溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1. 引言
現代計算機,即使很小的智能機亦或者平板電腦,都是一個多核(多CPU)處理設備,如何充分利用多核CPU資源,以達到單機性能的極大化成為我們碼農進行軟件開發的痛點和難點。在多核服務器中,采用多進程或多線程來并行處理任務,儼然成為了大家性能調優的標準解決方案。多進程(多線程)的并行編程方式,必然要面對共享數據的訪問問題,如何并發、高效、安全地訪問共享數據資源,成為并行編程的一個重點和難點。
傳統的共享數據訪問方式是采用同步原語(臨界區、鎖、條件變量等)來達到共享數據的安全訪問,然而,同步恰恰和并行編程是對立的,很容易成為并行程序中的瓶頸。一方面,有些同步原語是操作系統的內核對象,調用該原語會帶來昂貴的上下文切換(用戶態切換到內核態)代價,同時,內核對象是一個比較有限的資源。另一方面,同步杜絕了并行操作,一個線程在訪問共享數據的時候,其他的多個線程必須在排隊空閑等待,同時,同步可擴展性很弱,隨著并行線程的增加,很容易成為程序的一個瓶頸,甚至出現,服務性能吞吐量并沒隨CPU核數增加或并發線程的增加呈現線性增長,相反出現下降的情況。
于是,人們開始研究對共享數據進行并發訪問的數據結構和算法,通常有以下幾方面:
```
1. Transactional memory --- 事務性內存
2. Fine-grained algorithms --- 細粒度(鎖)算法
3. Lock-free data structures --- 無鎖數據結構
```
(1) 事務內存(Transactional memory)TM是一個軟件技術,簡化了并發程序的編寫。 TM借鑒了在數據庫社區中首先建立和發展起來的概念, 基本的想法是要申明一個代碼區域作為一個事務。一個事務(transaction ) 執行并原子地提交所有結果到內存(如果事務成功),或中止并取消所有的結果(如果事務失敗)。 TM的關鍵是提供原子性(Atomicity),一致性(Consistency )和隔離性(Isolation )這些要素。 事務可以安全地并行執行,以取代現有的痛苦和容易犯錯誤(下面幾點)的技術,如鎖和信號量。 還有一個潛在的性能優勢。 我們知道鎖是悲觀的(pessimistic ),并假設上鎖的線程將寫入數據,因此,其他線程的進展被阻塞。 然而訪問鎖定值的兩個事務可以并行地進行,且回滾只發生在當事務之一寫入數據的時候。但是,目前還沒有嵌入式的事務內存,比較難和傳統代碼集成,需要軟件做出比較大的變化,同時,軟件TM性能開銷極大,2-10倍的速度下降是常見的,這也限制了軟件TM的廣泛使用
```
1. 因為忘記使用鎖而導致條件競爭(race condition)
2. 因為不正確的加鎖順序而導致死鎖(deadlock)
3. 因為未被捕捉的異常而造成程序崩潰(corruption)
4. 因為錯誤地忽略了通知,造成線程無法正常喚醒(lost wakeup)
```
(2) 細粒度(鎖)算法是一種基于另類的同步方法的算法,它通常基于“輕量級的”原子性原語(比如自旋鎖),而不是基于系統提供的昂貴消耗的同步原語。細粒度(鎖)算法適用于任何鎖持有時間少于將一個線程阻塞和喚醒所需要的時間的場合,由于鎖粒度極小,在此類原語之上構建的數據結構,可以并行讀取,甚至并發寫入。Linux 4.4以前的內核就是采用_spin_lock自旋鎖這種細粒度鎖算法來安全訪問共享的listen socket,在并發連接相對輕量的情況下,其性能和無鎖性能相媲美。然而,在高并發連接的場景下,細粒度(鎖)算法就會成為并發程序的瓶頸所在。
(3) 無鎖數據結構,為解決在高并發場景下,細粒度鎖無法避免的性能瓶頸,將共享數據放入無鎖的數據結構中,采用原子修改的方式來訪問共享數據。
目前,常見的無鎖數據結構主要有:無鎖隊列(lock free queue)、無鎖容器(b+tree、list、hashmap等)。
本文以一個無鎖隊列實現片段為藍本,來談談無鎖編程中的那些事。下面是一個開源C++并發數據結構lib中的無鎖隊列的實現片段
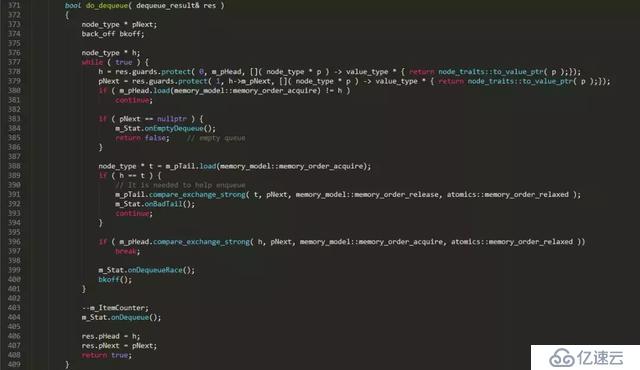
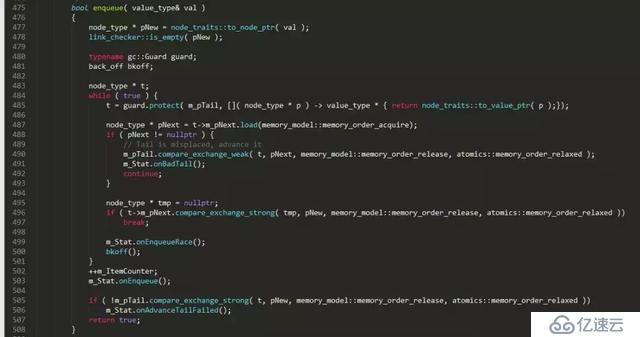
上面是一個普通單向鏈表隊列的無鎖實現,對比普通的鏈表隊列實現,無鎖實現復雜了很多,多出了很多獨有的特征操作:
```
1. C++11 標準的原子性操作: load、store、compare_exchange_weak、compare_exchange_strong
2. 一個無限循環: while ( true ) { ... }
3. 局部變量的安全性(guards):t = guard.protect( m_pTail, node_to_value() );
4. 補償策略(functor bkoff):這不是必須的,但可以在連接很多的情況下緩解處理器的壓力,尤其是多個線程逐個地調用隊列時。
5. helping方法:本例中,dequeue中幫助enqueue將m_pTail設置正確。
// It is needed to help enqueue
m_pTail.compare_exchange_strong( t, pNext, memory_model::memory_order_release,
memory_model::memory_order_relaxed );
6. 標準原子操作中使用的內存模型(memory model),也就是內存柵欄(屏障):memory_order_release、memory_order_acquire等
```
下面分別講一下上面提到無鎖隊列實現中的6個特征。
2. 原子性、原子性原語
我們知道無論是何種情況,只要有共享的地方,就離不開同步,也就是concurrency。對共享資源的安全訪問,在不使用鎖、同步原語的情況下,只能依賴于硬件支持的原子性操作,離開原子操作的保證,無鎖編程(lock-free programming)將變得不可能。
留意本例的無鎖隊列的實現例子,我們發現原子性操作可以簡單劃分為兩部分:
```
1. 原子性讀寫(atomic read and write):本例中的原子load(讀)、原子store(寫)
2. 原子×××換(Atomic Read-Modify-Write -- RMW):本例中的compare_exchange_weak、compare_exchange_strong
```
原子操作可認為是一個不可分的操作;要么發生,要么沒發生,我們看不到任何執行的中間過程,不存在部分結果(partial effects)。可以想象的到,原子操作要保證要么全部發生,要么全部沒發生,這樣原子操作絕對不是一個廉價的消耗低的指令,相反,原子操作是一個較為昂貴的指令。那么在無鎖編程中,我們要避免濫用原子操作,那么什么情況下,我們需要對共享變量的操作采用原子操作呢?對變量的普通的讀取賦值操作是原子的嗎?
通常情況下,我們有一個對共享變量必須使用原子操作的規則:
```
任何時刻,只要存在兩個或多個線程并發地對同一個共享變量進行操作,并且這些操作中的其中一個是執行了寫操作,那么所有的線程都必須使用原子操作。
```
如果違反上面的規則,即存在某個線程使用了非原子操作,那么你將會陷入一個在C++11標準中稱之為數據競爭(data race)(這里的數據競爭和Java中的data race概念,以及更通用的race condition是不一樣的)的情形。如果你引發了數據競爭,那么就會得到一個"未定義行為(undefined behavior)"的結果,它們會導致torn reads(撕裂讀)和torn writes(撕裂寫),也就是一個非完整的讀寫。
什么樣的內存操作是原子的呢?通常情況下,如果一個內存操作使用了多條CPU指令,那么這個內存操作是非原子的。那么只使用一條CPU指令的內存操作是不是就一定是原子的呢?答案是不一定,某些僅僅使用一條CPU的內存操作,在絕大多數CPU架構上是原子,但是,在個別CPU架構上是非原子的。如果,我們想寫出可移植的代碼,就不能做出使用一條CPU指令的內存操作一定是原子的假設。
在C/C++中,所有的內存操作都被假定為非原子性的,即使是普通的32位×××賦值,除非編譯器或硬件廠商有特殊說明這個賦值操作是原子的。在所有的現代x86,x64,Itanium,SPARC,ARM和PowerPC處理器中,普通的32位×××,只要內存地址是對齊的,那么賦值操作就是原子操作,這個保證是特定平臺下編譯器和處理器做出的保證。由于C/C++語言標準并沒對整型賦值是原子操作做出保證,于是,要想寫出真正可移植的C和C++代碼時,我們只能使用C++11提供的原子庫( C++11 atomic library)來保證對變量的load(讀)和store(寫)是原子的。
2.1 不能不說的關鍵字:volatile
通過上面我們知道,在現代處理器中,對于一個對齊的×××類型(×××或指針),其讀寫操作是原子的,而對于現代編譯器,用volatile修飾的基本類型正確對齊的保障,并且限制了編譯器對其優化。這樣通過對int變量加上volatile修飾,我們就能對該變量進行原子性讀寫。
```
volatile int i=10;//用volatile修飾變量i
......//something happened
int b = i;//atomic read
```
由于volatile 在某種程度上限制了編譯器的優化,而很多時候,對于同一個變量,我們在某些地方有原子性讀寫的需求,在某些地方我們又不需要原子性讀寫,這個時候希望編譯器該優化的時候就優化。然而,不加volatile修飾,那么就做不到前面一點。加了volatile,后面這一方面就無從談起,怎么辦?其實,這里有個小技巧可以達到這個目的:
```
int i = 2; //變量i還是不用加volatile修飾
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define READ_ONCE(x) ACCESS_ONCE(x)
#define WRITE_ONCE(x, val) ({ ACCESS_ONCE(x) = (val); })
a = READ_ONCE(i);
WRITE_ONCE(i, 2);
```
通過上面我們知道,用volatile修飾的int在現代處理器中,能夠做到原子性的讀寫,并且限制編譯器的優化,每次都是從內存中讀取最新的值,很多同學就誤以為volatile能夠保證原子性并且具有Memery Barrier的作用。其實vloatile既不能保證原子性,也不會有任何的Memery Barrier(內存柵欄)的保證。上面例子中,volatile僅僅是保證int的地址對齊,而對齊后的×××在現代處理器中,是能夠做到原子性讀寫的。在C++中volatile具有以下特性:
```
1. 易變性:所謂的易變性,在匯編層面反映出來,就是兩條語句,下一條語句不會直接使用上一條語句對應的volatile變量的寄存器內容,而是重新從內存中讀取。
2. "不可優化"性:volatile告訴編譯器,不要對我這個變量進行各種激進的優化,甚至將變量直接消除,保證程序員寫在代碼中的指令,一定會被執行。
3. "順序性":能夠保證Volatile變量間的順序性,編譯器不會進行亂序優化。Volatile變量與非Volatile變量的順序,編譯器不保證順序,可能會進行亂序優化。
```
2.2 Compare-And-Swap(CAS)
對于CAS相信大家都不陌生,在學術圈,compare-and-swap (CAS)被認為是最基礎的一種原子性RMW操作,其偽代碼如下:
```
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
```
上面的CAS返回bool告知原子×××換是否成功,然而在有些應用場景中,我們希望CAS 失敗后,能夠返回內存單元中的當前值,于是就有一個稱為 valued CAS的變種,偽代碼如下:
```
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr;
}
```
CAS作為最基礎的RMW操作,其他所有RMW操作都可以通過CAS來實現,例如 fetch-and-add(FAA),偽代碼如下:
```
int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;//compare_exchange失敗會返回當前值于ncur
return ncur ;
}
```
在C++11的原子lib中,主要有以下RMW操作:
```
std::atomic<>::fetch_add()
std::atomic<>::fetch_sub()
std::atomic<>::fetch_and()
std::atomic<>::fetch_or()
std::atomic<>::fetch_xor()
std::atomic<>::exchange()
std::atomic<>::compare_exchange_strong()
std::atomic<>::compare_exchange_weak()
```
其中compare_exchange_weak()就是最基礎的CAS,使用compare_exchange_weak()我們可以實現其他所有的RMW操作,C++11 atomic library中的原子RMW操作有點少,不能滿足我們實際需求,我們可以自己動手實現自己需要的原子RMW操作。
例如:我們需要一個原子對內存中值執行乘法,也就是 atomic fetch_multiply,實現偽代碼如下:
```
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue = shared.load();
while (!shared.compare_exchange_weak(oldValue, oldValue * multiplier))
{
}
return oldValue;
}
```
以上的原子RMW操作都是只能對一個integer變量進行原子修改操作,如果我們想同時對兩個integer變量進行原子操作,怎么實現呢?我們知道C++11的原子庫std::atomic<>是一個模版,這樣我們可以用一個結構體來包含兩個integer變量,來對結構體進行原子修改,實現如下:
```
struct Terms
{
uint32_t x;
uint32_t y;
};
std::atomic<Terms> terms;
void atomicFibonacciStep()
{
Terms oldTerms = terms.load();
Terms newTerms;
do
{
newTerms.x = oldTerms.y;
newTerms.y = oldTerms.x + oldTerms.y;
}
while (!terms.compare_exchange_weak(oldTerms, newTerms));
}
```
到這里,可能大家會有疑問了,是不是terms.compare_exchange_weak(oldTerms, newTerms)在內部加了鎖,要不怎么能夠原子修改呢?
