溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
MySQL中如何利用索引,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
一、前言
在MySQL中進行SQL優化的時候,經常會在一些情況下,對MySQL能否利用索引有一些迷惑。
譬如:
1、MySQL 在遇到范圍查詢條件的時候就停止匹配了,那么到底是哪些范圍條件?
2、MySQL 在LIKE進行模糊匹配的時候又是如何利用索引的呢?
3、MySQL 到底在怎么樣的情況下能夠利用索引進行排序?
今天,我將會用一個模型,把這些問題都一一解答,讓你對MySQL索引的使用不再畏懼。
二、知識補充
key_len
EXPLAIN執行計劃中有一列 key_len 用于表示本次查詢中,所選擇的索引長度有多少字節,通常我們可借此判斷聯合索引有多少列被選擇了。
在這里 key_len 大小的計算規則是:
一般地,key_len 等于索引列類型字節長度,例如int類型為4 bytes,bigint為8 bytes;
如果是字符串類型,還需要同時考慮字符集因素,例如:CHAR(30) UTF8則key_len至少是90 bytes;
若該列類型定義時允許NULL,其key_len還需要再加 1 bytes;
若該列類型為變長類型,例如 VARCHAR(TEXT\BLOB不允許整列創建索引,如果創建部分索引也被視為動態列類型),其key_len還需要再加 2 bytes;
三、哪些條件能用到索引
首先非常感謝登博,給了我一個很好的啟發,我通過他的文章,然后結合自己的理解,制作出了這幅圖
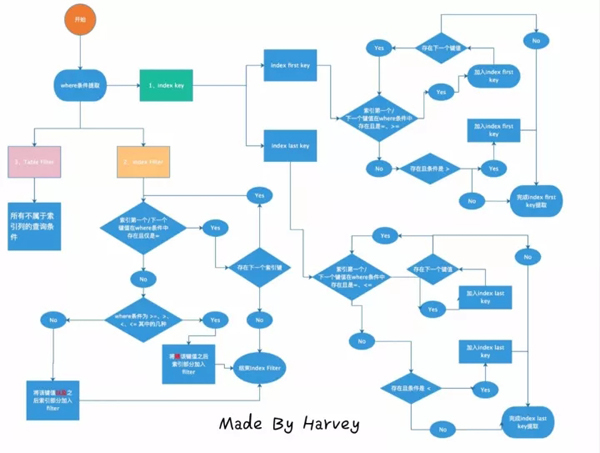
乍一看,是不是很暈,不急,我們慢慢來看
圖中一共分了三個部分:
1、Index Key :MySQL是用來確定掃描的數據范圍,實際就是可以利用到的MySQL索引部分,體現在Key Length。
2、Index Filter:MySQL用來確定哪些數據是可以用索引去過濾,在啟用ICP后,可以用上索引的部分。
3、Table Filter:MySQL無法用索引過濾,回表取回行數據后,到server層進行數據過濾。
我們細細展開。
Index Key
Index Key是用來確定MySQL的一個掃描范圍,分為上邊界和下邊界。
MySQL利用=、>=、> 來確定下邊界(first key),利用最左原則,首先判斷***個索引鍵值在where條件中是否存在,如果存在,則判斷比較符號,如果為(=,>=)中的一種,加入下邊界的界定,然后繼續判斷下一個索引鍵,如果存在且是(>),則將該鍵值加入到下邊界的界定,停止匹配下一個索引鍵;如果不存在,直接停止下邊界匹配。
exp: idx_c1_c2_c3(c1,c2,c3) where c1>=1 and c2>2 and c3=1 --> first key (c1,c2) --> c1為 '>=' ,加入下邊界界定,繼續匹配下一個 -->c2 為 '>',加入下邊界界定,停止匹配
上邊界(last key)和下邊界(first key)類似,首先判斷是否是否是(=,<=)中的一種,如果是,加入界定,繼續下一個索引鍵值匹配,如果是(<),加入界定,停止匹配
exp: idx_c1_c2_c3(c1,c2,c3) where c1<=1 and c2=2 and c3<3 --> first key (c1,c2,c3) --> c1為 '<=',加入上邊界界定,繼續匹配下一個 --> c2為 '='加入上邊界界定,繼續匹配下一個 --> c3 為 '<',加入上邊界界定,停止匹配
注:這里簡單的記憶是,如果比較符號中包含'='號,'>='也是包含'=',那么該索引鍵是可以被利用的,可以繼續匹配后面的索引鍵值;如果不存在'=',也就是'>','<',這兩個,后面的索引鍵值就無法匹配了。同時,上下邊界是不可以混用的,哪個邊界能利用索引的的鍵值多,就是最終能夠利用索引鍵值的個數。
Index Filter
字面理解就是可以用索引去過濾。也就是字段在索引鍵值中,但是無法用去確定Index Key的部分。
exp: idex_c1_c2_c3 where c1>=1 and c2<=2 and c3 =1 index key --> c1 index filter--> c2 c3
這里為什么index key 只是c1呢?因為c2 是用來確定上邊界的,但是上邊界的c1沒有出現(<=,=),而下邊界中,c1是>=,c2沒有出現,因此index key 只有c1字段。c2,c3 都出現在索引中,被當做index filter.
