溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Fuzz結果分析和代碼覆蓋率指的是什么,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
下面介紹何時結束測試過程,以及測試完成后又需要做些什么。并開始逐步介紹一些AFL相關原理,以下是文中主要討論的問題:
1.何時結束Fuzzing工作
2.afl-fuzz生成了哪些文件
3.如何對產生的crash進行驗證和分類
4.用什么來評估Fuzzing的結果
5.代碼覆蓋率及相關概念
6.AFL是如何記錄代碼覆蓋率的
因為afl-fuzz永遠不會停止,所以何時停止測試很多時候就是依靠afl-fuzz提供的狀態來決定的。除了前面提到過的通過狀態窗口、afl-whatsup查看afl-fuzz狀態外,這里再補充幾種方法。
afl-stat是afl-utils這套工具AFL輔助工具中的一個(這套工具中還有其他更好用的程序,后面用到時會做介紹),該工具類似于afl-whatsup的輸出結果。
使用前需要一個配置文件,設置每個afl-fuzz實例的輸出目錄:
{
"fuzz_dirs": [
"/root/syncdir/SESSION000",
"/root/syncdir/SESSION001",
...
"/root/syncdir/SESSION00x"
]
}然后指定配置文件運行即可:
$ afl-stats -c afl-stats.conf [SESSION000 on fuzzer1] Alive: 1/1 Execs: 64 m Speed: 0.3 x/s Pend: 6588/249 Crashes: 101 [SESSION001 on fuzzer1] Alive: 1/1 Execs: 105 m Speed: 576.6 x/s Pend: 417/0 Crashes: 291 ...
afl-whatsup是依靠讀afl-fuzz輸出目錄中的fuzzer_stats文件來顯示狀態的,每次查看都要需要手動執行,十分麻煩。因此可以對其進行修改,讓其實時顯示fuzzer的狀態。方法也很簡答,基本思路就是在所有代碼外面加個循環就好,還可以根據自己的喜好做些調整: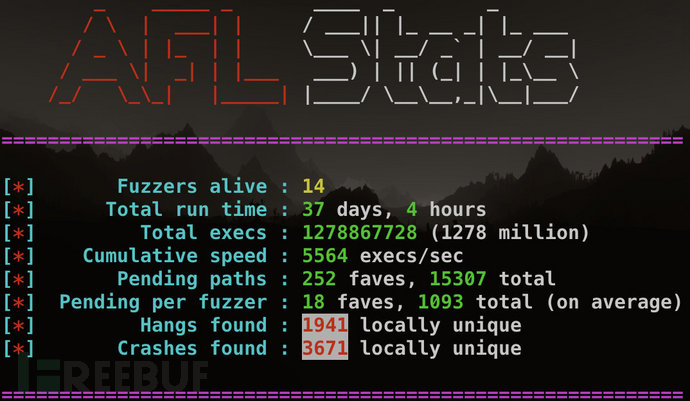
前面提到的都是基于命令行的工具,如果還想要更直觀的結果,可以用afl-plot繪制各種狀態指標的直觀變化趨勢。
#安裝依賴工具gnuplot $ apt-get install gnuplot $ afl-plot afl_state_dir graph_output_dir
以測試libtiff的情況為例,進入afl-plot輸出目錄,打開index.html,會看到下面三張圖:
首先是路徑覆蓋的變化,當pending fav的數量變為零并且total paths數量基本上沒有再增長時,說明fuzzer有新發現的可能性就很小了。
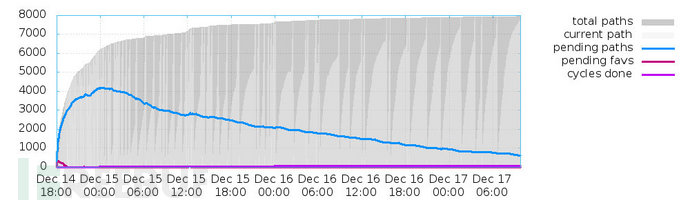
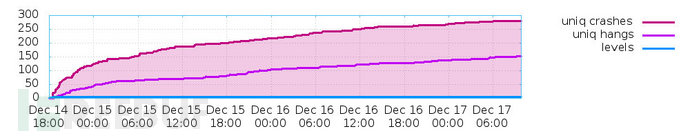
接著是崩潰和超時的變化
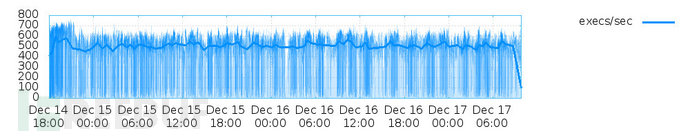
