溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“HBase的工作原理”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Hadoop中HBase工作的簡要概述
1.引言
HBase是一種高可靠性,高性能,面向列的可擴展分布式存儲系統,它使用HBase技術在廉價的PC服務器上構建大規模結構化存儲集群。 HBase的目標是存儲和處理大量數據,特別是僅使用標準硬件配置即可處理包含數千行和列的大量數據。
與MapReduce的離線批量計算框架不同,HBase是隨機訪問存儲和檢索數據平臺,彌補了HDFS無法隨機訪問數據的缺點。
它適用于實時性要求不高的業務場景-HBase存儲Byte數組,該數組不介意數據類型,從而允許動態,靈活的數據模型。
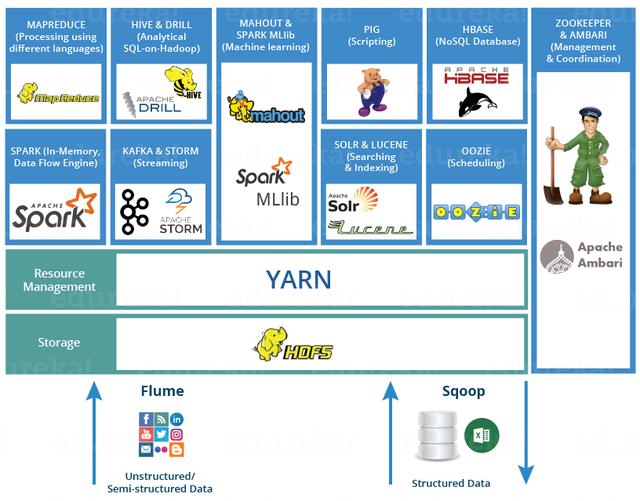
上圖描繪了Hadoop 2.0生態系統的各個層-位于結構化存儲層上的Hbase。
HDFS為HBase提供了高可靠性的低級存儲支持。
MapReduce為HBase提供了高性能的批處理功能。 ZooKeeper為HBase提供穩定的服務和故障轉移機制。 Pig和Hive為數據統計處理的高級語言支持提供了HBase,Sqoop為HDB提供了可用的RDBMS數據導入功能,這使得從傳統數據庫到HBase的業務數據遷移非常方便。
2. HBase架構
2.1設計Idea
HBase是一個分布式數據庫,使用ZooKeeper來管理群集和HDFS作為基礎存儲。
在體系結構級別,它由HMaster(由Zookeeper選擇的領導者)和多個HRegionServers組成。
下圖顯示了基礎架構:
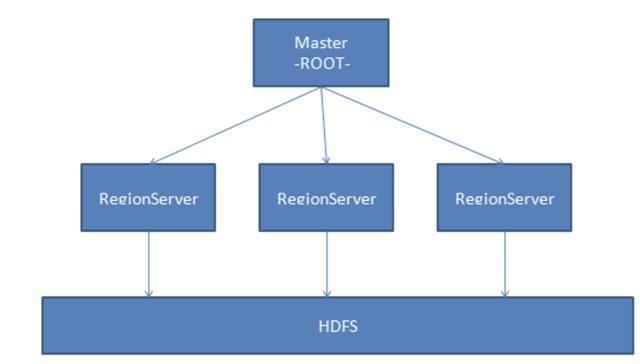
在HBase的概念中,HRegionServer對應于群集中的一個節點,一個HRegionServer負責管理多個HRegion,一個HRegion代表表數據的一部分。
在HBase中,一個表可能需要很多HRegion來存儲數據,并且每個HRegion中的數據都不會雜亂無章。
當HBase管理HRegion時,它將為每個HRegion定義一定范圍的Rowkey。 屬于定義范圍的數據將被移交給特定區域,從而將負載分配給多個節點,從而利用分布和特性的優勢。
同樣,HBase將自動調整區域的位置。 如果HRegionServer過熱,即大量請求落在HRegionServer管理的HRegion上,則HBase會將HRegion移動到相對空閑的其他節點,以確保充分利用群集環境。
2.2基本架構
HBase由HMaster和HRegionServer組成,并且遵循主從服務器體系結構。 HBase將邏輯表分為多個數據塊HRegion,并將它們存儲在HRegionServer中。
HMaster負責管理所有HRegionServer。 它本身不存儲任何數據,而僅存儲數據到HRegionServer的映射(元數據)。
群集中的所有節點均由Zookeeper協調,并處理HBase操作期間可能遇到的各種問題。 HBase的基本架構如下所示:
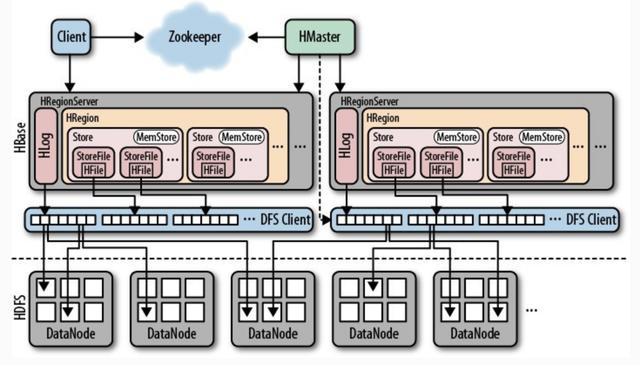
客戶端:使用HBase的RPC機制與HMaster和HRegionServer通信,提交請求并獲得結果。 對于管理操作,客戶端使用HMaster執行RPC。 對于數據讀取和寫入操作,客戶端使用HRegionServer執行RPC。
Zookeeper:通過將集群中每個節點的狀態信息注冊到ZooKeeper,HMaster可以隨時感知每個HRegionServer的健康狀態,還可以避免HMaster的單點故障。
