溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據庫連接池泄露后的思考是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
早上作為能效平臺系統的使用高峰期,系統負載通常比其它時間段更大一些,某個時間段會有大量用戶登錄。當天系統開始有用戶報障,發布系統線上無法構建發布,然后后續有用戶不能登錄系統,系統發生假死,當然系統不是真的宕機,而是所有和數據庫有關的連接都被阻塞,隨后查看日志發現有大量報錯。
和數據庫連接池相關:
Caused by: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30002ms.
可以看出上面的報錯和數據庫連接有關,大量超時。通過對線上debug日志的分析,也驗證了數據庫連接池被大量消耗。
[DEBUG] c.z.h.p.HikariPool: HikariPool-1 - Timeout failure stats (total=20, active=20, idle=0, waiting=13)
這是開始大量報錯前的日志。我們可以看到此時HikariPool連接池已經無法獲取連接了,active=20表示被獲取正在被使用的數據庫連接。waiting表示當前正在排隊獲取連接的請求數量。可以看出,已經有相當多的請求處于掛起狀態。
所以當時我們的解決辦法是調整數據庫連接池大小,開始初步認為是,高峰時期,我們設置的連接池數量大小,不足以支撐早高峰的連接數量導致的。
jdbc.connection.timeout=30000 jdbc.max.lifetime=1800000 jdbc.maximum.poolsize=200 jdbc.minimum.idle=10 jdbc.idle.timeout=60000 jdbc.readonly=false
我們將將數據庫連接池的數量調整到了200。
2.1事務濫用的后果
及時將配置調整成了200,服務重啟也恢復了正常,但是我仍然認為系統存在連接泄露的風險,我試圖從日志表現出的行為里尋找蛛絲馬跡。我在訪問日志看到每次在系統崩潰前,其實都有人在做構建,而且構建經常點擊沒反應,我當時添加的構建debug日志也顯示了這一點。我開始懷疑是構建造成的連接泄露。
在這里我簡單說下構建代碼處的邏輯
用戶觸發構建
將job加入增量job緩存,用于更新job狀態
jenkinsClient調用jenkins的api,開始構建
將構建信息寫入數據庫(jobname,version)
我開始觀察自己寫的代碼,可是看了多遍,我也發現不了這段代碼和數據庫連接有啥關系,大多數人包括當時自己來說,數據庫連接的泄露,大多數情況應該是服務和數據庫連接的過程中發生了阻塞,導致連接泄露。但是現在來看,很容易能發現問題所在,看當時的代碼:
@Transactional(rollbackFor = Exception.class) public void build(BuildHistoryReq buildHistoryReq) { //1.封裝操作 //2.調用jenkins Api //3.數據庫更新寫入 }這就是當時的代碼入口,當然代碼處沒有這么簡單。可以看到我在方法入口就加上了Transactional注解,這里的意思其實就是發生錯誤,拋出異常時,數據庫回滾。
問題就出現在了這里,當有用戶點擊構建時,請求剛進入build方法時,就會從數據庫連接獲取一個連接。可是此時,程序并沒有和數據庫相關的操作,如果此時代碼在步驟1或者2處出現io或者網絡阻塞,就會導致,事務無法提交,連接也就會一直被該請求占用。而再大的連接池也會被耗費殆盡。從而造成系統崩潰。
2.2事務注解的正確用法
通常情況下作為非業務部門,沒有涉及到核心的業務,像支付,訂單,庫存相關的操作時,事務在可讀層面并沒有特別高的要求。通常也只涉及到,多表操作同時更新時,保證數據一致性,要么同時成功要么同時失敗。而使用
@Transactional(rollbackFor = Exception.class)
足以。
而上述代碼該如何改進呢??