最后是執行速度的變化,這里要注意的是,如果隨著時間的推移,執行速度越來越慢,有一種可能是因為fuzzer耗盡一些共享資源。
筆者在查閱資料的過程中,還發現了pythia這個AFL的擴展項目,雖然不知道效果如何,但這里還是順便提一提。其特色在于可以估算發現新crash和path概率,其運行界面相比原版的AFL多出了下面幾個字段:
correctness: 在沒有發現crash時,發現一個導致crash輸入的概率。
fuzzability: 表示在該程序中發現新路徑的難度,該數值越高代表程序越容易Fuzz。
current paths: 顯示當前發現的路徑數。
path coverag: 路徑覆蓋率。
檢查afl-fuzz工作狀態的目的是為何時停止測試提供依據,通常來說符合下面幾種情況時就可以停掉了。
(1)狀態窗口中"cycles done"字段顏色變為綠色該字段的顏色可以作為何時停止測試的參考,隨著周期數不斷增大,其顏色也會由洋紅色,逐步變為黃色、藍色、綠色。當其變為綠色時,繼續Fuzzing下去也很難有新的發現了,這時便可以通過Ctrl-C停止afl-fuzz。
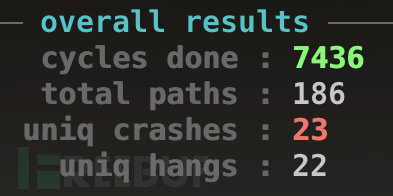
(2)距上一次發現新路徑(或者崩潰)已經過去很長時間了,至于具體多少時間還是需要自己把握,比如長達一個星期或者更久估計大家也都沒啥耐心了吧。
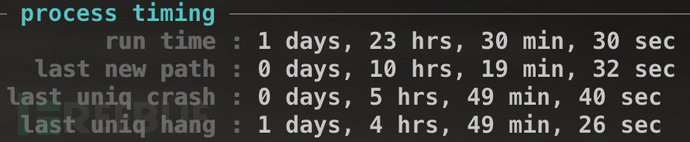
(3)目標程序的代碼幾乎被測試用例完全覆蓋,這種情況好像很少見,但是對于某些小型程序應該還是可能的,至于如何計算覆蓋率將在下面介紹。
(4)上面提到的pythia提供的各種數據中,一旦path covera達到99%(通常來說不太可能),如果不期望再跑出更多crash的話就可以中止fuzz了,因為很多crash可能是因為相同的原因導致的;還有一點就是correctness的值達到1e-08,根據pythia開發者的說法,這時從上次發現path/uniq crash到下一次發現之間大約需要1億次執行,這一點也可以作為衡量依據。
afl-fuzz的輸出目錄中存在很多文件,有時想要寫一個輔助工具可能就要用到其中的文件。下面以多個fuzz實例并行測試時的同步目錄為例:
$ tree -L 3 . ├── fuzzer1 │ ├── crashes │ │ ├── id:000000,sig:06,src:000019+000074,op:splice,rep:2 │ │ ├── ... │ │ ├── id:000002,sig:06,src:000038+000125,op:splice,rep:4 │ │ └── README.txt │ ├── fuzz_bitmap │ ├── fuzzer_stats │ ├── hangs │ │ └── id:000000,src:000007,op:flip1,pos:55595 │ ├── plot_data │ └── queue │ ├── id:000000,orig:1.png │ ├── .... │ └── id:000101,sync:fuzzer10,src:000102 └── fuzzer2 ├── crashes ├── ...