C++11的原子庫std::atomic<> template可以是任何類型(int、bool等buil-in type,或user-defined type),但并不是所有的類型的原子操作是lock-free的。C++11 標準庫 std::atomic 提供了針對×××(integral)和指針類型的特化實現,其中 integal 代表了如下類型char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, long long, unsigned long long, char16_t, char32_t, wchar_t,這些特化實現,都包含了一個is_lock_free()成員來用于判斷該原子類型是原子操作是否是lock-free的。
上面的例子中,在X64平臺下,用GCC4.9.2編譯出來的代碼terms.compare_exchange_weak(oldTerms, newTerms)是lock-free的,在其他平臺下就不能保證了。在實際應用中,通常情況下,同時滿足以下條件的原子類的原子操作才能做出是lock-free的保證:
```
1. The compiler is a recent version MSVC, GCC or Clang.
2. The target processor is x86, x64 or ARMv7 (and possibly others).
3. The atomic type is std::atomic<uint32_t>, std::atomic<uint64_t> or std::atomic<T*> for some type T.
```
2.3 Weak and Strong CAS
相信大家看到C++11的CAS操作有兩個compare_exchange_weak和compare_exchange_strong,CAS怎么還有強弱之分呢?現代處理器架構對CAS的實現分成兩大陣營:(1)實現了原子性CAS原語 -- X86、Intel Itanium、Sparc等處理器架構,最早實現于IBM System 370。(2)實現LL/SC對(load-linked/store-conditional) -- PowerPC, MIPS, Alpha, ARM 等處理器架構,最早實現于DEC,通過LL/SC對可以實現原子性CAS,但在一些情況下它并不具有原子性。為什么會存在LL/SC對的使用,而不直接實現CAS原語呢?要說明LL/SC對存在的原因,不得不說一下無鎖編程中的一個棘手問題:ABA問題。
2.3.1 ABA問題
下面無鎖堆棧的實現片段:
```
// Shared variables
static NodeType * Top = NULL; // Initially null
Push(NodeType * node) {
do {
/*Push2*/ NodeType * t = Top;
/*Push3*/ node->Next = t;
/*Push4*/ } while ( !CAS(&Top,t,node) );
}
NodeType * Pop() {
Node * next ;
do {
/*Pop1*/ NodeType * t = Top;
/*Pop2*/ if ( t == null )
/*Pop3*/ return null;
/*Pop4*/ next = t->Next;
/*Pop5*/ } while ( !CAS(&Top,t,next) );
/*Pop6*/ return t;
}
```
假設當前堆棧有4個成員是:A-->B-->C-->D,A位于棧頂。下面的一個執行時序會導致一個棧被破壞的ABA問題:
```
1. Thread X執行Pop()操作,并在執行完/*Pop4*/這行代碼后Thread X被切出去,這個時候對于Thread X來說, t == A; next == A->next == B;Top == A;當前棧:A-->B-->C-->D
2. Thread Y 執行NodeType * pTop=Pop()操作,接著又執行Pop(),最后執行Push(pTop)。這個時候當前棧變成了:A-->C-->D。
3. 這個時候Thread X被調度執行/*Pop5*/這行代碼,由于棧頂元素依然是A,于是CAS(&Top,t,next)執行成功,Top變成指向了B,棧頂指針指向了一個已經不再棧中的元素B,整個棧被破壞了。
```
通過這個例子,我們知道ABA問題是所有基于CAS的無鎖容器的一個災難問題,要解決ABA問題有兩個思路:
```
1. 不要重用容器中的元素,本例中,Pop出來的A不要直接Push進容器,應該new一個新的元素A_n出來然后在push進容器中。當然new一個新的元素也不絕對安全,如果是A先被delete了,接著調用new來new一個新的元素有可能會返回A的地址,這樣還是存在ABA的風險。一般對于無鎖編程中的內存回收采用延遲回收的方式,在確保被回收內存沒有被其他線程使用的情況下安全回收內存。
2. 允許內存重用,對指向的內存采用標簽指針(Tagged Pointers)的方式,標簽作為一個版本號,隨著標簽指針上的每一次CAS運算而增加,并且只增不減。本例中,如果采用標簽指針方式,Tread X的t指向Top的時候Top的標簽為T1,這個時候t == A并且標簽是T1。隨后Tread Y執行Pop(),Pop(),Push(),Top至少進過了3次CAS,標簽變成了T1+3,于是Top == A并且標簽是T1+3,這樣在Thread X被調度執行/*Pop5*/這行代碼的時候,雖然t == Top == A,但是標簽不一樣,于是CAS會失敗,這樣棧就不會被破壞了。
```
2.3.2 Load-Linked / Store-Conditional -- LL/SC對
通過上面我們知道,ABA問題的本質在于,CAS進行比較的是指針指向的內存地址,雖然在/*Pop1*/行讀取Top指向的內存地址,到/*Pop5*/行的CAS,t和Top都是指向A的內存地址,但是A內存里面的內容已經發生過變化了(A的next變成了C)。如果處理器能夠感知得到在進行CAS的內存地址的內如發生了變化,讓CAS失敗的話,那么就能從源頭上解決ABA問題。于是PowerPC, MIPS, Alpha, ARM 等處理器架構的開發人員找到了load-linked、store-conditional (LL/SC) 這樣的操作對來徹底解決ABA問題,偽代碼如下:
```
word LL( word * pAddr ) {
return *pAddr ;
}
bool SC( word * pAddr, word New ) {
if ( data in pAddr has not been changed since the LL call) {
*pAddr = New ;
return true ;
}
else
return false ;
}
```
LL/SC對以括號運算符的形式運行,Load-linked(LL) 運算僅僅返回 pAddr 地址的當前變量值。如果 pAddr 中的內存數據在讀取之后沒有變化,那么 Store-conditional(SC)操作將會成功,它將LL讀取 pAddr 地址的存儲新的值,否則,SC將執行失敗。這里的pAddr中的內存數據是否變化指的是pAddr地址所在的Cache Line是否發生變化。在實現上,處理器開發者給每個Cahce Line添加額外的比特狀態值(status bit)。一旦LL執行讀運算,就會關聯此比特值。任何的緩存行一旦有寫入,此比特值就會被重置;在存儲之前,SC操作會檢查此比特值是否針對特定的緩存行。如果比特值為1,意味著緩存行沒有任何改變,pAddr 地址中的值會變更為新值,SC操作成功。否則本操作就會失敗,pAddr 地址中的值不會變更為新值。
CAS通過LL/SC對得以實現,偽代碼如下:
```
bool CAS( word * pAddr, word nExpected, word nNew ) {
if ( LL( pAddr ) == nExpected )
return SC( pAddr, nNew ) ;
return false ;
}
```
可以看到通過LL/SC對實現的CAS并不是一個原子性操作,但是它確實執行了原子性的CAS,目標內存單元內容要么不變,要么發生原子性變化。由于通過LL/SC對實現的CAS并不是一個原子性操作,于是,該CAS在執行過程中,可能會被中斷,例如:線程X在執行LL行后,OS決定將X調度出去,等OS重新調度恢復X之后,SC將不再響應,這時CAS將返回false,CAS失敗的原因不在數據本身(數據沒變化),而是其他外部事件(線程被中斷了)。
正是因為如此,C++11標準中添入兩個compare_exchange原語-弱的和強的。也因此這兩原語分別被命名為compare_exchange_weak和compare_exchange_strong。即使當前的變量值等于預期值,這個弱的版本也可能失敗,比如返回false。可見任何weak CAS都能破壞CAS語義,并返回false,而它本應返回true。而Strong CAS會嚴格遵循CAS語義。
那么,何種情形下使用Weak CAS,何種情形下使用Strong CAS呢?通常執行以下原則:
```
倘若CAS在循環中(這是一種基本的CAS應用模式),循環中不存在成千上萬的運算(循環體是輕量級和簡單的,本例的無鎖堆棧),使用compare_exchange_weak。否則,采用強類型的compare_exchange_strong。
```
2.3.3 False sharing(偽共享)
現代處理器中,cache是以cache line為單位的,一個cache line長度L為64-128字節,并且cache line呈現長度進一步增加的趨勢。主存儲和cache數據交換在 L 字節大小的 L 塊中進行,即使緩存行中的一個字節發生變化,所有行都被視為無效,必需和主存進行同步。存在這么一個場景,有兩個變量share_1和share_2,兩個變量內存地址比較相近被加載到同一cahe line中,cpu core1 對變量share_1進行操作,cpu core2對變量share_2進行操作,從cpu core2的角度看,cpu core1對share_1的修改,會使得cpu core2的cahe line中的share_2無效,這種場景叫做False sharing(偽共享)。
由于LL/SC對比較依賴于cache line,當出現False sharing的時候可能會造成比較大的性能損失。加載連接(LL)操作連接緩存行,而存儲狀態(SC))操作在寫之前,會檢查本行中的連接標志是否被重置。如果標志被重置,寫就無法執行,SC返回 false。考慮到cache line比較長,在多核cpu中,cpu core1在一個while循環中變量share_1執行CAS修改,而其他cpu corei在對同一cache line中的變量share_i進行修改。在極端情況下會出現這樣的一個livelock(活鎖)現象:每次cpu core1在LL(share_1)后,在準備進行SC的時候,其他cpu core修改了同一cache line的其他變量share_i,這樣使得cache line發生了改變,SC返回false,于是cpu core1又進入下一個CAS循環,考慮到cache line比較長,cache line的任何變更都會導致SC返回false,這樣使得cup core1在一段時間內一直在進行一個CAS循環,cpu core1都跑到100%了,但是實際上沒做什么有用功。
為了杜絕這樣的False sharing情況,我們應該使得不同的共享變量處于不同cache line中,一般情況下,如果變量的內存地址相差住夠遠,那么就會處于不同的cache line,于是我們可以采用填充(padding)來隔離不同共享變量,如下:
```
struct Foo {
int volatile nShared1;
char _padding1[64]; // padding for cache line=64 byte
int volatile nShared2;
char _padding2[64]; // padding for cache line=64 byte
};
```
上面,nShared1和nShared2就會處于不同的cache line,cpu core1對nShared1的CAS操作就不會被其他core對nShared2的修改所影響了。
上面提到的cpu core1對share_1的修改會使得cpu core2的share_2變量的cache line失效,造成cpu core2需重新加載同步share_2;同樣,cpu core2對share_2變量的修改,也會使得cpu core1所在的cache line實現,造成cpu core1需要重新加載同步share_1。這樣cpu core1的一個修改造成cpu core2的一個cache miss,cpu core2的一個修改造成cpu core1的一個cache miss的反復現象就是所謂的Cache ping-pong問題,出現大量Cache ping-pong意味著大量的cache miss,會造成巨大的性能損失。我們同樣可以采用填充(padding)來隔離不同共享變量來解決cache ping-pong。
3 局部變量的安全性
通過上面,我們知道實現無鎖數據結構在內存使用上存在兩個棘手的問題:一是ABA問題,二是內存安全回收問題。這兩個問題之間聯系比較密切,但是鮮有兩全其美的辦法,同時解決這兩大難題,通常采用各個擊破,分別予以解決。
有種從根源上解決這個問題的方法,那就是不產生這兩個問題,對于無鎖隊列來說,我們可以實現一個定長無鎖隊列,隊列在初始化的時候確定好隊列的大小n,這樣一次性分配好所需的內存(n * sizeof(node))。
定長無鎖隊列將一塊連續的內存分割成n個小內存塊block,每個內存塊block可以存儲一個隊列node(當然在隊列node過大的情況下,可以用連續的幾個內存塊來存儲一個隊列node)。通過head和tail兩個指針來進行隊列node的入隊和出隊,從head到tail是已經被使用的內存block(被已入隊的隊列node占用),從tail到head之間是空閑內存block。入隊的時候,首先原子修改tail指針(tail指針向后移動若干block),占據需要使用的block,然后往blcok中寫入隊列node。出隊的時候,首先原子修改head指針(head指針向后移動若干block),占據需要讀取的block,然后從block中讀取隊列node。
定長無鎖隊列不存在內存的分配和回收問題,同時內存block的位置固定,像一個環形buf一直在循環讀寫使用,不存在ABA問題。定長無鎖隊列存在一個隊列元素讀寫完整性問題,由于入隊采用的是先入隊在寫入內容的方式,于是存在隊列node內容還沒寫入完畢就會被出隊讀取了,讀取到一個不完整的node。同樣,出隊采用先出隊,在讀取隊列node內容,于是也存在內容還沒讀取的時候,被新的隊列node入隊的內容給覆蓋了。要解決這個問題不復雜,只要給每個隊列node加上一個tag標記是否已經寫入完畢、是否已經讀取完畢即可。
定長無鎖隊列雖然不存在ABA問題和內存安全回收問題,但是由于其隊列是定長的,擴展性比較差。對于ABA問題的解決方案,前面已經介紹了標簽指針(Tagged pointers)和LL/SC對兩種解決方案。下面著重介紹以下內存安全回收的解決方案。
內存安全回收問題根源上是待回收的內存還被其他線程引用中,此時如果delete該內存,那么引用該內存的線程就會出現使用非法內存的問題,那么我們只能延遲回收該內存,即在安全時刻再delete。目前用于lock free代碼的內存回收的經典方法有:Lock Free Reference Counting、Hazard Pointer、Epoch Based Reclamation、Quiescent State Based Reclamation等。
3.1 Epoch Based Reclamation(基于周期的內存回收)
Epoch Based方法采用遞增的方式來維護記錄當前正在被引用的內存版本ver_i,如果能知道當前被引用的的內存的最小版本ver_min,那么我們就可以安全回收所有內存版本小于ver_min的內存了。通常不會給一個內存對象一個版本,這樣版本太多,難以管理,一個折中方案是一個周期內的內存對象都是分配同一個版本ver_p。那么,最少需要幾個不同版本呢?一個版本是肯定不可以的,這樣就無法區分哪些內存對象是可以安全回收的,哪些是暫時不能回收的。兩個版本ver_0、ver_1是否OK呢?假設當前的內存對象都被分配版本號ver_0,在某一個時刻t1,我們決定變更版本號為ver_1,這樣新的內存對象就被分配版本ver_1。這樣才t1后,在我們再次變更版本號為ver_0前,版本號為ver_0的內存對象就不再增加了。那么,在所有使用版本號為ver_0的內存對象的線程都不再使用這些內存對象后,假設這個時候是t2,這時我們就可以開始回收版本號ver_0的內存對象,回收耗時k*n(n是待回收的內存對象)。很明顯,我們再次變更版本號為ver_0的時刻t3是一定要大于等于t2+k*n時刻的,因為,如果t3<t2+k*n,那么在t2+k*n至t3間產生的版本號為的對象就會存在非安全回收的風險。
可以看出采用兩個版本是ok的,但是細心的同學會發現,這樣的回收粒度有點粗,版本號為ver_1的內存對象在t1至t2+k*n這段時間內一直在增長,整個時間長度依賴于內存對象被引用的時間和ver_0的內存對象被回收的時間,這樣可能會引起滾雪球效應,越往后面回收時間會越長。
通過上面的分析,我們知道,如果想版本號變更的時間點不依賴ver_0的內存對象被回收的時間,我們需要增加一個版本號ver_2,那么在t2時刻,我們就可以切換版本號為ver_2,同時可以啟動回收ver_0的內存對象。
通過上面的分析,Epoch Based算法維護了一個全局的epoch(取值為0、1、2)和三個全局的retire_list(每個全局的epoch對應一個retire list, retire list 存放邏輯刪除后待回收的節點指針)。除此之外我們為每個線程維護一個局部的thread_active flag(這個用來標識thread時候已經不再引用該epoch值的內存對象)和thread_epoch(取值自然也為0、1、2)。算法如下:
```
#define N_THREADS 4 //假設一共4個線程
const EPOCH_COUNT = 3 ;
bool active[N_THREADS] = {false};
int epoches[N_THREADS] = {0};
int global_epoch = 0;
vector<int*> retire_list[3];
void read(int thread_id)
{
active[thread_id] = true;
epoches[thread_id] = global_epoch;
//進入臨界區了。可以安全的讀取
//......
