溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下可解釋AI是什么,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
在人類歷史上,技術進步、生產關系邏輯、倫理法規的發展是動態演進的。當一種新的技術在實驗室獲得突破后,其引發的價值產生方式的變化會依次對商品形態、生產關系等帶來沖擊,而同時當新技術帶來的價值提升得到認可后,商業邏輯的組織形態在自發的調整過程中,也會對技術發展的路徑、內容甚至速度提出訴求,并當訴求得到滿足時適配以新型的倫理法規。在這樣的相互作用中,技術系統與社會體系會共振完成演進,是謂技術革命。
近10年來,籍由算力與數據規模的性價比突破臨界點,以深度神經網絡為代表的聯結主義模型架構及統計學習范式(以后簡稱深度學習)在特征表征能力上取得了跨越級別的突破,大大推動了人工智能的發展,在很多場景中達到令人難以置信的效果。比如:人臉識別準確率達到97%以上;谷歌智能語音助手回答正確率,在2019年的測試中達到92.9%。在這些典型場景下,深度學習在智能表現上的性能已經超過了普通人類(甚至專家),從而到了撬動技術更替的臨界點。在過去幾年間,在某些商業邏輯對技術友好或者倫理法規暫時稀缺的領域,如安防、實時調度、流程優化、競技博弈、信息流分發等,人工智能(暨深度學習)取得了技術和商業上快速突破。
食髓知味,技術發展的甜頭自然每個領域都不愿放過。而當對深度學習商業化運用來到某些對技術敏感、與人的生存或安全關系緊密的領域,如自動駕駛、金融、醫療和司法等高風險應用場景時,原有的商業邏輯在進行技術更替的過程中就會遇到阻力,從而導致商業化(及變現)速度的減緩甚至失敗。究其原因,以上場景的商業邏輯及背后倫理法規的中樞之一是穩定的、可追蹤的責任明晰與分發;而深度學習得到的模型是個黑盒,無法從模型的結構或權重中獲取模型行為的任何信息,從而使這些場景下責任追蹤和分發的中樞無法復用,導致人工智能在業務應用中遇到技術和結構上的困難。
舉2個具體的例子:
在金融風控場景,通過深度學習模型識別出來小部分用戶有欺詐嫌疑,但是業務部門不敢直接使用這個結果進行處理,因為難以理解結果是如何得到的,從而無法判斷結果是否準確,擔心處理錯誤;而且缺乏明確的依據,如果處理了,也無法向監管機構交代;
例2,在醫療領域,深度學習模型根據患者的檢測數據,判斷患者有肺結核,但是醫生不知道診斷結果是怎么來的,不敢直接采用,而是根據自己的經驗,仔細查看相關檢測數據,然后給出自己的判斷。從這2個例子可以看出,黑盒模型嚴重影響模型在實際場景的應用和推廣。
