溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Prometheus時序數據庫中怎么查詢數據,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Promql
一個Promql表達式可以計算為下面四種類型:
瞬時向量(Instant Vector) - 一組同樣時間戳的時間序列(取自不同的時間序列,例如不同機器同一時間的CPU idle) 區間向量(Range vector) - 一組在一段時間范圍內的時間序列 標量(Scalar) - 一個浮點型的數據值 字符串(String) - 一個簡單的字符串
我們還可以在Promql中使用svm/avg等集合表達式,不過只能用在瞬時向量(Instant Vector)上面。為了闡述Prometheus的聚合計算以及篇幅原因,筆者在本篇文章只詳細分析瞬時向量(Instant Vector)的執行過程。
瞬時向量(Instant Vector)
前面說到,瞬時向量是一組擁有同樣時間戳的時間序列。但是實際過程中,我們對不同Endpoint采樣的時間是不可能精確一致的。所以,Prometheus采取了距離指定時間戳之前最近的數據(Sample)。如下圖所示:
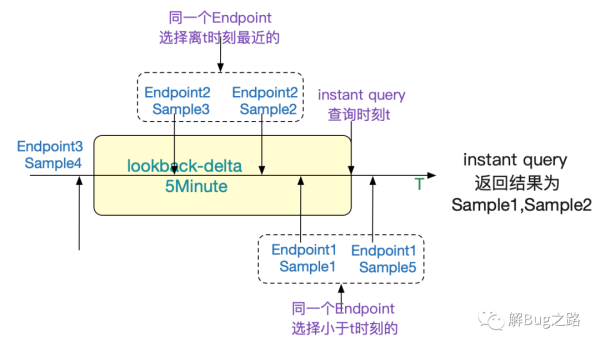
當然,如果是距離當前時間戳1個小時的數據直觀看來肯定不能納入到我們的返回結果里面。
所以Prometheus通過一個指定的時間窗口來過濾數據(通過啟動參數—query.lookback-delta指定,默認5min)。
對一條簡單的Promql進行分析
好了,解釋完Instant Vector概念之后,我們可以著手進行分析了。直接上一條帶有聚合函數的Promql吧。
SUM BY (group) (http_requests{job="api-server",group="production"})首先,對于這種有語法結構的語句肯定是將其Parse一把,構造成AST樹了。調用
promql.ParseExpr
由于Promql較為簡單,所以Prometheus直接采用了LL語法分析。在這里直接給出上述Promql的AST樹結構。
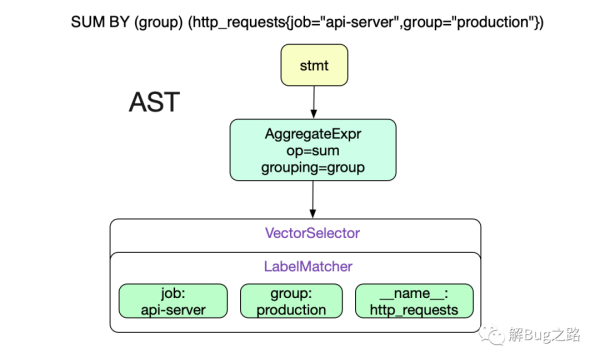
Prometheus對于語法樹的遍歷過程都是通過vistor模式,具體到代碼為:
ast.go vistor設計模式 func Walk(v Visitor, node Node, path []Node) error { var err error if v, err = v.Visit(node, path); v == nil || err != nil { return err } path = append(path, node) for _, e := range Children(node) { if err := Walk(v, e, path); err != nil { return err } } _, err = v.Visit(nil, nil) return err } func (f inspector) Visit(node Node, path []Node) (Visitor, error) { if err := f(node, path); err != nil { return nil, err } return f, nil }通過golang里非常方便的函數式功能,直接傳遞求值函數inspector進行不同情況下的求值。
type inspector func(Node, []Node) error
求值過程
具體的求值過程核心函數為:
func (ng *Engine) execEvalStmt(ctx context.Context, query *query, s *EvalStmt) (Value, storage.Warnings, error) { ...... querier, warnings, err := ng.populateSeries(ctxPrepare, query.queryable, s) // 這邊拿到對應序列的數據 ...... val, err := evaluator.Eval(s.Expr) // here 聚合計算 ...... }populateSeries
首先通過populateSeries的計算出VectorSelector Node所對應的series(時間序列)。這里直接給出求值函數
func(node Node, path []Node) error { ...... querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End)) ...... case *VectorSelector: ....... set, wrn, err = querier.Select(params, n.LabelMatchers...) ...... n.unexpandedSeriesSet = set ...... case *MatrixSelector: ...... } return nil可以看到這個求值函數,只對VectorSelector/MatrixSelector進行操作,針對我們的Promql也就是只對葉子節點VectorSelector有效。
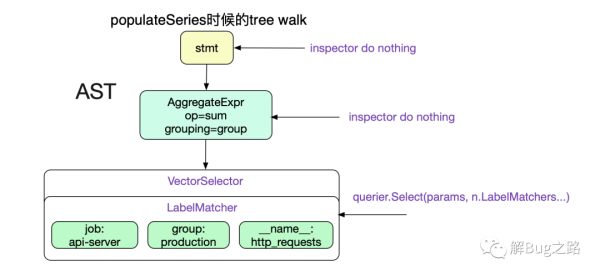
select
獲取對應數據的核心函數就在querier.Select。我們先來看下qurier是如何得到的.
querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End))
根據時間戳范圍去生成querier,里面最重要的就是計算出哪些block在這個時間范圍內,并將他們附著到querier里面。具體見函數
func (db *DB) Querier(mint, maxt int64) (Querier, error) { for _, b := range db.blocks { ...... // 遍歷blocks挑選block } // 如果maxt>head.mint(即內存中的block),那么也加入到里面querier里面。 if maxt >= db.head.MinTime() { blocks = append(blocks, &rangeHead{ head: db.head, mint: mint, maxt: maxt, }) } ...... }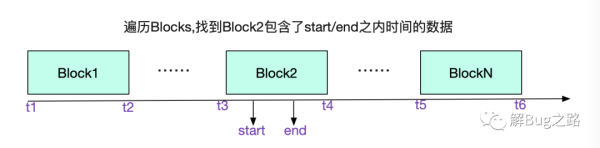
知道數據在哪些block里面,我們就可以著手進行計算VectorSelector的數據了。
// labelMatchers {job:api-server} {__name__:http_requests} {group:production} querier.Select(params, n.LabelMatchers...)有了matchers我們很容易的就能夠通過倒排索引取到對應的series。為了篇幅起見,我們假設數據都在headBlock(也就是內存里面)。那么我們對于倒排的計算就如下圖所示:
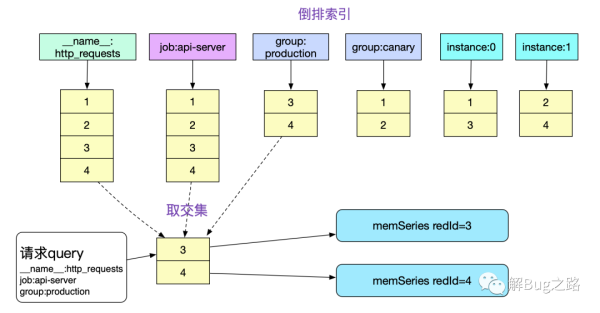
這樣,我們的VectorSelector節點就已經有了最終的數據存儲地址信息了,例如圖中的memSeries refId=3和4。
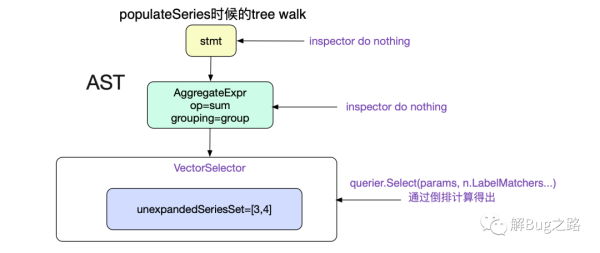
如果想了解在磁盤中的數據尋址,可以詳見筆者之前的博客
<<Prometheus時序數據庫-磁盤中的存儲結構>>
通過populateSeries找到對應的數據,那么我們就可以通過evaluator.Eval獲取最終的結果了。計算采用后序遍歷,等下層節點返回數據后才開始上層節點的計算。那么很自然的,我們先計算VectorSelector。
func (ev *evaluator) eval(expr Expr) Value { ...... case *VectorSelector: // 通過refId拿到對應的Series checkForSeriesSetExpansion(ev.ctx, e) // 遍歷所有的series for i, s := range e.series { // 由于我們這邊考慮的是instant query,所以只循環一次 for ts := ev.startTimestamp; ts <= ev.endTimestamp; ts += ev.interval { // 獲取距離ts最近且小于ts的最近的sample _, v, ok := ev.vectorSelectorSingle(it, e, ts) if ok { if ev.currentSamples < ev.maxSamples { // 注意,這邊的v對應的原始t被替換成了ts,也就是instant query timeStamp ss.Points = append(ss.Points, Point{V: v, T: ts}) ev.currentSamples++ } else { ev.error(ErrTooManySamples(env)) } } ...... } } }如代碼注釋中看到,當我們找到一個距離ts最近切小于ts的sample時候,只用這個sample的value,其時間戳則用ts(Instant Query指定的時間戳)代替。
