溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Kafka中時間輪TimingWheel的示例分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
Kafka中存在大量的延遲操作,比如延遲生產、延遲拉取以及延遲刪除等。Kafka并沒有使用JDK自帶的Timer或者DelayQueue來實現延遲的功能,而是基于時間輪自定義了一個用于實現延遲功能的定時器(SystemTimer)。JDK的Timer和DelayQueue插入和刪除操作的平均時間復雜度為O(nlog(n)),并不能滿足Kafka的高性能要求,而基于時間輪可以將插入和刪除操作的時間復雜度都降為O(1)。時間輪的應用并非Kafka獨有,其應用場景還有很多,在Netty、Akka、Quartz、Zookeeper等組件中都存在時間輪的蹤影。
參考下圖,Kafka中的時間輪(TimingWheel)是一個存儲定時任務的環形隊列,底層采用數組實現,數組中的每個元素可以存放一個定時任務列表(TimerTaskList)。TimerTaskList是一個環形的雙向鏈表,鏈表中的每一項表示的都是定時任務項(TimerTaskEntry),其中封裝了真正的定時任務TimerTask。
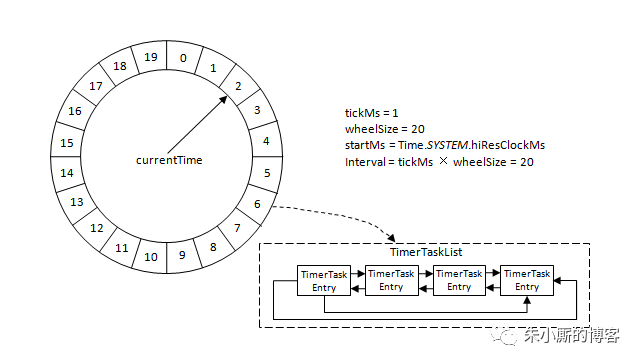
時間輪由多個時間格組成,每個時間格代表當前時間輪的基本時間跨度(tickMs)。時間輪的時間格個數是固定的,可用wheelSize來表示,那么整個時間輪的總體時間跨度(interval)可以通過公式 tickMs × wheelSize計算得出。時間輪還有一個表盤指針(currentTime),用來表示時間輪當前所處的時間,currentTime是tickMs的整數倍。currentTime可以將整個時間輪劃分為到期部分和未到期部分,currentTime當前指向的時間格也屬于到期部分,表示剛好到期,需要處理此時間格所對應的TimerTaskList的所有任務。
若時間輪的tickMs=1ms,wheelSize=20,那么可以計算得出interval為20ms。初始情況下表盤指針currentTime指向時間格0,此時有一個定時為2ms的任務插入進來會存放到時間格為2的TimerTaskList中。隨著時間的不斷推移,指針currentTime不斷向前推進,過了2ms之后,當到達時間格2時,就需要將時間格2所對應的TimeTaskList中的任務做相應的到期操作。
此時若又有一個定時為8ms的任務插入進來,則會存放到時間格10中,currentTime再過8ms后會指向時間格10。如果同時有一個定時為19ms的任務插入進來怎么辦?新來的TimerTaskEntry會復用原來的TimerTaskList,所以它會插入到原本已經到期的時間格1中。總之,整個時間輪的總體跨度是不變的,隨著指針currentTime的不斷推進,當前時間輪所能處理的時間段也在不斷后移,總體時間范圍在currentTime和currentTime+interval之間。
如果此時有個定時為350ms的任務該如何處理?直接擴充wheelSize的大小么?Kafka中不乏幾萬甚至幾十萬毫秒的定時任務,這個wheelSize的擴充沒有底線,就算將所有的定時任務的到期時間都設定一個上限,比如100萬毫秒,那么這個wheelSize為100萬毫秒的時間輪不僅占用很大的內存空間,而且效率也會拉低。Kafka為此引入了層級時間輪的概念,當任務的到期時間超過了當前時間輪所表示的時間范圍時,就會嘗試添加到上層時間輪中。
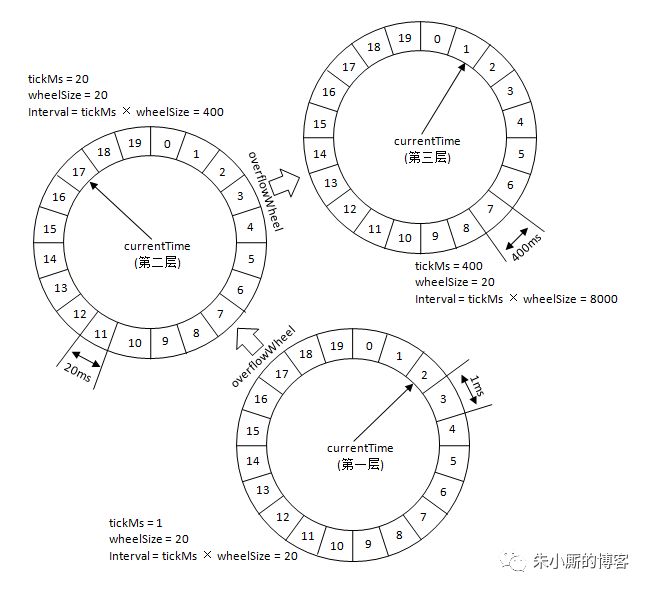
參考上圖,復用之前的案例,***層的時間輪tickMs=1ms, wheelSize=20, interval=20ms。第二層的時間輪的tickMs為***層時間輪的interval,即為20ms。每一層時間輪的wheelSize是固定的,都是20,那么第二層的時間輪的總體時間跨度interval為400ms。以此類推,這個400ms也是第三層的tickMs的大小,第三層的時間輪的總體時間跨度為8000ms。