要解決模型的這些問題,就需要打開黑盒模型,透明化模型構建過程和推理機理。那么可解釋AI是實現模型透明化的有效技術。
可解釋AI (eXplainable AI(XAI)),不論是學術界還是工業界都沒有一個統一的定義。這里列舉3種典型定義,供大家參考討論:
①可解釋性就是希望尋求對模型工作機理的直接理解,打破人工智能的黑盒子。
②可解釋AI是為AI算法所做出的決策提供人類可讀的以及可理解的解釋。
③可解釋的AI是確保人類可以輕松理解和信任人工智能代理做出的決策的一組方法。
可見,關注點在于對模型的理解,黑盒模型白盒化以及模型的可信任。
MindSpore團隊根據自身的實踐經驗和理解,將可解釋AI定義為:一套面向機器學習(主要是深度神經網絡)的技術合集,包括可視化、數據挖掘、邏輯推理、知識圖譜等,目的是通過此技術合集,使深度神經網絡呈現一定的可理解性,以滿足相關使用者對模型及應用服務產生的信息訴求(如因果或背景信息),從而為使用者對人工智能服務建立認知層面的信任。
按DARPA(美國國防部先進研究項目局)的說法,可解釋AI的目的,就是要解決用戶面對模型黑盒遇到問題,從而實現:
①用戶知道AI系統為什么這樣做,也知道AI系統為什么不這樣做。
②用戶知道AI系統什么時候可以成功,也知道AI系統什么時候失敗。
③用戶知道什么時候可以信任AI系統。
④用戶知道AI系統為什么做錯了。
MindSpore實現的可解釋AI計劃主要解決如下兩類問題:
①解決深度學習機制下技術細節不透明的問題,使得開發者可以通過XAI工具對開發流程中的細節信息進行獲取,并通過獲取到的可理解信息,幫助開發者進行模型故障排除或性能提升;
②提供深度學習技術與服務對象的友好的認知接口(cognitive-friendly interface),通過該接口,基于深度學習的服務提供者可以有合適工具對深度學習服務進行商業化邏輯的操作,基于深度學習的人工智能服務的消費者可以獲得必要的釋疑并建立信任,也可以為AI系統的審核提供能力支持。
從前面的介紹,大家可以感覺到可解釋AI很高大上,那么具體如何實現呢?結合業界的研究成果,我們認為實現可解釋AI主要有3類方法:
第一類是基于數據的可解釋性,通常稱為深度模型解釋,是最容易想到的一種方法,也是很多論文里面經常涉及的一類技術;主要是基于數據分析和可視化技術,實現深度模型可視化,直觀展示得到模型結果的關鍵依據。
第二類是基于模型的可解釋性,這類方法也稱為可解釋模型方法,主要是通過構建可解釋的模型,使得模型本身具有可解釋性,在輸出結果的同時也輸出得到該結果的原因。
