溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Hadoop的資源管理模塊YAR有什么用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
在之前文章中介紹過hadoop1與hadoop2架構的區別是hadoop2將資源管理功能從MapReduce框架中獨立出來,也就是現在的YARN模塊。
在沒有 YARN 之前,是一個集群一個計算框架。比如:MapReduce 一個集群、Spark 一個集群、HBase 一個集群等。
造成各個集群管理復雜,資源的利用率很低;比如:在某個時間段內 Hadoop 集群忙而Spark 集群閑著,反之亦然,各個集群之間不能共享資源造成集群間資源并不能充分利用。
并且采用"一個框架一個集群"的模式,也需要多個管理員管理這些集群, 進而增加運維成本;而共享集群模式通常需要少數管理員即可完成多個框架的統一管理; 隨著數據量的暴增,跨集群間的數據移動不僅需要花費更長的時間,且硬件成本也會大大增加;而共享集群模式可讓多種框架共享數據和硬件資源,將大大減少數據移動帶來的成本。
解決辦法:
將所有的計算框架運行在一個集群中,共享一個集群的資源,按需分配;Hadoop 需要資源就將資源分配給 Hadoop,Spark 需要資源就將資源分配給 Spark,進而整個集群中的資源利用率就高于多個小集群的資源利用率;
Master/Slave 結構,1 個ResourceManager(RM)對應多個 NodeManager(NM);YARN 由 Client、ResourceManager、NodeManager、ApplicationMaster (AM)組成;Client 向 RM 提交任務、殺死任務等;
AM由對應的應用程序完成;
每個應用程序對應一個 AM,AM向RM申請資源用于在NM上啟動相應的 Task;NM 向 RM通過心跳信息:匯報 NM健康狀況、任務執行狀況、領取任務等;
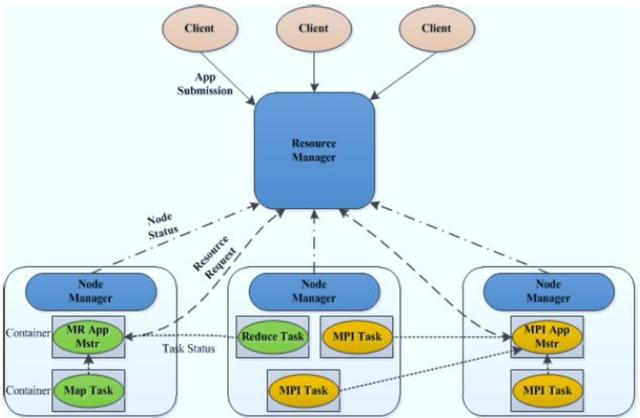
RM:整個集群只有一個,負責集群資源的統一管理和調度
1)處理來自客戶端的請求(啟動/殺死應用程序);
2)啟動/監控 AM;一旦某個 AM 掛了之后,RM 將會在另外一個節點上啟動該 AM;
3)監控 NM,接收 NM的心跳匯報信息并分配任務到 NM去執行;一旦某個 NM掛了,標志下該 NM 上的任務,來告訴對應的 AM 如何處理;
4)負責整個集群的資源分配和調度;
NM:整個集群中有多個,負責單節點資源管理和使用
1)周期性向 RM匯報本節點上的資源使用情況和各個 Container 的運行狀;
2)接收并處理來自 RM 的 Container 啟動/停止的各種命令;
3)處理來自 AM的命令;
4)負責單個節點上的資源管理和任務調度;
AM:每個應用一個,負責應用程序的管理
1)數據切分;
2)為應用程序/作業向 RM 申請資源(Container),并分配給內部任務;
3)與 NM通信以啟動/停止任務;
4)任務監控和容錯(在任務執行失敗時重新為該任務申請資源以重啟任務);
5)處理 RM發過來的命令:殺死 Container、讓 NM重啟等;
Container:對任務運行環境的抽象
1)任務運行資源(節點、內存、CPU);
2)任務啟動命令;
3)任務運行環境;任務是運行在Container中,一個Container中既可以運行AM也可以運行具體的 Map/Reduce/MPI/Spark Task;
1)用戶向 YARN 中提交應用程序/作業,其中包括 ApplicaitonMaster 程序、啟動ApplicationMaster 的命令、用戶程序等;
2)ResourceManager 為作業分配第一個 Container,并與對應的 NodeManager 通信,要求它在這個 Containter 中啟動該作業的 ApplicationMaster;
3 )ApplicationMaster 首 先 向 ResourceManager 注 冊 , 這 樣 用 戶 可 以 直 接 通 過ResourceManager 查詢作業的運行狀態;然后它將為各個任務申請資源并監控任務的運行狀態,直到運行結束。即重復步驟 4-7;
4)ApplicationMaster 采用輪詢的方式通過 RPC 請求向 ResourceManager 申請和領取資源;
5)一旦 ApplicationMaster 申請到資源后,便與對應的 NodeManager 通信,要求它啟動任務;
6)NodeManager 啟動任務;
7)各個任務通過 RPC 協議向 ApplicationMaster 匯報自己的狀態和進度,以讓ApplicaitonMaster 隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務;在作業運行過程中,用戶可隨時通過 RPC 向 ApplicationMaster 查詢作業當前運行狀態;
8)作業完成后,ApplicationMaster 向 ResourceManager 注銷并關閉自己;
ResourceMananger基于 ZooKeeper 實現 HA 避免單點故障;
NodeManager執行失敗后,ResourceManager 將失敗任務告訴對應的 ApplicationMaster;
由 ApplicationMaster 決定如何處理失敗的任務;
ApplicationMaster執行失敗后,由 ResourceManager 負責重啟;
ApplicationMaster 需處理內部任務的容錯問題;
RMAppMaster 會保存已經運行完成的 Task,重啟后無需重新運行。
1、雙層調度框架
1)ResourceManager 將資源分配給 ApplicationMaster;
2)ApplicationMaster 將資源進一步分配給各個 TASK;
2、基于資源預留的調度策略
1)資源不夠時,會為 Task 預留,直到資源充足;描述:當一個 Task 需要 10G 資源時,各個節點都不足 10G,那么就選擇一個節點,但是某個 NodeManager上只有 2G, 那么就在這個 NodeManager上預留, 當這個 NodeManager上釋放其他資源后,會將資源預留給 10G 的作業,直到攢夠 10G 時,啟動 Task;缺點:資源利用率不高,要先攢著,等到 10G 才利用,造成集群的資源利用率低;
2)與"all or nothing"策略不同(Apache Mesos)描述:當一個作業需要 10G 資源時,節點都不足 10G,那就慢慢等,等到某個節點上有 10G 空閑資源時再運行,很可能會導致該 Task 餓死。
“Hadoop的資源管理模塊YAR有什么用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





