溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“web消息隊列相關知識點有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
來看看維基百科怎么說的,順帶學學英語這波不虧:
In computer science, message queues and mailboxes are software-engineering components typically used for inter-process communication (IPC), or for inter-thread communication within the same process. They use a queue for messaging – the passing of control or of content. Group communication systems provide similar kinds of functionality.
翻譯一下:在計算機科學領域,消息隊列和郵箱都是軟件工程組件,通常用于進程間或同一進程內的線程通信。它們通過隊列來傳遞消息-傳遞控制信息或內容,群組通信系統提供類似的功能。
簡單的概括下上面的定義:消息隊列就是一個使用隊列來通信的組件。
上面的定義沒有錯,但就現在而言我們日常所說的消息隊列常常指代的是消息中間件,它的存在不僅僅只是為了通信這個問題。
從本質上來說是因為互聯網的快速發展,業務不斷擴張,促使技術架構需要不斷的演進。
從以前的單體架構到現在的微服務架構,成百上千的服務之間相互調用和依賴。從互聯網初期一個服務器上有 100 個在線用戶已經很了不得,到現在坐擁10億日活的微信。我們需要有一個「東西」來解耦服務之間的關系、控制資源合理合時的使用以及緩沖流量洪峰等等。
消息隊列就應運而生了。它常用來實現:異步處理、服務解耦、流量控制。
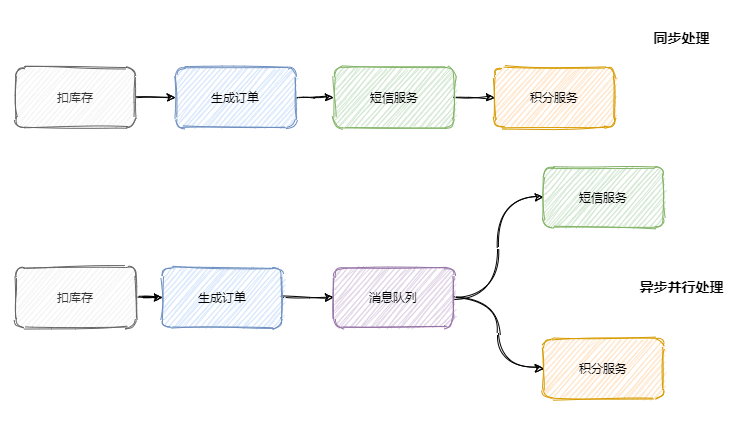
隨著公司的發展你可能會發現你項目的請求鏈路越來越長,例如剛開始的電商項目,可以就是粗暴的扣庫存、下單。慢慢地又加上積分服務、短信服務等。這一路同步調用下來客戶可能等急了,這時候就是消息隊列登場的好時機。
調用鏈路長、響應就慢了,并且相對于扣庫存和下單,積分和短信沒必要這么的 "及時"。因此只需要在下單結束那個流程,扔個消息到消息隊列中就可以直接返回響應了。而且積分服務和短信服務可以并行的消費這條消息。
可以看出消息隊列可以減少請求的等待,還能讓服務異步并發處理,提升系統總體性能。
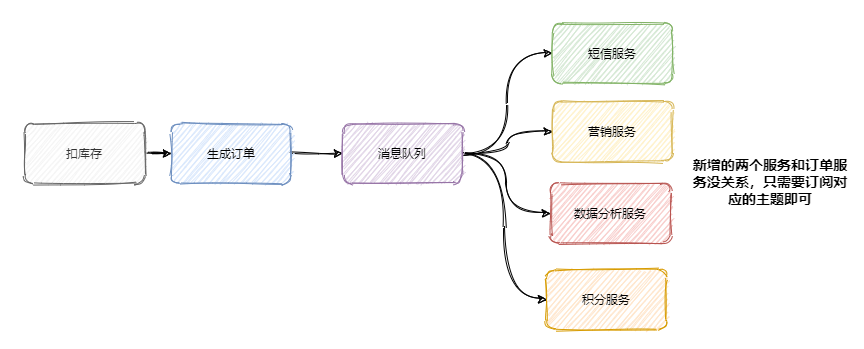
上面我們說到加了積分服務和短信服務,這時候可能又要來個營銷服務,之后領導又說想做個大數據,又來個數據分析服務等等。
可以發現訂單的下游系統在不斷的擴充,為了迎合這些下游系統訂單服務需要經常地修改,任何一個下游系統接口的變更可能都會影響到訂單服務,這訂單服務組可瘋了,真 ·「核心」項目組
所以一般會選用消息隊列來解決系統之間耦合的問題,訂單服務把訂單相關消息塞到消息隊列中,下游系統誰要誰就訂閱這個主題。這樣訂單服務就解放啦!