//讀取完畢,離開臨界區
active[thread_id] = false;
}
void logical_deletion(int thread_id)
{
active[thread_id] = true;
epoches[thread_id] = global_epoch;
//進入臨界區了,這里,我們可以安全的讀取
//好了,假如說我們現在要刪除它了。先邏輯刪除。
//而被邏輯刪除的tmp指向的節點還不能馬上被回收,因此把它加入到對應的retire list
retire_list[global_epoch].push_back(tmp);
//離開臨界區
active[thread_id] = false;
//看看能不能物理刪除
try_gc();
}
bool try_gc()
{
int &e = global_epoch;
for (int i = 0; i < N_THREADS; i++) {
if (active[i] && epoches[i] != e) {
//還有部分線程沒有更新到最新的全局的epoch值
//這時候可以回收(e + 1) % EPOCH_COUNT對應的retire list。
free((e + 1) % EPOCH_COUNT);//不是free(e),也不是free(e-1)。
return false;
}
}
//更新global epoch
e = (e + 1) % EPOCH_COUNT;
//更新之后,那些active線程中,部分線程的epoch值可能還是e - 1(模EPOCH_COUNT)
//那些inactive的線程,之后將讀到最新的值,也就是e。
//不管如何,(e + 1) % EPOCH_COUNT對應的retire list的那些內存,不會有人再訪問到了,可以回收它們了
//因此epoch的取值需要有三種,僅僅兩種是不夠的。
free((e + 1) % EPOCH_COUNT);//不是free(e),也不是free(e-1)。
}
bool free(int epoch)
{
for each pointer in retire_list[epoch]
if (pointer is not NULL)
delete pointer;
}
```
Epoch Based Reclamation算法規則比較簡單明了,該算法規則有個重要的缺陷是,它依賴于所有使用ver_0的內存對象的線程都進入到下個周期ver_1后,ver_0的內存對象才能被回收。只要有一個線程未能進入到下個周期ver_1,那么那些大多數已經沒有引用的ver_0內存對象就不能被刪除回收。這個在線程存在不同的優先級時候,優先級低的線程會導致優先級高的線程延遲待刪除元素增長變得不可控,一旦某個線程一直無法進入下一個周期,會導致無限的內存消耗。
3.2 險象指針(Hazard pointer)
Hazard Pointer由Maged M. Michael在論文"Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects"中提出,基本思路是將可能要被訪問到的共享對象指針(成為hazard pointer)先保存到線程局部,然后再訪問,訪問完成后從線程局部移除。而要釋放一個共享對象時,則要先遍歷查詢所有線程的局部信息,如果尚有線程局部保存有這個共享對象的指針,說明這個線程有可能將要訪問這個對象,因此不能釋放,只有所有線程的局部信息中都沒有保存這個共享對象的指針情況下,才能將其釋放。
我們知道Hazard Pointer封裝了原始指針,那么Hazard Pointer的內存和生命周期本身如何管理呢?以下是常見的策略:
```
1,Hazard Pointer本身的內存只分配,不釋放。在stack、queue等數據結構里,需要的Hazard Pointer數量一般為1或者2,所以不釋放問題不大。對于skip list這種數據結構又有遍歷需求的,那么Hazard Pointer可能就不是非常適用了,可以考慮使用Epoch Based Reclamation技術。據我所知,這也是memsql使用的內存回收策略。
2,每個線程擁有、管理自己的retire list和hazard pointer list ,而不是所有線程共享一個retire list,這樣可以避免維護retire list和hazard pointer list的開銷,否則我們可能又得想盡腦汁去設計另外一套lock free的策略來管理這些list,先有雞先有蛋,無窮無盡。所謂retire list就是指邏輯刪除后待物理回收的指針列表。
3,每個線程負責回收自己的retire list中記錄維護的內存。這樣,retire list是一個線程局部的數據結構,自己寫,自己讀,吃自己的狗糧。
4,只有當retire list的大小(數量)達到一定的閾值時,才進行GC。這樣,可以把GC的開銷進行分攤,同時,應該盡可能使用Jemalloc或者TCmalloc這些高效的、帶線程局部緩存的內存分配器。
```
3.3 Hazard Version
HazardPointer的實現簡單,但是其有個不足:需要為每個共享變量維護一個線程的hazard pointer,這樣使用者需要仔細分析算法以盡量減少同時存在的hazard pointer,Hazard Pointer機制也與具體數據結構的實現比較緊的耦合在一起,對于skip list這樣的有遍歷需求的數據結構同時存在的hazard pointer很容易膨脹比較多,內存使用是個問題。
因此在Hazard Pointer基礎上發展出了被稱為Hazard Version技術,它提供類似lock一樣的acquire/release接口,支持無限制個數共享對象的管理。
與Hazard Pointer的實現不同:首先全局要維護一個int64_t類型的GlobalVersion;要訪問共享對象前,先將當時的GlobalVersion保存到線程局部,稱為hazard version;而每次要釋放共享對象的時候先將當前GlobalVersion保存在共享對象,然后將GlobalVersion原子的加1,然后遍歷所有線程的局部信息,找到最小的version稱為reclaim version,判斷如果待釋放的對象中保存的version小于reclaim version則可以釋放。hazard version就類似于給每個內存對象分配一個單調遞增的version的Epoch Based方法,是更細粒度的內存回收。
4 補償策略(functor bkoff)
補償策略通常作為避免大量CAS競爭的一種退避策略,在大并發修改同一變量的情況下,能有效緩解CPU壓力。考慮這么一個場景,N個線程同時對一個無鎖隊列進行入隊操作,于是同時進行的N個CAS操作,最終只有一個線程返回成功。于是,失敗的N-1個線程在下一個循環中繼續重試同時進行N-1個CAS操作,最終還是只有一個線程返回成功。這樣一直下去,大量的CPU被消耗在無用的CAS操作上,我們知道CAS操作是一個很重的一個操作,服務器性能會急劇下降。這好比來自四面八方的車輛匯聚到一個出口,大家都比較自私的想要最快通過的話,那么這個路口會被堵的水泄不通,理想的情況是將車輛流水線化,這樣大家都能較快通過出口。然而實際情況是比較難流水線化的,于是,我們采用禮讓的方式,在嘗試通過路口發現堵塞的時候,就delay一小會在嘗試通過。一個簡單的實現如下:
```
bkoof()
{
static const int64_t INIT_LOOP = 1000000;
static const int64_t MAX_LOOP = 8000000;
static __thread int64_t delay = 0;
if (delay <= 0) {
delay = INIT_LOOP;
}
for (int64_t i = 0; i < delay; i++) {
CPU_RELAX();
}
int64_t new_delay = delay << 1LL;
if (new_delay <= 0 || new_delay >= MAX_LOOP) {
new_delay = INIT_LOOP;
}
delay = new_delay;
}
}
```
5 helping方法
Helping方法是一種廣泛存在于無鎖算法中的方法,特別是在一個線程幫助其它線程去執行任務場景中。本例中的無鎖隊列實現,會出現m_pTail的暫時錯位不正確,主要的原因是m_pTail的修改(如下)并不能保證一定成功。
```
m_pTail.compare_exchange_strong( t, pNew, memory_model::memory_order_acq_rel,
memory_model::memory_order_relaxed );
```
這里為什么不重試讓m_pTail指向正確的位置呢?這里主要是實現策略和成本開銷的問題,考慮這么一個場景:
```
1. 當前時刻隊列有3個節點(A-->B-->C),隊列狀態:m_pHead->m_pNext == A,m_pTail == C
2. 這時線程1執行入隊enqueue(D),線程2執行入隊enqueue(E)。
3. 線程1執行enqueue(D)進行到最后一步,這時隊列狀態:(A-->B-->C-->D),m_pHead->m_pNext == A,m_pTail == C
4. 線程2執行enqueue(E),這時它發現m_pTail->m_pNext != NULL,m_pTail位置不正確了。
```
這個時候,線程2有兩個選擇:(1) 不斷重試等待線程1將m_pTail設置正確后,自己在進行下面的操作步驟。(2) 順路幫線程1一把,自己將m_pTail調整到正確位置,然后在進行下面的操作步驟。如果采用(1),線程2可能會進入一個較漫長的等待來等線程1完成m_pTail 的設置。采用(2)則是一個雙贏的局面,線程2不在需要等待和依賴線程1,線程1也不再需要在m_pTail設置失敗的時候進行重試了。
第6章的內容將在本次推送的第二條圖文《說說無鎖(Lock-Free)編程那些事(下)》中闡述。
參考資料
http://chonghw.github.io/
http://chonghw.github.io/blog/2016/08/11/memoryreorder/
http://chonghw.github.io/blog/2016/09/19/sourcecontrol/
http://chonghw.github.io/blog/2016/09/28/acquireandrelease/
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html
http://www.wowotech.net/kernel_synchronization/memory-barrier-1.html
http://www.wowotech.net/kernel_synchronization/perfbook-memory-barrier-2.html
https://kukuruku.co/post/lock-free-data-structures-introduction/
https://kukuruku.co/post/lock-free-data-structures-basics-atomicity-and-atomic-primitives/
https://kukuruku.co/post/lock-free-data-structures-the-inside-memory-management-schemes/
6 內存屏障(Memory Barriers)