Table Filter
無法利用索引完成過濾,就只能用table filter。此時引擎層會將行數據返回到server層,然后server層進行table filter。
四、Between 和Like 的處理
那么如果查詢中存在between 和like,MySQL是如何進行處理的呢?
Between
where c1 between 'a' and 'b' 等價于 where c1>='a' and c1 <='b',所以進行相應的替換,然后帶入上層模型,確定上下邊界即可
Like
首先需要確認的是%不能是最在最左側,where c1 like '%a' 這樣的查詢是無法利用索引的,因為索引的匹配需要符合最左前綴原則
where c1 like 'a%' 其實等價于 where c1>='a' and c1<'b' 大家可以仔細思考下。
五、索引的排序
在數據庫中,如果無法利用索引完成排序,隨著過濾數據的數據量的上升,排序的成本會越來越大,即使是采用了limit,但是數據庫是會選擇將結果集進行全部排序,再取排序后的limit 記錄,而且MySQL 針對可以用索引完成排序的limit 有優化,更能減少成本。
Make sure it uses index It is very important to have ORDER BY with LIMIT executed without scanning and sorting full result set, so it is important for it to use index – in this case index range scan will be started and query execution stopped as soon as soon as required amount of rows generated.
CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c1` int(11) NOT NULL DEFAULT '0', `c2` int(11) NOT NULL DEFAULT '0', `c3` int(11) NOT NULL DEFAULT '0', `c4` int(11) NOT NULL DEFAULT '0', `c5` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_c1_c2_c3` (`c1`,`c2`,`c3`) ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 select * from t1; +----+----+----+----+----+----+ | id | c1 | c2 | c3 | c4 | c5 | +----+----+----+----+----+----+ | 1 | 3 | 3 | 2 | 0 | 0 | | 2 | 2 | 4 | 5 | 0 | 0 | | 3 | 3 | 2 | 4 | 0 | 0 | | 4 | 1 | 3 | 2 | 0 | 0 | | 5 | 1 | 3 | 3 | 0 | 0 | | 6 | 2 | 3 | 5 | 0 | 0 | | 7 | 3 | 2 | 6 | 0 | 0 | +----+----+----+----+----+----+ 7 rows in set (0.00 sec) select c1,c2,c3 from t1; +----+----+----+ | c1 | c2 | c3 | +----+----+----+ | 1 | 3 | 2 | | 1 | 3 | 3 | | 2 | 3 | 5 | | 2 | 4 | 5 | | 3 | 2 | 4 | | 3 | 2 | 6 | | 3 | 3 | 2 | +----+----+----+ 7 rows in set (0.00 sec)
存在一張表,c1,c2,c3上面有索引,select c1,c2,c3 from t1; 查詢走的是索引全掃描,因此呈現的數據相當于在沒有索引的情況下select c1,c2,c3 from t1 order by c1,c2,c3; 的結果
因此,索引的有序性規則是怎么樣的呢?
c1=3 —> c2 有序,c3 無序
c1=3,c2=2 — > c3 有序
c1 in(1,2) —> c2 無序 ,c3 無序
有個小規律,idx_c1_c2_c3,那么如何確定某個字段是有序的呢?c1 在索引的最前面,肯定是有序的,c2在第二個位置,只有在c1 ***確定一個值的時候,c2才是有序的,如果c1有多個值,那么c2 將不一定有序,同理,c3也是類似
關于MySQL中如何利用索引問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





