溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關MySQL的覆蓋索引與回表是怎樣的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
兩大類索引
使用的存儲引擎:MySQL5.7 InnoDB
聚簇索引
* 如果表設置了主鍵,則主鍵就是聚簇索引 * 如果表沒有主鍵,則會默認第一個NOT NULL,且唯一(UNIQUE)的列作為聚簇索引 * 以上都沒有,則會默認創建一個隱藏的row_id作為聚簇索引
InnoDB的聚簇索引的葉子節點存儲的是行記錄(其實是頁結構,一個頁包含多行數據),InnoDB必須要有至少一個聚簇索引。
由此可見,使用聚簇索引查詢會很快,因為可以直接定位到行記錄。
普通索引
普通索引也叫二級索引,除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引葉子節點存儲的是主鍵(聚簇索引)的值,而MyISAM的普通索引存儲的是記錄指針。
示例
建表
mysql> create table user( -> id int(10) auto_increment, -> name varchar(30), -> age tinyint(4), -> primary key (id), -> index idx_age (age) -> )engine=innodb charset=utf8mb4;
id 字段是聚簇索引,age 字段是普通索引(二級索引)
填充數據
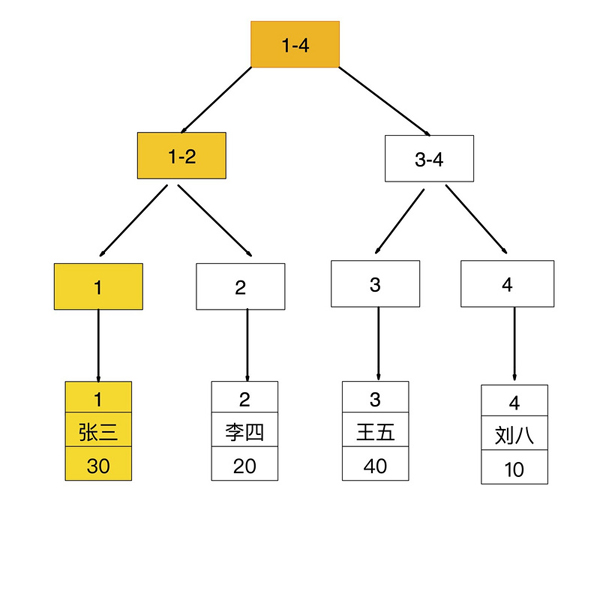
insert into user(name,age) values('張三',30); insert into user(name,age) values('李四',20); insert into user(name,age) values('王五',40); insert into user(name,age) values('劉八',10); mysql> select * from user; +----+--------+------+ | id | name | age | +----+--------+------+ | 1 | 張三 | 30 | | 2 | 李四 | 20 | | 3 | 王五 | 40 | | 4 | 劉八 | 10 | +----+--------+------+索引存儲結構
id 是主鍵,所以是聚簇索引,其葉子節點存儲的是對應行記錄的數據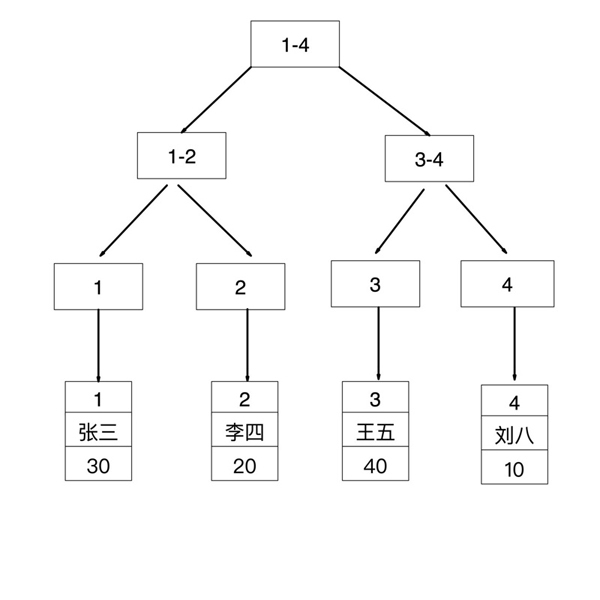
聚簇索引(ClusteredIndex)
age 是普通索引(二級索引),非聚簇索引,其葉子節點存儲的是聚簇索引的的值
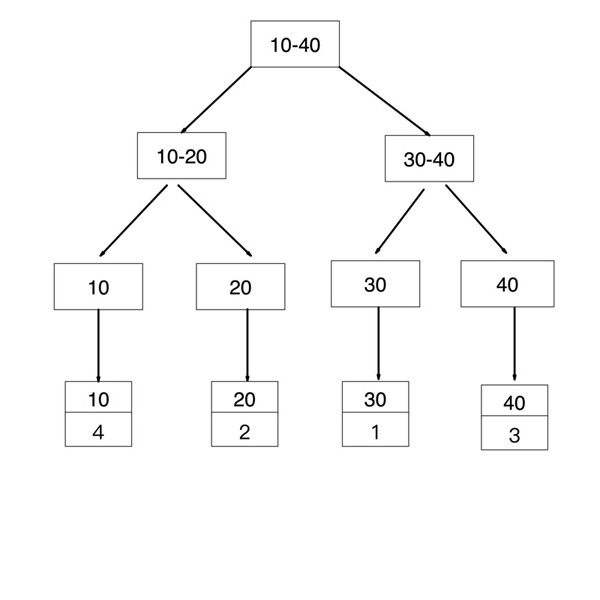
普通索引(secondaryIndex)
如果查詢條件為主鍵(聚簇索引),則只需掃描一次B+樹即可通過聚簇索引定位到要查找的行記錄數據。
如:select * from user where id = 1;
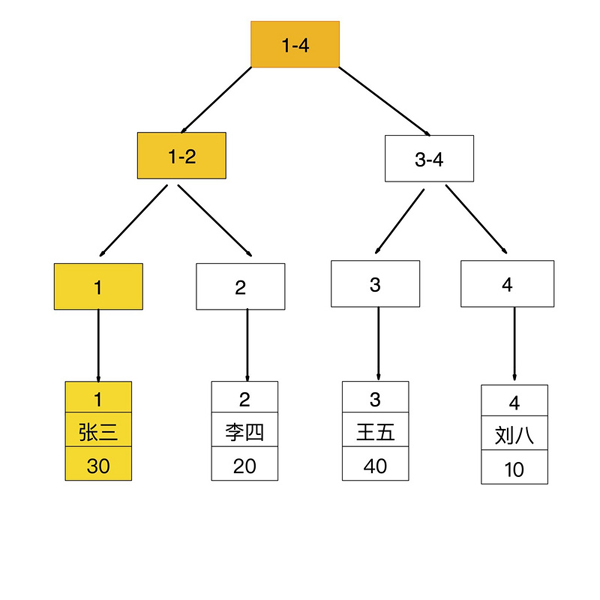
聚簇索引查找過程
如果查詢條件為普通索引(非聚簇索引),需要掃描兩次B+樹,第一次掃描通過普通索引定位到聚簇索引的值,然后第二次掃描通過聚簇索引的值定位到要查找的行記錄數據。
如:select * from user where age = 30;
1. 先通過普通索引 age=30 定位到主鍵值 id=1 2. 再通過聚集索引 id=1 定位到行記錄數據
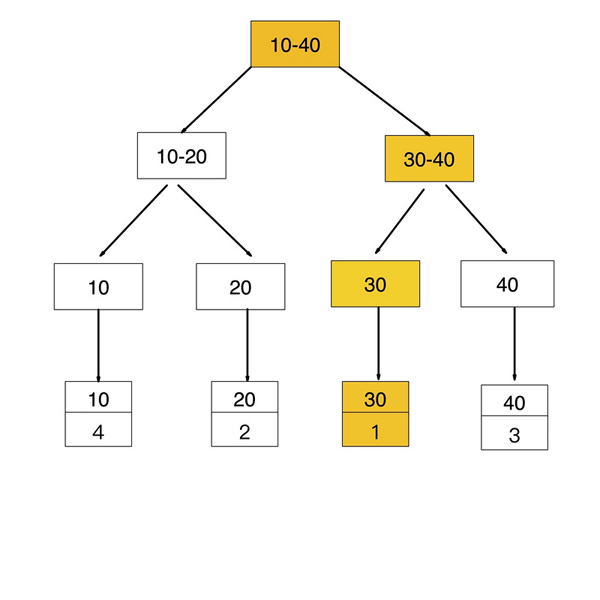
普通索引查找過程第一步
普通索引查找過程第二步
回表查詢
先通過普通索引的值定位聚簇索引值,再通過聚簇索引的值定位行記錄數據,需要掃描兩次索引B+樹,它的性能較掃一遍索引樹更低。
索引覆蓋
只需要在一棵索引樹上就能獲取SQL所需的所有列數據,無需回表,速度更快。
例如:select id,age from user where age = 10;
如何實現覆蓋索引
常見的方法是:將被查詢的字段,建立到聯合索引里去。
1、如實現:select id,age from user where age = 10;
explain分析:因為age是普通索引,使用到了age索引,通過一次掃描B+樹即可查詢到相應的結果,這樣就實現了覆蓋索引