首先分析有沒有需要使用事務的必要。在步驟3中,數據操作,看代碼后發現只有對一張表的操作,同時和其它操作沒有相關性。而且本身屬于最后一個步驟。所以在此代碼中完全沒有必要使用,刪除注解即可。
當然如果步驟3操作數據庫是多表操作,具有強相關性,數據一致,我們可以這樣做。將和步驟3無關的步驟分開,變成兩個方法,那么在1,2處發生阻塞也不會影響到數據庫連接。
public void build(BuildHistoryReq buildHistoryReq) { //1.封裝操作 //2.調用jenkins Api update**(XX); } @Transactional(rollbackFor = Exception.class) public void update**(XX xx) { //3.數據庫更新寫入 }這里需要注意,注解事務的用法,方法必須是公開調用的。
當時找到數據連接池泄露的原因后,我第一步就是去掉了事務,然后加上了一些日志,這時我已經能確定代碼在jenkinsclient處出現了問題,但是仍然不確定問題出在了哪,我只能加上一些日志,同時通過監控繼續觀察。
果然在hotfix的第二天還是出現了我預料中的事情,構建發布仍然有問題,當然此時其它功能是不受影響了。我觀察日志發現構建開始并在該處阻塞
jenkinsClient.startBuild(jobName, params);
隨后我觀察了項目監控。觀察線程情況,發現大量http-nio的線程阻塞了,而這個線程和httpclient相關。
java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007067027e8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at org.apache.http.pool.AbstractConnPool.getPoolEntryBlocking(AbstractConnPool.java:379) at org.apache.http.pool.AbstractConnPool.access$200(AbstractConnPool.java:69) at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:245) - locked <0x00000007824713a0> (a org.apache.http.pool.AbstractConnPool$2) at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:193)
隨后我跟進源碼查看了AbstractConnPool類的379行

可以看到線程走到379行執行了this.condition.await()后進入無限期的等待,所以此時如果沒有線程執行this.condition.signal()就會導致該線程一直處于waiting狀態,而前端也會遲遲收不到相應,導致請求timeout。
我們再分析下源碼,看看什么情況下會導致線程跑到該處:
/** * 獲取http連接,從名稱也能看出該方法會造成阻塞 */ private E getPoolEntryBlocking( final T route, final Object state, final long timeout, final TimeUnit timeUnit, final Future<E> future) throws IOException, InterruptedException, TimeoutException { Date deadline = null; if (timeout > 0) { deadline = new Date (System.currentTimeMillis() + timeUnit.toMillis(timeout)); } this.lock.lock(); try { final RouteSpecificPool<T, C, E> pool = getPool(route); E entry; for (;;) { Asserts.check(!this.isShutDown, "Connection pool shut down"); for (;;) { entry = pool.getFree(state); if (entry == null) { break; } if (entry.isExpired(System.currentTimeMillis())) { entry.close(); } if (entry.isClosed()) { this.available.remove(entry); pool.free(entry, false); } else { break; } } if (entry != null) { this.available.remove(entry); this.leased.add(entry); onReuse(entry); return entry; } // New connection is needed final int maxPerRoute = getMax(route); // Shrink the pool prior to allocating a new connection final int excess = Math.max(0, pool.getAllocatedCount() + 1 - maxPerRoute); if (excess > 0) { for (int i = 0; i < excess; i++) { final E lastUsed = pool.getLastUsed(); if (lastUsed == null) { break; } lastUsed.close(); this.available.remove(lastUsed); pool.remove(lastUsed); } } if (pool.getAllocatedCount() < maxPerRoute) { final int totalUsed = this.leased.size(); final int freeCapacity = Math.max(this.maxTotal - totalUsed, 0); if (freeCapacity > 0) { final int totalAvailable = this.available.size(); if (totalAvailable > freeCapacity - 1) { if (!this.available.isEmpty()) { final E lastUsed = this.available.removeLast(); lastUsed.close(); final RouteSpecificPool<T, C, E> otherpool = getPool(lastUsed.getRoute()); otherpool.remove(lastUsed); } } final C conn = this.connFactory.create(route); entry = pool.add(conn); this.leased.add(entry); return entry; } } boolean success = false; try { if (future.isCancelled()) { throw new InterruptedException("Operation interrupted"); } pool.queue(future); this.pending.add(future); if (deadline != null) { success = this.condition.awaitUntil(deadline); } else { this.condition.await(); success = true; } if (future.isCancelled()) { throw new InterruptedException("Operation interrupted"); } } finally { // In case of 'success', we were woken up by the // connection pool and should now have a connection // waiting for us, or else we're shutting down. // Just continue in the loop, both cases are checked. pool.unqueue(future); this.pending.remove(future); } // check for spurious wakeup vs. timeout if (!success && (deadline != null && deadline.getTime() <= System.currentTimeMillis())) { break; } } throw new TimeoutException("Timeout waiting for connection"); } finally { this.lock.unlock(); } }從源碼我們可以看出有幾處必要條件才會導致線程會無限期等待:
timeout=0 也就是說沒有給默認值,導致: deadline = null
pool.getAllocatedCount() < maxPerRoute 判斷是否已經到達了該路由(host地址)的最大連接數。
其實整體邏輯就是,從池里獲取連接,如果有就直接返回,沒有,判斷當前請求出去的路由有沒有到達該路由的最大值,如果達到了,就進行等待。如果timeout為0就會進行無限期等待。
而這些值我本身也沒有做任何設置,我當時的第一想法就是,給http請求設置超時時間。也就是給每個client設置必要的參數
1.jenkinsClient分配超時時間
public HttpClientBuilder clientBuilder() { HttpClientBuilder httpClientBuilder = HttpClientBuilder.create(); RequestConfig.Builder builder = RequestConfig.custom(); //該參數對應AbstractConnecPool getPoolEntryBlocking方法的timeout builder.setConnectionRequestTimeout(5 * 1000); //數據傳輸的超時時間 builder.setSocketTimeout(20 * 1000); //該參數為,服務和jenkins連接的時間(通常連接的時間都很短,可以設置小點) builder.setConnectTimeout(5 * 1000); httpClientBuilder.setDefaultRequestConfig(builder.build()); return httpClientBuilder; }2.構建JenkinsClient和更新使用的JenkinsClient分離
其實我已經嘗試用池化的思想來解決該問題了。
詭異bug(同一個JenkinsClient,調用不同的api,有的api會阻塞,有的調用仍然正常)
但hotfix的第二天,又出現了一個詭異的bug:
構建可以,但是無法同步job的狀態。這里出現這個問題的原因在于我將構建和更新兩個過程使用的jenkinsClient分離成兩個,所以這個過程相互獨立,互不影響,所以,更新的client出了問題但是構建的client仍然能正常使用。
但是更新過程的JenkinsClient出現的問題讓我百思不得其解。我們先看看更新狀態過程會使用到的api(接口)
//獲取對應的job 1 JobWithDetails job = client.get(UrlUtils.toJobBaseUrl(folder, jobName), JobWithDetails.class); //獲取job構建的pipeline流水 2 client.get("/job/" + EncodingUtils.encode(jobName) + "/" + version + "/wfapi/describe", PipelineStep.class); //獲取對應job某次build的詳情 3 client.get(url, BuildWithDetails.class);bug問題1:為什么全量更新job和增量更新job使用的是同一個JenkinsClient,但是全量更新仍然正常獲取值,而增量更新job狀態的線程確出現阻塞超時(超時是因為前面我設置了timeout,使得請求不會一直阻塞下去)。
要回答這個問題,就要回到線程的相關問題了,
this.condition.wait()會導致當前線程阻塞,并不會影響到另外線程。而更新使用了兩個線程。所以這個問題也比較好回答。
bug問題2:為什么同一個線程(增量更新job線程)調用不同api,有的成功,而有的會阻塞:
解決這個問題,我們還是得回到AbstractConnPool中的方法getPoolEntryBlocking()來看:
if (pool.getAllocatedCount() < maxPerRoute) { }當前請求的路由如果已經達到最大值了就會阻塞等待。那么同一個jenkinsclient,按理來說不可能會出現不同的路由。所以同一個client要么都能訪問,要么都會阻塞,怎么會出現有的能訪問有的會阻塞。為了尋求問題的答案,我翻閱了JenkinsClient的源碼,結合日志,發現服務每次阻塞的方法是:
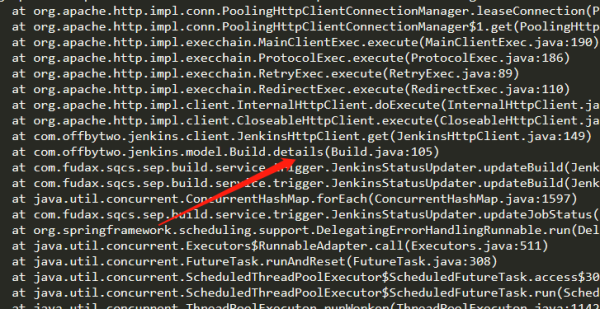
不管多少次,每次都會完美的在該地方阻塞:對應上面的api 3:
//獲取對應job某次build的詳情 3 client.get(url, BuildWithDetails.class);
這個url和其它兩個api拿到的路由都有區別:可以跟隨我一起看源碼:
public class Build extends BaseModel { private int number; private int queueId; private String url; }我們可以看到url是屬于Build的屬性,并非client我們設置的值,當然有人會覺得該值可能是通過將配置的url設置過來的。我們可以接著看,哪些方法可能會給build設置url,三個構造函數,一個set方法都可以,如果我們繼續只看源碼仍然很難找到問題所在,所以這時候我開始啟動服務debug;
發現了問題在哪:
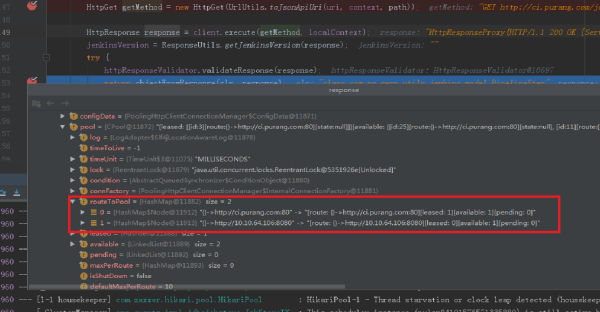
可以看出調用jenkins的這個api出現了兩個router,也可以看出這個url是jenkins返回的,查閱資料可以看到,jenkins系統設置時可以設置這個url。
所以這個bug也能很好的解釋了,對于httpclient來說,每個router默認可以最多兩個連接。雖然是同一個調用api采用的是同一個jenkinsClient,但是卻維護了兩個router,一個是從配置中獲取,一個是jenkins返回的,這個是配置不一致導致的。
JenkinsClient分配連接數:
public HttpClientBuilder clientBuilder() { HttpClientBuilder httpClientBuilder = HttpClientBuilder.create(); RequestConfig.Builder builder = RequestConfig.custom(); builder.setConnectionRequestTimeout(5 * 1000); builder.setSocketTimeout(20 * 1000); builder.setConnectTimeout(5 * 1000); httpClientBuilder.setDefaultRequestConfig(builder.build()); //每個路由最多有10個連接(默認2個) httpClientBuilder.setMaxConnPerRoute(10); //設置連接池最大連接數 httpClientBuilder.setMaxConnTotal(20); return httpClientBuilder; }給JenkinsClient添加健康檢查,并手動更新不能用的Client
@Slf4j public class JenkinsClientManager implements Runnable { private volatile boolean flag = true; private final JenkinsClientProvider jenkinsClientProvider; public JenkinsClientManager(JenkinsClientProvider jenkinsClientProvider) { this.jenkinsClientProvider = jenkinsClientProvider; } @Override public void run() { while (flag) { try { checkJenkinsHealth(); //每30秒檢查一次 Thread.sleep(30_000); } catch (Exception e) { log.warn("check health error:{}", e.getMessage()); } } } public void checkJenkinsHealth() { log.debug("check jenkins client health start"); //獲取client是否可用 available = isAvailable(..) if (!available || !queryAvailable) { //更新client jenkinsClientProvider.retrieveJenkinsClient(); } } private boolean isAvailable(Set<Map.Entry<String, JenkinsClient>> entries) { boolean available = true; for (Map.Entry<String, JenkinsClient> entry : entries) { boolean running = entry.getValue().isRunning(); if (!running) { log.debug("jenkins running error"); available = false; } } return available; } @PostConstruct public void start() { TaskSchedulerConfig.getExecutor().execute(this); } }采用池化技術解決client高可用和重復利用問題
雖然我手動寫了一個JenkinsClientManager每30秒來維護一次client,但是這種手工的方式并不好:
每30秒維護一次,若是在期間發生問題,那么只能干等
無法動態的根據系統需要,動態構建新的client,也就是無法滿足高并發下的使用問題
無法配置
目前我們都知道各種池化技術:線程池、數據庫連接池、redis連接池。
筆者在實現jenkinsClient pool之前,參考了線程池、數據庫連接池的實現、發現其底層實現較為復雜、redis的連接池技術相對來說容易看懂和學習、所以采用了和jedis一樣的實現方式來實現JenkinsClient的連接池
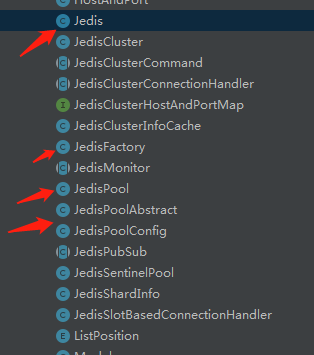
這是jedis的類結構目錄,其實重點在我標記的這5個類。
jedis本身也是采用的commons-pool2提供的池技術實現的,接下來我會簡單介紹一下該工具提供的池化技術。
JenkinsClient連接池應該要具備哪些功能??
