 節點規格和用戶使用量進行區分,初步分為 small,default,large 三檔。
告警統一標準:通過標準化的實施,告警規則不再依賴大量正則匹配實現,通過場景和規格能夠確定對應告警指標的閾值,結合告警指標表達式即可實現告警規則的配置,對于新增告警規則,通過場景和規格的有效分割,可以在不變動現有告警規則的情況下實現新增。同時帶入內部自研告警系統的場景和規格標簽能夠反應告警的應處理人群,實現告警的定向推送,分級告警,提高告警的準確性。
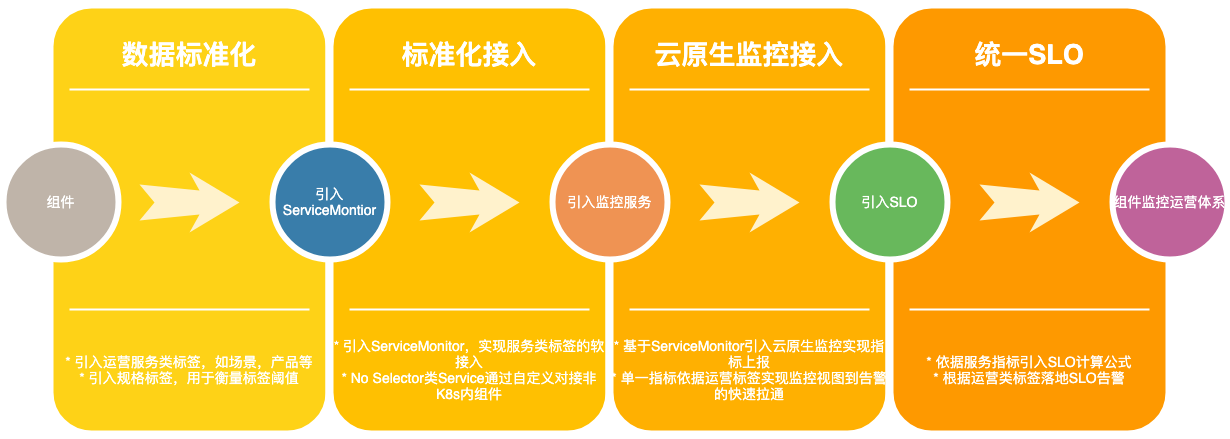
上述標準化流程不僅適用于云原生組件,對于以二進制運行于機器的組件,也可以通過自建 No Selector Service 實現對應指標的采集,組件根據使用場景等運營信息確定好運營類標簽后,通過 ServiceMonitor 的 Relabel 能力能快速聯動TKE云原生 Prometheus 實現監控告警鏈路,建立數據標準化的運營體系。
基于上述標準化流程,落地 etcd 產品化現網運營支持,跟隨著產品化 etcd 上線,利用 ServiceMonitor 的 Relabel 能力,在不變動監控層的情況下實現了接入即運維的特性:
定義接入規范:引入業務和規格的運營類標簽,依據該類標簽將etcd使用場景反應到監控指標當中,為立體監控大盤提供了數據依據,同時圍繞這類標簽實現告警規則的配置和運維。
通用告警規則直接適配:圍繞運營類標簽業務和規格,結合監控指標和閾值,直接生成通用告警規則,實現不同維度的告警。
分析視圖:基于業務場景,結合不同的監控指標,直接套用標準化的監控視圖生成業務維度的 etcd 監控大盤。
如何抽象一個SLO:SLO 即服務水平目標,主要面向內部,用于衡量服務質量。確定 SLO 前,首先要確定 SLI(服務水平指標)。服務是面向用戶的,因此一個重要衡量指標是用戶方對服務的感知,其中,錯誤率和延時感知最為明顯。同時服務本身和服務依賴的第三方服務也會決定服務質量。因此對于 etcd 服務,SLI三要素可確定為請求錯誤率及延時,是否有 Leader 和節點磁盤IO。節點磁盤IO在一定程度上會體現在讀操作的錯誤率和延時,對 SLI 進一步分層為 etcd 可用性和讀寫可用性。結合 Prometheus 實時計算能力,etcd SLO 計算公式可初步確定。
