溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關OLAP中怎么使用Druid組件實現數據統計分析,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Druid是一款基于分布式架構的OLAP引擎,支持數據寫入、低延時、高性能的數據分析,具有優秀的數據聚合能力與實時查詢能力。在大數據分析、實時計算、監控等領域都有相關的應用場景,是大數據基礎架構建設中重要組件。
與現在相對熱門的Clickhouse引擎相比,Druid對高并發的支持相對較好和穩定,但是Clickhouse在任務隊列模式中的數據查詢能力十分出色,但是對高并發支持不夠友好,需要做好很多服務監控和預警。大數據組件中OLAP引擎的選型有很多,在數據的查詢引擎層通常都具有兩種或者以上的OLAP引擎,選擇合適的組件解決業務需求是優先原則。
分布式
分布式的OLAP數據引擎,數據分布在多個服務節點中,當數據量激烈增長的時候,可以通過增加節點的方式進行水平擴容,數據在多個節點相互備份,如果單個節點出現故障,則可基于Zookeeper調度機制重新構建數據,這是分布式OLAP引擎的基本特點,在之前Clickhouse系列中也說過這個策略。
聚合查詢
主要針對時間序列數據提供低延時數據寫入和快速聚合查詢,時序數據庫特點寫入即可查詢,Druid在數據寫入時就會對數據預聚合,進而減少原始數據量,節省存儲空間并提升查詢效率;數據聚合粒度可以基于特定策略,例如分鐘、小時、天等。必須要強調Druid適合數據分析場景,并不適合單條數據主鍵查詢的業務。
列式存儲
Druid面向列的存儲方式,并且可以在集群中進行大規模的并行查詢,這意味在只需要加載特定查詢所需要的列情況下,查詢速度可以大幅度提升。
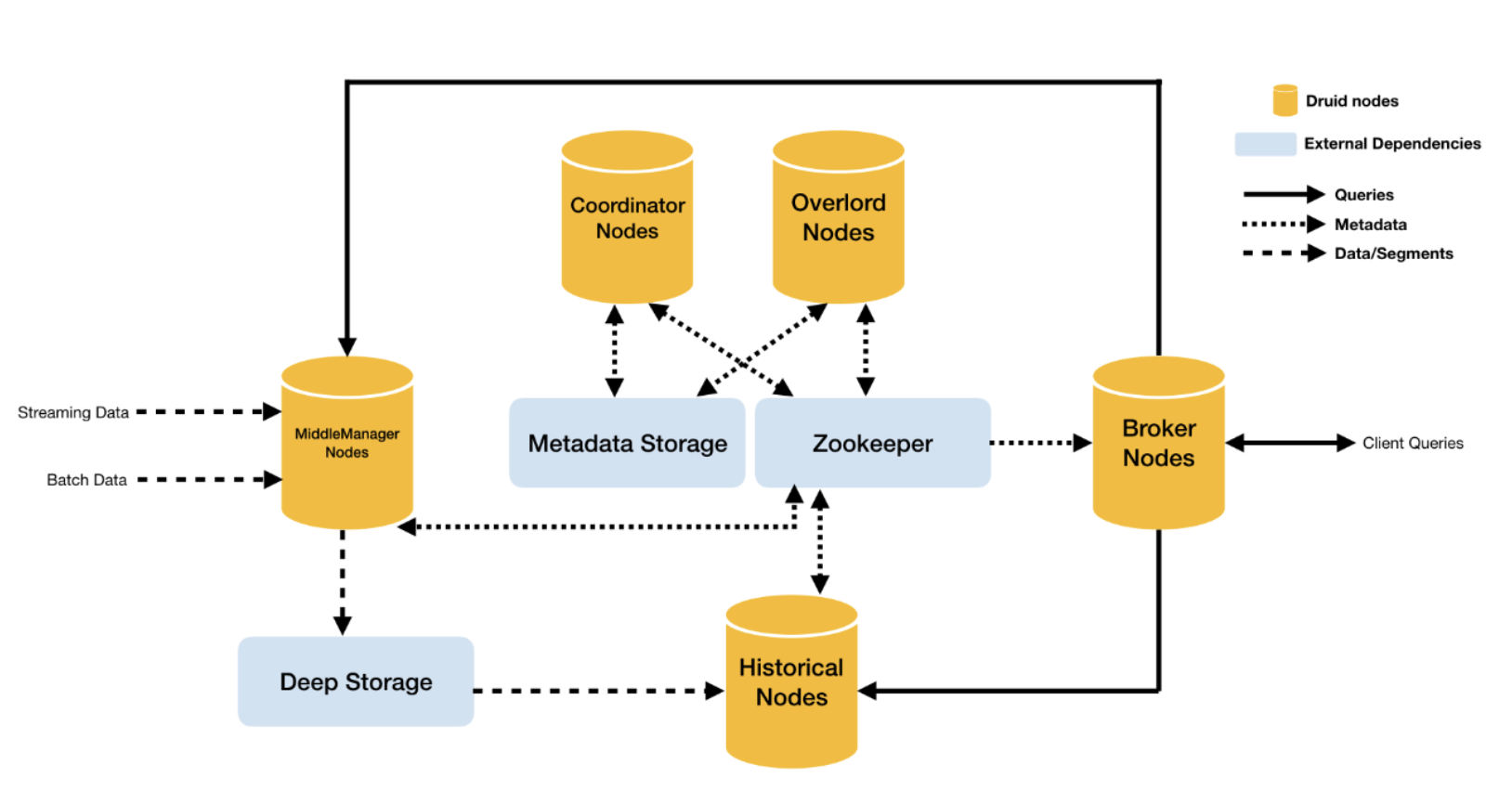
統治者節點
即Overlord-Node,任務的管理節點,進程監視MiddleManager進程,并且是數據攝入Druid的控制器,負責將提取任務分配給MiddleManagers并協調Segement發布。