6.1 What Memory Barriers?
內存屏障,也稱內存柵欄,內存柵障,屏障指令等,是一類同步屏障指令,是CPU或編譯器在對內存隨機訪問的操作中的一個同步點,使得此點之前的所有讀寫操作都執行后才可以開始執行此點之后的操作。大多數現代計算機為了提高性能而采取亂序執行,這使得內存屏障成為必須。語義上,內存屏障之前的所有寫操作都要寫入內存;內存屏障之后的讀操作都可以獲得同步屏障之前的寫操作的結果。因此,對于敏感的程序塊,寫操作之后、讀操作之前可以插入內存屏障。
通常情況下,我們希望我們所編寫的程序代碼能"所見即所得",即程序邏輯滿足程序的順序性(滿足program order),然而,很遺憾,我們的程序邏輯("所見")和最后的執行結果("所得")隔著:
```
1. 編譯器
2. CPU取指執行
```
1. 編譯器將符合人類思考的邏輯(程序代碼)翻譯成了符合CPU運算規則的匯編指令,編譯器了解底層CPU的思維模式,因此,它可以在將程序翻譯成匯編的時候進行優化(例如內存訪問指令的重新排序),讓產出的匯編指令在CPU上運行的時候更快。然而,這種優化產出的結果未必符合程序員原始的邏輯,因此,作為程序員,必須有能力了解編譯器的行為,并在通過內嵌在程序代碼中的memory barrier來指導編譯器的優化行為(這種memory barrier又叫做優化屏障,Optimization barrier),讓編譯器產出即高效,又邏輯正確的代碼。
2. CPU的核心思想就是取指執行,對于in-order的單核CPU,并且沒有cache,匯編指令的取指和執行是嚴格按照順序進行的,也就是說,匯編指令就是所見即所得的,匯編指令的邏輯嚴格的被CPU執行。然而,隨著計算機系統越來越復雜(多核、cache、superscalar、out-of-order),使用匯編指令這樣貼近處理器的語言也無法保證其被CPU執行的結果的一致性,從而需要程序員告知CPU如何保證邏輯正確。
綜上所述,memory barrier是一種保證內存訪問順序的一種方法,讓系統中的HW block(各個cpu、DMA controler、device等)對內存有一致性的視角。
通過上面介紹,我們知道我們所編寫的代碼會根據一定規則在與內存的交互過程中發生亂序。內存執行順序的變化在編譯器(編譯期間)和cpu(運行期間)中都會發生,其目的都是為了讓代碼運行的更快。就算是為了性能而亂序,但是亂序總有個度吧(總不能將指針的初始化的代碼亂序在使用指針的代碼之后吧,這樣誰還敢寫代碼)。編譯器開發者和cpu廠商都遵守著內存亂序的基本原則,簡單歸納如下:
```
不能改變單線程程序的執行行為 -- 但線程程序總是滿足Program Order(所見即所得)
```
在此原則指導下,寫單線程代碼的程序員不需要關心內存亂序的問題。在多線程編程中,由于使用互斥量,信號量和事件都在設計的時候都阻止了它們調用點中的內存亂序(已經隱式包含各種memery barrier),內存亂序的問題同樣不需要考慮了。只有當使用無鎖(lock-free)技術時–內存在線程間共享而沒有任何的互斥量,內存亂序的效果才會顯露無疑,這樣我們才需要考慮在合適的地方加入合適的memery barrier。
6.1.1 編譯期亂序
考慮下面一段代碼:
```
int Value = 0;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
IsPublished = 1;
}
int tryRecvValue()
{
if (IsPublished)
{
return Value;
}
return -1; // or some other value to mean not yet received
}
```
在出現編譯期亂序的時候,sendValue可能變成如下:
```
void sendValue(int x)
{
IsPublished = 1;
Value = x;
}
```
對于但線程而言,這樣的亂序是不會有影響的,因為sendValue(10)調用后,IsPublished == 1; Value == 10;這時調用tryRecvValue()就會得到10和亂序前是一樣的結果。但是對于多線程,線程1調用sendValue(10), 線程2調用tryRecvValue(),當線程1執行完IsPublished = 1;的時候,線程2調用tryRecvValue()就會得到Value的初始默認值0,這和程序原本邏輯違背,于是我們必須加上編譯器的barrier來防止編譯器的亂序優化:
```
#define COMPILER_BARRIER() asm volatile("" ::: "memory")
int Value;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
COMPILER_BARRIER(); // prevent reordering of stores
IsPublished = 1;
}
int tryRecvValue()
{
if (IsPublished)
{
COMPILER_BARRIER(); // prevent reordering of loads
return Value;
}
return -1; // or some other value to mean not yet received
}
```
下面也是一個編譯器亂序的例子(在Gcc4.8.5下 gcc -O2 -c -S compile_reordering.cpp):
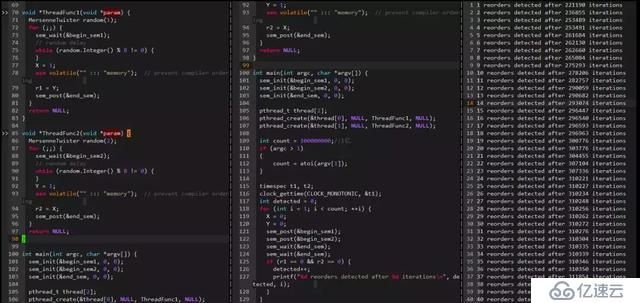
可以看出,在開啟-o2編譯器優化選項時,內存會發生亂序,在寫變量A之前會先寫變量B。
6.1.2 運行期亂序
下面看一個運行期CPU亂序的例子:
可以看出在22W多次迭代后檢測到一次亂序,亂序間隔在搖擺不定。
6.2 Why Memory Barriers?
6.2.1 現代處理器cache架構
通過上面,我們知道存在兩種類型的Memory Barriers:編譯器的Memory Barrier、處理器的Memory Barrier。對于編譯器的Memory Barrier比較好理解,就是防止編譯器為了優化而將代碼執行調整亂序。而處理器的Memory Barrier是防止CPU怎樣的亂序呢?CPU的內存亂序是怎么來的?
亂序會有問題本質上是讀到了老的數據,或者是一部分讀到新的一部分讀到老的數據,例如:上面的例子中,已經讀到了IsPublished的新值,卻還是讀到了Value老的值,從而引起問題。這種數據不一致怎么來的呢?相信這個時候大家腦海里已經浮現出一個詞了:Cache。
首先我們來看看現代處理器基本的cache架構

現代處理器為了彌補內存速度低下的缺陷,引入Cache來提高處理器訪問程序和數據的速度,Cache作為連接內核和內存的橋梁,極大提升了程序的運行速度。為什么處理器內部加一個速度快,容量小的cache就能提速呢?這里基于程序的兩個特性:時間的局部性(Temporal locality)和空間的局部性(Spatial)
```
[1] 時間的局部性(Temporal locality):如果某個數據被訪問了,那么不久的將來它很有可能被再次訪問到。典型的例子就是循環,循環的代碼被處理器重復執行,將循環代碼放在Cache中,那么只是在第一次的時候需要耗時較長去內存取,以后這些代碼都能被內核從cache中快速訪問到。
[2] 空間的局部性(Spatial):如果某個數據被訪問了,那么它相臨的數據很可能很快被訪問到。典型的例子就是數組,數組中的元素常常安裝順序依次被程序訪問。
```
現代處理器一般是多個核心Core,每個Core在并發執行不同的代碼和訪問不同的數據,為了隔離影響,每個core都會有自己私有的cache(如圖的L1和L2),同時也在容量和存儲速度上進行一個平衡(容量也大存儲速度越慢,速度:L1>L2>L3, 容量:L3>L2>L1),于是就出現圖中的層次化管理。Cache的層次化必然帶來一個cache一致性的問題:

如圖的例子,變量X(初始值是3)被cache在Core 0和Core 1的私有cache中,這時core 0將X修改成5,如果core 1不知道X已經被修改了,繼續使用cache中的舊值,那么可能會導致嚴重的問題,這就是Cache的不一致導致的。為了保證Cache的一致性,處理器提供兩個保證Cache一致性的底層操作:Write Invalidate和Write Update。
```
Write Invalidate(置無效):當一個CPU Core修改了一份數據X,那么它需要通知其他core將他們的cache中的X設置為無效(invalid)(如果cache中有的話),如下圖
```
```
Write Update(寫更新):當一個CPU Core修改了一份數據X,那么它需要通知其他core將他們的cache中的X更新到最新值(如果cache中有的話),如下圖
```
Write Invalidate和Write Update的比較:Write Invalidate是一種更為簡單和輕量的實現方式,它不需要立刻將數據更新到存儲中(這時一個耗時過程),如果后續Core 0繼續需要修改X而Core 1和Core 2又不再使用數據X了,那么這個Update過程就有點做了無用功,而采用write invalidate就更為輕量和有效。不過,由于valid標志是對應一個Cache line的,將valid標志設置為invalid后,這個cache line的其他本來有效的數據也不能被使用了,如果處理不好容易出現前面提到的False sharing(偽共享)和Cache pingpong問題。
6.2.2 cache一致性協議MESI
由于Write Invalidate比較簡單和輕量,大多數現代處理器都采用Write Invalidate策略,基于Write Invalidate處理器會有一套完整的協議來保證Cache的一致性,比較經典的當屬MESI協議,奔騰處理器采用它,很多其他處理器都是采用它的一個小變種。
每個核的Cache中的每個Cache Line都有2個標志位:dirty標志和valid標志位,兩個標志位分別描述了Cache和Memory間的數據關系(數據是否有效,數據是否被修改),而在多核處理器中,多個核會共享一些數據,MESI協議就包含了描述共享的狀態。
這樣在MESI協議中,每個Cache line都有4個狀態,可用2個bit來表示(也就是,每個cache line除了物理地址和具體的數據之外,還有一個2-bit的tag來標識該cacheline的4種不同的狀態):
```
[1] M(Modified): cache line數據有效,但是數據被修改過了,本Cache中的數據是最新的,內存的數據是老的,需要在適當時候將Cache數據寫回內存。因此,處于modified狀態的cacheline也可以說是被該CPU獨占。而又因為只有該CPU的cache保存了最新的數據(最終的memory中都沒有更新),所以,該cache需要對該數據負責到底。例如根據請求,該cache將數據及其控制權傳遞到其他cache中,或者cache需要負責將數據寫回到memory中,而這些操作都需要在reuse該cache line之前完成。
[2] E(Exclusive):cache line數據有效,并且cache和memory中的數據是一致的,同時數據只在本cache中有效。exclusive狀態和modified狀態非常類似,唯一的區別是對應CPU還沒有修改cacheline中的數據,也正因為還沒有修改數據,因此memory中對應的data也是最新的。在exclusive狀態下,cpu也可以不通知其他CPU cache而直接對cacheline進行操作,因此,exclusive狀態也可以被認為是被該CPU獨占。由于memory中的數據和cacheline中的數據都是最新的,因此,cpu不需對exclusive狀態的cacheline執行寫回的操作或者將數據以及歸屬權轉交其他cpu cache,而直接reuse該cacheline(將cacheine中的數據丟棄,用作他用)。
[3] S(Shared):cache line的數據有效,并且cache和memory中的數據是一致的,同時該數據在多個cpu cache中也是有效的。和exclusive狀態類似,處于share狀態的cacheline對應的memory中的數據也是最新的,因此,cpu也可以直接丟棄cacheline中的數據而不必將其轉交給其他CPU cache或者寫回到memory中。
[4] I(Invalid):本cache line的數據已經是無效的。處于invalid狀態的cacheline是空的,沒有數據。當新的數據要進入cache的時候,優選狀態是invalid的cacheline,之所以如此是因為如果選中其他狀態的cacheline,則說明需要替換cacheline數據,而未來如果再次訪問這個被替換掉的cacheline數據的時候將遇到開銷非常大的cache miss。
```
在MESI協議中,每個CPU都會監聽總線(bus)上的其他CPU對每個Cache line的所有操作,因此該協議也稱為監聽(snoop)協議,監聽協議比較簡單,被多少處理器使用,不過監聽協議的溝通成本比較高。有另外一種協議叫目錄協議,他采用集中管理的方式,將cache共享的信息集中在一起,類似一個目錄,只有共享的Cache line才會交互數據,這種協議溝通成本就大大減少了。在基于snoop的處理器中,所有的CPU都是在一個共享的總線上,多個CPU之間需要相互通信以保證Cache line在M、E、S、I四個狀態間正確的轉換,從而保證數據的一致性。通常情況下,CPU需要以下幾個通信message即可:
```
[1] Read消息:read message用來獲取指定物理地址上的cacheline數據。
[2] Read Response消息:該消息攜帶了read message請求的數據。read response可能來自memory,也可能來自其他的cache。例如:如果一個cache有read message請求的數據并且該cacheline的狀態是modified,那么該cache必須以read response回應這個read message,因為該cache中保存了最新的數據。
[3] Invalidate消息:該命令用來將其他cpu cache中的數據設定為無效。該命令攜帶物理地址的參數,其他CPU cache在收到該命令后,必須進行匹配,發現自己的cacheline中有該物理地址的數據,那么就將其移除并用Invalidate Acknowledge回應。
[4] Invalidate Acknowledge消息: 收到invalidate message的cpu cache,在移除了其cache line中的特定數據之后,必須發送invalidate acknowledge消息。
[5] Read Invalidate消息: 該message中也包括了物理地址這個參數,以便說明其想要讀取哪一個cacheline數據。此外,該message還同時有invalidate message的功效,即其他的cache在收到該命令后,移除自己cacheline中的數據。因此,Read Invalidate message實際上就是read + invalidate。發送Read Invalidate之后,cache期望收到一個read response以及多個invalidate acknowledge。