SLO的計算:SLO用于衡量服務質量,服務質量由用戶感知,自身服務狀態以及依賴的底層服務決定,因此SLO由基于etcd核心接口RPC(Range/Txn/Put等)的延時,磁盤IO,是否有Leader以及相關巡檢指標組成。
SLO運營方案:經過對 etcd 服務的分析初步得出 SLO 計算公式并且落地具體SLO指標,但只是初步實現。SLO 需要通過對比實際異常情況,不斷修正,提高SLO的準確率。經過一段時間的觀察和修正,SLO 指標日趨準確,逐步形成如下圖的運營模式,通過 SLO 聯動監控,告警以及現網問題,提高運營效率,完善主動服務能力。經過一段時間的運營,SLO 告警在數次異常情況下通過電話告警及時暴露問題,實現了異常的主動發現。
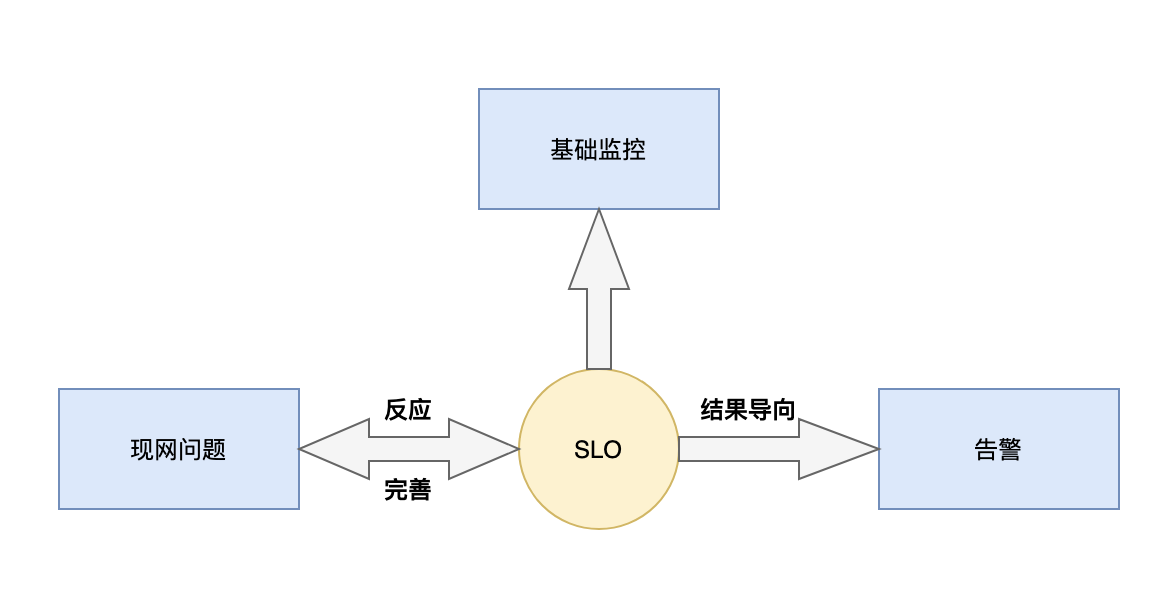
etcd 可用性和延時等構建SLO的關鍵指標已經通過 TKE 云原生 Prometheus 進行采集,依托 Promethues 的計算能力,能夠實現 SLO 的計算,但是由于SLO計算涉及的指標較多,etcd 體量大,SLO 計算延遲大,出現的斷點較多。
Recording Rules 是 Prometheus 的記錄規則,通過該能力能夠提前設置好一個運算表達式,其結果將被保存為一組新的時間序列數據。通過這種方式,能夠將復雜的SLO計算公式分解為不同單元,分散計算壓力,避免數據斷點,并且由于計算結果已被保存,SLO 歷史數據查詢速度極快。同時,Promethues 通過收到的 SIGNUP 信號量更新記錄規則,因此記錄規則的重載是實時的,這種特性有利于在SLO實踐過程不斷修改計算公式,持續優化SLO。
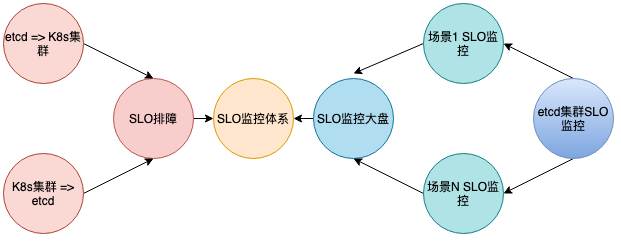
通過SLO的落地,etcd 平臺監控告警依托SLO實現了入口的統一,考慮到 etcd 使用場景繁多,日常排障困難,問題分析不易進行,圍繞SLO監控體系建立SLO快速排障和立體 SLO 監控,整體如下圖所示。
基本面確認:通過監控能夠了解 etcd 的整體概況,如容量信息,組件穩定性,服務可用性等。
不同場景的特性訴求:不同應用場景 etcd 的側重點不同,所關注的監控維度也不相同,監控大盤應能反應不同場景的特性。
運維排障:底層 IAAS 層資源抖動時快速確定受影響etcd集群,故障時快速確定影響面,并且能夠通過告警視圖進一步確認故障原因。