queue:存放所有具有獨特執行路徑的測試用例。
crashes:導致目標接收致命signal而崩潰的獨特測試用例。
crashes/README.txt:保存了目標執行這些crash文件的命令行參數。
hangs:導致目標超時的獨特測試用例。
fuzzer_stats:afl-fuzz的運行狀態。
plot_data:用于afl-plot繪圖。
到了這里,我們可能已經跑出了一大堆的crashes,那么接下來的步驟,自然是確定造成這些crashes的bug是否可以利用,怎么利用?這是另一個重要方面。當然,個人覺得這比前面提到的內容都要困難得多,這需要對常見的二進制漏洞類型、操作系統的安全機制、代碼審計和調試等內容都有一定深度的了解。但如果只是對crash做簡單的分析和分類,那么下面介紹的幾種方法都可以給我們提供一些幫助。
這是afl-fuzz的一種運行模式,也稱為peruvian rabbit mode,用于確定bug的可利用性,具體細節可以參考lcamtuf的博客。
$ afl-fuzz -m none -C -i poc -o peruvian-were-rabbit_out -- ~/src/LuPng/a.out @@ out.png
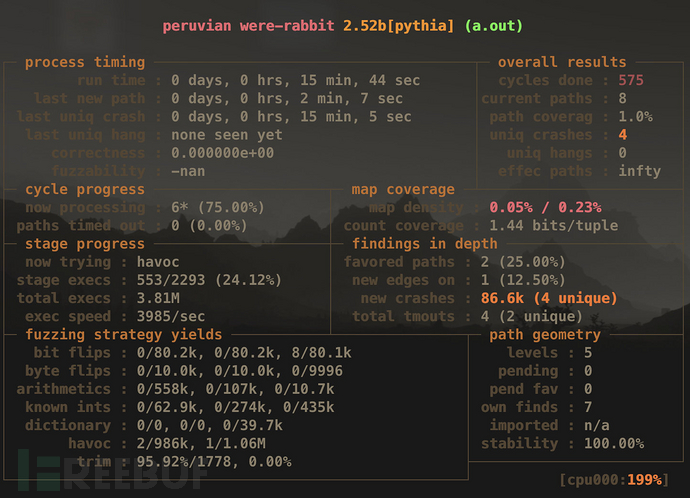
舉個例子,當你發現目標程序嘗試寫入\跳轉到一個明顯來自輸入文件的內存地址,那么就可以猜測這個bug應該是可以利用的;然而遇到例如NULL pointer dereferences這樣的漏洞就沒那么容易判斷了。
將一個導致crash測試用例作為afl-fuzz的輸入,使用-C選項開啟crash exploration模式后,可以快速地產生很多和輸入crash相關、但稍有些不同的crashes,從而判斷能夠控制某塊內存地址的長度。這里筆者在實踐中沒有找到適合的例子,但在一篇文章中發現了一個很不錯的例子——tcpdump棧溢出漏洞,crash exploration模式從一個crash產生了42個新的crash,并讀取不同大小的相鄰內存。

AFL源碼的experimental目錄中有一個名為triage_crashes.sh的腳本,可以幫助我們觸發收集到的crashes。例如下面的例子中,11代表了SIGSEGV信號,有可能是因為緩沖區溢出導致進程引用了無效的內存;06代表了SIGABRT信號,可能是執行了abort\assert函數或double free導致,這些結果可以作為簡單的參考。
$ ~/afl-2.52b/experimental/crash_triage/triage_crashes.sh fuzz_out ~/src/LuPng/a.out @@ out.png 2>&1 | grep SIGNAL +++ ID 000000, SIGNAL 11 +++ +++ ID 000001, SIGNAL 06 +++ +++ ID 000002, SIGNAL 06 +++ +++ ID 000003, SIGNAL 06 +++ +++ ID 000004, SIGNAL 11 +++ +++ ID 000005, SIGNAL 11 +++ +++ ID 000006, SIGNAL 11 +++ ...