2、實現:select id,age,name from user where age = 10;
explain分析:age是普通索引,但name列不在索引樹上,所以通過age索引在查詢到id和age的值后,需要進行回表再查詢name的值。此時的Extra列的NULL表示進行了回表查詢

為了實現索引覆蓋,需要建組合索引idx_age_name(age,name)
drop index idx_age on user; create index idx_age_name on user(`age`,`name`);
explain分析:此時字段age和name是組合索引idx_age_name,查詢的字段id、age、name的值剛剛都在索引樹上,只需掃描一次組合索引B+樹即可,這就是實現了索引覆蓋,此時的Extra字段為Using index表示使用了索引覆蓋。

哪些場景適合使用索引覆蓋來優化SQL
全表count查詢優化
mysql> create table user( -> id int(10) auto_increment, -> name varchar(30), -> age tinyint(4), -> primary key (id), -> )engine=innodb charset=utf8mb4;
例如:select count(age) from user;

使用索引覆蓋優化:創建age字段索引
create index idx_age on user(age);

列查詢回表優化
前文在描述索引覆蓋使用的例子就是
例如:select id,age,name from user where age = 10
使用索引覆蓋:建組合索引idx_age_name(age,name)即可
分頁查詢
例如:select id,age,name from user order by age limit 100,2;
因為name字段不是索引,所以在分頁查詢需要進行回表查詢,此時Extra為Using filesort文件排序,查詢性能低下。

使用索引覆蓋:建組合索引idx_age_name(age,name)

看完上述內容,你們對MySQL的覆蓋索引與回表是怎樣的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





