溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Reddit中怎么統計每個帖子的瀏覽量,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
計數機制
對于計數系統我們主要有四種需求:
帖子瀏覽數必須是實時或者近實時的,而不是每天或者每小時匯總。
同一用戶在短時間內多次訪問帖子,只算一個瀏覽量
顯示的瀏覽量與真實瀏覽量間允許有小百分之幾的誤差
Reddit 是全球訪問量第八的網站,系統要能在生產環境的規模上正常運行,僅允許幾秒的延遲
要全部滿足以上四個需求的困難遠遠比聽上去大的多。為了實時精準計數,我們需要知道某個用戶是否曾經訪問過這篇帖子。想要知道這個信息,我們就要為每篇帖子維護一個訪問用戶的集合,然后在每次計算瀏覽量時檢查集合。一個 naive 的實現方式就是將訪問用戶的集合存儲在內存的 hashMap 中,以帖子 Id 為 key。
這種實現方式對于訪問量低的帖子是可行的,但一旦一個帖子變得流行,訪問量劇增時就很難控制了。甚至有的帖子有超過 100 萬的獨立訪客! 對于這樣的帖子,存儲獨立訪客的 ID 并且頻繁查詢某個用戶是否之前曾訪問過會給內存和 CPU 造成很大的負擔。
因為我們不能提供準確的計數,我們查看了幾種不同的基數估計算法。有兩個符合我們需求的選擇:
一是線性概率計數法,很準確,但當計數集合變大時所需內存會線性變大。
二是基于 HyperLogLog (以下簡稱 HLL )的計數法。 HLL 空間復雜度較低,但是精確度不如線性計數。
下面看下 HLL 會節省多少內存。如果我們需要存儲 100 萬個獨立訪客的 ID, 每個用戶 ID 8 字節長,那么為了存儲一篇帖子的獨立訪客我們就需要 8 M的內存。反之,如果采用 HLL 會顯著減少內存占用。不同的 HLL 實現方式消耗的內存不同。如果采用這篇文章的實現方法,那么存儲 100 萬個 ID 僅需 12 KB,是原來的 0.15%!!
Big Data Counting: How to count a billion distinct objects using only 1.5KB of Memory – High Scalability –這篇文章很好的總結了上面的算法。
許多 HLL 的實現都是結合了上面兩種算法。在集合小的時候采用線性計數,當集合大小到達一定的閾值后切換到 HLL。前者通常被成為 ”稀疏“(sparse) HLL,后者被稱為”稠密“(dense) HLL。這種結合了兩種算法的實現有很大的好處,因為它對于小集合和大集合都能夠保證精確度,同時保證了適度的內存增長。
現在我們已經確定要采用 HLL 算法了,不過在選擇具體的實現時,我們考慮了以下三種不同的實現。因為我們的數據工程團隊使用 Java 和 Scala,所以我們只考慮 Java 和 Scala 的實現。
Twitter 提供的 Algebird,采用 Scala 實現。Algebird 有很好的文檔,但他們對于 sparse 和 dense HLL 的實現細節不是很容易理解。
stream-lib中提供的 HyperLogLog++, 采用 Java 實現。stream-lib 中的代碼文檔齊全,但有些難理解如何合適的使用并且改造的符合我們的需求。
Redis HLL 實現,這是我們最終選擇的。我們認為 Redis 中 HLLs 的實現文檔齊全、容易配置,提供的相關 API 也很容易集成。還有一個好處是,我們可以用一臺專門的服務器部署,從而減輕性能上的壓力。
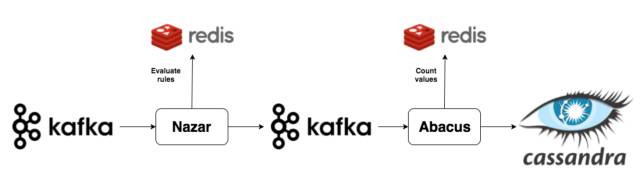
Reddit 的數據管道依賴于 Kafka。當一個用戶訪問了一篇博客,會觸發一個事件,事件會被發送到事件收集服務器,并被持久化在 Kafka 中。
之后,計數系統會依次順序運行兩個組件。在我們的計數系統架構中,***部分是一個 Kafka 的消費者,我們稱之為 Nazar。Nazar 會從 Kafka 中讀取每個事件,并將它通過一系列配置的規則來判斷該事件是否需要被計數。我們取這個名字僅僅是因為 Nazar 是一個眼睛形狀的護身符,而 ”Nazar“ 系統就像眼睛一樣使我們的計數系統遠離不懷好意者的破壞。其中一個我們不將一個事件計算在內的原因就是同一個用戶在很短時間內重復訪問。Nazar 會修改事件,加上個標明是否應該被計數的布爾標識,并將事件重新放入 Kafka。
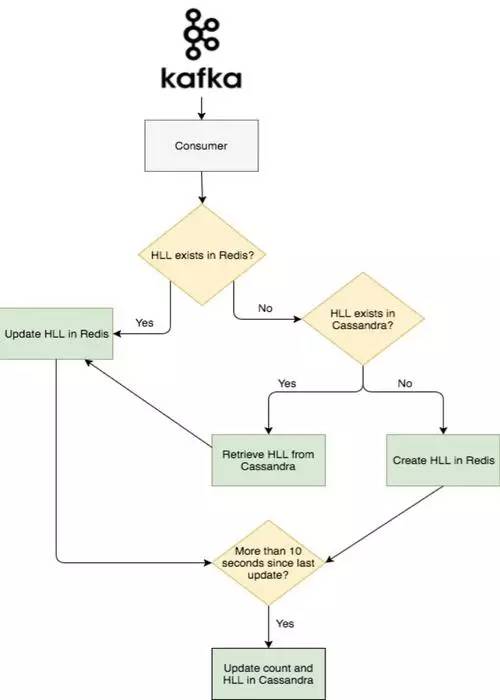
下面就到了系統的第二個部分。我們將第二個 Kafka 的消費者稱作 Abacus,用來進行真正瀏覽量的計算,并且將計算結果顯示在網站或客戶端。Abacus 從 Kafka 中讀取經過 Nazar 處理過的事件,并根據 Nazar 的處理結果決定是跳過這個事件還是將其加入計數。如果 Nazar 中的處理結果是可以加入計數,那么 Abacus 首先會檢查這個事件所關聯的帖子在 Redis 中是否已經存在了一個 HLL 計數器。如果已經存在,Abacus 會給 Redis 發送個 PFADD 的請求。如果不存在,那么 Abacus 會給 Cassandra 集群發送個請求(Cassandra 用來持久化 HLL 計數器和 計數值的),然后向 Redis 發送 SET 請求。這通常會發生在網友訪問較老帖子的時候,這時該帖子的計數器很可能已經在 Redis 中過期了。
為了存儲存在 Redis 中的計數器過期的老帖子的瀏覽量。Abacus 會周期性的將 Redis 中全部的 HLL 和 每篇帖子的瀏覽量寫入到 Cassandra 集群中。為了避免集群過載,我們以 10 秒為周期批量寫入。
下圖是事件流的大致流程:
看完上述內容,你們對Reddit中怎么統計每個帖子的瀏覽量有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





