溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Flink流計算常用算子是什么”,在日常操作中,相信很多人在Flink流計算常用算子是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Flink流計算常用算子是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Flink和Spark類似,也是一種一站式處理的框架;既可以進行批處理(DataSet),也可以進行實時處理(DataStream)。
所以下面將Flink的算子分為兩大類:一類是DataSet,一類是DataStream。
fromCollection:從本地集合讀取數據
例:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,張三", "2,李四", "3,王五", "4,趙六")
)
readTextFile:從文件中讀取:
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt")readTextFile可以對一個文件目錄內的所有文件,包括所有子目錄中的所有文件的遍歷訪問方式:
val parameters = new Configuration
// recursive.file.enumeration 開啟遞歸
parameters.setBoolean("recursive.file.enumeration", true)
val file = env.readTextFile("/data").withParameters(parameters)
對于以下壓縮類型,不需要指定任何額外的inputformat方法,flink可以自動識別并且解壓。但是,壓縮文件可能不會并行讀取,可能是順序讀取的,這樣可能會影響作業的可伸縮性。
| 壓縮方法 | 文件擴展名 | 是否可并行讀取 |
|---|---|---|
| DEFLATE | .deflate | no |
| GZip | .gz .gzip | no |
| Bzip2 | .bz2 | no |
| XZ | .xz | no |
val file = env.readTextFile("/data/file.gz")因為Transform算子基于Source算子操作,所以首先構建Flink執行環境及Source算子,后續Transform算子操作基于此:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("張三,1", "李四,2", "王五,3", "張三,4")
)
將DataSet中的每一個元素轉換為另外一個元素:
// 使用map將List轉換為一個Scala的樣例類
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()
將DataSet中的每一個元素轉換為0...n個元素:
// 使用flatMap操作,將集合中的數據:
// 根據第一個元素,進行分組
// 根據第二個元素,進行聚合求值
val result = textDataSet.flatMap(line => line)
.groupBy(0) // 根據第一個元素,進行分組
.sum(1) // 根據第二個元素,進行聚合求值
result.print() 將一個分區中的元素轉換為另一個元素:
// 使用mapPartition操作,將List轉換為一個scala的樣例類
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
result.print()
過濾出來一些符合條件的元素,返回boolean值為true的元素:
val source: DataSet[String] = env.fromElements("java", "scala", "java")
val filter:DataSet[String] = source.filter(line => line.contains("java"))//過濾出帶java的數據
filter.print()
可以對一個dataset或者一個group來進行聚合計算,最終聚合成一個元素:
// 使用 fromElements 構建數據源
val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 使用map轉換成DataSet元組
val mapData: DataSet[(String, Int)] = source.map(line => line)
// 根據首個元素分組
val groupData = mapData.groupBy(_._1)
// 使用reduce聚合
val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2))
// 打印測試
reduceData.print()
將一個dataset或者一個group聚合成一個或多個元素。
reduceGroup是reduce的一種優化方案;
它會先分組reduce,然后在做整體的reduce;這樣做的好處就是可以減少網絡IO:
// 使用 fromElements 構建數據源
val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 根據首個元素分組