想必大家都聽過「削峰填谷」,后端服務相對而言都是比較「弱」的,因為業務較重,處理時間較長。像一些例如秒殺活動爆發式流量打過來可能就頂不住了。因此需要引入一個中間件來做緩沖,消息隊列再適合不過了。
網關的請求先放入消息隊列中,后端服務盡自己最大能力去消息隊列中消費請求。超時的請求可以直接返回錯誤。
當然還有一些服務特別是某些后臺任務,不需要及時地響應,并且業務處理復雜且流程長,那么過來的請求先放入消息隊列中,后端服務按照自己的節奏處理。這也是很 nice 的。
上面兩種情況分別對應著生產者生產過快和消費者消費過慢兩種情況,消息隊列都能在其中發揮很好的緩沖效果。

引入消息隊列固然有以上的好處,但是多引入一個中間件系統的穩定性就下降一層,運維的難度抬高一層。因此要權衡利弊,系統是演進的。
消息隊列有兩種模型:隊列模型和發布/訂閱模型。
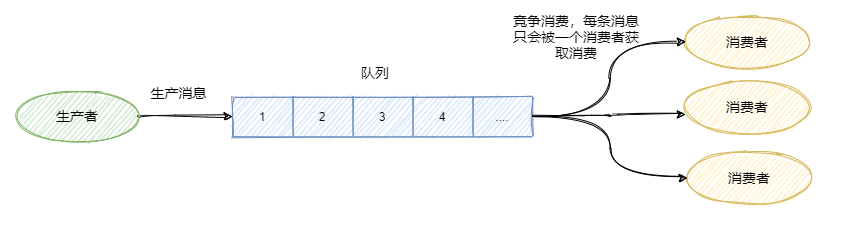
生產者往某個隊列里面發送消息,一個隊列可以存儲多個生產者的消息,一個隊列也可以有多個消費者, 但是消費者之間是競爭關系,即每條消息只能被一個消費者消費。
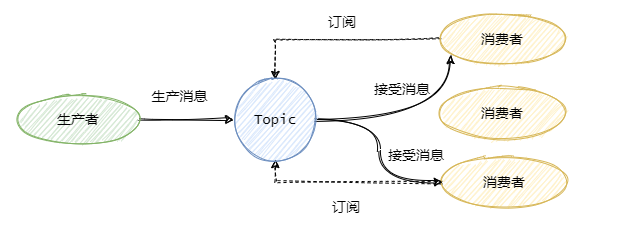
為了解決一條消息能被多個消費者消費的問題,發布/訂閱模型就來了。該模型是將消息發往一個Topic即主題中,所有訂閱了這個 Topic 的訂閱者都能消費這條消息。
其實可以這么理解,發布/訂閱模型等于我們都加入了一個群聊中,我發一條消息,加入了這個群聊的人都能收到這條消息。那么隊列模型就是一對一聊天,我發給你的消息,只能在你的聊天窗口彈出,是不可能彈出到別人的聊天窗口中的。
講到這有人說,那我一對一聊天對每個人都發同樣的消息不就也實現了一條消息被多個人消費了嘛。
是的,通過多隊列全量存儲相同的消息,即數據的冗余可以實現一條消息被多個消費者消費。RabbitMQ 就是采用隊列模型,通過 Exchange 模塊來將消息發送至多個隊列,解決一條消息需要被多個消費者消費問題。
這里還能看到假設群聊里除我之外只有一個人,那么此時的發布/訂閱模型和隊列模型其實就一樣了。
隊列模型每條消息只能被一個消費者消費,而發布/訂閱模型就是為讓一條消息可以被多個消費者消費而生的,當然隊列模型也可以通過消息全量存儲至多個隊列來解決一條消息被多個消費者消費問題,但是會有數據的冗余。
發布/訂閱模型兼容隊列模型,即只有一個消費者的情況下和隊列模型基本一致。
RabbitMQ 采用隊列模型,RocketMQ和Kafka 采用發布/訂閱模型。
接下來的內容都基于發布/訂閱模型。
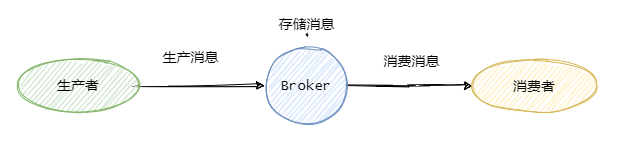
一般我們稱發送消息方為生產者 Producer,接受消費消息方為消費者Consumer,消息隊列服務端為Broker。
消息從Producer發往Broker,Broker將消息存儲至本地,然后Consumer從Broker拉取消息,或者Broker推送消息至Consumer,最后消費。
為了提高并發度,往往發布/訂閱模型還會引入隊列或者分區的概念。即消息是發往一個主題下的某個隊列或者某個分區中。RocketMQ中叫隊列,Kafka叫分區,本質一樣。
例如某個主題下有 5 個隊列,那么這個主題的并發度就提高為 5 ,同時可以有 5 個消費者并行消費該主題的消息。一般可以采用輪詢或者 key hash 取余等策略來將同一個主題的消息分配到不同的隊列中。
與之對應的消費者一般都有組的概念 Consumer Group, 即消費者都是屬于某個消費組的。一條消息會發往多個訂閱了這個主題的消費組。
