溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL分庫分表后總存儲變大了的原因是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1.背景
在完成一個分表項目后,發現分表的數據遷移后,新庫所需的存儲容量遠大于原本兩張表的大小。在做了一番查詢了解后,完成了優化。
回過頭來,需要進一步了解下為什么會出現這樣的情況。
與標題的問題的類似問題還有,為什么表數據內容刪除了而表大小沒有變化。其本質都是一樣的。
要回答這些問題,我們需要從mysql的索引模型談起。
2.InnoDB 的索引模型
在 MySQL 中,索引是在存儲引擎層實現的,所以并沒有統一的索引標準,即不同存儲引擎的索引的工作方式并不一樣。
而即使多個存儲引擎支持同一種類型的索引,其底層的實現也可能不同。由于 InnoDB 存儲引擎在 MySQL 數據庫中使用最為廣泛,所以接下來就以 InnoDB 為例,分析其中的索引模型。
在 InnoDB 中,表都是根據主鍵順序以索引的形式存放的,這種存儲方式的表稱為索引組織表。而InnoDB中,使用了 B+ 樹索引模型,所以數據都是存儲在 B+ 樹中的,每一個索引會對應一顆B+樹。
假設,我們有一個主鍵列為 ID 的表,表中有字段 k,并且在 k 上有索引,建表語句如下
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) NOT NULL,
`name` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k` (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
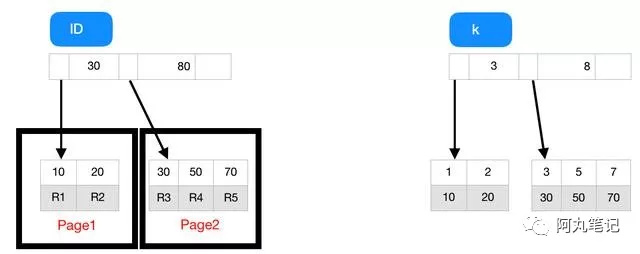
表中 R1~R5 的 (ID,k) 值分別為 (10,1)、(20,2)、(30,3)、(50,5) 和 (70,7),索引id和索引k的B+樹的示例示意圖如下。
根據葉子節點的內容,索引類型分為主鍵索引和非主鍵索引,主鍵索引的葉子節點存的是整行數據R1~R5,非主鍵索引的葉子節點內容是主鍵的值。
從圖中可以看出,基于非主鍵索引的查詢需要多掃描一棵索引樹才能找到對應的數據。提一句題外話,我們在應用中應該盡量使用主鍵查詢。
3.索引維護
B+ 樹為了維護索引有序性,在增刪改數據的時候需要做必要的維護。
假設,我們要刪掉 R4 這個記錄,InnoDB 引擎只會把 R4 這個記錄標記為刪除。如果之后要再插入一個 ID 在 300 和 600 之間的記錄時,可能會復用這個位置。
如果刪掉了一個數據頁上的所有記錄,那么整個數據頁就能被復用了。進一步地,如果我們用 delete 命令把整個表的數據刪除呢?結果就是,這個表相關的所有的數據頁都會被標記為可復用。
但是,無論如何,磁盤文件的大小并不會縮小。
這些被標記為可復用,而并沒有實際被使用的空間,就是一些“存儲空洞”。
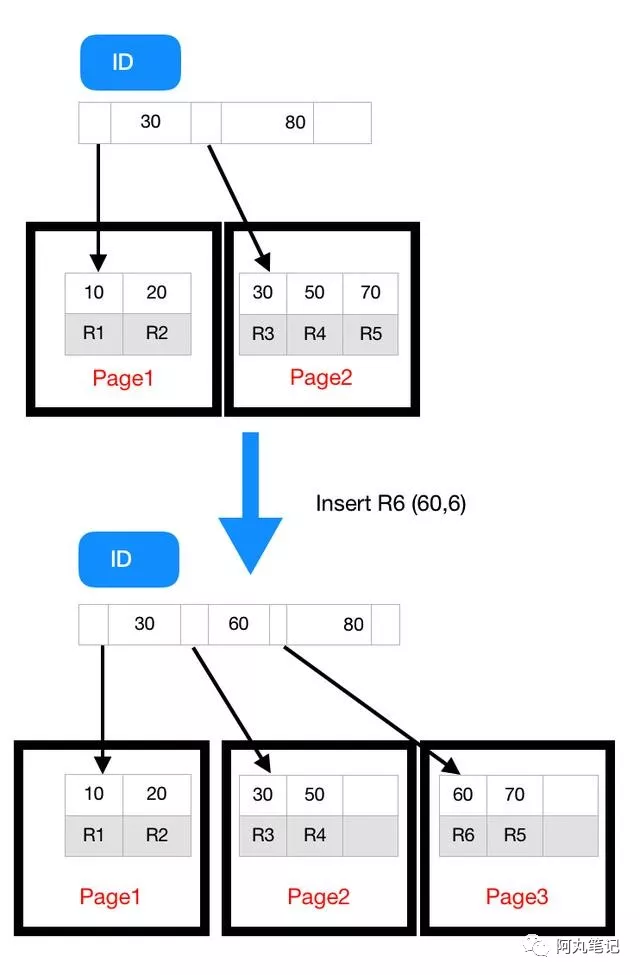
實際上,不止是刪除數據會造成空洞,插入數據也會。
以上圖為例,如果插入新的行 ID 值為 80,則只需要在 R5 的記錄后面插入一個新記錄。
如果新插入的 ID 值為 60,就相對麻煩了,需要邏輯上挪動后面的數據,空出位置。
而更糟的情況是,如果 R5 所在的數據頁已經滿了,根據 B+ 樹的算法,這時候需要申請一個新的數據頁,然后挪動部分數據過去。這個過程稱為頁分裂。在這種情況下,性能自然會受影響。