第三類是基于結果的可解釋性,此類方法又稱為模型歸納方法,思路是將已有模型作為一個黑盒,根據給定的一批輸入和對應的輸出,結合觀察到模型的行為,推斷出產生相應的結果的原因,這類方法的好處是完全與模型無關,什么模型都可以用。
MindSpore1.1開源版本,在MindInsight部件中集成了的可解釋AI能力:顯著圖可視化(Saliency Map Visualization),也稱為關鍵特征區域可視化。這部分歸屬于第一類基于數據的可解釋性方法,后續我們將陸續開源更多的解釋方法,除了第一類,還將包括第二類基于模型的可解釋方法和第三類基于結果的可解釋方法。
當前顯著圖可視化主要是CV領域的模型解釋,在1.1版本中,我們支持6種顯著圖可視化解釋方法:Gradient、Deconvolution、GuidedBackprop、GradCAM、RISE、Occlusion。
其中:Gradient、Deconvolution,、GuidedBackprop和GradCAM等4種方法屬于基于梯度的解釋方法。這種類型的解釋方法,主要利用模型的梯度計算,來突顯關鍵特征,效率比較高,下面簡要介紹下這4種方法:
Gradient,是最簡單直接的解釋方法,通過計算輸出對輸入的梯度,得到輸入對最終輸出的“貢獻”值;而Deconvolution和GuidedBackprop是對Gradient的延展和優化;
Deconvolution,對原網絡中ReLU進行了修改使其成為梯度的ReLU,從而過濾負向梯度,僅關注對輸出起到正向貢獻的特征;
GuidedBackprop,是在原網絡ReLU基礎上對負梯度過濾,僅關注對輸出起到正向貢獻的且激活了的特征,能夠減少顯著圖噪音;
GradCAM,針對中間激活層計算類別權重,生成對類別敏感的顯著圖,可以得到類別相關的解釋。
另外2種方法:Occlusion和RISE,則屬于基于擾動的解釋方法,該類型方法的好處是,僅需利用模型的輸入和輸出,可以做到模型無關,具體說明下:
RISE,使用蒙特卡洛方法,對隨機掩碼進行加權(權重為遮掩后的模型的輸出)平均得到最終顯著圖;
Occlusion,通過遮掩特定位置的輸入,計算模型輸出的改變量來得到該位置的“貢獻”,遍歷全部輸入,得到顯著圖。
那么對于具體場景,該如何選擇合適的解釋方法來解釋對應的模型呢?
為了滿足這個訴求,MindSpore1.1版本提供了可解釋AI的度量框架,同時還提供了4種度量方法:Faithfulness、Localization、Class sensitivity、Robustness,針對不同解釋方法的解釋效果進行度量,幫助開發者或用戶選擇最合適的解釋方法。簡單描述下這4種度量方法:
Faithfulness,可信度。按照重要度從大到小移除特征,并記錄特定標簽概率的減少量。遍歷所有特征之后,比較置信度減少量的分布和特征重要性的分布相似性。與黑盒模型越契合的解釋,兩個分布情況應當越相似,該解釋方法具有更好的可信度。
Localization,定位性。基于顯著圖的解釋具有目標定位的能力(即給定感興趣的標簽,顯著圖高亮圖片中與標簽相關的部分),localization借助目標檢測數據集,對于同一圖片同一個標簽,通過顯著圖高亮部分和Ground Truth的重合度,來度量顯著圖的定位能力。
Class sensitivity,分類敏感度,不同分類對應的圖中的對象的顯著圖高亮部分應該明顯不同。將概率最大和最小標簽的顯著圖進行比較,如果兩個標簽的顯著圖差異越大,解釋方法的分類敏感度越好。
Robustness,健壯性。該指標反映解釋方法在局部范圍的抗擾動能力,Lipschitz值越小,解釋收擾動影響越小,健壯性越強。
下面結合MindSpore1.1版本中已支持的顯著圖可視方法的其中3種解釋方法:Gradient 、GradCAM和RISE,介紹如何使用可解釋AI能力來更好理解圖片分類模型的預測結果,獲取作為分類預測依據的關鍵特征區域,從而判斷得到分類結果的合理性和正確性,加速模型調優。
Gradient,是最簡單直接的基于梯度的解釋方法,通過計算輸出對輸入的梯度,得到輸入對最終輸出的“貢獻”值,用于解釋預測結果的關鍵特征依據。
對深度神經網絡,這個梯度計算可通過后向傳播算法獲得,如下圖所示:
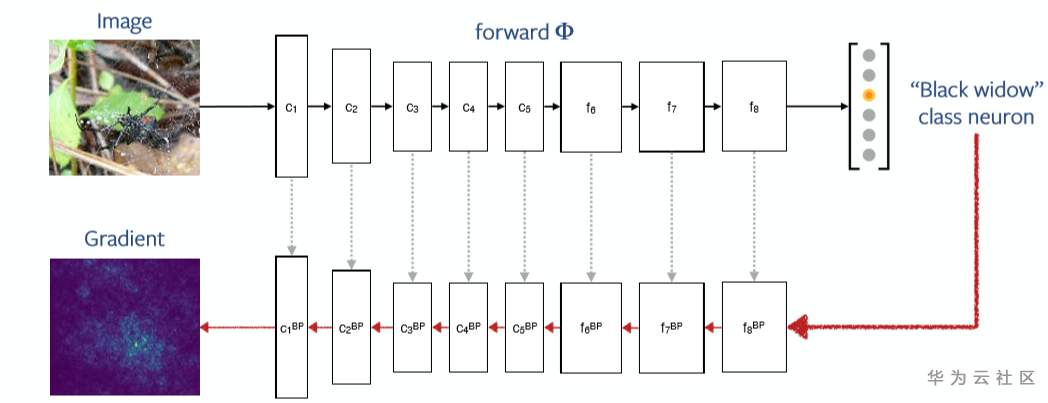
Source:Understanding models via visualizations and attribution
注:Gradient解釋方法會遇到梯度飽和問題,即某個特征的貢獻一旦達到飽和后,由于該特征不再對結果的變化產生影響,會導致該特征的梯度為0而出錯。
Gradient解釋效果如下圖所示:
注:所有解釋效果圖片均來源于MindInsight截圖
從上面2張圖中可以看出,Gradient的解釋結果可理解性較差,顯著圖高亮區域成散點狀,沒有清晰明確的特征區域定位,很難從中獲取到預測結果的具體特征依據。