HMaster:管理所有HRegionServer,告訴他們需要維護哪些HRegion,并監視所有HRegionServer的運行狀況。 當新的HRegionServer登錄到HMaster時,HMaster告訴它等待數據分配。 當HRegion死亡時,HMaster將其負責的所有HRegion標記為未分配,然后將它們分配給其他HRegionServer。 HMaster沒有單點問題。 HBase可以啟動多個HMaster。 通過Zookeeper的選舉機制,群集中始終有一個HMaster運行,從而提高了群集的可用性。
HRegion:當表的大小超過預設值時,HBase會自動將表劃分為不同的區域,每個區域都包含表中所有行的子集。 對于用戶來說,每個表都是數據的集合,用主鍵(RowKey)加以區分。 從物理上講,一個表分為多個塊,每個塊都是一個HRegion。 我們使用表名+開始/結束主鍵來區分每個HRegion。 一個HRegion會將一段連續數據保存在一個表中。 完整的表數據存儲在多個HRegions中。
HRegionServer:HBase中的所有數據通常從底層存儲在HDFS中。 用戶可以通過一系列HRegionServer獲得此數據。 通常,群集的一個節點上僅運行一臺HRegionServer,并且每個段的HRegion僅由一個HRegionServer維護。 HRegionServer主要負責響應用戶I / O請求將數據讀取和寫入HDFS文件系統。 它是HBase中的核心模塊。 HRegionServer在內部管理一系列HRegion對象,每個HRegion對應于邏輯表中的連續數據段。 HRegion由多個HStore組成。 每個HStore對應于邏輯表中一個列族的存儲。 可以看出,每個列族都是一個集中式存儲單元。 因此,為了提高操作效率,最好將具有共同I / O特性的列放在一個列系列中。
HStore:它是HBase存儲的核心,它由MemStore和StoreFiles組成。 MemStore是內存緩沖區。用戶寫入的數據將首先放入MemStore。當MemStore已滿時,Flush將是一個StoreFile(底層實現是HFile)。當StoreFile文件的數量增加到某個閾值時,將觸發Compact合并操作,將多個StoreFile合并為一個StoreFile,并在合并過程中執行版本合并和數據刪除操作。因此,可以看出,HBase僅添加數據,并且所有更新和刪除操作都在后續的Compact進程中執行,因此用戶的寫入操作可以在其進入內存后立即返回,從而確保HBaseI /哦當StoreFiles Compact時,它將逐漸形成越來越大的StoreFile。當單個StoreFile的大小超過某個閾值時,將觸發分割操作。同時,當前的HRegion將被拆分為2個HRegion,并且父HRegion將脫機。 HMaster將這兩個子HRegion分配給相應的HRegionServer,以便將原始HRegion的負載壓力分流到這兩個HRegion。
HLog:每個HRegionServer都有一個HLog對象,該對象是實現預寫日志的預寫日志類。 每次用戶將數據寫入MemStore時,它還將數據的副本寫入HLog文件。 定期滾動和刪除HLog文件,并刪除舊文件(已保存到StoreFile的數據)。 當HMaster檢測到HRegionServer被Zookeeper意外終止時,HMaster首先處理舊版HLog文件,分割不同HRegion的HLog數據,將它們放入相應的HRegion目錄中,然后重新分發無效的HRegion。 在加載HRegion的過程中,這些HRegion的HRegionServer將發現需要處理HLog的歷史記錄,因此將Replay HLog中的數據傳輸到MemStore,然后刷新到StoreFiles以完成數據恢復。
2.3 根和元