val groupData = source.groupBy(_._1)
// 使用reduceGroup聚合
val result: DataSet[(String, Int)] = groupData.reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
// 打印測試
result.print()
選擇具有最小值或最大值的元素:
// 使用minBy操作,求List中每個人的最小值
// List("張三,1", "李四,2", "王五,3", "張三,4")
case class User(name: String, id: String)
// 將List轉換為一個scala的樣例類
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0) // 按照姓名分組
.minBy(1) // 每個人的最小值 在數據集上進行聚合求最值(最大值、最小值):
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yuwen", 89.99))
// 使用 fromElements 構建數據源
val input: DataSet[(Int, String, Double)] = env.fromCollection(data)
// 使用group執行分組操作
val value = input.groupBy(1)
// 使用aggregate求最大值元素
.aggregate(Aggregations.MAX, 2)
// 打印測試
value.print() Aggregate只能作用于元組上
注意:
要使用aggregate,只能使用字段索引名或索引名稱來進行分組groupBy(0),否則會報一下錯誤:
Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
去除重復的數據:
// 數據源使用上一題的
// 使用distinct操作,根據科目去除集合中重復的元組數據
val value: DataSet[(Int, String, Double)] = input.distinct(1)
value.print()
取前N個數:
input.first(2) // 取前兩個數
將兩個DataSet按照一定條件連接到一起,形成新的DataSet:
// s1 和 s2 數據集格式如下:
// DataSet[(Int, String,String, Double)]
val joinData = s1.join(s2) // s1數據集 join s2數據集
.where(0).equalTo(0) { // join的條件
(s1, s2) => (s1._1, s1._2, s2._2, s1._3)
}
左外連接,左邊的Dataset中的每一個元素,去連接右邊的元素
此外還有:
rightOuterJoin:右外連接,左邊的Dataset中的每一個元素,去連接左邊的元素
fullOuterJoin:全外連接,左右兩邊的元素,全部連接
下面以 leftOuterJoin 進行示例:
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zhangsan"))
data1.append((2,"lisi"))
data1.append((3,"wangwu"))
data1.append((4,"zhaoliu"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"beijing"))
data2.append((2,"shanghai"))
data2.append((4,"guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()
交叉操作,通過形成這個數據集和其他數據集的笛卡爾積,創建一個新的數據集
和join類似,但是這種交叉操作會產生笛卡爾積,在數據比較大的時候,是非常消耗內存的操作:
val cross = input1.cross(input2){
(input1 , input2) => (input1._1,input1._2,input1._3,input2._2)
}
cross.print()
聯合操作,創建包含來自該數據集和其他數據集的元素的新數據集,不會去重:
val unionData: DataSet[String] = elements1.union(elements2).union(elements3)
// 去除重復數據
val value = unionData.distinct(line => line)
Flink也有數據傾斜的時候,比如當前有數據量大概10億條數據需要處理,在處理過程中可能會發生如圖所示的狀況:
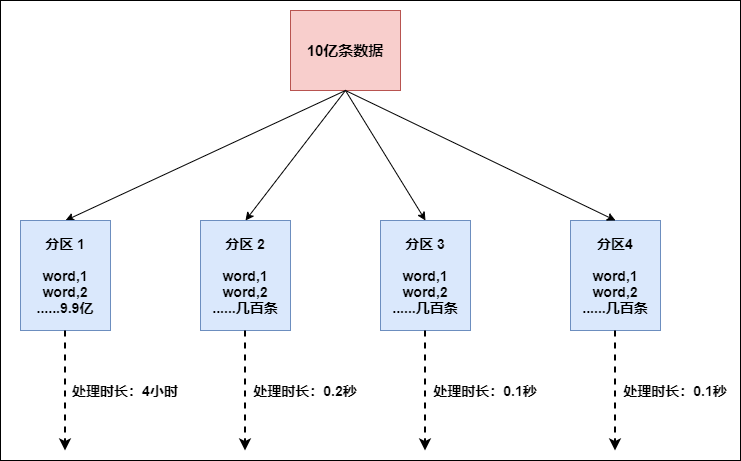
這個時候本來總體數據量只需要10分鐘解決的問題,出現了數據傾斜,機器1上的任務需要4個小時才能完成,那么其他3臺機器執行完畢也要等待機器1執行完畢后才算整體將任務完成;所以在實際的工作中,出現這種情況比較好的解決方案就是接下來要介紹的—rebalance(內部使用round robin方法將數據均勻打散。這對于數據傾斜時是很好的選擇。)
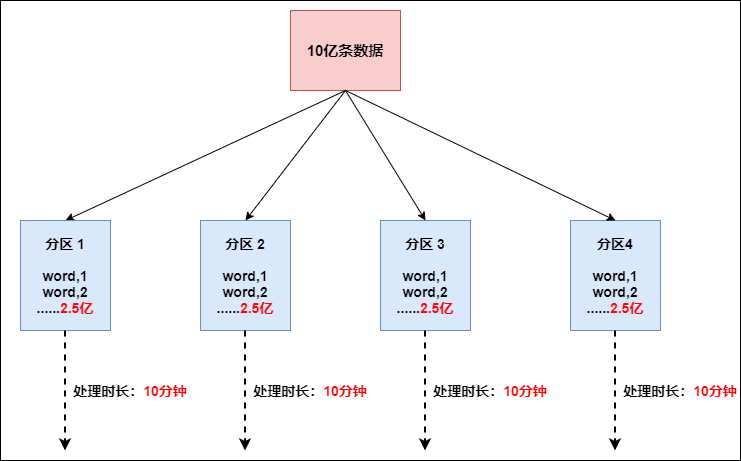
// 使用rebalance操作,避免數據傾斜