GradCAM,是Gradient-weighted Class Activation Mapping的簡寫,一般翻譯為:加權梯度的類激活映射,是一種基于梯度的解釋方法;該解釋方法通過對某一層網絡各通道激活圖進行加權(權重由梯度計算得到),得到影響預測分類結果的關鍵特征區域。
GradCAM解釋結果過程的概覽,如下圖:
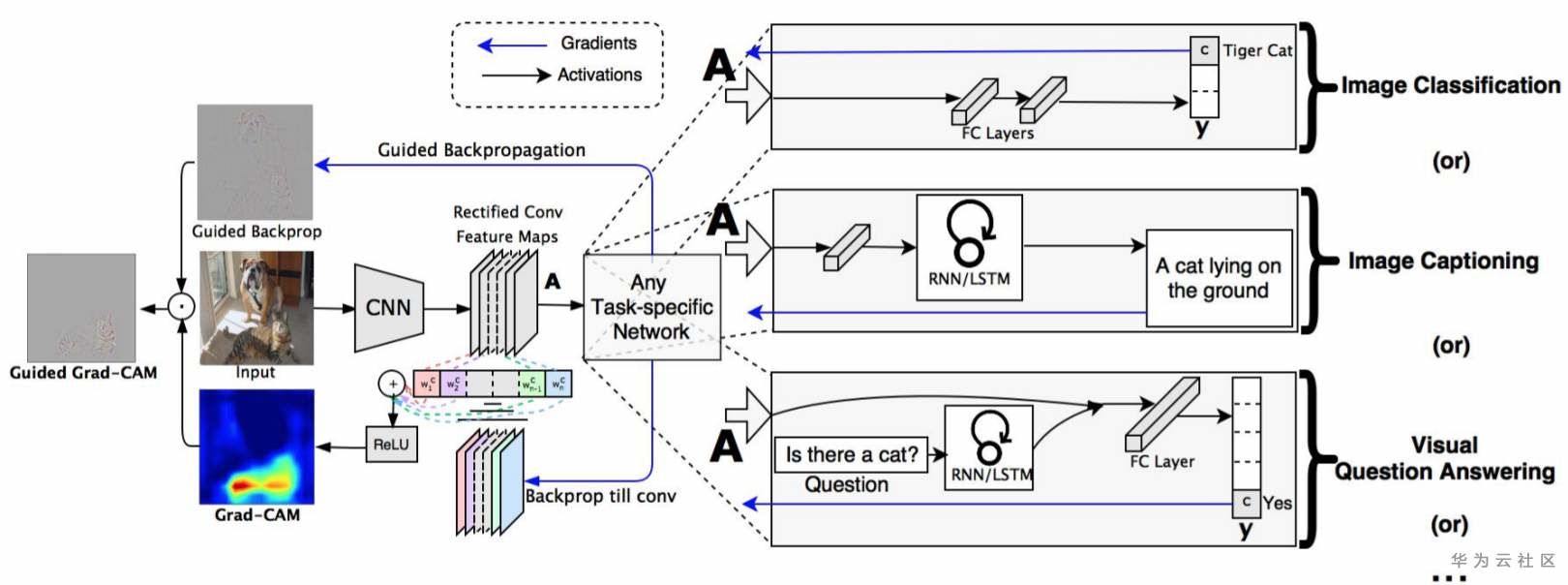
Source:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
這里給出2個實際的例子,來看看GradCAM具體的解釋效果:
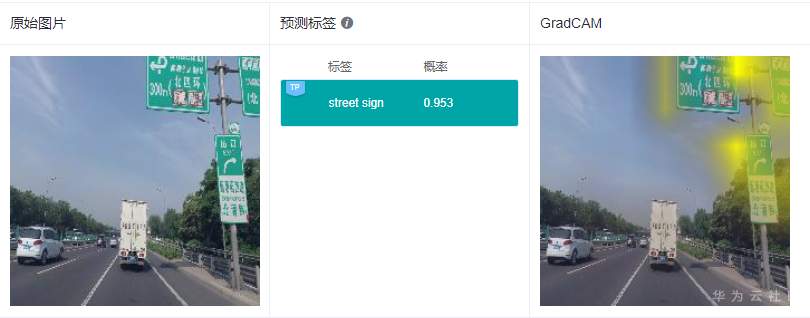
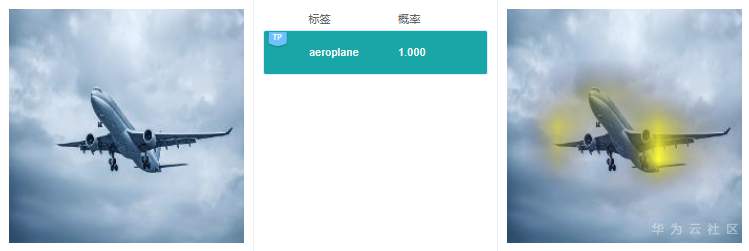
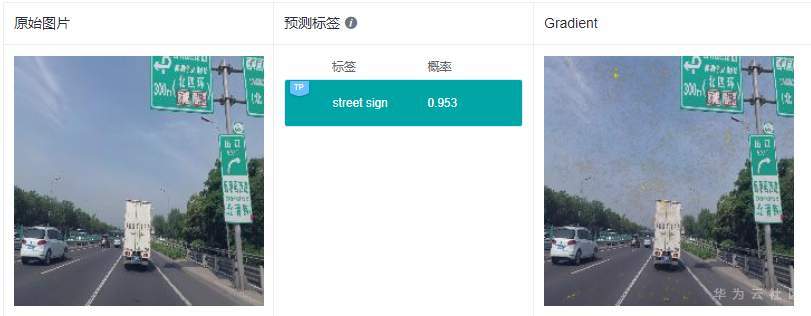
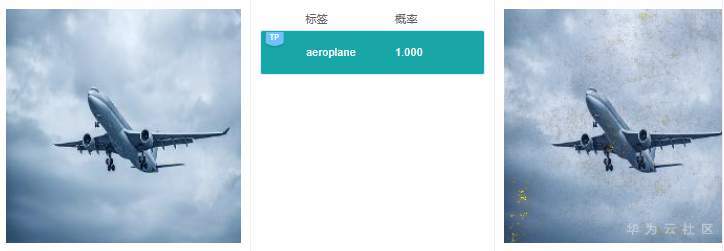
可以看到GradCAM的解釋結果定位性和可理解性比較好,高亮區域集中在具體的特征上,用戶可以通過高亮區域判斷出和預測結果相關的特征。對于標簽“路牌”,圖像中的路牌被高亮,對于標簽“飛機”,圖像中的飛機被高亮,即GradCAM認為路牌區域和飛機區域是2個分類結果的主要依據。
RISE,是Randomized Input Sampling for Explanation的簡寫,即基于隨機輸入采樣的解釋,是一種基于擾動的解釋,與模型無關;主要原理:使用蒙特卡洛采樣產生多個掩碼,然后對隨機掩碼進行加權(權重為遮掩后的模型的輸出)平均得到最終顯著圖。
RISE方法解釋過程的概覽圖,如下:
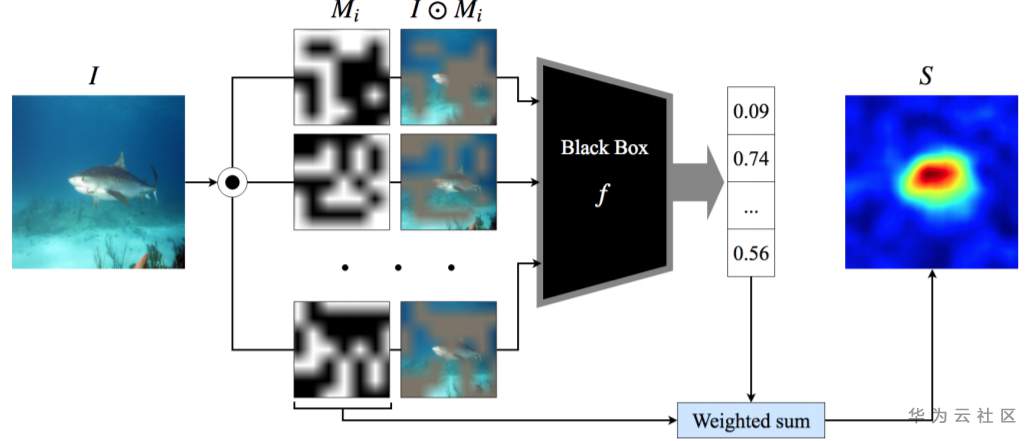
Source:RISE: Randomized Input Sampling for Explanation of Black-box Models
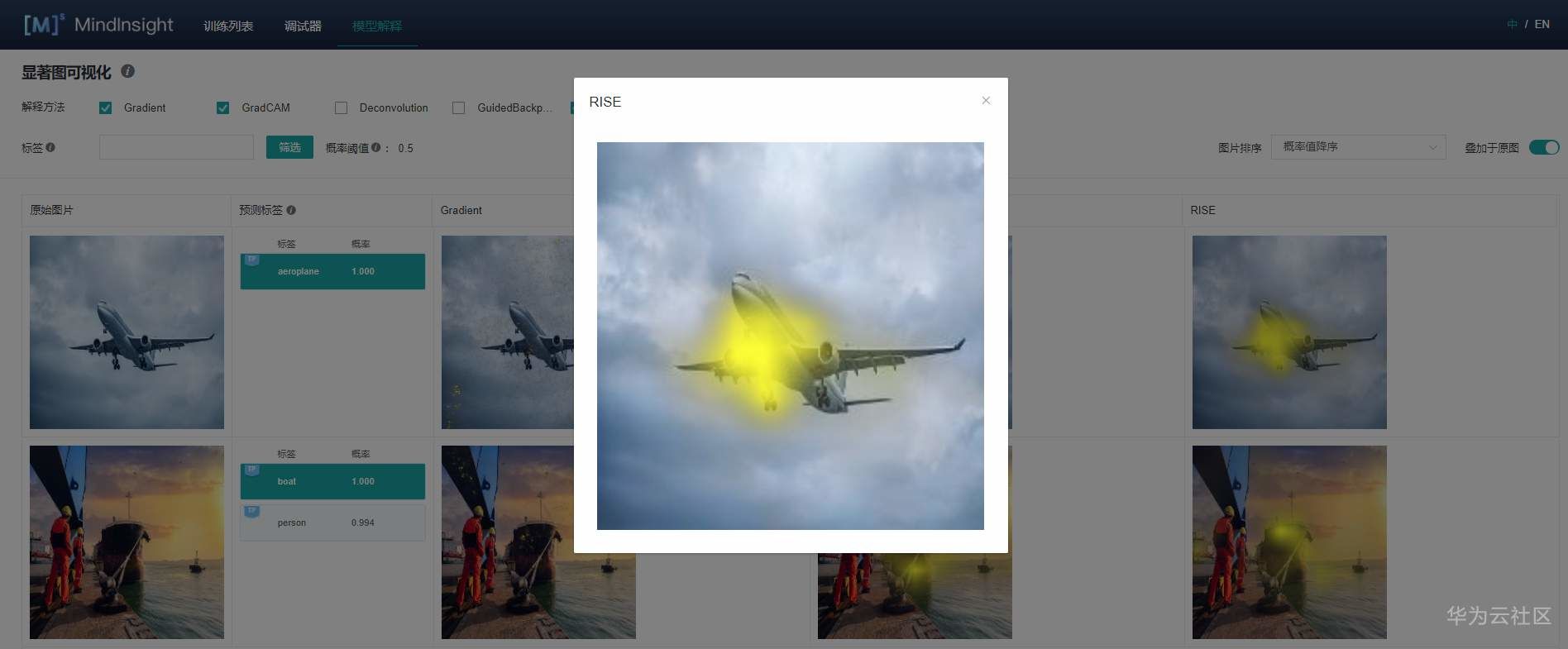
同樣給出2個示例,展示下解釋效果:
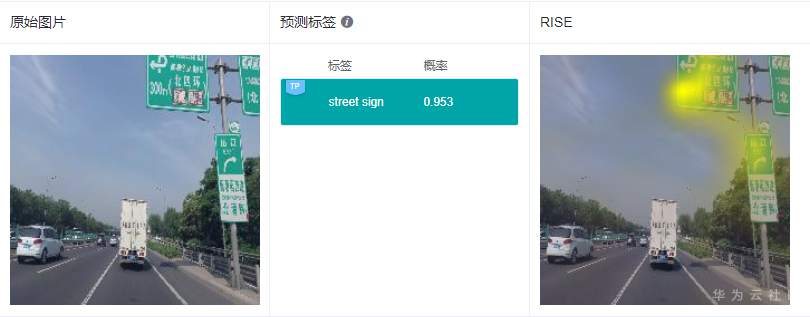
RISE采用遮掩的方法得到與分類結果相關的特征區域,解釋結果的可理解性和定位性不錯,和GradCAM類似,RISE準確地高亮了路牌區域和飛機區域。
在實際應用中,上面介紹的3種解釋方法的解釋效果如何呢?根據預測結果和解釋的有效性,我們將解釋結果分為3類,并分別找幾個典型的例子來看看實際的效果。
說明:下面所有示例圖中的解釋結果,都是MindSpore的MindInsight部件中的模型解釋特性展現出來的。