協調節點
即Coordinator-Node,主要負責數據的管理和在歷史節點上的分布,協調節點告訴歷史節點加載新數據、卸載過期數據、復制數據、和為了負載均衡移動數據。
中間管理節點
即MiddleManager-Node,攝入實時數據,已生成Segment數據文件,可以理解為overlord節點的工作節點。
歷史節點
即Historical-Node,主要負責歷史數據存儲和查詢,接收協調節點數據加載與刪除指令,historical節點是整個集群查詢性能的核心所在,因為historical會承擔絕大部分的segment查詢。
查詢節點
即Broker-Node,扮演著歷史節點和實時節點的查詢路由的角色,接收客戶端查詢請求,并將這些查詢轉發給Historicals和MiddleManagers,當Brokers從這些子查詢中收到結果時,它們會合并這些結果并將它們返回給調用者。
數據文件存儲庫
即DeepStorage,存放生成的Segment數據文件。
元數據庫
即MetadataStorage,存儲Druid集群的元數據信息,比如Segment的相關信息。
協調中間件
即Zookeeper,為Druid集群提供協調服務,如內部服務的監控,協調和領導者選舉。
imply對druid做了集成,并提供從部署到配置到各種可視化工具的完整的解決方案。
https://static.imply.io/release/imply-2.7.10.tar.gz
解壓并重新命名。
[root@hop01 opt]# tar -zxvf imply-2.7.10.tar.gz [root@hop01 opt]# mv imply-2.7.10 imply2.7
配置Zookeeper集群各個節點,逗號分隔。
[root@hop01 _common]# cd /opt/imply2.7/conf/druid/_common [root@hop01 _common]# vim