[6] Writeback消息: 該message包括兩個參數,一個是地址,另外一個是寫回的數據。該消息用在modified狀態的cacheline被驅逐出境(給其他數據騰出地方)的時候發出,該命名用來將最新的數據寫回到memory(或者其他的CPU cache中)。
```
根據protocol message的發送和接收情況,cacheline會在“modified”, “exclusive”, “shared”, 和 “invalid”這四個狀態之間遷移,具體如下圖所示:
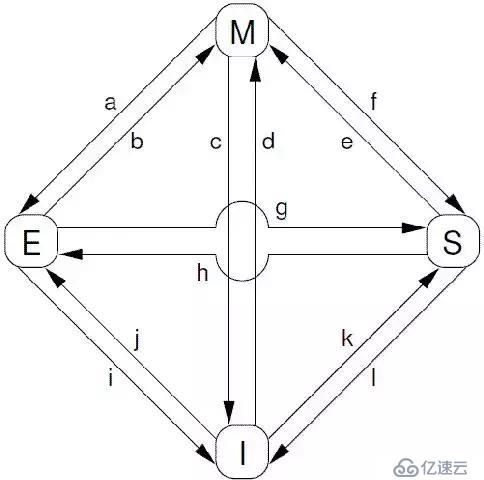
對上圖中的狀態遷移解釋如下:
```
[a] Transition (a):cache可以通過writeback transaction將一個cacheline的數據寫回到memory中(或者下一級cache中),這時候,該cacheline的狀態從Modified遷移到Exclusive狀態。對于cpu而言,cacheline中的數據仍然是最新的,而且是該cpu獨占的,因此可以不通知其他cpu cache而直接修改之。
[b] Transition (b):在Exclusive狀態下,cpu可以直接將數據寫入cacheline,不需要其他操作。相應的,該cacheline狀態從Exclusive狀態遷移到Modified狀態。這個狀態遷移過程不涉及bus上的Transaction(即無需MESI Protocol Messages的交互)。
[c] Transition (c):CPU 在總線上收到一個read invalidate的請求,同時,該請求是針對一個處于modified狀態的cacheline,在這種情況下,CPU必須該cacheline狀態設置為無效,并且用read response”和“invalidate acknowledge來回應收到的read invalidate的請求,完成整個bus transaction。一旦完成這個transaction,數據被送往其他cpu cache中,本地的copy已經不存在了。
[d] Transition (d):CPU需要執行一個原子的readmodify-write操作,并且其cache中沒有緩存數據,這時候,CPU就會在總線上發送一個read invalidate用來請求數據,同時想獨自霸占對該數據的所有權。該CPU的cache可以通過read response獲取數據并加載cacheline,同時,為了確保其獨占的權利,必須收集所有其他cpu發來的invalidate acknowledge之后(其他cpu沒有local copy),完成整個bus transaction。
[e] Transition (e):CPU需要執行一個原子的readmodify-write操作,并且其local cache中有read only的緩存數據(cacheline處于shared狀態),這時候,CPU就會在總線上發送一個invalidate請求其他cpu清空自己的local copy,以便完成其獨自霸占對該數據的所有權的夢想。同樣的,該cpu必須收集所有其他cpu發來的invalidate acknowledge之后,才算完成整個bus transaction。
[f] Transition (f):在本cpu獨自享受獨占數據的時候,其他的cpu發起read請求,希望獲取數據,這時候,本cpu必須以其local cacheline的數據回應,并以read response回應之前總線上的read請求。這時候,本cpu失去了獨占權,該cacheline狀態從Modified狀態變成shared狀態(有可能也會進行寫回的動作)。
[g] Transition (g):這個遷移和f類似,只不過開始cacheline的狀態是exclusive,cacheline和memory的數據都是最新的,不存在寫回的問題。總線上的操作也是在收到read請求之后,以read response回應。
[h] Transition (h):如果cpu認為自己很快就會啟動對處于shared狀態的cacheline進行write操作,因此想提前先霸占上該數據。因此,該cpu會發送invalidate敦促其他cpu清空自己的local copy,當收到全部其他cpu的invalidate acknowledge之后,transaction完成,本cpu上對應的cacheline從shared狀態切換exclusive狀態。還有另外一種方法也可以完成這個狀態切換:當所有其他的cpu對其local copy的cacheline進行寫回操作,同時將cacheline中的數據設為無效(主要是為了為新的數據騰些地方),這時候,本cpu坐享其成,直接獲得了對該數據的獨占權。
[i] Transition (i):其他的CPU進行一個原子的read-modify-write操作,但是,數據在本cpu的cacheline中,因此,其他的那個CPU會發送read invalidate,請求對該數據以及獨占權。本cpu回送read response”和“invalidate acknowledge”,一方面把數據轉移到其他cpu的cache中,另外一方面,清空自己的cacheline。
[j] Transition (j):cpu想要進行write的操作但是數據不在local cache中,因此,該cpu首先發送了read invalidate啟動了一次總線transaction。在收到read response回應拿到數據,并且收集所有其他cpu發來的invalidate acknowledge之后(確保其他cpu沒有local copy),完成整個bus transaction。當write操作完成之后,該cacheline的狀態會從Exclusive狀態遷移到Modified狀態。
[k] Transition (k):本CPU執行讀操作,發現local cache沒有數據,因此通過read發起一次bus transaction,來自其他的cpu local cache或者memory會通過read response回應,從而將該cacheline從Invalid狀態遷移到shared狀態。
[l] Transition (l):當cacheline處于shared狀態的時候,說明在多個cpu的local cache中存在副本,因此,這些cacheline中的數據都是read only的,一旦其中一個cpu想要執行數據寫入的動作,必須先通過invalidate獲取該數據的獨占權,而其他的CPU會以invalidate acknowledge回應,清空數據并將其cacheline從shared狀態修改成invalid狀態。
```
下面通過幾個例子,說明一下MESI協議是怎么工作的。CPU執行序列如下:
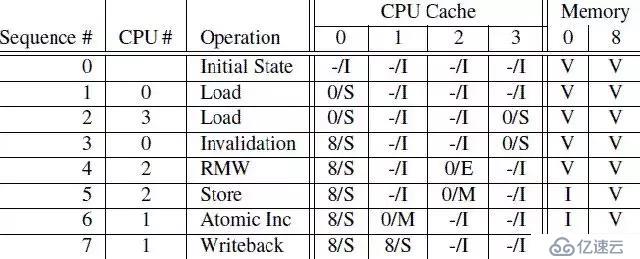
第一列是操作序列號,第二列是執行操作的CPU,第三列是具體執行哪一種操作,第四列描述了各個cpu local cache中的cacheline的狀態(用meory address/狀態表示),最后一列描述了內存在0地址和8地址的數據內容的狀態:V表示是最新的,和cpu cache一致,I表示不是最新的內容,最新的內容保存在cpu cache中。
```
[1] sequence 0:初始狀態下,內存地址0和8保存了最新的數據,而4個CPU的cache line都是invalid(沒cache任何數據或cache的數據都是過期無效的)。
[2] sequence 1:CPU 0對內存地址0執行load操作,這樣內存地址0的數據被加載到CPU 0的cache line中,CPU 0的cache line從Invalid狀態切換到Share狀態(這個時候,CPU 0的cache line和內存地址0都是相同的最新數據)。
[3] sequence 2:CPU 3也對內存地址0執行load操作,這樣內存地址0的數據被加載到CPU 3的cache line中,CPU 3的cache line從Invalid狀態切換到Share狀態(這個時候,CPU 0、CPU 3的cache line和內存地址0都是相同的最新數據)。
[4] sequence 3:CPU 0執行對內存地址8的load操作,(內存地址0和8共用一個cache line set)由于cache line已經存放了內存地址0的數據,這個時候,CPU 0需要將cache line的數據清理掉(Invalidation)以便騰出空間存放內存地址8的數據。由于,當前cache line的狀態是Share,CPU 0不需要通知其他CPU,CPU 0在Invalidation cache line的數據后,就加載內存地址8的數據到cache line中,并將cache line狀態改成Share。
[5] sequence 4:CPU 2對內存地址0執行load操作,由于CPU 2知道程序隨后會修改該值,它需要獨占該數據,因此CPU 2向總線發送了read invalidate命令,一方面獲取該數據(自己的local cache中沒有地址0的數據),另外,CPU 2想獨占該數據(因為隨后要write)。這個操作導致CPU 3的cacheline遷移到invalid狀態。當然,這時候,memory仍然是最新的有效數據。
[6] sequence 5:CPU 2對內存地址0執行Store操作,由于CPU 2的cache line是Exclusive狀態(對內存地址0的數據是獨占狀態的),于是CPU 2可以直接將新的值寫入cache line覆蓋老值,cache line狀態轉換成Modified狀態。(這個時候,內存地址0中的數據已經是Invalid的,其他CPU如果想load內存地址0的數據,不能直接從內存地址0加載數據了,需要嗅探(snoop)的方式從CPU 2的local cache中獲取。
[7] sequence 6:CPU 1對內存地址0執行一個原子加操作。這時候CPU 1會發出read invalidate命令,將地址0的數據從CPU 2的cache line中嗅探得到,同時通過invalidate其他CPU local cache的內容而獲得獨占性的數據訪問權。這時候,CPU 2中的cache line狀態變成invalid狀態,而CPU 1的cache line將從invalid狀態遷移到modified狀態。
[8] sequence 7:CPU 1對內存地址8執行load操作。由于cache line已經存放了內存地址0的數據,并且該狀態是modified的,CPU 1需要將cache line的數據寫回地址0,于是執行write back操作將地址0的數據寫回到memory(這個時候,內存地址0中的數據從Invalid變成有效的)。接著,CPU 1發出read命令,從CPU 0中得到內存地址8的數據,并寫入自己的cache line,cache line狀態轉換成Share。
```
通過上面的例子,我們發現,對于某些特定地址的數據(在一個cache line中)重復的進行讀寫,這種結構可以獲得很好的性能(例如,在sequence 5,CPU 2反復對內存地址0進行store操作將獲得很好的性能,因為,每次store操作,CPU 2僅僅需要將新值寫入自己的local cache即可),不過,對于第一次寫,其性能非常差,如圖:
cpu 0發起一次對某個地址的寫操作,但是local cache沒有數據,該數據在CPU 1的local cache中,因此,為了完成寫操作,CPU 0發出invalidate的命令,invalidate其他CPU的cache數據。只有完成了這些總線上的transaction之后,CPU 0才能正在發起寫的操作,這是一個漫長的等待過程。
6.2.3 Store Buffer
對于CPU 0來說,這樣的漫長等待顯得有點沒必要,因為,CPU 1中的cache line保存有什么樣子的數據,其實都沒有意義,這個值都會被CPU 0新寫入的值覆蓋的。為了給CPU 0提速,需要將這種同步阻塞等待,變成異步處理。于是,硬件工程師,修改CPU架構,在CPU和cache之間增加store buffer這個HW block,如下圖所示:
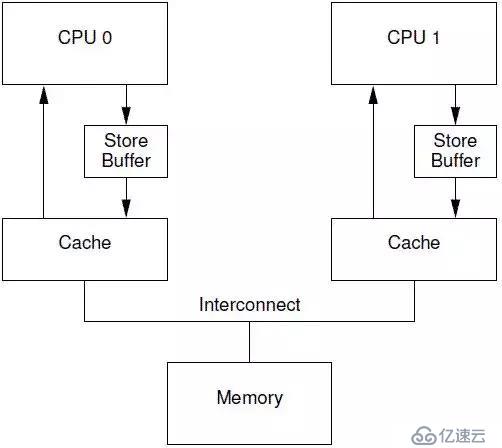
一旦增加了store buffer,那么cpu 0無需等待其他CPU的相應,只需要將要修改的內容放入store buffer,然后繼續執行就OK了。當cache line完成了bus transaction,并更新了cache line的狀態后,要修改的數據將從store buffer進入cache line。引入了store buff,帶來了一些復雜性,一不小心,會帶來本地數據不一致的問題。我們先看看下面的代碼:
```
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
a和b都是初始化為0,并且變量a在CPU 1的cache line中,變量b在CPU 0的cacheline中。
```
如果cpu執行上述代碼,那么第三行的assert不應該失敗,不過,如果CPU設計者使用上圖中的那個非常簡單的store buffer結構,那么你應該會遇到“驚喜”(assert失敗了)。具體的執行序列過程如下:
```
[1] CPU 0執行a=1的賦值操作, CPU 0遇到cache miss
[2] CPU 0發送read invalidate消息以便從CPU 1那里獲得數據,并invalid其他cpu保存a數據的local cache line。
[3] 由于store buff的存在,CPU 0把要寫入的數據“1”放入store buffer
[4] CPU 1收到read invalidate后回應,把本地cache line的數據發送給CPU 0并清空本地cache中a的數據。
[5] CPU 0執行b = a + 1
[6] CPU 0 收到來自CPU 1的數據,該數據是“0”
[7] CPU 0從cache line中加載a,獲得0值
[8] CPU 0將store buffer中的值寫入cache line,這時候cache中的a值是“1”
[9] CPU 0執行a+1,得到1并將該值寫入b
[10] CPU 0 executes assert(b == 2), which fails. OMG,你期望b等于2,但是實際上b等于了1
```
導致這個問題的根本原因是我們有兩個a值,一個在cache line中,一個在store buffer中。store buffer的引入,違反了每個CPU按照其視角來觀察自己的行為的時候必須是符合program order的原則。一旦違背這個原則,對軟件工程師而言就是災難。還好,有”好心“的硬件工程師幫助我們,修改了CPU的設計如下:
這種設計叫做store forwarding,當CPU執行load操作的時候,不但要看cache,還有看store buffer是否有內容,如果store buffer有該數據,那么就采用store buffer中的值。有了store forwarding的設計,上面的步驟[7]中就可以在store buffer獲取正確的a值是”1“而不是”0“,因此計算得到的b的結果就是2,和我們預期的一致了。
store forwarding解決了CPU 0的cache line和store buffer間的數據一致性問題,但是,在CPU 1的角度來看,是否也能看到一致的數據呢?我們來看下一個例子:
```
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
同樣的,a和b都是初始化成0.