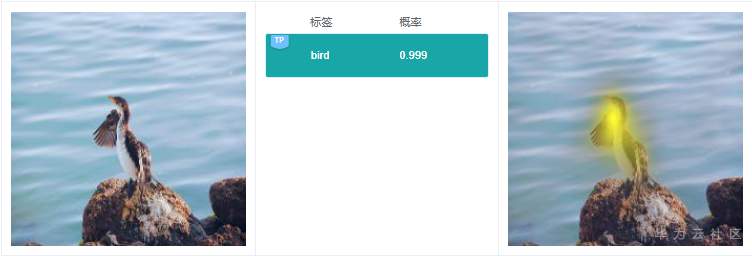
例7.1.1:上圖預測標簽是“bird”,右邊給出依據的關鍵特征在鳥身上,說明這個分類判斷依據是合理的。
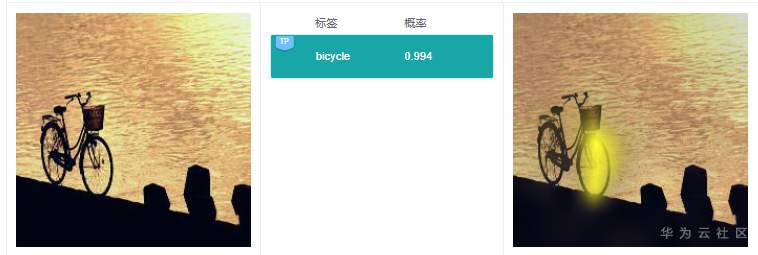
例7.1.2:上圖預測標簽是“bicycle”,右邊解釋的時候,將自行車車輪高亮,這個關鍵特征同樣較為合理。
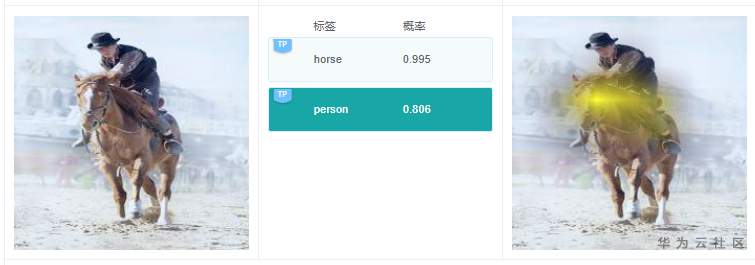
例7.2.1:原圖中,有人,在預測標簽中有1個標簽是“person”,這個結果是對的;但是選擇“person”標簽,在查看右邊解釋的時候,可以看到高亮區域在馬頭上,那么這個關鍵特征依據很可能是錯誤的。
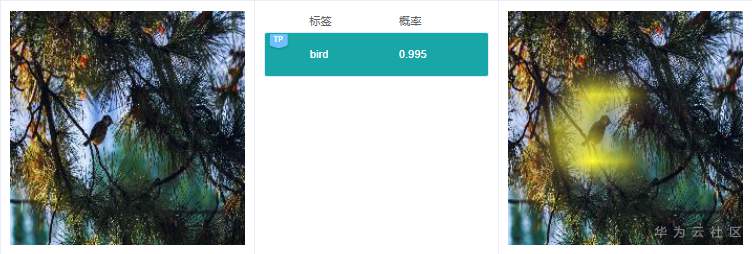
例7.2.2:原圖中,有一只鳥,預測結果“bird”是對的,但是右邊解釋的時候,高亮區域在樹枝和樹葉上,而不是鳥的身上,這個依據也很可能是錯的。
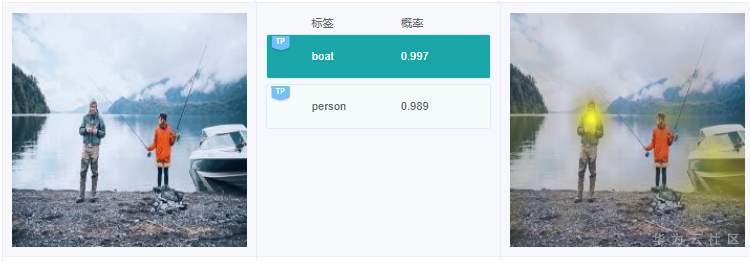
例7.2.3:上圖中,有1艘小艇,有個標簽是“boat”,這個沒錯。不過在右邊針對標簽“boat”的解釋,高亮區域卻在人身上,這個偏差有點大。
仔細分析上面的3個例子,這種高亮標識出來作為分類依據的關鍵特征,出現錯誤的情況,一般出現在圖像中存在多目標的場景中。根據調優經驗,往往是因為在訓練過程中,這些特征經常與目標對象共同出現,導致模型在學習過程中,錯誤將這些特征識別為關鍵特征。
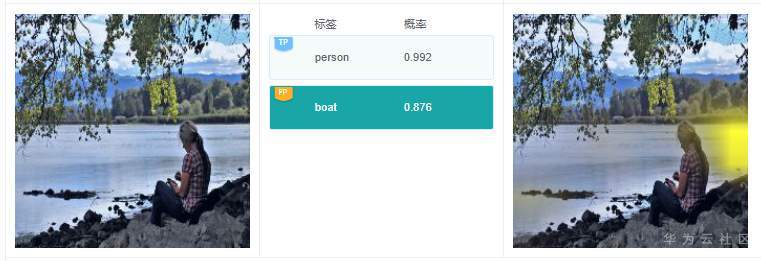
例7.3.1:在上圖中,有個預測標簽為“boat”,但是原始圖像中并沒有船只存在,通過圖中右側關于標簽“boat”的解釋結果可以看到模型將水面作為分類的關鍵依據,得到預測結果“boat”,這個依據是錯誤的。通過對訓練數據集中標簽為“boat”的數據子集進行分析,發現絕大部分標簽為“boat”的圖片中,都有水面,這很可能導致模型訓練的時候,誤將水面作為“boat”類型的關鍵依據。基于此,按比例補充有船沒有水面的圖片集,從而大幅消減模型學習的時候誤判關鍵特征的概率。
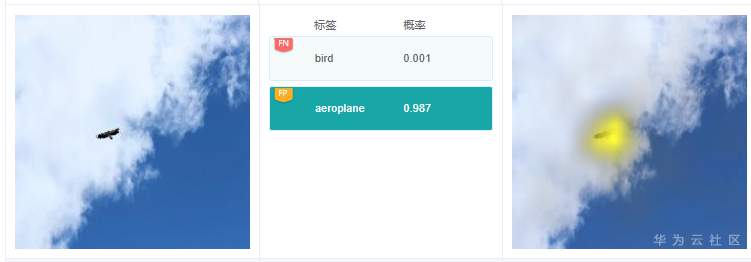
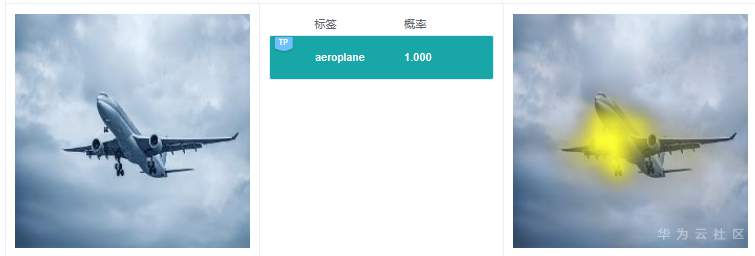