common.runtime.properties druid.zk.service.host=hop01:2181,hop02:2181,hop03:2181
關閉Zookeeper內置校驗并且不啟動。
[root@hop01 supervise]# cd /opt/imply2.7/conf/supervise [root@hop01 supervise]# vim quickstart.conf
注釋掉如下內容:
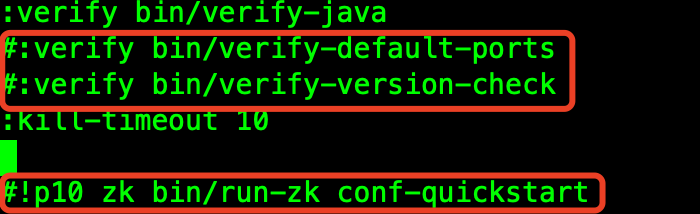
依次啟動相關組件:Zookeeper、Hadoop相關組件,然后啟動imply服務。
[root@hop01 imply2.7]# /opt/imply2.7/bin/supervise -c /opt/imply2.7/conf/supervise/quickstart.conf
注意虛擬機內存問題,在如下的目錄中Druid各個組件的JVM配置,條件不允許的話適當拉低,并且要拉高JVM相關內存參數。
[root@hop01 druid]# cd /opt/imply2.7/conf/druid
啟動默認端口:9095,訪問界面如下:
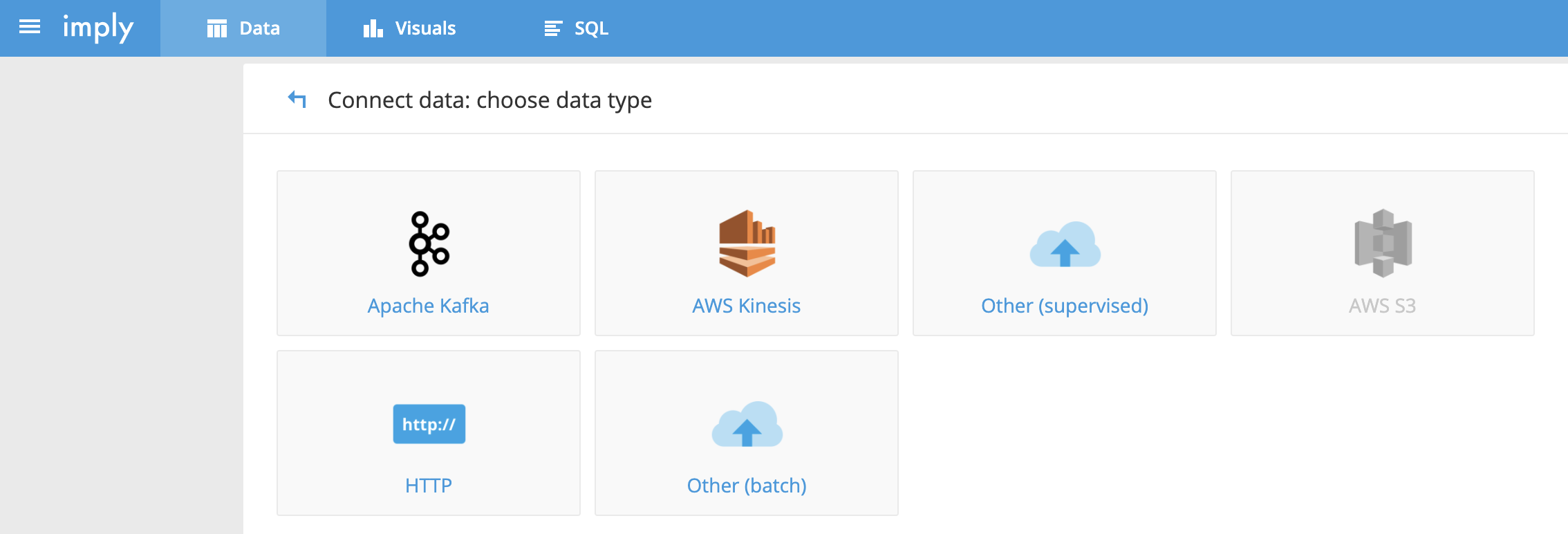
選擇上述Http的方式,基于imply提供的JSON測試文件。
https://static.imply.io/data/wikipedia.json.gz
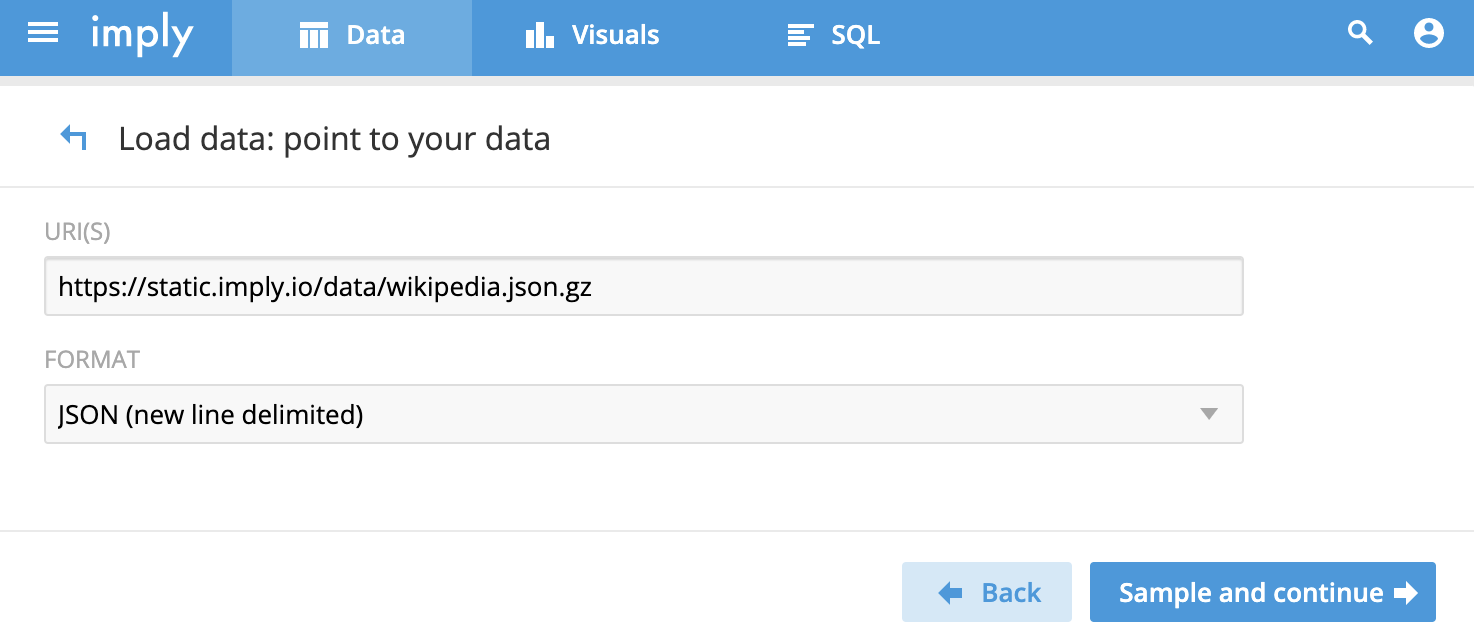
執行上述:Sample and continue。
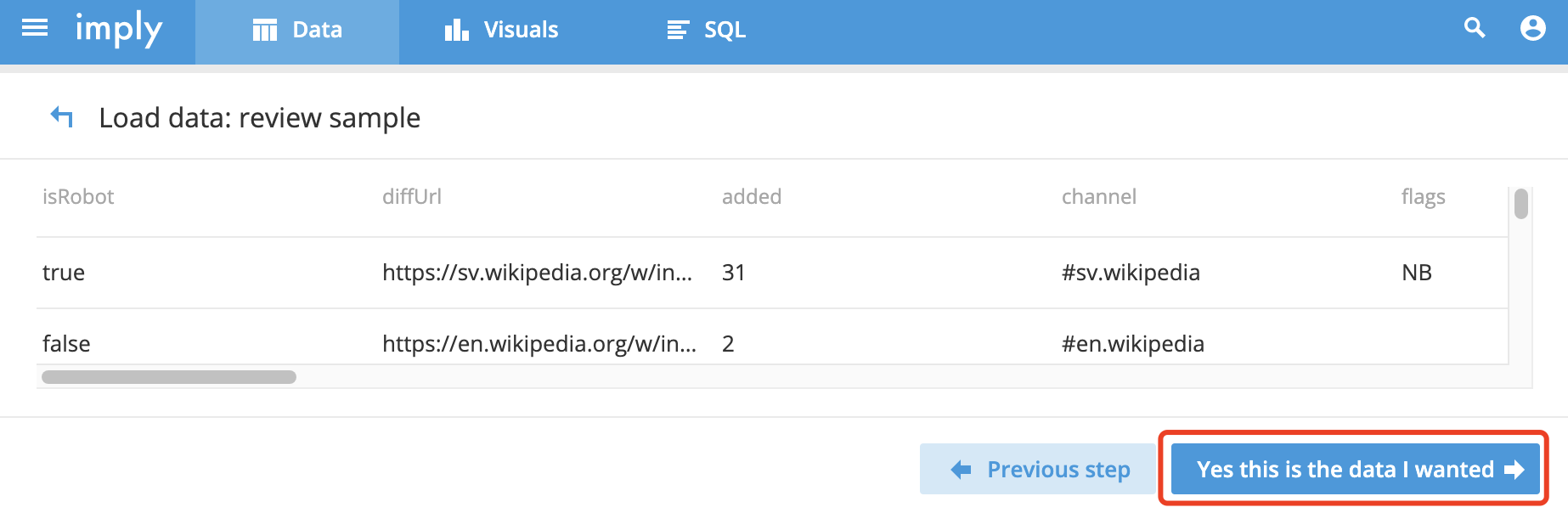
樣本數據加載配置:
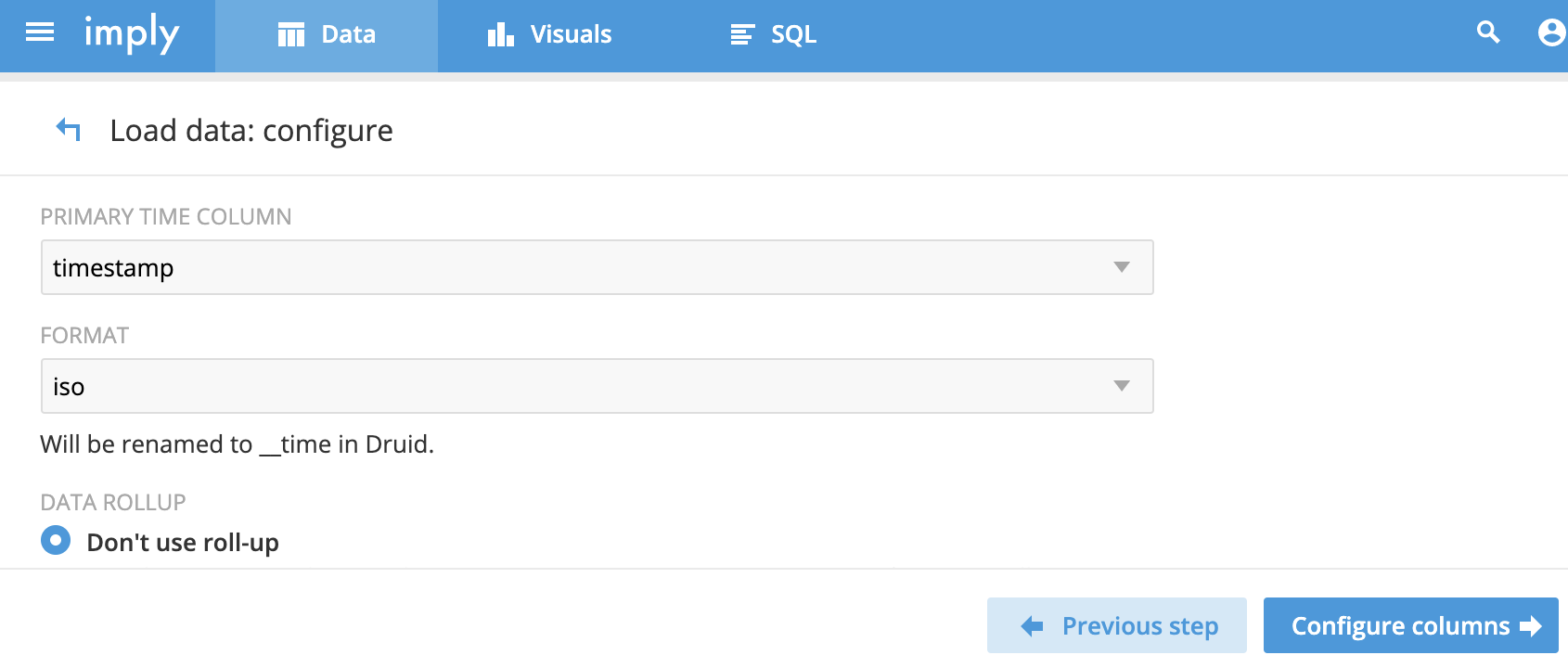
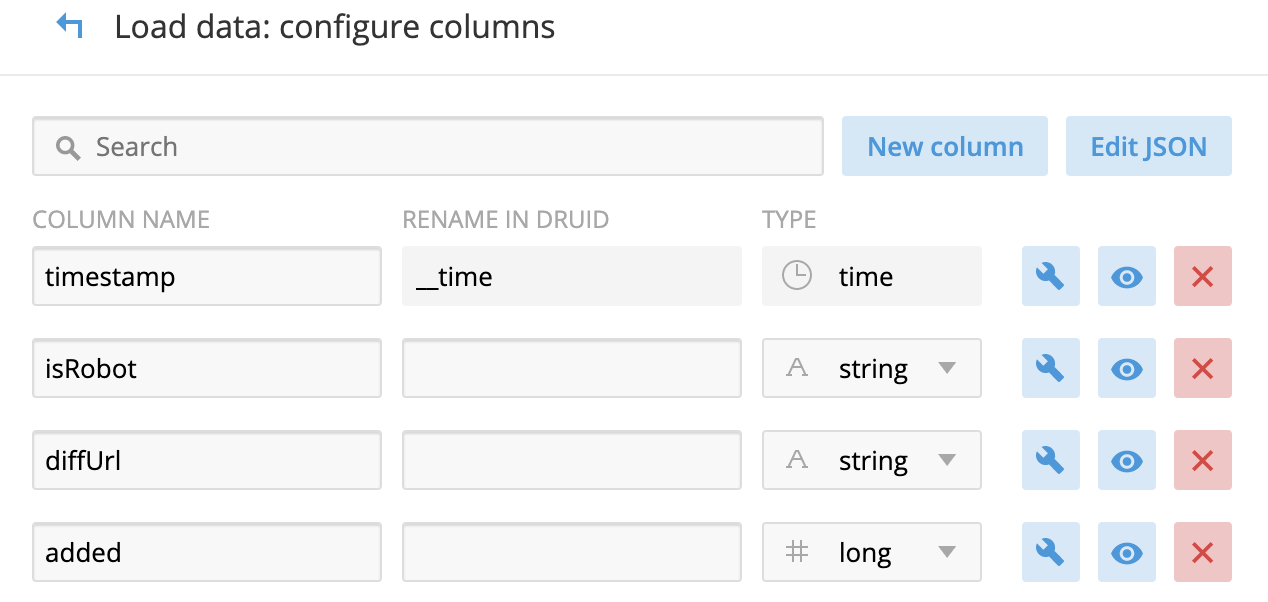
數據列的配置:
配置項總體概覽:
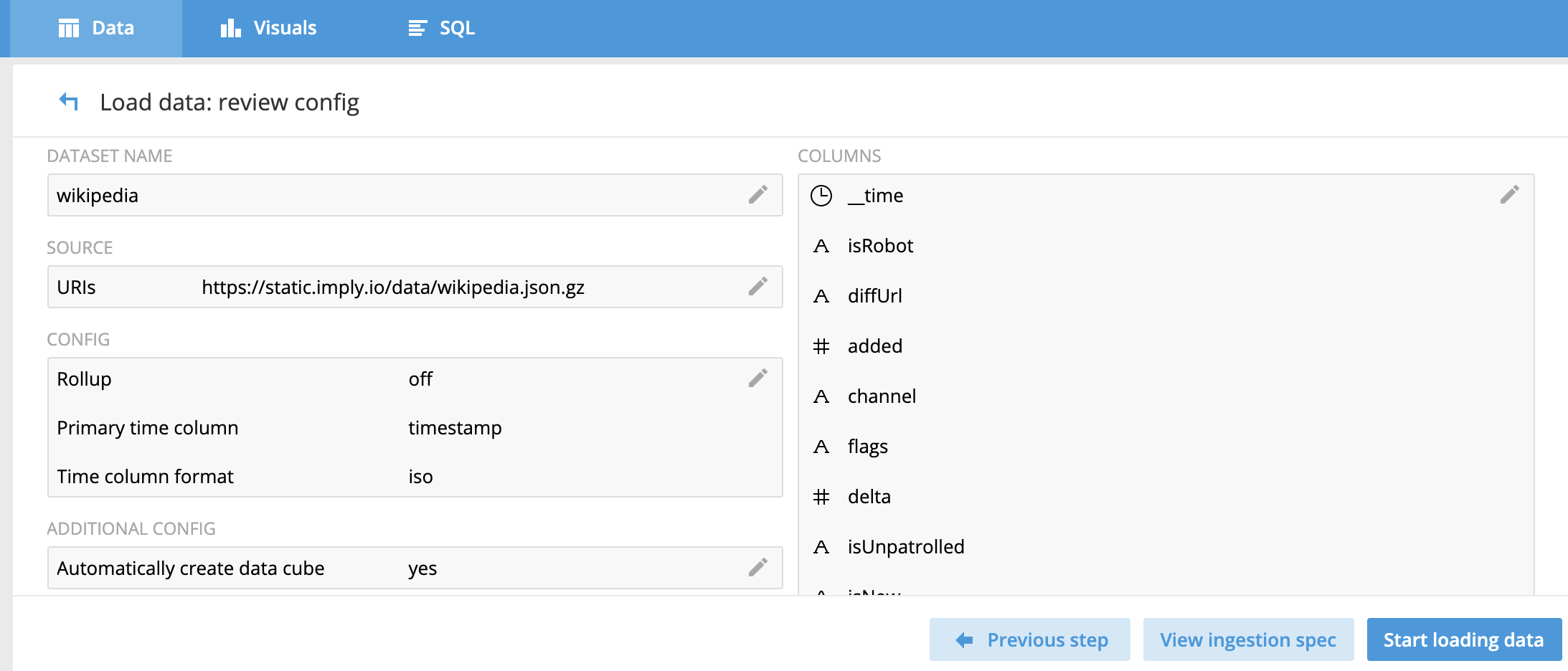
最后執行數據加載任務即可。
[root@hop01 imply2.7]# bin/post-index-task --file quickstart/wikipedia-index.json
這樣讀取兩份數據腳本。
數據加載完成后,查看可視化數據立方體:
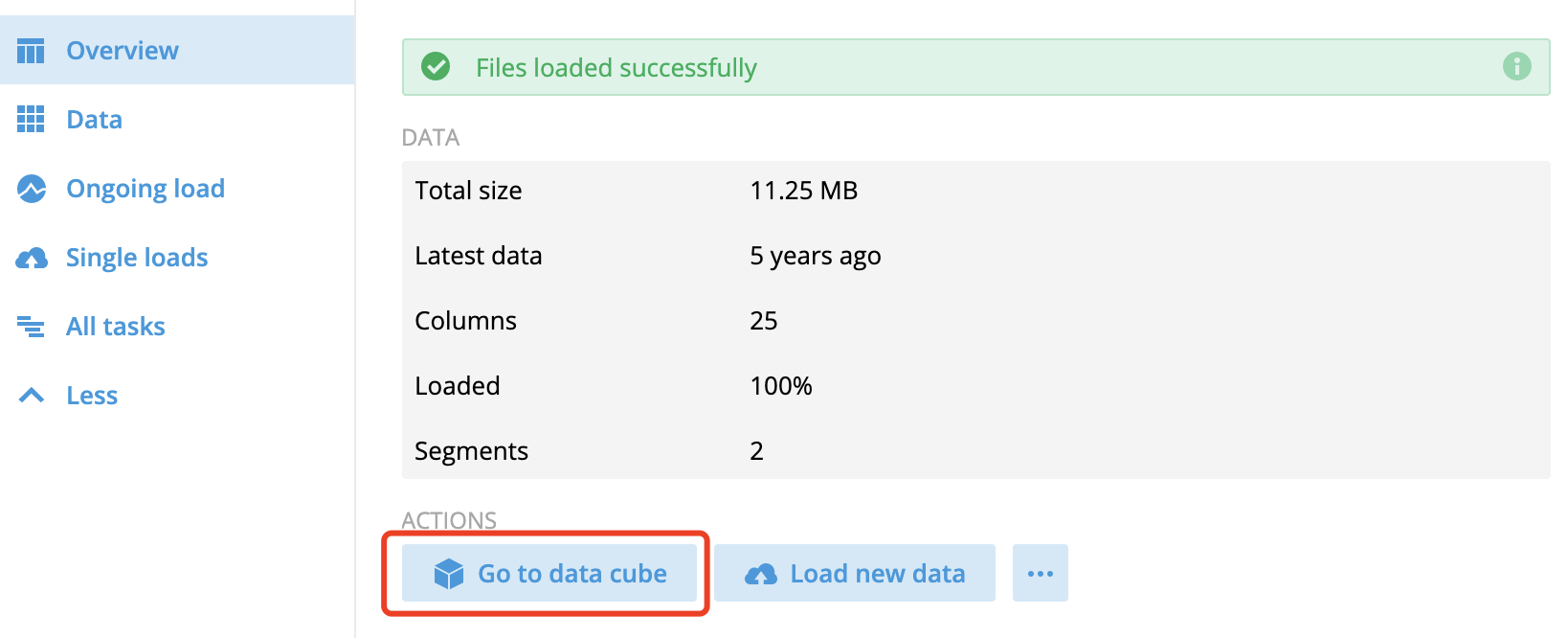
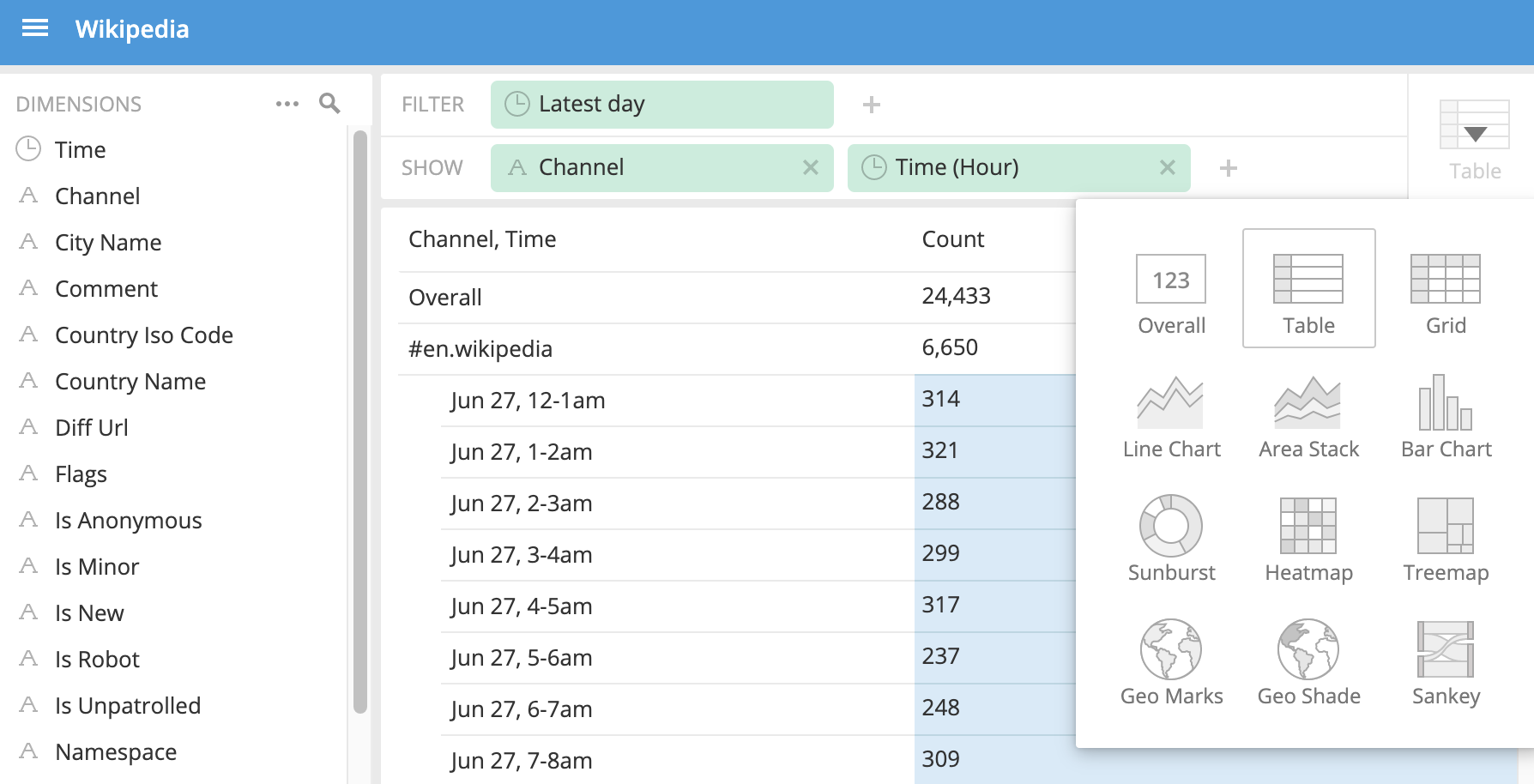
數據立方體中提供一些基礎的視圖分析,可以在多個維度上拆分數據集并進行數據分析:
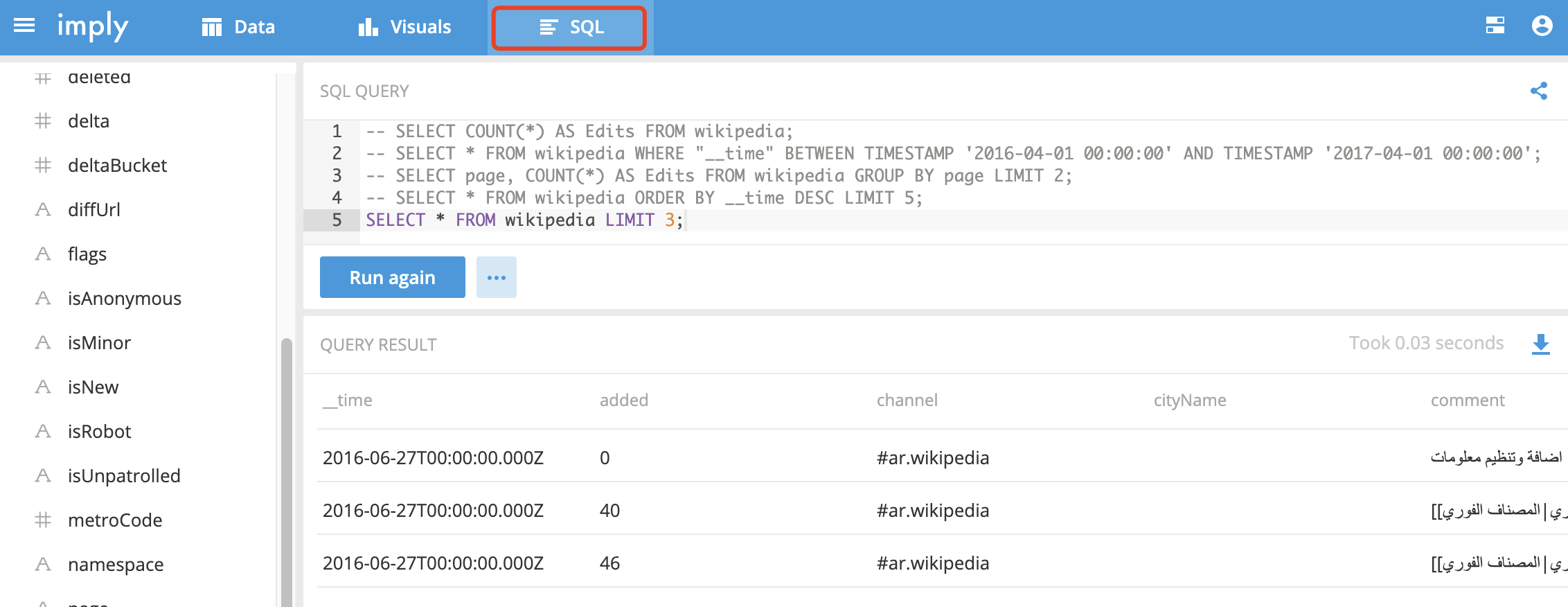
可以基于可視化工具對Druid進行SQL查詢,語法與常用規則幾乎一樣:
SELECT COUNT(*) AS Edits FROM wikipedia; SELECT * FROM wikipedia WHERE "__time" BETWEEN TIMESTAMP '開始' AND TIMESTAMP '結束'; SELECT page, COUNT(*) AS Edits FROM wikipedia GROUP BY page LIMIT 2; SELECT * FROM wikipedia ORDER BY __time DESC LIMIT 5; SELECT * FROM wikipedia LIMIT 3;
文件位置:
/opt/imply2.7/var/druid/segments/wikipedia/
Druid基于Segment實現對數據的切割,數據按時間的時序分布,將不同時間范圍內的數據存儲在不同的Segment數據塊中,按時間范圍查詢數據時,可以避免全數據掃描效率可以極大的提高,同時面向列進行數據壓縮存儲,提高分析的效率。
以上就是OLAP中怎么使用Druid組件實現數據統計分析,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