除了性能外,頁分裂操作還影響數據頁的利用率。原本放在一個頁的數據,現在分到兩個頁中,插入一條記錄竟然使得整體空間利用率降低大約 50%。
可以看到,由于 page 2 滿了,再插入一個 ID 是 60 的數據時,就不得不再申請一個新的頁面 page 3 來保存數據了。
頁分裂完成后,page 2 的末尾就留下了空洞(注意:實際上,可能不止 1 個記錄的位置是空洞)。
另外,更新索引上的值,可以理解為刪除一個舊的值,再插入一個新值。不難理解,這也是會造成空洞的。
因此,大量的增刪改之后的表,都是可能存在很大的“數據空洞”的。
因此,我們就能解釋,為什么分表后的總存儲變大了。
因為分表后,需要從老庫全量同步數據到新庫,數據同步平臺開啟多個線程進行同步,插入各個分表并不是按照遞增的順序插入的,因此,會產生巨量的“數據空洞”,造成存儲空間變大。
如果能夠把這些空洞去掉,就能達到收縮表空間的目的。而重建表就能達到這樣的目的。
4.重建表
如果我們手動重建一張表,可以新建一個與表 A 結構相同的表 B,然后按照主鍵 ID 遞增的順序,把數據一行一行地(就是遞增地)從表 A 里讀出來再插入到表 B 中。由于表 B 是新建的表,所以表 A 主鍵索引上的空洞,在表 B 中就都不存在了。顯然地,表 B 的主鍵索引更緊湊,數據頁的利用率也更高。如果我們把表 B 作為臨時表,數據從表 A 導入表 B 的操作完成后,用表 B 替換 A,從效果上看,就起到了收縮表 A 空間的作用。
這里,你可以使用 alter table A engine=InnoDB 命令來重建表。在 MySQL 5.5 版本之前,這個命令的執行流程跟我們前面描述的差不多,區別只是這個臨時表 B 不需要你自己創建,MySQL 會自動完成轉存數據、交換表名、刪除舊表的操作。顯然,花時間最多的步驟是往臨時表插入數據的過程,如果在這個過程中,有新的數據要寫入到表 A 的話,就會造成數據丟失。因此,在整個 DDL 過程中,表 A 中不能有更新。也就是說,這個 DDL 不是 Online 的。
MySQL 5.6 版本開始引入的 Online DDL,對這個操作流程做了優化。
建立一個臨時文件,掃描表 A 主鍵的所有數據頁;
用數據頁中表 A 的記錄生成 B+ 樹,存儲到臨時文件中;
生成臨時文件的過程中,將所有對 A 的操作記錄在一個日志文件(row log)中;
臨時文件生成后,將日志文件中的操作應用到臨時文件,得到一個邏輯數據上與表 A 相同的數據文件;(應用row log的過程可能又回有頁分裂)
用臨時文件替換表 A 的數據文件。
可以看到,在這個過程中,由于日志文件記錄和重放操作這個功能的存在,這個方案在重建表的過程中,允許對表 A 做增刪改操作。這也就是 Online DDL 名字的來源。
需要補充說明的是,上述的這些重建方法都會掃描原表數據和構建臨時文件。對于很大的表來說,這個操作是很消耗 IO 和 CPU 資源的。因此,如果是線上服務,你要很小心地控制操作時間。
optimize table、analyze table 和 alter table 這三種方式重建表的區別:
從 MySQL 5.6 版本開始,alter table t engine = InnoDB(也就是 recreate)默認的就是上面online DDL 的流程了;
analyze table t 其實不是重建表,只是對表的索引信息做重新統計,沒有修改數據,這個過程中加了 MDL 讀鎖;
optimize table t 等于 recreate+analyze。
“MySQL分庫分表后總存儲變大了的原因是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