HBase的所有HRegion元數據都存儲在.META中。 表。 隨著HRegion的增加,.META表中的數據也增加并分裂為多個新的HRegion。
為了找到.META表中每個HRegion的位置,將表中.META表中所有HRegion的元數據存儲在-ROOT-table中,最后,Zookeeper記錄ROOT表的位置信息。
在所有客戶端訪問用戶數據之前,他們需要首先訪問Zookeeper以獲取-ROOT-的位置,然后訪問-ROOT-table以獲取.META表的位置,最后根據以下信息確定用戶數據的位置: META表中的信息,如下所示:該圖顯示。
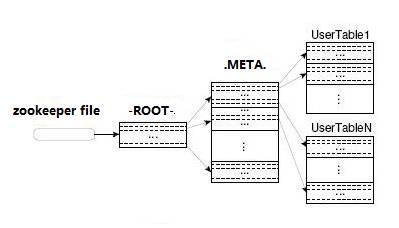
-ROOT表永遠不會拆分。 它只有一個HRegion,這可以確保只需三個跳轉就可以定位任何HRegion。 為了加快訪問速度,.META表的所有區域都保留在內存中。
客戶端緩存查詢的位置信息,并且緩存不會主動失敗。 如果客戶端仍然無法基于緩存的信息訪問數據,則請相關.META表的Region服務器嘗試獲取數據的位置。 如果仍然失敗,請詢問與-ROOT-table關聯的.META表在哪里。
最后,如果先前的信息全部無效,則Zookeeper將HRegion的數據重定位。 因此,如果客戶端上的緩存完全無效,則需要來回六次以獲取正確的HRegion。
3. HBase數據模型
HBase是類似于BigTable的分布式數據庫。 它是稀疏的長期存儲(在HDFS上),多維和排序的映射表。 該表的索引是行關鍵字,列關鍵字和時間戳。 HBase數據是字符串,沒有類型。

將表視為大型映射。 您可以按行鍵,行鍵+時間戳或行鍵+列(列族:列修飾符)查找特定數據。 由于HBase稀疏地存儲數據,因此某些列可以為空。 上表給出了com.cnn.www網站的邏輯存儲邏輯視圖。 表中只有一行數據。
該行的唯一標識符是" com.cnn.www",并且此數據行的每次邏輯修改都有一定的時間。 標記對應于。
該表中有四列:內容:HTML,anchor:cnnsi.com,anchor:my.look.ca,mime:type,每個列都給出了它所屬的列族。
行鍵(RowKey)是表中數據行的唯一標識符,并用作檢索記錄的主鍵。
在HBase中,只有三種方法可以訪問表中的行:通過行鍵進行訪問,給定行鍵的范圍訪問以及全表掃描。
行鍵可以是任何字符串(最大長度為64KB),并按字典順序存儲。 對于經常一起讀取的行,需要仔細設計基本值,以便可以將它們一起存儲。
4. HBase讀寫過程
下圖是HRegionServer數據存儲關系圖。 如上所述,HBase使用MemStore和StoreFile將更新存儲到表中。 數據在更新后首先寫入HLog和MemStore。 MemStore中的數據已排序。
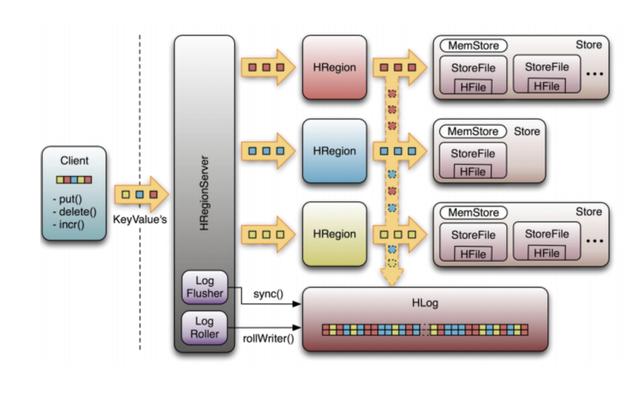
當MemStore累積到某個閾值時,將創建一個新的MemStore,并將舊的MemStore添加到Flush隊列中,并將一個單獨的線程刷新到磁盤上以成為StoreFile。 同時,系統將在Zookeeper中記錄一個CheckPoint,表明該時間之前的數據更改已保留。 當發生意外系統時,MemStore中的數據可能會丟失。
在這種情況下,HLog用于在CheckPoint之后恢復數據。
StoreFile是只讀的,一旦創建便無法修改。 因此,HBase的更新是一項附加操作。 當商店中的StoreFile達到某個閾值時,將執行合并操作,并且將相同密鑰的修改合并以形成一個大型StoreFile。 當StoreFile的大小達到某個閾值時,StoreFile被拆分并分為兩個StoreFiles。
4.1寫操作流程
步驟1:客戶端通過Zookeeper的調度向HRegionServer發送寫數據請求,并將數據寫入HRegion。
