溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關時序數據庫的快速檢索是怎么進行的,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Elasticsearch 是通過 Lucene 的倒排索引技術實現比關系型數據庫更快的過濾。特別是它對多條件的過濾支持非常好,比如年齡在 18 和 30 之間,性別為女性這樣的組合查詢。倒排索引很多地方都有介紹,但是其比關系型數據庫的 b-tree 索引快在哪里?到底為什么快呢?
籠統的來說,b-tree 索引是為寫入優化的索引結構。當我們不需要支持快速的更新的時候,可以用預先排序等方式換取更小的存儲空間,更快的檢索速度等好處,其代價就是更新慢。要進一步深入的化,還是要看一下 Lucene 的倒排索引是怎么構成的。

這里有好幾個概念。我們來看一個實際的例子,假設有如下的數據:
docid | 年齡 | 性別 |
1 | 18 | 女 |
2 | 20 | 女 |
3 | 18 | 男 |
這里每一行是一個 document。每個 document 都有一個 docid。那么給這些 document 建立的倒排索引就是:
年齡
性別
可以看到,倒排索引是 per field 的,一個字段有一個自己的倒排索引。18,20 這些叫做 term,而 [1,3] 就是 posting list。Posting list 就是一個 int 的數組,存儲了所有符合某個 term 的文檔 id。那么什么是 term dictionary 和 term index?
假設我們有很多個 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照這樣的順序排列,找出某個特定的 term 一定很慢,因為 term 沒有排序,需要全部過濾一遍才能找出特定的 term。排序之后就變成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
這樣我們可以用二分查找的方式,比全遍歷更快地找出目標的 term。這個就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盤查找得到目標。但是磁盤的隨機讀操作仍然是非常昂貴的(一次 random access 大概需要 10ms 的時間)。所以盡量少的讀磁盤,有必要把一些數據緩存到內存里。但是整個 term dictionary 本身又太大了,無法完整地放到內存里。于是就有了 term index。term index 有點像一本字典的大的章節表。比如:
A 開頭的 term ……………. Xxx 頁
C 開頭的 term ……………. Xxx 頁
E 開頭的 term ……………. Xxx 頁
如果所有的 term 都是英文字符的話,可能這個 term index 就真的是 26 個英文字符表構成的了。但是實際的情況是,term 未必都是英文字符,term 可以是任意的 byte 數組。而且 26 個英文字符也未必是每一個字符都有均等的 term,比如 x 字符開頭的 term 可能一個都沒有,而 s 開頭的 term 又特別多。實際的 term index 是一棵 trie 樹:
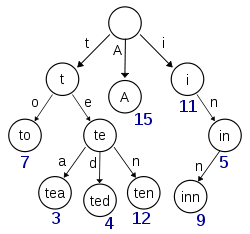
例子是一個包含 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的 trie 樹。這棵樹不會包含所有的 term,它包含的是 term 的一些前綴。通過 term index 可以快速地定位到 term dictionary 的某個 offset,然后從這個位置再往后順序查找。再加上一些壓縮技術(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的幾十分之一,使得用內存緩存整個 term index 變成可能。整體上來說就是這樣的效果。
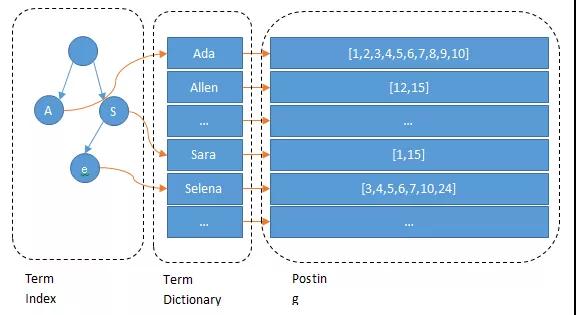
現在我們可以回答“為什么 Elasticsearch/Lucene 檢索可以比 mysql 快了。Mysql 只有 term dictionary 這一層,是以 b-tree 排序的方式存儲在磁盤上的。檢索一個 term 需要若干次的 random access 的磁盤操作。而 Lucene 在 term dictionary 的基礎上添加了 term index 來加速檢索,term index 以樹的形式緩存在內存中。從 term index 查到對應的 term dictionary 的 block 位置之后,再去磁盤上找 term,大大減少了磁盤的 random access 次數。
額外值得一提的兩點是:term index 在內存中是以 FST(finite state transducers)的形式保存的,其特點是非常節省內存。Term dictionary 在磁盤上是以分 block 的方式保存的,一個 block 內部利用公共前綴壓縮,比如都是 Ab 開頭的單詞就可以把 Ab 省去。這樣 term dictionary 可以比 b-tree 更節約磁盤空間。
如何聯合索引查詢?