val rebalance = filterData.rebalance()
按照指定的key進行hash分區:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
val collection = env.fromCollection(data)
val unique = collection.partitionByHash(1).mapPartition{
line =>
line.map(x => (x._1 , x._2 , x._3))
}
unique.writeAsText("hashPartition", WriteMode.NO_OVERWRITE)
env.execute()
根據指定的key對數據集進行范圍分區:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val collection = env.fromCollection(data)
val unique = collection.partitionByRange(x => x._1).mapPartition(line => line.map{
x=>
(x._1 , x._2 , x._3)
})
unique.writeAsText("rangePartition", WriteMode.OVERWRITE)
env.execute()
根據指定的字段值進行分區的排序:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val ds = env.fromCollection(data)
val result = ds
.map { x => x }.setParallelism(2)
.sortPartition(1, Order.DESCENDING)//第一個參數代表按照哪個字段進行分區
.mapPartition(line => line)
.collect()
println(result)
將數據輸出到本地集合:
result.collect()
將數據輸出到文件
Flink支持多種存儲設備上的文件,包括本地文件,hdfs文件等
Flink支持多種文件的存儲格式,包括text文件,CSV文件等
// 將數據寫入本地文件
result.writeAsText("/data/a", WriteMode.OVERWRITE)
// 將數據寫入HDFS
result.writeAsText("hdfs://node01:9000/data/a", WriteMode.OVERWRITE)
和DataSet一樣,DataStream也包括一系列的Transformation操作。
Flink可以使用 StreamExecutionEnvironment.addSource(source) 來為我們的程序添加數據來源。
Flink 已經提供了若干實現好了的 source functions,當然我們也可以通過實現 SourceFunction 來自定義非并行的source或者實現 ParallelSourceFunction 接口或者擴展 RichParallelSourceFunction 來自定義并行的 source。
Flink在流處理上的source和在批處理上的source基本一致。大致有4大類:
下面使用addSource將Kafka數據寫入Flink為例:
如果需要外部數據源對接,可使用addSource,如將Kafka數據寫入Flink, 先引入依賴:
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.0</version>
</dependency>
將Kafka數據寫入Flink:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val source = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
基于網絡套接字的:
val source = env.socketTextStream("IP", PORT)將DataSet中的每一個元素轉換為另外一個元素:
dataStream.map { x => x * 2 }采用一個數據元并生成零個,一個或多個數據元。將句子分割為單詞的flatmap函數:
dataStream.flatMap { str => str.split(" ") }計算每個數據元的布爾函數,并保存函數返回true的數據元。過濾掉零值的過濾器:
dataStream.filter { _ != 0 }邏輯上將流分區為不相交的分區。具有相同Keys的所有記錄都分配給同一分區。在內部,keyBy()是使用散列分區實現的。指定鍵有不同的方法。
此轉換返回KeyedStream,其中包括使用被Keys化狀態所需的KeyedStream:
dataStream.keyBy(0)
被Keys化數據流上的“滾動”Reduce。將當前數據元與最后一個Reduce的值組合并發出新值:
keyedStream.reduce { _ + _ }具有初始值的被Keys化數據流上的“滾動”折疊。將當前數據元與最后折疊的值組合并發出新值:
val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i })
// 解釋:當上述代碼應用于序列(1,2,3,4,5)時,輸出結果“start-1”,“start-1-2”,“start-1-2-3”,...