動態創建JenkinsClient
使用完的Client放回池中
回收長期不用和不可用的Client
能夠根據需要配置一定數量的Client
對于提到的這些功能,我將通過commons-pool2包來實現
PooledObjectFactory:該接口管理著bean的生命周期(An interface defining life-cycle methods for instances to be served by an)
makeObject 方法創建一個可以入池的實例,也就是我們需要用的Client由該方法創建
destroyObject 方法可以銷毀不可用或者過期的對象
validateObject 方法對實例進行驗證,在每次創建完實例后,都會調用該方法,同時也會以一定的頻率進行健康檢查(頻率timeBetweenEvictionRunsMillis)
GenericObjectPool:實例都會放入該池中進行管理:
//所有的可用連接 private final Map<IdentityWrapper<T>, PooledObject<T>> allObjects = new ConcurrentHashMap<>(); //空閑的可用連接 private final LinkedBlockingDeque<PooledObject<T>> idleObjects; //獲取可用連接 T borrowObject() throws Exception, NoSuchElementException, IllegalStateException; //資源釋放(將連接放回連接池) void returnObject(T obj) throws Exception;
配置(BaseObjectPoolConfig,但是我們繼承GenericObjectPoolConfig,該類給出了大量的默認值)
鏈接池中最大連接數,默認為8 maxTotal #鏈接池中最大空閑的連接數,默認也為8 maxIdle #連接池中最少空閑的連接數,默認為0 minIdle #連接空閑的最小時間,達到此值后空閑連接將可能會被移除。默認為1000L*60L*30L minEvictableIdleTimeMillis #連接空閑的最小時間,達到此值后空閑鏈接將會被移除,且保留minIdle個空閑連接數。默認為-1 softMinEvictableIdleTimeMillis #當連接池資源耗盡時,等待時間,超出則拋異常,默認為-1即永不超時 maxWaitMillis #當這個值為true的時候,maxWaitMillis參數才能生效。為false的時候,當連接池沒資源,則立馬拋異常。默認為true blockWhenExhausted #空閑鏈接檢測線程檢測的周期,毫秒數。如果為負值,表示不運行檢測線程。默認為-1. timeBetweenEvictionRunsMillis #在每次空閑連接回收器線程(如果有)運行時檢查的連接數量,默認為3 numTestsPerEvictionRun #默認false,create的時候檢測是有有效,如果無效則從連接池中移除,并嘗試獲取繼續獲取 testOnCreate #默認false,borrow的時候檢測是有有效,如果無效則從連接池中移除,并嘗試獲取繼續獲取 testOnBorrow #默認false,return的時候檢測是有有效,如果無效則從連接池中移除,并嘗試獲取繼續獲取 testOnReturn #默認false,在evictor線程里頭,當evictionPolicy.evict方法返回false時,而且testWhileIdle為true的時候則檢測是否有效,如果無效則移除 testWhileIdle
了解了這些我們對于需要開發的連接池就很輕松了:
實現PooledObjectFactory(JenkinsFactory)該工廠類就是負責JenkinsClient的生命周期
自定義連接池Pool,通過組合的方式引入框架的連接池GenericObjectPool,當然我們也可以用繼承的方式來實現(組合優先于繼承)
連接池寫完,目前也只是在測試環境運行,還在觀察階段
有個特別的問題也需要指出來,該問題是筆者在開發時沒有注意的問題,也是此次線上產生問題的原因
筆者將原來更新頻率從15s調整到了10s,問題就暴露出來了,對于1個job,可能會拉出上百個build,每次會調用3個api接口,如果每次有十個job,每次更新會在10秒內完成,隨著job增加,和構建歷史增加(雖然有設置保留多少版本,但是api還是會拉出很奇怪的歷史build),會超量發出大量http請求。所以我在代碼層面也做了改動,每次只更新每個job的前5個最新的build,這樣下來,請求量會降低很多
List<Build> buildList = builds.stream().sorted(Comparator.comparing(Build::getNumber).reversed()).limit(5).collect(toList());
by陳朗:
整體來講,還是筆者技術有限,解決問題時繞了很多彎,花了大量時間研究源碼。我也總結了以下幾點
對于連接、鎖等這些可能會阻塞的場景,都需要給出超時設置
資源消耗型,需要有池化的思想,提高資源利用率,保證系統穩定
基礎很重要,需要持續不斷的學習,這樣解決問題才能深入底層,找出問題所在,而不是浮于表面
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