所以給定查詢過濾條件 age=18 的過程就是先從 term index 找到 18 在 term dictionary 的大概位置,然后再從 term dictionary 里精確地找到 18 這個 term,然后得到一個 posting list 或者一個指向 posting list 位置的指針。然后再查詢 gender= 女 的過程也是類似的。最后得出 age=18 AND gender= 女 就是把兩個 posting list 做一個“與”的合并。
這個理論上的“與”合并的操作可不容易。對于 mysql 來說,如果你給 age 和 gender 兩個字段都建立了索引,查詢的時候只會選擇其中最 selective 的來用,然后另外一個條件是在遍歷行的過程中在內存中計算之后過濾掉。那么要如何才能聯合使用兩個索引呢?有兩種辦法:
使用 skip list 數據結構。同時遍歷 gender 和 age 的 posting list,互相 skip;
使用 bitset 數據結構,對 gender 和 age 兩個 filter 分別求出 bitset,對兩個 bitset 做 AN 操作。
PostgreSQL 從 8.4 版本開始支持通過 bitmap 聯合使用兩個索引,就是利用了 bitset 數據結構來做到的。當然一些商業的關系型數據庫也支持類似的聯合索引的功能。Elasticsearch 支持以上兩種的聯合索引方式,如果查詢的 filter 緩存到了內存中(以 bitset 的形式),那么合并就是兩個 bitset 的 AND。如果查詢的 filter 沒有緩存,那么就用 skip list 的方式去遍歷兩個 on disk 的 posting list。
利用 Skip List 合并
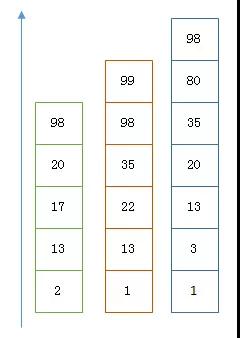
以上是三個 posting list。我們現在需要把它們用 AND 的關系合并,得出 posting list 的交集。首先選擇最短的 posting list,然后從小到大遍歷。遍歷的過程可以跳過一些元素,比如我們遍歷到綠色的 13 的時候,就可以跳過藍色的 3 了,因為 3 比 13 要小。
整個過程如下
Next -> 2 Advance(2) -> 13 Advance(13) -> 13 Already on 13 Advance(13) -> 13 MATCH!!! Next -> 17 Advance(17) -> 22 Advance(22) -> 98 Advance(98) -> 98 Advance(98) -> 98 MATCH!!!
最后得出的交集是 [13,98],所需的時間比完整遍歷三個 posting list 要快得多。但是前提是每個 list 需要指出 Advance 這個操作,快速移動指向的位置。什么樣的 list 可以這樣 Advance 往前做蛙跳?skip list:
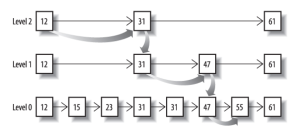
從概念上來說,對于一個很長的 posting list,比如:
[1,3,13,101,105,108,255,256,257]
我們可以把這個 list 分成三個 block:
[1,3,13] [101,105,108] [255,256,257]
然后可以構建出 skip list 的第二層:
[1,101,255]
1,101,255 分別指向自己對應的 block。這樣就可以很快地跨 block 的移動指向位置了。
Lucene 自然會對這個 block 再次進行壓縮。其壓縮方式叫做 Frame Of Reference 編碼。
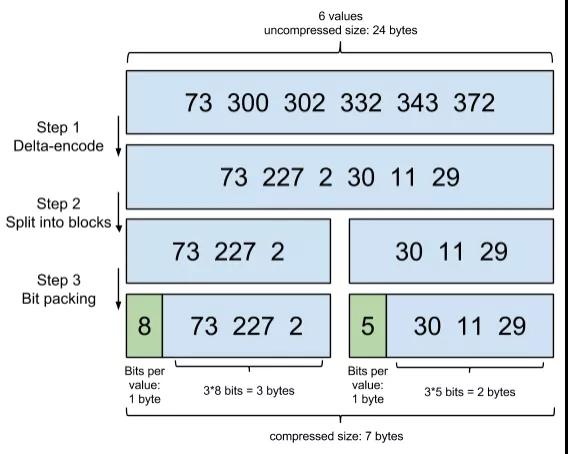
示例如下:考慮到頻繁出現的 term(所謂 low cardinality 的值),比如 gender 里的男或者女。如果有 1 百萬個文檔,那么性別為男的 posting list 里就會有 50 萬個 int 值。用 Frame of Reference 編碼進行壓縮可以極大減少磁盤占用。這個優化對于減少索引尺寸有非常重要的意義。當然 mysql b-tree 里也有一個類似的 posting list 的東西,是未經過這樣壓縮的。
因為這個 Frame of Reference 的編碼是有解壓縮成本的。利用 skip list,除了跳過了遍歷的成本,也跳過了解壓縮這些壓縮過的 block 的過程,從而節省了 cpu。
利用 bitset 合并
Bitset 是一種很直觀的數據結構,對應 posting list 如:
[1,3,4,7,10]
對應的 bitset 就是:
[1,0,1,1,0,0,1,0,0,1]
每個文檔按照文檔 id 排序對應其中的一個 bit。Bitset 自身就有壓縮的特點,其用一個 byte 就可以代表 8 個文檔。所以 100 萬個文檔只需要 12.5 萬個 byte。但是考慮到文檔可能有數十億之多,在內存里保存 bitset 仍然是很奢侈的事情。而且對于個每一個 filter 都要消耗一個 bitset,比如 age=18 緩存起來的話是一個 bitset,18<=age<25 是另外一個 filter 緩存起來也要一個 bitset。
所以秘訣就在于需要有一個數據結構:
可以很壓縮地保存上億個 bit 代表對應的文檔是否匹配 filter;
這個壓縮的 bitset 仍然可以很快地進行 AND 和 OR 的邏輯操作。
Lucene 使用的這個數據結構叫做 Roaring Bitmap。

其壓縮的思路其實很簡單。與其保存 100 個 0,占用 100 個 bit。還不如保存 0 一次,然后聲明這個 0 重復了 100 遍。
這兩種合并使用索引的方式都有其用途。Elasticsearch 對其性能有詳細的對比( https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps )。簡單的結論是:因為 Frame of Reference 編碼是如此 高效,對于簡單的相等條件的過濾緩存成純內存的 bitset 還不如需要訪問磁盤的 skip list 的方式要快。
如何減少文檔數?
一種常見的壓縮存儲時間序列的方式是把多個數據點合并成一行。Opentsdb 支持海量數據的一個絕招就是定期把很多行數據合并成一行,這個過程叫 compaction。類似的 vivdcortext 使用 mysql 存儲的時候,也把一分鐘的很多數據點合并存儲到 mysql 的一行里以減少行數。
這個過程可以示例如下:
12:05:00 | 10 |
12:05:01 | 15 |
12:05:02 | 14 |
12:05:03 | 16
|
合并之后就變成了:
可以看到,行變成了列了。每一列可以代表這一分鐘內一秒的數據。
Elasticsearch 有一個功能可以實現類似的優化效果,那就是 Nested Document。我們可以把一段時間的很多個數據點打包存儲到一個父文檔里,變成其嵌套的子文檔。示例如下:
{timestamp:12:05:01, idc:sz, value1:10,value2:11} {timestamp:12:05:02, idc:sz, value1:9,value2:9} {timestamp:12:05:02, idc:sz, value1:18,value:17}可以打包成:
{ max_timestamp:12:05:02, min_timestamp: 1205:01, idc:sz, records: [ {timestamp:12:05:01, value1:10,value2:11} {timestamp:12:05:02, value1:9,value2:9} {timestamp:12:05:02, value1:18,value:17} ] }這樣可以把數據點公共的維度字段上移到父文檔里,而不用在每個子文檔里重復存儲,從而減少索引的尺寸。
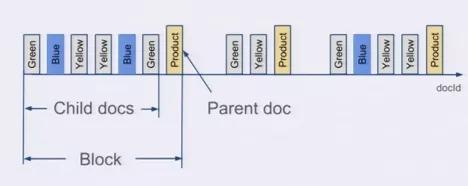
在存儲的時候,無論父文檔還是子文檔,對于 Lucene 來說都是文檔,都會有文檔 Id。但是對于嵌套文檔來說,可以保存起子文檔和父文檔的文檔 id 是連續的,而且父文檔總是最后一個。有這樣一個排序性作為保障,那么有一個所有父文檔的 posting list 就可以跟蹤所有的父子關系。也可以很容易地在父子文檔 id 之間做轉換。把父子關系也理解為一個 filter,那么查詢時檢索的時候不過是又 AND 了另外一個 filter 而已。前面我們已經看到了 Elasticsearch 可以非常高效地處理多 filter 的情況,充分利用底層的索引。
使用了嵌套文檔之后,對于 term 的 posting list 只需要保存父文檔的 doc id 就可以了,可以比保存所有的數據點的 doc id 要少很多。如果我們可以在一個父文檔里塞入 50 個嵌套文檔,那么 posting list 可以變成之前的 1/50。
以上就是時序數據庫的快速檢索是怎么進行的,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





