溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么用Python連接所有數據庫做數據分析”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么用Python連接所有數據庫做數據分析”吧!
對于大部分sqlboys和sqlgirls而言,只關心我的sql提交到以上數據庫,返回給我一個pandas的dataframe即可。所以必要的輸入包括sql和數據庫連接信息(包括地址,port, 賬號密碼)即可。
from sqlachemy import create_engine import pandas as pd # 數據庫連接地址 engine = create_engine("mysql://root:123456@127.0.0.1:3306/database") # 用戶要查詢的sql sql = "select * from users limit 10" df = pd.read_sql_query(sql, engine)# presto uri = "presto://username:password@127.0.0.1:8080/database?source=pyhive" sql = "select * from users limit 10" df = pd.read_sql_query(sql, create_engine(uri))
# mysql uri = "mysql://root:123456@127.0.0.1:3306/database" sql = "select * from users limit 10" df = pd.read_sql_query(sql, create_engine(uri))
# druid uri = "druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql" sql = "select count(*) from users where _time> TIME_SHIFT...." df = pd.read_sql_query(sql, create_engine(uri))
更多數據庫連接方式:
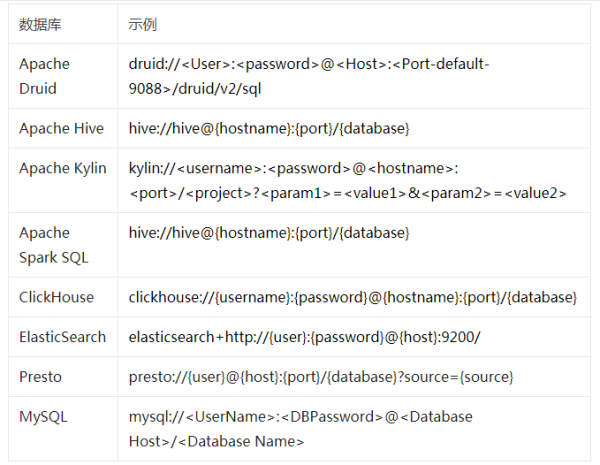
基本上市面上所有的數據庫,只要該數據庫支持sqlalchemy dialect和對應的python driver,都可以按照上面的套路去無腦操作。簡單省心。
核心只需要一行代碼即可:
df = pd.read_sql_query(sql, create_engine(uri))
到此,相信大家對“怎么用Python連接所有數據庫做數據分析”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