其中vectorSelectorSingle值得我們觀察一下:
func (ev *evaluator) vectorSelectorSingle(it *storage.BufferedSeriesIterator, node *VectorSelector, ts int64) (int64, float64, bool){ ...... // 這一步是獲取>=refTime的數據,也就是我們instant query傳入的 ok := it.Seek(refTime) ...... if !ok || t > refTime { // 由于我們需要的是<=refTime的數據,所以這邊回退一格,由于同一memSeries同一時間的數據只有一條,所以回退的數據肯定是<=refTime的 t, v, ok = it.PeekBack(1) if !ok || t < refTime-durationMilliseconds(LookbackDelta) { return 0, 0, false } } }就這樣,我們找到了series 3和4距離Instant Query時間最近且小于這個時間的兩條記錄,并保留了記錄的標簽。這樣,我們就可以在上層進行聚合。
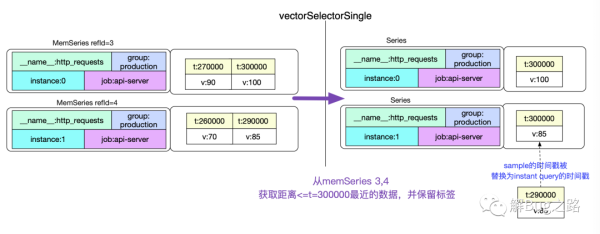
SUM by聚合
葉子節點VectorSelector得到了對應的數據后,我們就可以對上層節點AggregateExpr進行聚合計算了。代碼棧為:
evaluator.rangeEval |->evaluate.eval.func2 |->evelator.aggregation grouping key為group
具體的函數如下圖所示:
func (ev *evaluator) aggregation(op ItemType, grouping []string, without bool, param interface{}, vec Vector, enh *EvalNodeHelper) Vector { ...... // 對所有的sample for _, s := range vec { metric := s.Metric ...... group, ok := result[groupingKey] // 如果此group不存在,則新加一個group if !ok { ...... result[groupingKey] = &groupedAggregation{ labels: m, // 在這里我們的m=[group:production] value: s.V, mean: s.V, groupCount: 1, } ...... } switch op { // 這邊就是對SUM的最終處理 case SUM: group.value += s.V ..... } } ..... for _, aggr := range result { enh.out = append(enh.out, Sample{ Metric: aggr.labels, Point: Point{V: aggr.value}, }) } ...... return enh.out }好了,有了上面的處理,我們聚合的結果就變為:
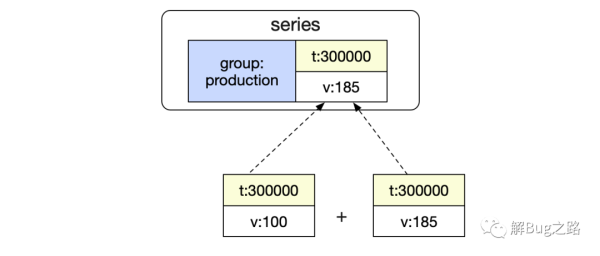
看完上述內容,你們對Prometheus時序數據庫中怎么查詢數據有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