```
我們假設CPU 0執行foo函數,CPU 1執行bar函數,a變量在CPU 1的cache中,b在CPU 0 cache中,執行的操作序列如下:
```
[1] CPU 0執行a=1的賦值操作,由于a不在local cache中,因此,CPU 0將a值放到store buffer中之后,發送了read invalidate命令到總線上去。
[2] CPU 1執行 while (b == 0) 循環,由于b不在CPU 1的cache中,因此,CPU發送一個read message到總線上,看看是否可以從其他cpu的local cache中或者memory中獲取數據。
[3] CPU 0繼續執行b=1的賦值語句,由于b就在自己的local cache中(cacheline處于modified狀態或者exclusive狀態),因此CPU0可以直接操作將新的值1寫入cache line。
[4] CPU 0收到了read message,將最新的b值”1“回送給CPU 1,同時將b cacheline的狀態設定為shared
[5] CPU 1收到了來自CPU 0的read response消息,將b變量的最新值”1“值寫入自己的cacheline,狀態修改為shared。
[6] 由于b值等于1了,因此CPU 1跳出while (b == 0)的循環,繼續前行。
[7] CPU 1執行assert(a == 1),這時候CPU 1的local cache中還是舊的a值,因此assert(a == 1)失敗。
[8] CPU 1收到了來自CPU 0的read invalidate消息,以a變量的值進行回應,同時清空自己的cacheline,但是這已經太晚了。
[9] CPU 0收到了read response和invalidate ack的消息之后,將store buffer中的a的最新值”1“數據寫入cacheline,然并卵,CPU 1已經assertion fail了。
```
CPU 1出現異常的assertion fail的根本原因是,CPU 0在發出read invalidate message后,并沒有等待CPU 1收到,就繼續執行將b改寫為1,也就是store buffer的存在導致了CPU 1先看到了b修改為1,后看到a被修改為1。遇到這樣的問題,CPU設計者也不能直接幫什么忙(除非去掉store buffer),畢竟CPU并不知道哪些變量有相關性,這些變量是如何相關的。不過CPU設計者可以間接提供一些工具讓軟件工程師來控制這些相關性。這些工具就是memory-barrier指令。要想程序正常運行,必須增加一些memory barrier的操作,具體如下:
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12}
```
smp_mb() 這個內存屏障的操作會在執行后續的store操作之前,首先flush store buffer(也就是將之前的值寫入到cacheline中)。達到這個目標有兩種方法:
```
[1] CPU遇到smp_mb內存屏障后,需要等待store buffer中的數據完成transaction并將strore buffer中的數據寫入cache line;
[2] CPU在遇到smp_mb內存屏障后,可以繼續前行,但是需要記錄一下store buffer中的數據順序,在store buffer中的數據嚴格按順序全部寫回cache line之前,其他數據不能先更新cache line,需要按照順序先寫到store buffer才能繼續前行。
```
通常采用的是方法[2],增加了smp_mb()后,執行序列如下:
```
[1] CPU 0執行a=1的賦值操作,由于a不在local cache中,因此,CPU 0將a值放到store buffer中之后,發送了read invalidate命令到總線上去。
[2] CPU 1執行 while (b == 0) 循環,由于b不在CPU 1的cache中,因此,CPU發送一個read message到總線上,看看是否可以從其他cpu的local cache中或者memory中獲取數據。
[3] CPU 0執行smp_mb()函數,給目前store buffer中的所有項做一個標記(后面我們稱之marked entries)。當然,針對我們這個例子,store buffer中只有一個marked entry就是“a=1”。
[4] CPU 0繼續執行b=1的賦值語句,雖然b就在自己的local cache中(cacheline處于modified狀態或者exclusive狀態),不過在store buffer中有marked entry,因此CPU 0不能直接操作將新的值1寫入cache line,取而代之是b的新值'1'被寫入store buffer(CPU 0也可以不執行b=1語句,等到a的transaction完成并寫回cache line,在執行b=1,將b的新值'1'寫入cache line),當然是unmarked狀態。
[5] CPU 0收到了read message,將b值”0“(新值”1“還在store buffer中)回送給CPU 1,同時將b cacheline的狀態設定為shared。
[6] CPU 1收到了來自CPU 0的read response消息,將b變量的值('0')寫入自己的cacheline,狀態修改為shared。
[7] 由于smp_mb內存屏障的存在,b的新值'1'隱藏在CPU 0的store buffer中,CPU 1只能看到b的舊值'0',這時CPU 1處于死循環中。
[8] CPU 1收到了來自CPU 0的read invalidate消息,以a變量的值進行回應,同時清空自己的cacheline。
[9] CPU 0收到CPU 1的響應msg,完成了a的賦值transaction,CPU 0將store buffer中的a值寫入cacheline,并且將cacheline狀態修改為modified狀態。
[10] 由于store buffer只有一項marked entry(對應a=1),因此,完成step 9之后,store buffer的b也可以進入cacheline了。不過需要注意的是,當前b對應的cache line的狀態是shared。
[11] CPU 0想將store buffer中的b的新值'1'寫回cache line。由于b的cache line是share的。CPU 0需要發送invalidate消息,請求b數據的獨占權。
[12] CPU 1收到invalidate消息,清空自己b的 cache line,并回送acknowledgement給CPU 0。
[13] CPU 1的某次循環執行到while (b == 0),這時發現b的cache line是Invalid的了,于是CPU 1發送read消息,請求獲取b的數據。
[14] CPU 0收到acknowledgement消息,將b對應的cache line修改成exclusive狀態,這時候,CPU 0終于可以將b的新值1寫入cache line了。
[15] CPU 0收到read消息,將b的新值1回送給CPU 1,同時將其local cache中b對應的cacheline狀態修改為shared。
[16] CPU 1獲取來自CPU 0的b的新值,將其放入cache line中。
[17] 由于b值等于1了,因此CPU 1跳出while (b == 0)的循環,繼續前行。
[18] CPU 1執行assert(a == 1),不過這時候a值沒有在自己的cache line中,因此需要通過cache一致性協議從CPU 0那里獲得,這時候獲取的是a的最新值,也就是1值,因此assert成功。
```
從上面的執行序列可以看出,在調用memory barrier指令之后,使得CPU 0遲遲不能將b的新值'1'寫回cache line,從而使得CPU 1一直不能觀察到b的新值'1',造成CPU 1一直不能繼續前行。直觀上CPU 0似乎不受什么影響,因為CPU 0可以繼續前行,只是將b的新值'1'寫到store buffer而不能寫回cache line。不幸的是:每個cpu的store buffer不能實現的太大,其entry的數目不會太多。當cpu 0以中等的頻率執行store操作的時候(假設所有的store操作導致了cache miss),store buffer會很快的被填滿。在這種狀況下,CPU 0只能又進入等待狀態,直到cache line完成invalidation和ack的交互之后,可以將store buffer的entry寫入cacheline,從而為新的store讓出空間之后,CPU 0才可以繼續執行。這種狀況恰恰在調用了memory barrier指令之后,更容易發生,因為一旦store buffer中的某個entry被標記了,那么隨后的store都必須等待invalidation完成,因此不管是否cache miss,這些store都必須進入store buffer,這樣就很容易塞滿store buffer。
6.2.4 Invalidate Queue
store buffer之所以很容易被填充滿,主要是其他CPU回應invalidate acknowledge比較慢,如果能夠加快這個過程,讓store buffer盡快進入cache line,那么也就不會那么容易填滿了。
invalidate acknowledge不能盡快回復的主要原因是invalidate cacheline的操作沒有那么快完成,特別是cache比較繁忙的時候,這時,CPU往往進行密集的loading和storing的操作,而來自其他CPU的,對本CPU local cacheline的操作需要和本CPU的密集的cache操作進行競爭,只要完成了invalidate操作之后,本CPU才會發生invalidate acknowledge。此外,如果短時間內收到大量的invalidate消息,CPU有可能跟不上處理,從而導致其他CPU不斷的等待。
要想達到快速回復acknowledgement,一個解決方法是,引入一個緩沖隊列,接收到invalidate請求,可以先將請求入隊緩沖隊列,就可以回復acknowledgement消息了,后面在異步完成invalidate操作。于是硬件工程師,引入一個invalidate queue,有invalidate queue的系統結構如下圖所示:
異步延后處理,也需要有個度才行。一旦將一個invalidate(例如針對變量a的cacheline)消息放入CPU的Invalidate Queue,實際上該CPU就等于作出這樣的承諾:在處理完該invalidate消息之前,不會發送任何相關(即針對變量a的cacheline)的MESI協議消息。為什么是在發出某個變量a的MESI協議消息的時候,需求去檢查invalidate queue看是否有變量a的invalidate消息呢?而不是在對該變量的任何操作都需要檢查以下invalidate queue呢?其實這樣在保證MESI協議正確性的情況下,進一步保證性能的折中方案。
因為,在單純考慮性能的情況下,少去檢查invalidate queue,周期性(一定時間,cpu沒那么繁忙、invalidate queue容量達到一定)批量處理invalidate queue中的消息,這樣性能能夠達到最佳。但是,這樣在某些情況下,使得MESI協議失效。例如:在一個4核的機器上,變量a初始值是'0',它cache在CPU 0和CPU 1的cache line中,狀態都是Share。
```
[1] CPU 0需要修改變量a的值為'1',CPU 0發送invalidate消息給其他CPU(1~3).
[2] 其他CPU(1~3)將invalidate消息放入invalidate queue,然后都回復給CPU 0.
[3] CPU 0收到響應后,將a的新值'1'寫入cache line并修改狀態為Modified。
[4] CPU 2需要讀取a的時候遇到cache miss,于是CPU 2發送read消息給其他CPU,請求獲取a的數據。
[5] CPU 1收到read請求,由于a在自己的cache line并且是share狀態的,于是CPU 1將a的invalid值'0'響應給CPU 2。
[6] CPU 2通過一個read消息獲取到一個過期的非法的值,這樣MESI協議無法保證數據一致性了。
```
于是,為了保證MESI協議的正確性,CPU在需要發出某個變量的a的MESI協議消息的時候,需要檢查invalidate queue中是否有該變量a的invalidate消息,如果有需要先出來完成這個invliadte消息后,才能發出正確的MESI協議消息。在合適的時候,發出正確的MESI協議是保證了不向其他CPU傳遞錯誤的信息,從而保證數據的一致性。但是,對于本CPU是否也可以高枕無憂呢?我們來看同上面一樣的一個例子:
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
```
在上面的代碼片段中,我們假設a和b初值是0,并且a在CPU 0和CPU 1都有緩存的副本,即a變量對應的CPU0和CPU 1的cacheline都是shared狀態。b處于exclusive或者modified狀態,被CPU 0獨占。我們假設CPU 0執行foo函數,CPU 1執行bar函數,執行序列如下:
```
[1] CPU 0執行a=1的賦值操作,由于a在CPU 0 local cache中的cacheline處于shared狀態,因此,CPU 0將a的新值“1”放入store buffer,并且發送了invalidate消息去清空CPU 1對應的cacheline。
[2] CPU 1執行while (b == 0)的循環操作,但是b沒有在local cache,因此發送read消息試圖獲取該值。
[3] CPU 1收到了CPU 0的invalidate消息,放入Invalidate Queue,并立刻回送Ack。
[4] CPU 0收到了CPU 1的invalidate ACK之后,即可以越過程序設定內存屏障(第四行代碼的smp_mb() ),這樣a的新值從store buffer進入cacheline,狀態變成Modified。
[5] CPU 0 越過memory barrier后繼續執行b=1的賦值操作,由于b值在CPU 0的local cache中,因此store操作完成并進入cache line。
[6] CPU 0收到了read消息后將b的最新值“1”回送給CPU 1,并修正該cache line為shared狀態。
[7] CPU 1收到read response,將b的最新值“1”加載到local cacheline。
[8] 對于CPU 1而言,b已經等于1了,因此跳出while (b == 0)的循環,繼續執行后續代碼
[9] CPU 1執行assert(a == 1),但是由于這時候CPU 1 cache的a值仍然是舊值0,因此assertion 失敗
[10] 該來總會來,Invalidate Queue中針對a cacheline的invalidate消息最終會被CPU 1執行,將a設定為無效,但,大錯已經釀成。
```
CPU 1出現assert失敗,是因為沒有及時處理invalidate queue中的a的invalidate消息,導致使用了本cache line中的一個已經是invalid的一個舊的值,這是典型的cache帶來的一致性問題。這個時候,我們也需要一個memory barrier指令來告訴CPU,這個時候應該需要處理invalidate queue中的消息了,否則可能會讀到一個invalid的舊值。
```
當CPU執行memory barrier指令的時候,對當前Invalidate Queue中的所有的entry進行標注,這些被標注的項被稱為marked entries,而隨后CPU執行的任何的load操作都需要等到Invalidate Queue中所有marked entries完成對cacheline的操作之后才能進行
```
因此,要想保證程序邏輯正確,我們需要給bar函數增加內存屏障的操作,具體如下:
```
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
```
bar()函數添加smp_mb內存屏障后,執行序列如下:
```
[1] ~ [8] 同上
[9] CPU 1遇到smp_mb內存屏障,發現下一條語句是load a,這個時候CPU 1不能繼續執行代碼,只能等待,直到Invalidate Queue中的message被處理完成
[10] CPU 1處理Invalidate Queue中緩存的Invalidate消息,將a對應的cacheline設置為無效。
[11] 由于a變量在local cache中無效,因此CPU 1在執行assert(a == 1)的時候需要發送一個read消息去獲取a值。
[12] CPU 0用a的新值1回應來自CPU 1的請求。
[13] CPU 1獲得了a的新值,并放入cacheline,這時候assert(a == 1)不會失敗了。
```
在我們上面的例子中,memory barrier指令對store buffer和invalidate queue都進行了標注,不過,在實際的代碼片段中,foo函數不需要mark invalidate queue,bar函數不需要mark store buffer。因此,許多CPU architecture提供了弱一點的memory barrier指令只mark其中之一。如果只mark invalidate queue,那么這種memory barrier被稱為read memory barrier。相應的,write memory barrier只mark store buffer。一個全功能的memory barrier會同時mark store buffer和invalidate queue。
我們一起來看看讀寫內存屏障的執行效果:對于read memory barrier指令,它只是約束執行CPU上的load操作的順序,具體的效果就是CPU一定是完成read memory barrier之前的load操作之后,才開始執行read memory barrier之后的load操作。read memory barrier指令象一道柵欄,嚴格區分了之前和之后的load操作。同樣的,write memory barrier指令,它只是約束執行CPU上的store操作的順序,具體的效果就是CPU一定是完成write memory barrier之前的store操作之后,才開始執行write memory barrier之后的store操作。全功能的memory barrier會同時約束load和store操作,當然只是對執行memory barrier的CPU有效。
現在,我們可以改一個用讀寫內存屏障的版本了,具體如下:
```
1 void foo(void)
2 {
3 a = 1;
4 smp_wmb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_rmb();
12 assert(a == 1);
13 }
```
可見,memory barrier需要成對使用才能保證程序的正確性。什么情況下使用memory barrier,使用怎樣的memory barrier,和CPU架構有那些相關性呢?