當然上面的兩種方式都過于雞肋了,如果你想得到更細致的crashes分類結果,以及導致crashes的具體原因,那么crashwalk就是不錯的選擇之一。這個工具基于gdb的exploitable插件,安裝也相對簡單,在ubuntu上,只需要如下幾步即可:
$ apt-get install gdb golang $ mkdir tools $ cd tools $ git clone https://github.com/jfoote/exploitable.git $ mkdir go $ export GOPATH=~/tools/go $ export CW_EXPLOITABLE=~/tools/exploitable/exploitable/exploitable.py $ go get -u github.com/bnagy/crashwalk/cmd/...
crashwalk支持AFL/Manual兩種模式。前者通過讀取crashes/README.txt文件獲得目標的執行命令(前面第三節中提到的),后者則可以手動指定一些參數。兩種使用方式如下:
#Manual Mode $ ~/tools/go/bin/cwtriage -root syncdir/fuzzer1/crashes/ -match id -- ~/parse @@ #AFL Mode $ ~/tools/go/bin/cwtriage -root syncdir -afl
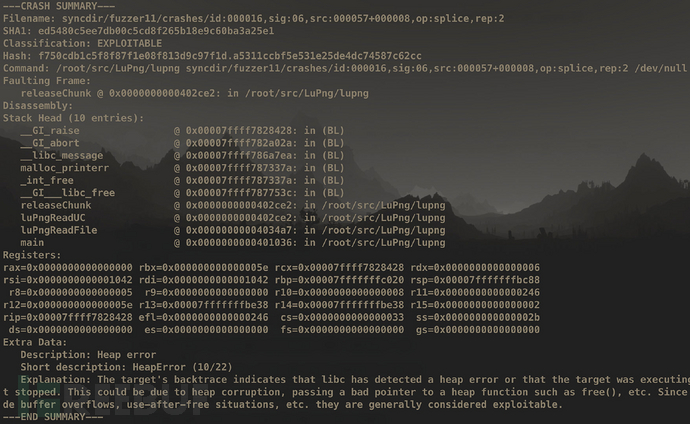
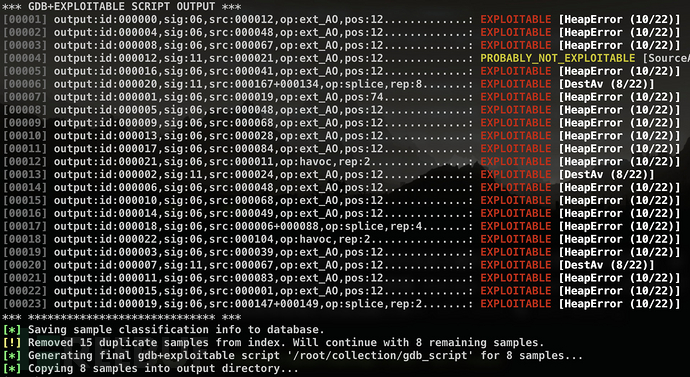
兩種模式的輸出結果都一樣,如上圖所示。這個工具比前面幾種方法要詳細多了,但當有大量crashes時結果顯得還是十分混亂。
最后重磅推薦的工具便是afl-collect,它也是afl-utils套件中的一個工具,同樣也是基于exploitable來檢查crashes的可利用性。它可以自動刪除無效的crash樣本、刪除重復樣本以及自動化樣本分類。使用起來命令稍微長一點,如下所示:
$ afl-collect -j 8 -d crashes.db -e gdb_script ./afl_sync_dir ./collection_dir -- /path/to/target --target-opts
但是結果就像下面這樣非常直觀:
代碼覆蓋率是模糊測試中一個極其重要的概念,使用代碼覆蓋率可以評估和改進測試過程,執行到的代碼越多,找到bug的可能性就越大,畢竟,在覆蓋的代碼中并不能100%發現bug,在未覆蓋的代碼中卻是100%找不到任何bug的,所以本節中就將詳細介紹代碼覆蓋率的相關概念。