etcd 平臺監控視圖如下圖所示,總體分為一級,二級,三級以及排障視圖。一級為監控大盤,二級劃分為三個場景,三級為單集群監控,是具體問題的關鍵,排障視圖聯動 etcd 與 Kubernetes 實現雙向查詢。
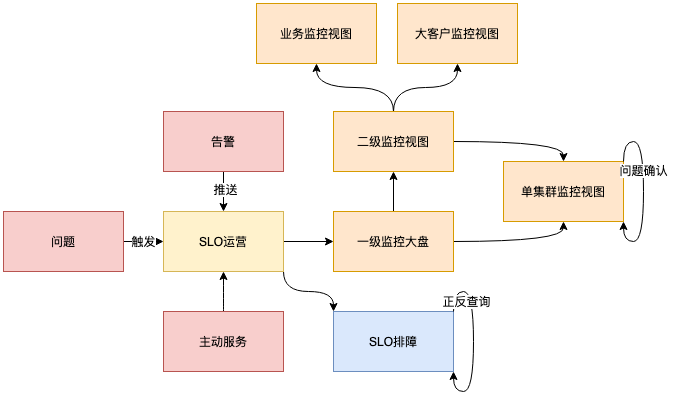
一級監控視圖:SLO 基于多種監控指標計算而成,能有效衡量 etcd 可用性,起到了收斂監控指標的作用,實現統一入口。依據 SLO 建立多地域的監控大盤,能夠整體了解 etcd 情況,快速確認故障影響面。
二級監控視圖:依據 etcd 應用場景,二級監控由業務,大客戶等場景組成,實現不同場景的特性需求,業務反應各個地域的整體可用性,能夠現實各業務各地域是否具備足夠的 etcd 資源,大客戶則在容量上需要反應出其規模,也需要考慮到開放給客戶使用的情況。
三級監控視圖:三級監控為單集群監控視圖,通過該視圖,能夠確認 etcd 具體問題所在,為故障恢復提供依據。
SLO排障監控視圖:etcd 是 Kubernetes 的底層存儲服務,在排障過程中,etcd 與 Kubernetes 往往需要雙向確認,為提高排障效率,SLO排障監控由 etcd 與 Kubernetes 集群正向查詢,反向查詢視圖組成。
運營成效
SLO監控體系基本覆蓋了所有的運營場景,在實際運營過程中多次起到了關鍵作用。
底層IAAS抖動:通過一級監控快速確認影響面,進一步在不同場景下確認受影響 etcd 集群,可快速確定影響面。
問題定位:接收相應SLO告警后,可通過三級監控確定SLO告警原因,確認影響指標,實現故障的快速恢復,同時 etcd 與 Kubernetes 的正反查詢不僅方便了 etcd 問題確認,也是 Kubernetes 問題確認的利器。
主動服務:通過SLO監控大盤多次提前發現etcd異常,并主動反饋給上層服務相關團隊,有效將服務故障扼殺在搖籃當中。
自愈能力:etcd節點故障會影響etcd可用性,通過SLO監控告警,能夠快速感知異常,同時依托容器化部署的優勢,產品化etcd集群的節點均以Pod形式運行,當出現異常節點時,自動會剔除異常POD,添加新的節點,從而在用戶無感知的前提實現故障自愈。
以上就是如何構建萬級Kubernetes集群場景下的etcd監控平臺,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





