溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹基于ClickHouse的用戶行為大數據架構是怎樣的,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
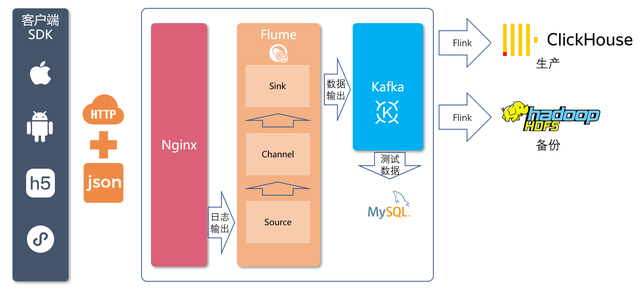
SDK埋點采集行為數據來源終端包括iOS、安卓、Web、H5、微信小程序等。不同終端SDK采用對應平臺和主流語言的SDK,埋點采集到的數據通過JSON數據以HTTP POST方式提交到服務端API。
服務端API由數據接入系統組成,采用Nginx來接收通過 API 發送的數據,并且將之寫到日志文件上。使用Nginx實現高可靠性與高可擴展性。
對于Nginx打印到文件的日志,會由Flume的 Source 模塊來實時讀取Nginx日志,并由Channel模塊進行數據處理,最終通過Sink模塊將處理結果發布到 Kafka中。
Kafka是一個廣泛使用的高可用的分布式消息隊列,作為數據接入與數據處理兩個流程之間的緩沖,同時也作為近期數據的一個備份。
在Flume處理時,根據版本號識別到是測試數據,會寫入kafka的測試分支,此分支會將行為日志的JSON數據寫入MySQL,為開發人員提供埋點開發調試過程中的確認。對線上業務沒有影響。
在Flume識別到生產數據,會寫入kafka的生產分支。后端由Flink將Kafka中數據進行必要的ETL與實時維度join操作,形成規范的明細數據,并寫回Kafka以便下游與其他業務使用。再通過Flink將明細數據分別寫入ClickHouse和Hive打成大寬表,前者作為查詢與分析的核心,后者作為備份和數據質量保證。
關于基于ClickHouse的用戶行為大數據架構是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