對于之前所說的350ms的定時任務,顯然***層時間輪不能滿足條件,所以就升級到第二層時間輪中,最終被插入到第二層時間輪中時間格17所對應的TimerTaskList中。如果此時又有一個定時為450ms的任務,那么顯然第二層時間輪也無法滿足條件,所以又升級到第三層時間輪中,最終被插入到第三層時間輪中時間格1的TimerTaskList中。注意到在到期時間在[400ms,800ms)區間的多個任務(比如446ms、455ms以及473ms的定時任務)都會被放入到第三層時間輪的時間格1中,時間格1對應的TimerTaskList的超時時間為400ms。
隨著時間的流逝,當次TimerTaskList到期之時,原本定時為450ms的任務還剩下50ms的時間,還不能執行這個任務的到期操作。這里就有一個時間輪降級的操作,會將這個剩余時間為50ms的定時任務重新提交到層級時間輪中,此時***層時間輪的總體時間跨度不夠,而第二層足夠,所以該任務被放到第二層時間輪到期時間為[40ms,60ms)的時間格中。再經歷了40ms之后,此時這個任務又被“察覺”到,不過還剩余10ms,還是不能立即執行到期操作。所以還要再有一次時間輪的降級,此任務被添加到***層時間輪到期時間為[10ms,11ms)的時間格中,之后再經歷10ms后,此任務真正到期,最終執行相應的到期操作。
設計,其本源于生活。我們常見的鐘表就是一種具有三層結構的時間輪,***層時間輪tickMs=1ms, wheelSize=60,interval=1min,此為秒鐘;第二層tickMs=1min,wheelSize=60,interval=1hour,此為分鐘;第三層tickMs=1hour,wheelSize為12,interval為12hours,此為時鐘。
在Kafka中***層時間輪的參數同上面的案例一樣:tickMs=1ms, wheelSize=20, interval=20ms,各個層級的wheelSize也固定為20,所以各個層級的tickMs和interval也可以相應的推算出來。Kafka在具體實現時間輪TimingWheel時還有一些小細節:
TimingWheel在創建的時候以當前系統時間為***層時間輪的起始時間(startMs),這里的當前系統時間并沒有簡單的調用System.currentTimeMillis(),而是調用了Time.SYSTEM.hiResClockMs,這是因為currentTimeMillis()方法的時間精度依賴于操作系統的具體實現,有些操作系統下并不能達到毫秒級的精度,而Time.SYSTEM.hiResClockMs實質上是采用了System.nanoTime()/1_000_000來將精度調整到毫秒級。也有其他的某些騷操作可以實現毫秒級的精度,但是筆者并不推薦,System.nanoTime()/1_000_000是最有效的方法。(如對此有想法,可在留言區探討。)
TimingWheel中的每個雙向環形鏈表TimerTaskList都會有一個哨兵節點(sentinel),引入哨兵節點可以簡化邊界條件。哨兵節點也稱為啞元節點(dummy node),它是一個附加的鏈表節點,該節點作為***個節點,它的值域中并不存儲任何東西,只是為了操作的方便而引入的。如果一個鏈表有哨兵節點的話,那么線性表的***個元素應該是鏈表的第二個節點。
除了***層時間輪,其余高層時間輪的起始時間(startMs)都設置為創建此層時間輪時前面***輪的currentTime。每一層的currentTime都必須是tickMs的整數倍,如果不滿足則會將currentTime修剪為tickMs的整數倍,以此與時間輪中的時間格的到期時間范圍對應起來。修剪方法為:currentTime = startMs - (startMs % tickMs)。currentTime會隨著時間推移而推薦,但是不會改變為tickMs的整數倍的既定事實。若某一時刻的時間為timeMs,那么此時時間輪的currentTime = timeMs - (timeMs % tickMs),時間每推進一次,每個層級的時間輪的currentTime都會依據此公式推進。