例7.3.2:圖中有一個分類預測結果是“aeroplane”,但圖中并沒有飛機。從標簽“aeroplane”的解釋結果看,高亮區域在鷹的身上。打開飛機相關的訓練數據子集,發現很多情況下訓練圖片中飛機都是遠處目標,與老鷹展翅滑翔很像,猜測可能是這種原因導致模型推理的時候,誤將老鷹當做飛機了。模型優化的時候,可以考慮增加老鷹滑翔的圖片比例,提升模型的區分和辨別能力,提高分類準確率。
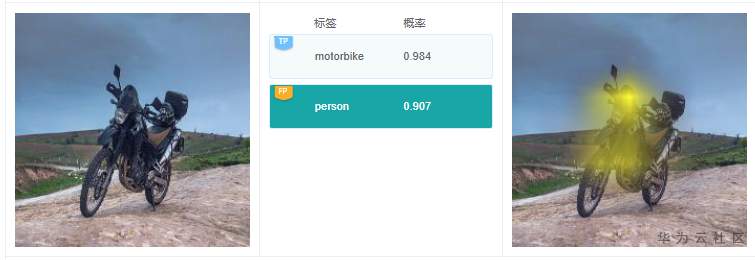
例7.3.3:這個例子中,有個預測標簽是“person”,仔細看圖中沒有人。根據標簽“person”的解釋結果,高亮區域在摩托車的前部;在原圖中,乍一看,還真像一個人趴著;猜測是分類模型推理的時候,誤將這部分當做人了。
在MindSpore官網的模型解釋教程中,詳細介紹了如何部署和使用MindSpore提供的解釋方法,鏈接請見:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/model_explaination.html
下面,對部署和使用方法,做簡要介紹:
先使用腳本調用MindSpore 提供的python API進行解釋結果的生成和收集,然后啟動MindInsight對這些結果進行展示,整體流程如下圖:
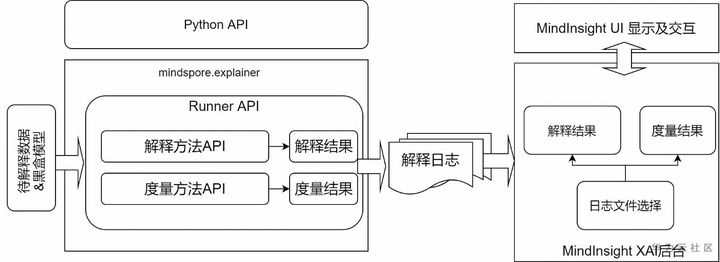
具體步驟如下:
通過調用解釋方法Python API對模型預測結果進行解釋,已提供的解釋方法可以在mindspore.explainer.explanation包中獲取。用戶準備好待解釋的黑盒模型和數據,在腳本中根據需要實例化解釋方法,調用API用于收集解釋結果。
MindSpore還提供mindspore.explainer.ImageClassificationRunner接口,支持自動化運行所有解釋方法。用戶事先將實例化的解釋方法進行注冊,即可在該接口調用后自動運行解釋方法,生成及保存包含解釋結果的解釋日志。
下面以ResNet50為例,介紹如何初始化explanation中解釋方法,調用ImageClassificationRunner進行解釋。其樣例代碼如下:
``` import mindspore.nn as nn from mindspore.explainer.explanation import GradCAM, GuidedBackprop from mindspore.explainer import ImageClassificationRunner from user_defined import