假設現在有兩個消費組分別是Group 1 和 Group 2,它們都訂閱了Topic-a。此時有一條消息發往Topic-a,那么這兩個消費組都能接收到這條消息。
然后這條消息實際是寫入Topic某個隊列中,消費組中的某個消費者對應消費一個隊列的消息。
在物理上除了副本拷貝之外,一條消息在Broker中只會有一份,每個消費組會有自己的offset即消費點位來標識消費到的位置。在消費點位之前的消息表明已經消費過了。當然這個offset是隊列級別的。每個消費組都會維護訂閱的Topic下的每個隊列的offset。
來個圖看看應該就很清晰了。

基本上熟悉了消息隊列常見的術語和一些概念之后,咱們再來看看消息隊列常見的核心面試點。
就我們市面上常見的消息隊列而言,只要配置得當,我們的消息就不會丟。
先來看看這個圖,
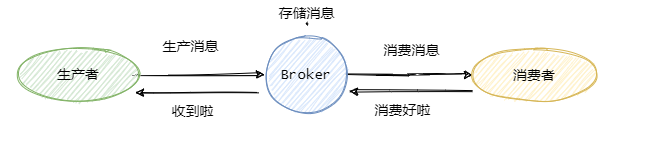
可以看到一共有三個階段,分別是生產消息、存儲消息和消費消息。我們從這三個階段分別入手來看看如何確保消息不會丟失。
生產者發送消息至Broker,需要處理Broker的響應,不論是同步還是異步發送消息,同步和異步回調都需要做好try-catch,妥善的處理響應,如果Broker返回寫入失敗等錯誤消息,需要重試發送。當多次發送失敗需要作報警,日志記錄等。
這樣就能保證在生產消息階段消息不會丟失。
存儲消息階段需要在消息刷盤之后再給生產者響應,假設消息寫入緩存中就返回響應,那么機器突然斷電這消息就沒了,而生產者以為已經發送成功了。
如果Broker是集群部署,有多副本機制,即消息不僅僅要寫入當前Broker,還需要寫入副本機中。那配置成至少寫入兩臺機子后再給生產者響應。這樣基本上就能保證存儲的可靠了。一臺掛了還有一臺還在呢(假如怕兩臺都掛了..那就再多些)。
那假如來個地震機房機子都掛了呢?emmmmmm...大公司基本上都有異地多活。
那要是這幾個地都地震了呢?emmmmmm...這時候還是先關心關心人吧。
這里經常會有同學犯錯,有些同學當消費者拿到消息之后直接存入內存隊列中就直接返回給Broker消費成功,這是不對的。
你需要考慮拿到消息放在內存之后消費者就宕機了怎么辦。所以我們應該在消費者真正執行完業務邏輯之后,再發送給Broker消費成功,這才是真正的消費了。
所以只要我們在消息業務邏輯處理完成之后再給Broker響應,那么消費階段消息就不會丟失。
可以看出,保證消息的可靠性需要三方配合。
生產者需要處理好Broker的響應,出錯情況下利用重試、報警等手段。
Broker需要控制響應的時機,單機情況下是消息刷盤后返回響應,集群多副本情況下,即發送至兩個副本及以上的情況下再返回響應。
消費者需要在執行完真正的業務邏輯之后再返回響應給Broker。
但是要注意消息可靠性增強了,性能就下降了,等待消息刷盤、多副本同步后返回都會影響性能。因此還是看業務,例如日志的傳輸可能丟那么一兩條關系不大,因此沒必要等消息刷盤再響應。
我們先來看看能不能避免消息的重復。
假設我們發送消息,就管發,不管Broker的響應,那么我們發往Broker是不會重復的。
但是一般情況我們是不允許這樣的,這樣消息就完全不可靠了,我們的基本需求是消息至少得發到Broker上,那就得等Broker的響應,那么就可能存在Broker已經寫入了,當時響應由于網絡原因生產者沒有收到,然后生產者又重發了一次,此時消息就重復了。