6.3 How Memory Barriers?
memory barrier的語義在不同CPU上是不同的,因此,想要實現一個可移植的memory barrier的代碼需要對形形×××的CPU上的memory barrier進行總結。幸運的是,無論哪一種cpu都遵守下面的規則:
```
[1]、從CPU自己的視角看,它自己的memory order是服從program order的
[2]、從包含所有cpu的sharebility domain的角度看,所有cpu對一個共享變量的訪問應該服從若干個全局存儲順序
[3]、memory barrier需要成對使用
[4]、memory barrier的操作是構建互斥鎖原語的基石
```
6.3.1 有條件的順序保證
要保證程序在多核CPU中執行服從program order,那么我們需要成對使用的memory barrier,然而成對的memory barrier并不能提供絕對的順序保證,只能提供有條件的順序保證。那么什么是有條件的順序保證?考慮下面一個訪問例子(這里的access可以是讀或寫):
從CPU1角度來看,對A的訪問總是先于對B的訪問。但是,關鍵的是從CPU2的角度來看,CPU1對A、B的訪問順序是否就一定是A優先于B呢?假如在CPU2感知CPU1對A的訪問結果的情況下,是否可以保證CPU2也能感知CPU1對B的訪問結果呢?這是不一定的,例如執行時序如下,那么顯然,在CPU2感知CPU1對A的訪問結果的情況下,是并不能感知CPU1對B的訪問結果(CPU2對A的訪問要早于CPU1對B的訪問)。
另外,如果CPU1對B的訪問結果已經被CPU2感知到了,那么,在這個條件下,CPU1對A的訪問結果就一定能夠被CPU2感知到。這就是觀察者(CPU2)在滿足一定條件下才能保證這個memory的訪問順序。
對于上面例子中的access操作,在內存上包括load和store兩種不同操作,下面列出了CPU1和CPU2不同的操作組合共16個,下面來詳細描述一下,在不同的操作組合下memory barrier可以做出怎樣的保證。

由于CPU架構千差萬別,上面的16種組合可以分成3類
```
[1] Portable Combinations -- 通殺所有CPU
[2] Semi-Portable Combinations -- 現代CPU可以work,但是不適應在比較舊的那些CPU
[3] Dubious Combinations -- 基本是不可移植的
```
6.3.1.1 通殺所有CPU
(1) Pairing 1
情況3,CPU執行代碼如下:(A和B的初值都是0)
| CPU1 | CPU2 |
| ------ | ------ |
| X = A; | B = 1; |
| smp_mb(); | smp_mb(); |
| Y = B; | A = 1; |
對于這種情況,兩個CPU都執行完上面的代碼后,如果X的值是1,那么我們可以斷定Y也是等于1的。也就是如果CPU1感知到了CPU2對A的訪問結果,那么可以斷定CPU1也必能感知CPU2對B的訪問結果。但是,如果X的值是0,那么memory barrier的條件不存在,于是Y的值可能是0也可能是1。
對于情況C,它是和情況1是對稱,于是結論也是類似的:(A和B的初值都是0)
同樣,兩個CPU都執行完上面的代碼后,如果Y的值是1,那么可以斷定X的值也是1。
(2) Pairing 2
情況5,CPU執行代碼如下:(A和B的初值都是0)
兩個CPU都執行完上面的代碼后,在不影響邏輯的情況下,在CPU2的A=1;前面插入代碼Z=X,根據情況C,如果Y的值是1,那么Z的值就一定是A,由于Z=X執行在A=1前面,那么Z的值是A的初始值0,于是X的值一定是0。同樣,如果X等于1,那么我們一定可以得到Y等于0;
(3) Pairing 3
情況7,CPU執行代碼如下:(A和B的初值都是0)
兩個CPU都執行完上面的代碼后,在不影響邏輯的情況下,在CPU1的B=1;前面插入代碼Z=B,根據情況3,如果X等于1,那么可以斷定Z等于2,也就是在CPU1執行完畢Z=B代碼前,B的值是2,由于CPU1在執行完Z=B后會執行B=1,于是對CPU1而已,最后B的值是1。
通過上面(1) ,如果CPU1執行的全是store操作,而CPU2執行的全是load操作(對稱下,CPU2執行的全是store操作,而CPU1執行的全是load操作),那么會有一個memory barrier條件使得執行得到一個確定的順序,并且是通吃所有CPU的。而,(2)和(3)經過插入代碼也可以轉換成(1)的情況。
情況D,CPU執行代碼如下:(A和B的初值都是0)
該情況是情況7是類似的。在Y等1的時候,最終A等于2.
6.3.1.2 現代CPU可以work,但是不適應在比較舊的那些CPU
(1) Ears to Mouths
情況A,CPU執行代碼如下:(A和B初值都是0,其他變量初始值是-1)
這種情況下,比較容易推算出X等1的時候,Y可能為0也可能為1,當X等于0的時候,也比較容易推算出Y值可以為1。但是,X等0的時候,Y有沒可能也是0呢?
我們通過插入代碼(Z=X),這樣就轉換成情況C,在X等于0,Z等于0的時候,那么memory barrier條件成立,于是Y必然等1。然而,如果X等于0的時候,Z不等于0,這個時候memory barrier條件就不能成立了,這個時候Y就可能為0。
下面我們來講下,上面情況下會出現X和Y同時為0。在一個有Invalidate queue和store buffer的系統中,B和X在CPU1的local cache中并且是獨占的,A和Y在CPU2的local cache中并且也是獨占的。CPUs的執行序列如下:
```
[1] CPU1對A發起store操作,由于A不在CPU1的cache中,CPU1發起invalidate message,當然,CPU1不會停下它的腳步,將A的新值'1'放入store buffer,它就繼續往下執行
[2] smp_mb使得CPU1對store buffer中的entry進行標注(當然也對Invalidate Queue進行標注,不過和本場景無關),store A的操作變成marked狀態
[3] CPU2對B發起store操作,由于B不在CPU2的cache中,CPU2發起invalidate message,當然,CPU2不會停下它的腳步,將B的新值'1'放入store buffer,它就繼續往下執行
[4] CPU2收到CPU1的invalidate message將該message放入Invalidate Queue后繼續前行。
[5] smp_mb使得CPU2對store buffer中的entry進行標注(當然也對Invalidate Queue進行標注),store B的操作變成marked狀態
[6] CPU1收到CPU2的invalidate message將該message放入Invalidate Queue后繼續前行。
[7] CPU1前行執行load B,由于B在CPU1的local cache獨占的(CPU1并不需要發送任何MESI協議消息,它并不需要立即處理Invalidate Queue里面的消息),于是CPU1從local cache中得到B的值'0',接著CPU1繼續執行store X,由于X也在CPU1的local cache獨占的,于是,CPU1將X的新值修改為B的值'0'并將其放入store buffer中。
[8] CPU2前行執行load A,由于A在CPU2的local cache獨占的(CPU2并不需要發送任何MESI協議消息,它并不需要立即處理Invalidate Queue里面的消息),于是CPU2從local cache中得到A的值'0',接著CPU2繼續執行store Y,由于Y也在CPU2的local cache獨占的,于是,CPU2將Y的新值修改為B的值'0'并將其放入store buffer中。
[9] CPU1開始處理Invalidate Queue里面的消息,將本local cache中的B置為Invalide,同時響應Invalidate response message給CPU2
[10] CPU2收到Invalidate response message后,這個時候可以將store buffer里面的B和Y寫回cache line,最后B為1,Y為0。
[11] CPU1和CPU2類似,最終A為1,X為0.
```
(2) Pass in the Night
情況F,CPU執行代碼如下:(A和B初值都是0,其他變量初始值是-1)
| CPU1 | CPU2 |
| ------ | ------ |
| A = 1; | B = 2;|
| smp_mb(); | smp_mb(); |
| B = 1; | A = 2; |
情況F,正常情況下,無論如何,但是無論如何,在兩個CPU都執行完上面的代碼之后{A==1,B==2} 這種情況不可能發生。不幸的是,在一些老的CPU架構上,是可能出現{A==1,B==2} 的,出現這種情況和上面的原因有點類似,下面也簡單描述一下,在一個有Invalidate queue和store buffer的系統中,B在CPU1的local cache中并且是獨占的,A在CPU2的local cache中并且也是獨占的。CPUs的執行序列如下:
```
[1]~[6]和 (1) Ears to Mouths中的基本一樣
[7] CPU1繼續前行,由于B在CPU1的local cache獨占的(CPU1并不需要發送任何MESI協議消息,它并不需要立即處理Invalidate Queue里面的消息),于是,CPU1將B的新值'1'放入store buffer中。
[8] CPU2繼續前行,由于A在CPU2的local cache獨占的(CPU1并不需要發送任何MESI協議消息,它并不需要立即處理Invalidate Queue里面的消息),于是,CPU2將A的新值'2'放入store buffer中。
[9] CPU1開始處理Invalidate Queue里面的消息,將本local cache中的B置為Invalide(這個時候store buffer里面B的新值'1'也被invalidate了),同時響應Invalidate response message給CPU2
[9] CPU2開始處理Invalidate Queue里面的消息,將本local cache中的置為Invalide(這個時候store buffer里面A的新值'2'也被invalidate了),同時響應Invalidate response message給CPU1
[10] CPU1收到Invalidate response message,這個時候可以將store buffer中的A=1刷到cache line,最終A的值為1
[11] CPU2收到Invalidate response message,這個時候可以將store buffer中的B=2刷到cache line,最終B的值為2
```
到這來,大家應該會發現,第一個賦值(對于CPU1而言是A = 1,對于CPU2而言是B = 2)其實是pass in the night,靜悄悄的走過,而第二個賦值(對于CPU1而言是B = 1,對于CPU2而言是A = 2)則會后發先至,最終導致第一個賦值先發而后至覆蓋第二個賦值。
其實,只要符合下面的使用模式,上面描述的操作順序(第二個store的結果被第一個store覆蓋)都是有可能發生的:
| CPU1 | CPU2 |
| ------ | ------ |
| A = 1; | B = 2;|
| smp_mb(); | smp_mb(); |
|xxxx; | xxxx; |
前面說的'ears to mouths'也是這種模式,不過,對于21世紀的硬件系統而言,硬件工程師已經幫忙解決了上面的問題,因此,軟件工程師可以安全的使用Stores “Pass in the Night”。
6.3.1.3 基本不可移植
剩下的情況0、1、2、4、6、8、9這7種情況的組合,即使是在21世紀的那些新的CPU硬件平臺上,也是不能夠保證是可移植的。當然,在一些硬件平臺上,我們還是可以得到一些確定的執行順序的。
(1) Ears to Ears
情況0,CPUs上全是load操作
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | load B;|
| smp_mb(); | smp_mb(); |
| load B; | load A; |
由于load操作不能改變memory的狀態,因此,一個CPU上的load是無法感知到另外一側CPU的load操作的。不過,如果CPU2上的load B操作返回的值比CPU 1上的load B返回的值新的話(即CPU2上load B晚于CPU1的load B執行),那么可以推斷CPU2的load A返回的值要么和CPU1上的load A返回值一樣新,要么加載更新的值。
(2) Mouth to Mouth, Ear to Ear
這個組合的特點是一個變量只是執行store操作,而另外一個變量只是進行load操作。執行序列如下:
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | store B;|
| smp_mb(); | smp_mb(); |
| store B; | load A; |
這種情況下,如果CPU2上的store B最后發生(也就是,上面代碼執行完畢后,在執行一次load B得到的值是CPU2 store B的值),那么可以推斷CPU2的load A返回的值要么和CPU1上的load A返回值一樣新,要么加載更新的值。
(3) Only One Store
| CPU1 | CPU2 |
| ------ | ------ |
| load A; | load B;|
| smp_mb(); | smp_mb(); |
| load B; | store A; |
這種情況下,只有一個變量的store操作可以被另外的CPU上的load操作觀察到,如果在CPU1上運行的load A感知到了在CPU2上對A的賦值,那么,CPU1上的load B必然能觀察到和CPU2上load B一樣的值或者更新的值。
6.3.2 memory barrier內存屏障類型
6.3.2.1 顯式內存屏障
6.3.1章節列舉的16種情況的例子中內存屏障smp_mb()指的是一種全功能內存屏障(General memory barrier),然而全功能的內存屏障對性能的殺傷較大,某些情況下我們可以使用一些弱一點的內存屏障。在有Invalidate queue和store buffer的系統中,全功能的內存屏障既會mark store buffer也會mark invalidate queue,對于情況3,CPU1全是load它只需要mark invalidate queue即可,相反CPU2全是store,它只需mark store buffer即可,于是CPU1只需要使用讀內存屏障(Read memory barrier),CPU2只需使用寫內存屏障(Write memory barrier)。
情況3,修改如下
| CPU1 | CPU2 |
| ------ | ------ |
| X = A; | B = 1; |
| read_mb(); | write_mb(); |
| Y = B; | A = 1; |
到這來,我們知道有3種不同的內存屏障,還沒有其他的呢?我們來看一個例子:
初始化
int A = 1;
int B = 2;
int C = 3;
int *P = &A;
int *Q = &B;
通常情況下,Q最后要么等于&A,要么等于&B。也就是說:Q == &A, D == 1 或者 Q == &B, D == 4,絕對不會出現Q == &B, D == 2的情形。然而,讓人吃驚的是,DEC Alpha下,就可能出現Q == &B, D == 2的情形。
于是,在DEC Alpha下,CPU2上的Q=P下面需要插入一個memory barrier來保證程序順序,這來用一個讀內存屏障(read_mb)即可,但是我們發現CPU2上的Q = P和D = *Q是一個數據依賴關系,是否可以引入一個更為輕量的內存屏障來解決呢?
