溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何實現K8s集群架構與高可用解析,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
基本工作過程
Kubernetes 的核心工作過程:
資源對象:Node、Pod、Service、Replication Controller 等都可以看作一種資源對象
操作:通過使用 kubectl 工具,執行增刪改查
存儲:對象的目標狀態(預設狀態),保存在 etcd 中持久化儲存;
自動控制:跟蹤、對比 etcd 中存儲的目標狀態與資源的當前狀態,對差異資源糾偏,自動控制集群狀態。
Kubernetes 實際是:高度自動化的資源控制系統,將其管理的一切抽象為資源對象,大到服務器 Node 節點,小到服務實例 Pod。
Kubernetes 的資源控制是一種聲明+引擎的理念:
聲明:對某種資源,聲明他的目標狀態
自動:Kubernetes 自動化資源控制系統,會一直努力將該資源對象維持在目標狀態。
架構(物理+邏輯)
Kubernetes 集群,是主從架構:
Master:管理節點,集群的控制和調度
Node:工作節點,執行具體的業務容器
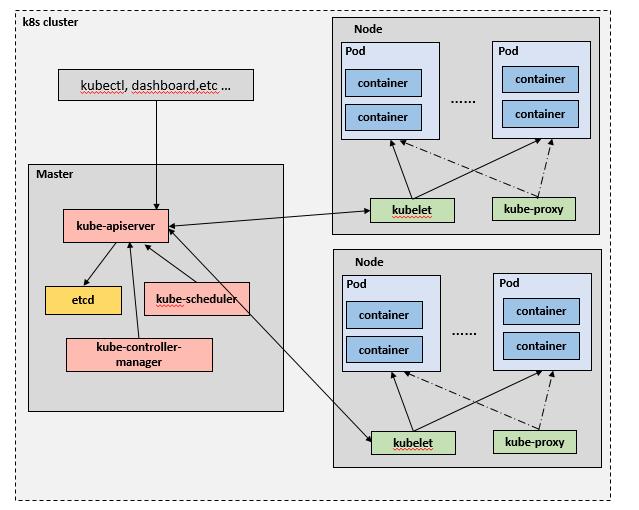
下述幾個組件,都是獨立的進程,每個進程都是 Go 語言編寫,實際部署 Kubernetes 集群,就是部署這些程序。
Master節點:
kube-apiserver
kube-controller-manager
kube-scheduler
Node節點:
kubelet
kube-proxy
具體,2 種角色的節點,需要運行的進程和職責不同,詳細描述如下。
Master 管理節點:管理整個 Kubernetes 集群,接收外部命令,維護集群狀態。
apiserver: Kubernetes API Server
集群控制的入口
資源的增刪改查,持久化存儲到 etcd
kubectl 直接與 API Server 交互,默認端口 6443。
etcd: 一個高可用的 key-value 存儲系統
作用:存儲資源的狀態
支持 Restful 的API。
默認監聽 2379 和 2380 端口(2379提供服務,2380用于集群節點通信)(疑問:集群節點,是說 etcd 的集群? Master 集群?)
scheduler: 負責將 pod 資源調度到合適的 node 上。
調度算法:根據 node 節點的性能、負載、數據位置等,進行調度。
默認監聽 10251 端口。
controller-manager: 所有資源的自動化控制中心
每個資源,都對應有一個控制器(疑問:作用是什么?)
controller manager 管理這些控制器
controller manager 是自動化的循環控制器
Kubernetes 的核心控制守護進程,默認監聽10252端口。(疑問:為什么有監聽段口感?)
補充說明:
scheduler和controller-manager都是通過apiserver從etcd中獲取各種資源的狀態,進行相應的調度和控制操作。
Node 節點:Master 節點,將任務調度到 Node 節點,以 docker 方式運行;當 Node 節點宕機時,Master 會自動將 Node 上的任務調度到其他 Node 上。
kubelet: 本節點Pod的生命周期管理,定期向Master上報本節點及Pod的基本信息
Kubelet是在每個Node節點上運行agent
負責維護和管理所有容器:從 apiserver 接收 Pod 的創建請求,啟動和停止Pod
Kubelet不會管理不是由Kubernetes創建的容器
定期向Master上報信息,如操作系統、Docker版本、CPU、內存、pod 運行狀態等信息
kube-proxy:集群中 Service 的通信以及負載均衡
功能:服務發現、反向代理。
反向代理:支持TCP和UDP連接轉發,默認基于Round Robin算法將客戶端流量轉發到與service對應的一組后端pod。
服務發現:使用 etcd 的 watch 機制,監控集群中service和endpoint對象數據的動態變化,并且維護一個service到endpoint的映射關系。(本質是:路由關系)
實現方式:存在兩種實現方式,userspace 和 iptables。
userspace:在用戶空間,通過kuber-proxy實現負載均衡的代理服務,是最初的實現方案,較穩定、效率不高;
iptables:在內核空間,是純采用iptables來實現LB,是Kubernetes目前默認的方式;
runtime:一般使用 docker 容器,也支持其他的容器。
集群的高可用
Kubernetes 集群,在生產環境,必須實現高可用:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
實現Master節點及其核心組件的高可用;
如果Master節點出現問題的話,那整個集群就失去了控制;
具體的 HA 示意圖:
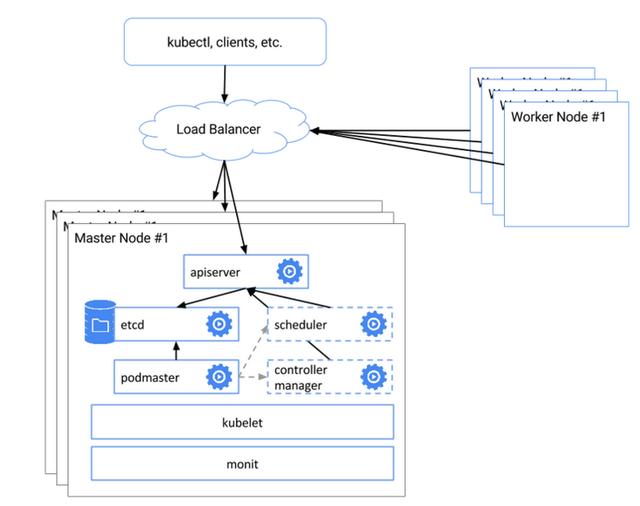
上述方式可以用作 HA,但仍未成熟,據了解,未來會更新升級 HA 的功能.
具體工作原理:
etcd 集群:部署了3個Master節點,每個Master節點的etcd組成集群
入口集群:3個Master節點上的APIServer的前面放一個負載均衡器,工作節點和客戶端通過這個負載均衡和APIServer進行通信
pod-master保證僅是主master可用,scheduler、controller-manager 在集群中多個實例只有一個工作,其他為備用
關于如何實現K8s集群架構與高可用解析就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