在被Keys化數據流上滾動聚合。min和minBy之間的差異是min返回最小值,而minBy返回該字段中具有最小值的數據元(max和maxBy相同):
keyedStream.sum(0);
keyedStream.min(0);
keyedStream.max(0);
keyedStream.minBy(0);
keyedStream.maxBy(0);
可以在已經分區的KeyedStream上定義Windows。Windows根據某些特征(例如,在最后5秒內到達的數據)對每個Keys中的數據進行分組。這里不再對窗口進行詳解,有關窗口的完整說明,請查看這篇文章:Flink 中極其重要的 Time 與 Window 詳細解析
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
Windows可以在常規DataStream上定義。Windows根據某些特征(例如,在最后5秒內到達的數據)對所有流事件進行分組。
注意:在許多情況下,這是非并行轉換。所有記錄將收集在windowAll 算子的一個任務中。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
將一般函數應用于整個窗口。
注意:如果您正在使用windowAll轉換,則需要使用AllWindowFunction。
下面是一個手動求和窗口數據元的函數:
windowedStream.apply { WindowFunction }
allWindowedStream.apply { AllWindowFunction }
將函數縮減函數應用于窗口并返回縮小的值:
windowedStream.reduce { _ + _ }將函數折疊函數應用于窗口并返回折疊值:
val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i })
// 上述代碼應用于序列(1,2,3,4,5)時,將序列折疊為字符串“start-1-2-3-4-5”
兩個或多個數據流的聯合,創建包含來自所有流的所有數據元的新流。注意:如果將數據流與自身聯合,則會在結果流中獲取兩次數據元:
dataStream.union(otherStream1, otherStream2, ...)
在給定Keys和公共窗口上連接兩個數據流:
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...})
在給定的時間間隔內使用公共Keys關聯兩個被Key化的數據流的兩個數據元e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
am.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2))
.upperBoundExclusive(true)
.lowerBoundExclusive(true)
.process(new IntervalJoinFunction() {...})
在給定Keys和公共窗口上對兩個數據流進行Cogroup:
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...})
“連接”兩個保存其類型的數據流。連接允許兩個流之間的共享狀態:
DataStream<Integer> someStream = ... DataStream<String> otherStream = ... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream)
// ... 代表省略中間操作
類似于連接數據流上的map和flatMap:
connectedStreams.map(
(_ : Int) => true,
(_ : String) => false)connectedStreams.flatMap(
(_ : Int) => true,
(_ : String) => false)
根據某些標準將流拆分為兩個或更多個流:
val split = someDataStream.split(
(num: Int) =>
(num % 2) match {
case 0 => List("even")
case 1 => List("odd")
})
從拆分流中選擇一個或多個流:
SplitStream<Integer> split;DataStream<Integer> even = split.select("even");DataStream<Integer> odd = split.select("odd");DataStream<Integer> all = split.select("even","odd")
支持將數據輸出到:
除此之外,還支持:
下面以sink到kafka為例:
val sinkTopic = "test"
//樣例類
case class Student(id: Int, name: String, addr: String, sex: String)
val mapper: ObjectMapper = new ObjectMapper()
//將對象轉換成字符串
def toJsonString(T: Object): String = {
mapper.registerModule(DefaultScalaModule)
mapper.writeValueAsString(T)
}
def main(args: Array[String]): Unit = {
//1.創建流執行環境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.準備數據
val dataStream: DataStream[Student] = env.fromElements(
Student(8, "xiaoming", "beijing biejing", "female")
)
//將student轉換成字符串
val studentStream: DataStream[String] = dataStream.map(student =>
toJsonString(student) // 這里需要顯示SerializerFeature中的某一個,否則會報同時匹配兩個方法的錯誤
)
//studentStream.print()
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092")
val myProducer = new FlinkKafkaProducer011[String](sinkTopic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), prop)
studentStream.addSink(myProducer)
studentStream.print()
env.execute("Flink add sink")
}到此,關于“Flink流計算常用算子是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