Kafka中的定時器只需持有TimingWheel的第一層時間輪的引用,并不會直接持有其他高層的時間輪,但是每一層時間輪都會有一個引用(overflowWheel)指向更高一層的應用,以此層級調用而可以實現定時器間接持有各個層級時間輪的引用。
關于時間輪的細節就描述到這里,各個組件中時間輪的實現大同小異。讀者讀到這里是否會好奇文中一直描述的一個情景——“隨著時間的流逝”或者“隨著時間的推移”,那么在Kafka中到底是怎么推進時間的呢?類似采用JDK中的scheduleAtFixedRate來每秒推進時間輪?顯然這樣并不合理,TimingWheel也失去了大部分意義。
Kafka中的定時器借助了JDK中的DelayQueue來協助推進時間輪。具體做法是對于每個使用到的TimerTaskList都會加入到DelayQueue中,“每個使用到的TimerTaskList”特指有非哨兵節點的定時任務項TimerTaskEntry的TimerTaskList。DelayQueue會根據TimerTaskList對應的超時時間expiration來排序,最短expiration的TimerTaskList會被排在DelayQueue的隊頭。Kafka中會有一個線程來獲取DelayQueue中的到期的任務列表,有意思的是這個線程所對應的名稱叫做“ExpiredOperationReaper”,可以直譯為“過期操作收割機”,和“SkimpyOffsetMap”有的一拼。當“收割機”線程獲取到DelayQueue中的超時的任務列表TimerTaskList之后,既可以根據TimerTaskList的expiration來推進時間輪的時間,也可以就獲取到的TimerTaskList執行相應的操作,對立面的TimerTaskEntry該執行過期操作的就執行過期操作,該降級時間輪的就降級時間輪。
讀者讀到這里或許又非常的困惑,文章開頭明確指明的DelayQueue不適合Kafka這種高性能要求的定時任務,為何這里還要引入DelayQueue呢?注意對于定時任務項TimerTaskEntry插入和刪除操作而言,TimingWheel時間復雜度為O(1),性能高出DelayQueue很多,如果直接將TimerTaskEntry插入DelayQueue中,那么性能顯然難以支撐。就算我們根據一定的規則將若干TimerTaskEntry劃分到TimerTaskList這個組中,然后再將TimerTaskList插入到DelayQueue中,試想下如果這個TimerTaskList中又要多添加一個TimerTaskEntry該如何處理?對于DelayQueue而言,這類操作顯然變得力不從心。
分析到這里可以發現,Kafka中的TimingWheel專門用來執行插入和刪除TimerTaskEntry的操作,而DelayQueue專門負責時間推進的任務。再試想一下,DelayQueue中的***個超時任務列表的expiration為200ms,第二個超時任務為840ms,這里獲取DelayQueue的隊頭只需要O(1)的時間復雜度。如果采用每秒定時推進,那么獲取到***個超時的任務列表時執行的200次推進中有199次屬于“空推進”,而獲取到第二個超時任務時有需要執行639次“空推進”,這樣會無故空耗機器的性能資源,這里采用DelayQueue來輔助以少量空間換時間,從而做到了“精準推進”。Kafka中的定時器真可謂是“知人善用”,用TimingWheel做最擅長的任務添加和刪除操作,而用DelayQueue做最擅長的時間推進工作,相輔相成。
看完上述內容,你們掌握Kafka中時間輪TimingWheel的示例分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