load_resnet50, get_dataset, get_class_names # load user defined classification network and data network = load_resnet50() dataset = get_dataset() classes = get_class_names() data = (dataset, classes) runner = ImageClassificationRunner(summary_dir='./summary_dir', network=network, activation_fn=nn.Sigmoid(), data=data) # register explainers explainers = [GradCAM(network, layer='layer4'), GuidedBackprop(network)] runner.register_saliency(explainers) # run and generate summary runner.run() ```
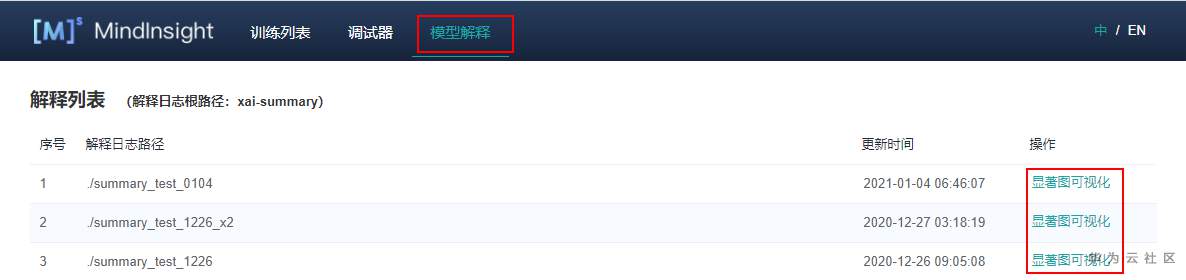
啟動MindInsight系統,在頂部選擇進入“模型解釋”模塊。可以看到所有的解釋日志路徑,當日志滿足條件時,操作列會有“顯著圖可視化”的功能入口。
顯著圖可視化用于展示對模型預測結果影響最為顯著的圖片區域,通常高亮部分可視為圖片被標記為目標分類的關鍵特征。
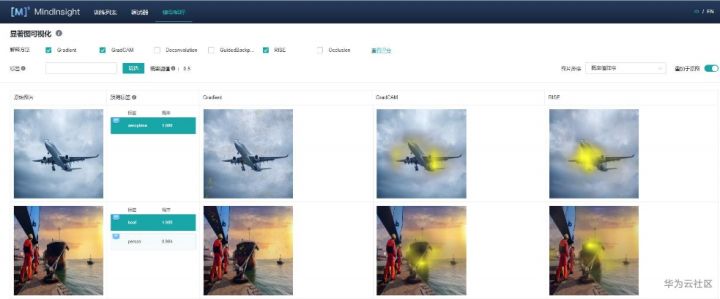
進入顯著圖可視化界面,如上圖,會展現:
用戶通過Dataset的Python API接口設置的目標數據集。
真實標簽、預測標簽,以及模型對對應標簽的預測概率。根據具體情況,系統會在對應標簽的左上角增加TP, FP,FN(含義見界面提示信息)的旗標。
選中的解釋方法給出的顯著圖。
界面操作介紹:
1.通過界面上方的解釋方法勾選需要的解釋方法;
2.通過切換界面右上方的“疊加于原圖”按鈕,可以選擇讓顯著圖疊加于原圖上顯示;
3.點擊不同標簽,顯示對不同標簽的顯著圖分析結果,對于不同的分類結果,通常依據的關鍵特征區域也是不同的;
4.通過界面上方的標簽篩選功能,篩選出指定標簽圖片;
5.通過界面右上角的圖片排序改變圖片顯示的順序;
6.點擊圖片可查看放大圖。
以上是“可解釋AI是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