再看消費者消費的時候,假設我們消費者拿到消息消費了,業務邏輯已經走完了,事務提交了,此時需要更新Consumer offset了,然后這個消費者掛了,另一個消費者頂上,此時Consumer offset還沒更新,于是又拿到剛才那條消息,業務又被執行了一遍。于是消息又重復了。
可以看到正常業務而言消息重復是不可避免的,因此我們只能從另一個角度來解決重復消息的問題。
關鍵點就是冪等。既然我們不能防止重復消息的產生,那么我們只能在業務上處理重復消息所帶來的影響。
冪等是數學上的概念,我們就理解為同樣的參數多次調用同一個接口和調用一次產生的結果是一致的。
例如這條 SQLupdate t1 set money = 150 where id = 1 and money = 100; 執行多少遍money都是150,這就叫冪等。
因此需要改造業務處理邏輯,使得在重復消息的情況下也不會影響最終的結果。
可以通過上面我那條 SQL 一樣,做了個前置條件判斷,即money = 100情況,并且直接修改,更通用的是做個version即版本號控制,對比消息中的版本號和數據庫中的版本號。
或者通過數據庫的約束例如唯一鍵,例如insert into update on duplicate key...。
或者記錄關鍵的key,比如處理訂單這種,記錄訂單ID,假如有重復的消息過來,先判斷下這個ID是否已經被處理過了,如果沒處理再進行下一步。當然也可以用全局唯一ID等等。
基本上就這么幾個套路,真正應用到實際中還是得看具體業務細節。
有序性分:全局有序和部分有序。
如果要保證消息的全局有序,首先只能由一個生產者往Topic發送消息,并且一個Topic內部只能有一個隊列(分區)。消費者也必須是單線程消費這個隊列。這樣的消息就是全局有序的!
不過一般情況下我們都不需要全局有序,即使是同步MySQL Binlog也只需要保證單表消息有序即可。
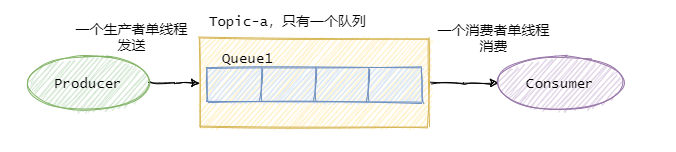
因此絕大部分的有序需求是部分有序,部分有序我們就可以將Topic內部劃分成我們需要的隊列數,把消息通過特定的策略發往固定的隊列中,然后每個隊列對應一個單線程處理的消費者。這樣即完成了部分有序的需求,又可以通過隊列數量的并發來提高消息處理效率。
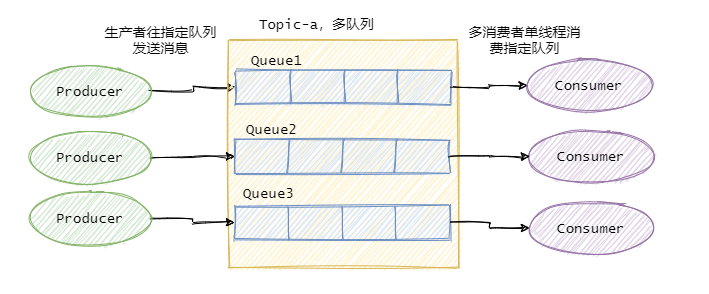
圖中我畫了多個生產者,一個生產者也可以,只要同類消息發往指定的隊列即可。
消息的堆積往往是因為生產者的生產速度與消費者的消費速度不匹配。有可能是因為消息消費失敗反復重試造成的,也有可能就是消費者消費能力弱,漸漸地消息就積壓了。
因此我們需要先定位消費慢的原因,如果是bug則處理 bug ,如果是因為本身消費能力較弱,我們可以優化下消費邏輯,比如之前是一條一條消息消費處理的,這次我們批量處理,比如數據庫的插入,一條一條插和批量插效率是不一樣的。
假如邏輯我們已經都優化了,但還是慢,那就得考慮水平擴容了,增加Topic的隊列數和消費者數量,注意隊列數一定要增加,不然新增加的消費者是沒東西消費的。一個Topic中,一個隊列只會分配給一個消費者。
當然你消費者內部是單線程還是多線程消費那看具體場景。不過要注意上面提高的消息丟失的問題,如果你是將接受到的消息寫入內存隊列之后,然后就返回響應給Broker,然后多線程向內存隊列消費消息,假設此時消費者宕機了,內存隊列里面還未消費的消息也就丟了。
“web消息隊列相關知識點有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