步驟2:將數據寫入HRegion的MemStore,直到MemStore達到預設閾值。
步驟3:MemStore中的數據被整理到StoreFile中。
步驟4:隨著StoreFile文件數量的增加,當StoreFile文件數量增加到特定閾值時,將執行Compact合并操作,并將多個StoreFiles合并到一個StoreFile中,并在版本庫中執行版本合并和數據刪除。 同時。
步驟5:StoreFiles通過連續的Compact操作逐漸形成越來越大的StoreFile。
步驟6:在單個StoreFile的大小超過某個閾值之后,將觸發Split操作,將當前的HRegion拆分為兩個新的HRegion。 父HRegion將脫機,新的Split的兩個子HRegion將由HMaster分配給相應的HRegionServer,以便可以將原始HRegion的壓力分流到這兩個HRegion。
4.2讀取操作流程
步驟1:客戶端訪問Zookeeper,找到-ROOT-table,并獲得.META。 表信息。
步驟2:從.META中搜索。 表獲取目標數據的HRegion信息,找到對應的HRegionServer。
步驟3:獲取需要通過HRegionServer查找的數據。
步驟4:HRegionserver的內存分為兩部分:MemStore和BlockCache。 MemStore主要用于寫入數據,而BlockCache主要用于讀取數據。 首先將請求讀取到MemStore以檢查數據,檢查BlockCache檢查,然后檢查StoreFile,然后將讀取結果放入BlockCache。
5. HBase使用場景
半結構化或非結構化數據:對于沒有很好定義或混亂的數據結構字段,很難根據適用于HBase的概念來提取數據。 如果隨著業務增長存儲更多字段,則需要關閉RDBMS來維護更改表結構,并且HBase支持動態添加。
記錄非常稀疏:RDBMS行的多少列是固定的,而空列則浪費存儲空間。 HBase為空的列不會存儲,這樣可以節省空間并提高讀取性能。
多版本數據:根據RowKey和列標識符定位的值可以具有任意數量的版本值(時間戳是不同的),因此將HBase用于需要存儲更改歷史記錄的數據非常方便 。
大量數據:當數據量越來越大時,RDBMS數據庫將無法承受,并且存在讀寫分離策略。 通過一個主機,它負責寫操作,而多個從機則負責讀取操作,服務器成本增加了一倍。 隨著壓力的增加,船長無法承受壓力。 此時,將對庫進行劃分,并且將幾乎不相關的數據分別部署。 某些聯接查詢無法使用,并且需要使用中間層。 隨著數據量的進一步增加,表的記錄變得越來越大,查詢變得非常慢。
因此,有必要例如通過對ID進行模化將表劃分為多個表,以減少單個表的記錄數。 經歷過這些事情的人都知道如何拋棄這個過程。
HBase很簡單,只需將新節點添加到群集,HBase就會自動水平拆分,并且與Hadoop的無縫集成可確保數據可靠性(HDFS)和高性能的海量數據分析(MapReduce)。
6. HBase Map Reduce
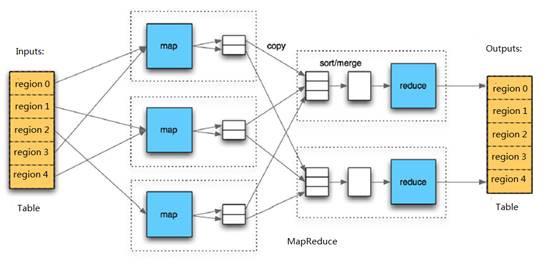
HBase中的Table與Region之間的關系與HDFS中的File與Block之間的關系有些相似。 由于HBase提供了與MapReduce進行交互的API,例如TableInputFormat和TableOutputFormat,因此HBase數據表可以直接用作Hadoop MapReduce的輸入和輸出,這有利于MapReduce應用程序的開發,并且不需要注意HBase的處理。 系統本身的詳細信息。
“HBase的工作原理”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