代碼覆蓋率是一種度量代碼的覆蓋程度的方式,也就是指源代碼中的某行代碼是否已執行;對二進制程序,還可將此概念理解為匯編代碼中的某條指令是否已執行。其計量方式很多,但無論是GCC的GCOV還是LLVM的SanitizerCoverage,都提供函數(function)、基本塊(basic-block)、邊界(edge)三種級別的覆蓋率檢測,更具體的細節可以參考LLVM的官方文檔。
縮寫為BB,指一組順序執行的指令,BB中第一條指令被執行后,后續的指令也會被全部執行,每個BB中所有指令的執行次數是相同的,也就是說一個BB必須滿足以下特征:
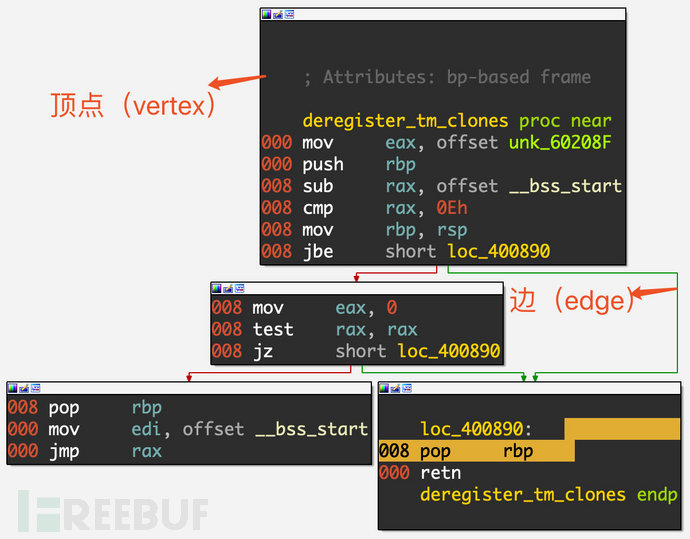
只有一個入口點,BB中的指令不是任何跳轉指令的目標。
只有一個退出點,只有最后一條指令使執行流程轉移到另一個BB

將上面的程序拖進IDA,可以看到同樣被劃分出了4個基本塊:

AFL的技術白皮書中提到fuzzer通過插樁代碼捕獲邊(edge)覆蓋率。那么什么是edge呢?我們可以將程序看成一個控制流圖(CFG),圖的每個節點表示一個基本塊,而edge就被用來表示在基本塊之間的轉跳。知道了每個基本塊和跳轉的執行次數,就可以知道程序中的每個語句和分支的執行次數,從而獲得比記錄BB更細粒度的覆蓋率信息。
具體到AFL的實現中,使用二元組(branch_src, branch_dst)來記錄當前基本塊 + 前一基本塊 的信息,從而獲取目標的執行流程和代碼覆蓋情況,偽代碼如下:
cur_location = <COMPILE_TIME_RANDOM>;//用一個隨機數標記當前基本塊 shared_mem[cur_location ^ prev_location]++;//將當前塊和前一塊異或保存到shared_mem[] prev_location = cur_location >> 1;//cur_location右移1位區分從當前塊到當前塊的轉跳
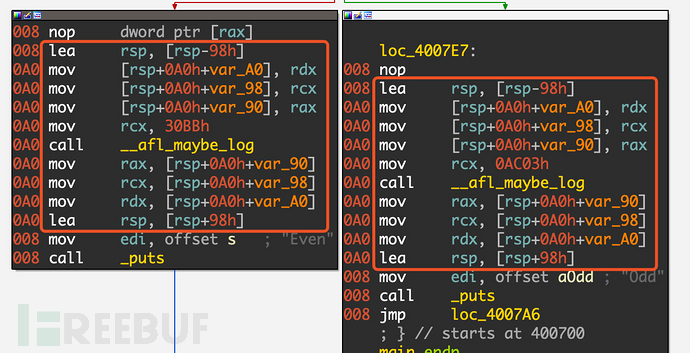
實際插入的匯編代碼,如下圖所示,首先保存各種寄存器的值并設置ecx/rcx,然后調用__afl_maybe_log,這個方法的內容相當復雜,這里就不展開講了,但其主要功能就和上面的偽代碼相似,用于記錄覆蓋率,放入一塊共享內存中。
了解了代碼覆蓋率相關的概念后,接下來看看如何計算我們的測試用例對前面測試目標的代碼覆蓋率。
這里需要用到的工具之一是GCOV,它隨gcc一起發布,所以不需要再單獨安裝,和afl-gcc插樁編譯的原理一樣,gcc編譯時生成插樁的程序,用于在執行時生成代碼覆蓋率信息。
另外一個工具是LCOV,它是GCOV的圖形前端,可以收集多個源文件的gcov數據,并創建包含使用覆蓋率信息注釋的源代碼HTML頁面。
最后一個工具是afl-cov,可以快速幫助我們調用前面兩個工具處理來自afl-fuzz測試用例的代碼覆蓋率結果。在ubuntu中可以使用apt-get install afl-cov安裝afl-cov,但這個版本似乎不支持分支覆蓋率統計,所以還是從Github下載最新版本為好,下載完無需安裝直接運行目錄中的Python腳本即可使用:
$ apt-get install lcov $ git clone https://github.com/mrash/afl-cov.git $ ./afl-cov/afl-cov -V afl-cov-0.6.2
還是以Fuzz libtiff為例,計算Fuzzing過程的代碼覆蓋率流程如下:
第一步,使用gcov重新編譯源碼,在CFLAGS中添加"-fprofile-arcs"和"-ftest-coverage"選項,可以在--prefix中重新指定一個新的目錄以免覆蓋之前alf插樁的二進制文件。
$ make clean $ ./configure --prefix=/root/tiff-4.0.10/build-cov CC="gcc" CXX="g++" CFLAGS="-fprofile-arcs -ftest-coverage" --disable-shared $ make $ make install
第二步,執行afl-cov。其中-d選項指定afl-fuzz輸出目錄;—live用于處理一個還在實時更新的AFL目錄,當afl-fuzz停止時,afl-cov將退出;--enable-branch-coverage用于開啟邊緣覆蓋率(分支覆蓋率)統計;-c用于指定源碼目錄;最后一個-e選項用來設置要執行的程序和參數,其中的AFL_FILE和afl中的"@@"類似,會被替換為測試用例,LD_LIBRARY_PATH則用來指定程序的庫文件。
$ cd ~/tiff-4.0.10 $ afl-cov -d ~/syncdir --live --enable-branch-coverage -c . -e "cat AFL_FILE | LD_LIBRARY_PATH=./build-cov/lib ./build-cov/bin/tiff2pdf AFL_FILE"
成功執行的結果如下所示:
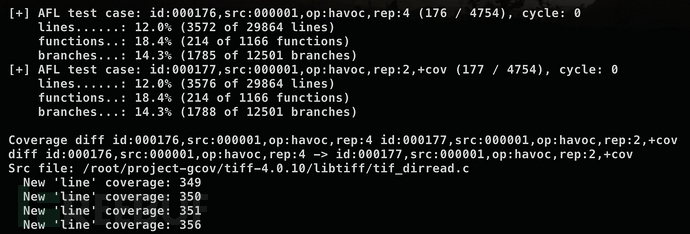
我們可以通過—live選擇,在fuzzer運行的同時計算覆蓋率,也可以在測試結束以后再進行計算,最后會得到一個像下面這樣的html文件。它既提供了概述頁面,顯示各個目錄的覆蓋率;也可以在點擊進入某個目錄查看某個具體文件的覆蓋率。
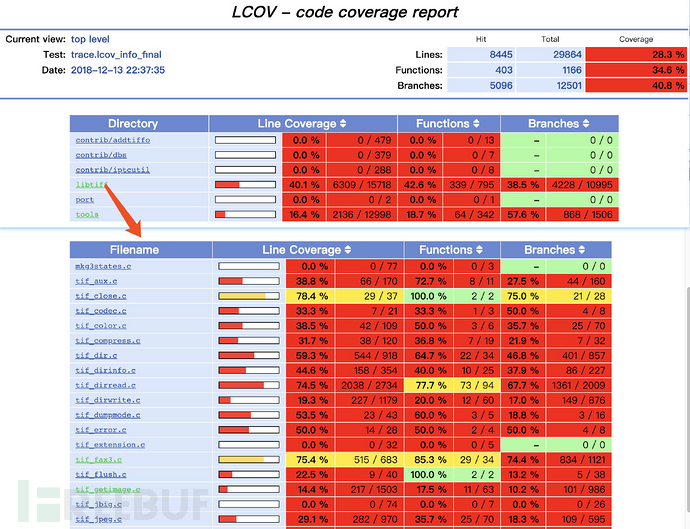
點擊進入每個文件,還有更詳細的數據。每行代碼前的數字代表這行代碼被執行的次數,沒有執行過的代碼會被紅色標注出來。

關于Fuzz結果分析和代碼覆蓋率指的是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





