溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL狀態表的優化是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
自打構建數據源集市的技術棧以來,其實整個體系也在不斷的完善,在數據流轉的出口方向我們基本達成了一致,那就是在保證數據準確性和穩定性的基礎上盡可能按照實時的標準去落地數據交付效率,所以數據源集市的目標不是簡單交付數據了事,而是需要對中下游的服務提供強有力的支持,甚至提供數據實時流轉的參考和依據。
目前一張表的數據如果要提供近實時的數據交付標準,一般有以下的幾類策略:
1)基于自增ID的模式,根據數據庫的自增ID可以快速的定位數據的增量位置,基本實現數據的增量同步,當然這種模式的局限性比較大,需要表中含有自增ID字段,對于數據庫的吞吐量也會有潛在瓶頸,同時不適用于基于中間件的集群環境數據實時流轉。
2)基于時間字段同步模式,時間字段的同步是表數據實現增量同步的經典方法,也是和業務緊密結合,但是帶來的潛在風險是可能相關的時間字段有多個,同步定制化程度高,另外單一使用增量模式其實難以完全定位數據,還是需要另外一個維度的支持,比如自增ID等。
如果一張狀態表要實現實時流轉,實時交付,那么面臨的問題其實是比較復雜的。
通常這類狀態表數據量巨大,但很可能沒有基于自增ID的字段(通常是基于業務的ID字段),而基于時間字段基本可行,但是難以快速定位唯一的記錄內容,最緊要的一點是我們通過唯一性定位得到的是變化后的值,變化前的值已經被完全覆蓋,所以對于變化量的定義是比較復雜的。
目前來看,碰到的一些瓶頸問題主要有:
中下游的數據服務提取數據時,盡管數據源是實時更新的,但是后續的數據服務是難以定位增量數據的。通過上述的多個維度都不合適,通常做數據檢查的時候只能無奈使用select count(*) from xxx這種校驗模式,而要解決這個問題最直接的方案就是程序段提供相應的流水日志,如果開發能力較強這個事情比較好落地,而如果業務風險高,這個事情要解決就比較麻煩了。
如下是一種折中的解決方案,在不需要程序修改代碼的前提下,能夠實時提取數據變化并實時更新同步數據狀態,大體的設計思路是基于實時日志服務,在這里是Maxwell.
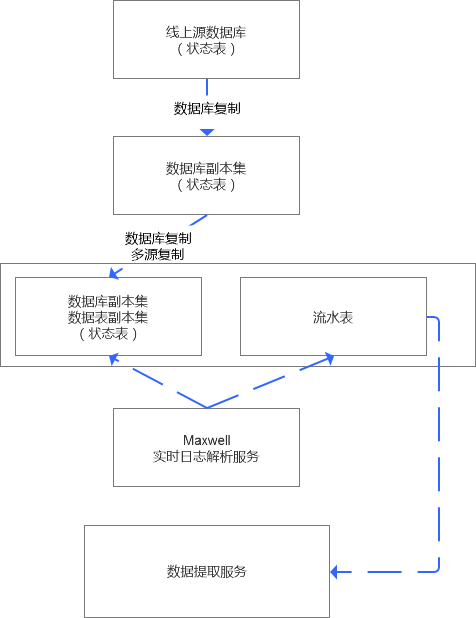
我來簡單解釋下,如果一張狀態表的數據要實時交付,那么數據源集市中我們保證狀態表的數據實時復制是沒有問題的,技術上完全能夠做到,無論是基于庫級別還是過濾到表級別,都是可操作的。
而基于Maxwell的實時日志提取,我們可以從狀態表中解析出表中數據實時變化的內容,我們可以間接實現一個賬單表,對于中下游來說,就是間接把狀態表轉換為流水日志表,從而間接實現的實時流轉和交付。
“MySQL狀態表的優化是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