于是這里引入一種內存屏障-數據依賴內存屏障dd_mb(data dependency memory barrier),dd_mb是一種比read_mb要弱一些的內存屏障(這里的弱是指對性能的殺傷力要弱一些)。read_mb適用所有的load操作,而ddmb要求load之間有依賴關系,即第二個load操作依賴第一個load操作的執行結果(例如:先load地址,然后load該地址的內容)。ddmb被用來保證這樣的操作順序:在執行第一個load A操作的時候(A是一個地址變量),務必保證A指向的數據已經更新。只有保證了這樣的操作順序,在第二load操作的時候才能獲取A地址上保存的新值。
在純粹的數據依賴關系下使用數據依賴內存屏障dd_mb來保證順序,但是如果加入了控制依賴,那么僅僅使用dd_mb是不夠的,需要使用read_mb,看下面例子:
由于加入了條件if (t)依賴,這就不是真正的數據依賴了,在這種情況下,CPU會進行分支預測,可能會"抄近路"先去執行*Q的load操作,在這種情況下,需要將data_dependency_mb改成read_mb。
到這來,我們知道有4中不同的內存屏障種類:
```
[1] Write (or store) memory barriers -- 寫內存屏障
[2] Data dependency barriers -- 數據依賴內存屏障
[3] Read (or load) memory barriers -- 讀內存屏障
[4] General memory barriers -- 全功能內存屏障
```
6.3.2.2 隱式內存屏障
有些操作可以隱含memory barrier的功能,主要有兩種類型的操作:一是加鎖操作,另外一個是釋放鎖的操作。
```
[1] LOCK operations -- 加鎖操作
[2] UNLOCK operations -- 釋放鎖操作
```
(1) 加鎖操作被認為是一種half memory barrier,加鎖操作之前的內存訪問可以任意***過加鎖操作,在其他執行,但是,另外一個方向絕對是不允許的:即加鎖操作之后的內存訪問操作,必須在加鎖操作之后完成。
(2) 和lock操作一樣,unlock也是half memory barrier。它確保在unlock操作之前的內存操作先于unlock操作完成,也就是說unlock之前的操作絕對不能越過unlock這個籬笆,在其后執行。當然,另外一個方向是OK的,也就是說,unlock之后的內存操作可以在unlock操作之前完成。
我們看下面一個例子:
```
1 *A = a;
2 LOCK
3 C = 1;
4 UNLOCK
5 *B = b;
```
上面的程序有可能按照下面的順序執行:
```
2 LOCK
3 C = 1;
5 *B = b;
1 *A = a;
4 UNLOCK
```
通過上面,我們得知,經LOCK-UNLOCK對不能實現完全的內存屏障的功能,但是,它們也的確會影響內存訪問順序,參考下面的例子:
多個CPU對一把鎖操作的場景:
這種情況下,CPU1或者CPU2,只能有一個進入臨界區,如果是CPU1進入臨界區的話,對A B C的賦值操作,必然在對F G H變量賦值之前完成。如果CPU2進入臨界區的話,對E F G的賦值操作,必然在對B C D變量賦值之前完成。
6.3.3 C++11 memory order
要編寫出正確的lock free多線程程序,我們需要在正確的位置上插入合適的memory barrier代碼,然而不同CPU架構對于的memory barrier指令千差萬別,要寫出可移植的C++程序,我們需要一個語言層面的Memory Order規范,以便編譯器可以根據不同CPU架構插入不同的memory barrier指令,或者并不需要插入額外的memory barrier指令。
有了這個Memory Order規范,我們可以在high level language層面實現對在多處理器中多線程共享內存交互的次序控制,而不用考慮compiler,CPU arch的不同對多線程編程的影響了。
C++11提供6種可以應用于原子變量的內存順序:
```
[1] memory_order_relaxed
[2] memory_order_consume
[3] memory_order_acquire
[4] memory_order_release
[5] memory_order_acq_rel
[6] memory_order_seq_cst
```
上面6種內存順序描述了三種內存模型(memory model):
```
[1] sequential consistent(memory_order_seq_cst)
[2] relaxed(momory_order_relaxed)
[3] acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel)
```
6.3.3.1 C++11中的各種關系
C++11引入上面6種內存順序本質上是為了解決"visible side-effects"的問題,也就是讀操作的返回值問題,通俗來講:
```
線程1執行寫操作A之后,如何可靠并高效地保證線程2執行的讀操作B,load A的結果是完整可見的?
```
為了解決"visible side-effects"這個問題,C++11引入"happens-before"關系,其定義如下:
```
Let A and B represent operations performed by a multithreaded process. If A happens-before B, then the memory effects of A effectively become visible to the thread performing B before B is performed.
```
OK,現在問題就轉化為:如何在A、B兩個操作之間建立起happens-before關系。在推導happens-before關系前,我們先描述下面幾個關系:
6.3.3.1.1 Sequenced-before 關系
定義如下:
```
Sequenced before is an asymmetric, transitive, pair-wise relation between evaluations executed by a single thread, which induces a partial order among those evaluations.
```
Sequenced-before是在同一個線程內,對求值順序關系的描述,它是非對稱的,可傳遞的關系。
```
[1] 如果A is sequenced-before B,代表A的求值會先完成,才進行對B的求值
[2] 如果A is not sequenced before B 而且 B is sequenced before A,代表B的求值會先完成,才開始對A的求值。
[3] 如果A is not sequenced before B 而且 B is not sequenced before A,這樣求值順序是不確定的,可能A先于B,也可能B先于A,也可能兩種求值重疊。
```
6.3.3.1.2 Carries a dependency 關系
定義如下:
```
Within the same thread, evaluation A that is sequenced-before evaluation B may also carry a dependency into B (that is, B depends on A), if any of the following is true
1) The value of A is used as an operand of B, except
a) if B is a call to std::kill_dependency
b) if A is the left operand of the built-in &&, ||, ?:, or , operators.
2) A writes to a scalar object M, B reads from M
3) A carries dependency into another evaluation X, and X carries dependency into B
```
簡單來講,carries-a-dependency-to 嚴格應用于單個線程,建立了 操作間的數據依賴模型:如果操作 A 的結果被操作 B 作為操作數,那么 A carries-a-dependency-to B(一個直觀的例子:B=M[A] ), carries a dependency具有傳遞性。
######6.3.3.1.3 Dependency-ordered before 關系
該關系描述的是線程間的兩個操作間的關系,定義如下:
```
Between threads, evaluation A is dependency-ordered before evaluation B if any of the following is true
1) A performs a release operation on some atomic M, and, in a different thread, B performs a consume operation on the same atomic M, and B reads a value written by any part of the release sequence headed by A.
2) A is dependency-ordered before X and X carries a dependency into B.
```
case 1指的是:線程1的操作A對變量M執行“release”寫,線程2的操作B對變量M執行“consume”讀,并且操作B讀取到的值源于操作A之后的“release”寫序列中的任何一個(包括操作A本身)。
case 2描述的是一種傳遞性。
6.3.3.1.4 Synchronized-with 關系
定義如下:
```
An atomic operation A that performs a release operation on an atomic object M synchronizes withan atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
```
該關系描述的是,對于在變量 x 上的寫操作 W(x) synchronized-with 在該變量上的讀操作 R(x), 這個讀操作欲讀取的值是 W(x) 或同一線程隨后的在 x 上的寫操作 W’,或任意線程一系列的在 x 上的 read-modify-write 操作(如 fetch_add()或
compare_exchange_weak())而這一系列操作最初讀到 x 的值是 W(x) 寫入的值。
例如:A Write-Release Can Synchronize-With a Read-Acquire,簡單來說, 線程1的A操作寫了變量x,線程2的B操作讀了變量x,B讀到的是A寫入的值或者更新的值,那么A, B 間存在 synchronized-with 關系。
6.3.3.1.5 Inter-thread happens-before 關系
定義如下:
```
Between threads, evaluation A inter-thread happens before evaluation B if any of the following is true
1) A synchronizes-with B
2) A is dependency-ordered before B
3) A synchronizes-with some evaluation X, and X is sequenced-before B
4) A is sequenced-before some evaluation X, and X inter-thread happens-before B
5) A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
```
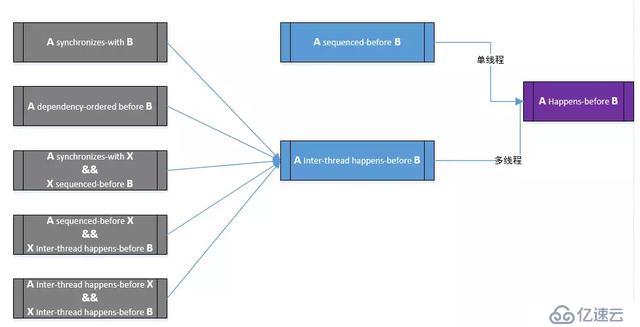
Inter-thread happens-before 關系具有傳遞性。該關系描述的是,如果A inter-thread happens-before B,則線程1的A操作對memory的訪問結果,會在線程2的B操作執行前對線程2是可見的。
######6.3.3.1.6 Happens-before 關系
定義如下:
```
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true:
1) A is sequenced-before B
2) A inter-thread happens before B
```
Happens-before 指明了哪些指令將看到哪些指令的結果。
對于單線程,sequenced-before關系即是Happens-before 關系,表明了操作 A 排列在另一個操作 B 之前。
對于多線程,則inter-thread happens before關系即是Happens-before 關系。
Happens-before 關系推導圖總結如下:
6.3.3.2 6種memory order描述
下面我們分別來解析一下上面說的6種memory order的作用以及用法。
6.3.3.2.1 順序一致次序 - memory_order_seq_cst
SC是C++11中原子變量的默認內存序,它意味著將程序看做是一個簡單的序列。如果對于一個原子變量的操作都是順序一致的,那么多線程程序的行為就像是這些操作都以一種特定順序被單線程程序執行。
從同步的角度來看,一個順序一致的 store 操作 synchroniezd-with 一個順序一致的需要讀取相同的變量的 load 操作。除此以外,順序模型還保證了在 load 之后執行的順序一致原子操作都得表現得在 store 之后完成。
順序一致次序對內存序要求比較嚴格,對性能的損傷比較大。
6.3.3.2.2 松弛次序 - memory_order_relaxed
在原子變量上采用 relaxed ordering 的操作不參與 synchronized-with 關系。在同一線程內對同一變量的操作仍保持happens-before關系,但這與別的線程無關。在 relaxed ordering 中唯一的要求是在同一線程中,對同一原子變量的訪問不可以被重排。
我們看下面的代碼片段,x和y初始值都是0
```
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
```
由于標記為memory_order_relaxed的atomic操作對于memory order幾乎不作保證,那么最終可能輸出r1 == r2 == 42,造成這種情況可能是編譯器對指令的重排,導致在線程2中D操作先于C操作完成。
Relaxed ordering比較適用于“計數器”一類的原子變量,不在意memory order的場景。
6.3.3.2.3 獲取-釋放次序 --memory_order_release, memory_order_acquire, memory_order_acq_rel
Acquire-release 中沒有全序關系,但它供了一些同步方法。在這種序列模型下,原子 load 操作是 acquire 操作(memory_order_acquire),原子 store 操作是release操作(memory_order_release), 原子read_modify_write操作(如fetch_add(),exchange())可以是 acquire, release 或兩者皆是(memory_order_acq_rel)。同步是成對出現的,它出現在一個進行 release 操作和一個進行 acquire 操作的線程間。一個 release 操作 syncrhonized-with 一個想要讀取剛才被寫的值的 acquire 操作。
也就是,如果在線程1中,操作A對原子M使用memory_order_release來進行atomic store,而在另外一個線程2中,操作B對同一個原子變量M使用memory_order_acquire來進行atomic load,那么線程1在操作A之前的所有寫操作(包括操作A),都會在線程2完成操作B后是可見的。
我們看下面一個例子:
```
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello");//A
data = 42;//B
ptr.store(p, std::memory_order_release);//C
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))//D
;
assert(*p2 == "Hello"); //E
assert(data == 42); //F
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
```
首先,我們可以直觀地得出如下關系:A sequenced-before B sequenced-before C、C synchronizes-with D、D sequenced-before E sequenced-before F。利用前述happens-before推導圖,不難得出A happens-before E、B happens-before F,因此,這里的E、F兩處的assert永遠不會fail。
6.3.3.2.4 數據依賴次序 memory_order_consume
memory_order_consume是輕量級的memory_order_acquire,是 memory_order_acquire 內存序的特例:它將同步數據限定為具有直接依賴的數據。能夠用memory_order_consume的場景下就一定能夠使用memory_order_acquire,引入memory_order_consume的目的是為了在一些已知的PowerPC和ARM等weakly-ordered CPUs上,對于在對有數據依賴的數據進行同步的時候不要插入額外memory barrier,因為它們本身就能保證在有數據依賴的情況下機器指令的內存順序,少了額外的memory barrier對性能提升還是比較大的。
memory_order_consume描述的是dependency-ordered-before關系。我們看上面的例子,把D中memory_order_acquire改成memory_order_consume會怎樣呢?
這個時候,由于p2和ptr有數據依賴,上面例子基本的關系對是:A sequenced-before B sequenced-before C、C dependency-ordered before D、D carries a dependency into E, E sequenced-before F。
根據關系推導,由C dependency-ordered before D && D carries a dependency into E得到C dependency-ordered before E,進一步得到C Inter-thread happens-before E,繼而A sequenced-before C && C Inter-thread happens-before E得到A Inter-thread happens-before E,于是得到A Happens-before E,E永遠不會assert fail。對于F,由于D、F間不存在 carries a dependency關系,那么F的assert是可能fail的。
通常情況下,我們可以通過源碼的小調整實現從Release-Acquire ordering到Release-Consume ordering的轉換,下面是一個
例子:

7. 總結
本文通過一個無鎖隊列為引子,介紹了無鎖編程涉及的6個技術要點,其中內存屏障是最為關鍵,使用什么樣的memory barrier,什么時候使用memory barrier又是其中的重中之重。memory barrier不容易理解,要想正確高效地使用memory barrier就更難了,通常情況下,能不直接用memory barrier原語就不用,最好使用鎖(互斥量)等互斥原語這樣的隱含了memory barrier功能的原語。鎖在在很長一段時間都被誤解了,認為鎖是慢的,由于鎖的引入,給性能帶來巨大的瓶頸是很常見的。但這并不意味著所有的鎖都是緩慢的,當我們使用輕量級鎖并控制好鎖競爭的時候,鎖依然有非常出色的性能表現,鎖不慢,鎖競爭慢。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





