溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Rust中怎么重構業務架構,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
概述
案例涉及的是一個企業的業務監控系統,該系統用來以幫助開發人員監控業務API。當客戶的應用程序調用API時,會向系統發送日志,系統對發送的日志中進行監控和分析。
系統數據流為平均每分鐘處理30k 的API調用。每個客戶都會進行很多個API的調用。系統的處理分為兩個關鍵部分:日志提取和日志處理。
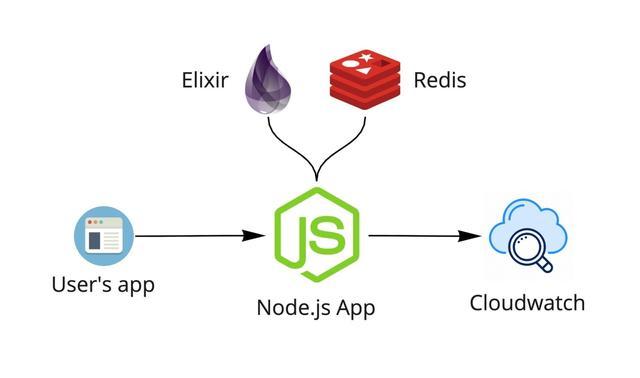
起初的系統中是通過Node.js構建提取服務。Node.js接收日志,與elixir服務進行通信檢查用戶的訪問權限,用Redis檢查速率限制,然后將日志發送到CloudWatch。CloudWatch部署了觸發器,觸發事件通知數據處理程序處理。
系統提取有關API調用的信息,包括從用戶應用程序發送的每個調用的有效負載(請求和響應)。這些文件的大小被限制為1MB,但是仍然涉及大量的數據需要處理。處理程序以異步的形式發送和處理所有內容,目標是使信息盡快提供給最終用戶。
所有內容都托管在亞馬遜云AWS Fargate上,并對其設置為在4000 req/min閾值觸發自動縮放。
整個流程都運行的很好,但是費用卻非常昂貴。由于AWS是按照CloudWatch存儲的使用來收費的,存儲的越多,需要支付的費用就越多。
為了解決費用的問題,于是就有一個救援計劃。
Kinesis救援和災難
為了解決昂貴的CloudWatch存儲費用問題,在將日志傳送到CloudWatch之前,使用了Kinesis Firehose前置處理。Kinesis Firehose可能熟悉少,但是知道kafka的人可能多,那么Kinesis Firehose就是AWS云中的Kafka。使用Kinesis Firehose前置處理,可以用可靠的方式將數據流傳遞到多個目的地。只需對日志處理程序進行很少的更新,就可以從CloudWatch和Kinesis Firehose提取日志。通過該架構的更改,可以將日成本下降到之前的千分之六。

新架構中系統將日志數據通過Kinesis傳遞到s3中,從而觸發日志處理程序。新架構運行后,一切都ok。但是過幾天出現了異常。。。監控儀表板上的一些異常情況。系統在收集垃圾,很多垃圾!
垃圾回收(GC)是某些編程語言自動釋放不再使用內存的一種方式。發生這種情況時,程序將會暫停。這稱為GC暫停。對內存進行的寫操作越多,需要進行的垃圾回收就越多,因此暫停時間會增加。對于系統服務,這些暫停的速度越來越快,足以導致服務器重新啟動并給CPU造成壓力。發生這種情況時,它看起來就像是服務器已關閉(因為它暫時處于關閉狀態),并且在客戶端會有大量的5xx錯誤,而代理所嘗試提取的日志中大約有6%出現了這個錯誤。
下面圖顯示了垃圾回收的暫停時間和暫停頻率:
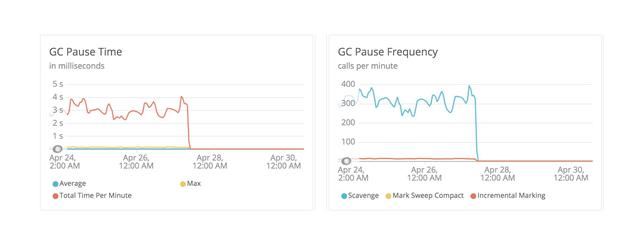
在某些情況下,暫停時間超過了4秒(如左圖所示),并且每分鐘最多有400次暫停(如右圖所示)。
經過更多研究分析后,似乎成為AWS Javascript SDK中內存泄漏的導致的該問題的發生。嘗試將資源分配增加到極限,例如減小縮放閾值到1000 req/min自動縮放,但是沒有問題仍沒有解決。
可能的解決方案
由于不能能使用上面的kninesis方案,因此需要新的解決方案來解決問題。可選的方案有以下幾種。
Elixir
如前的架構介紹,系統使用Elixir服務檢查客戶訪問權限。該服務是私有的,只能從虛擬私有云(VPC)中訪問。由于從未遇到過該服務的任何可擴展性問題,并且大多數邏輯已經存在。所以可選擇簡單地從該服務中將日志發送到Kinesis,而跳過Node.js服務層。這是一個值得嘗試的方案。
做了一番改進后,系統進行了測試。效果會好一點,但仍然不是很佳。系統的基準測試表明,GC垃圾收集的水平仍然很高,并且在使用日志時仍會有5xx的日志返回給用戶。
Golang
系統也考慮到Golang。這是一個很好的選擇方案,但是,畢竟Golang也是一種垃圾收集語言。雖然可能可以實現比上述更高效,但隨著規模的擴展,很可能還會遇到類似的問題。考慮到這些限制,系統需要一個更好的選擇。
以Rust為核心進行重新架構
在系統最初的實現和備份中,核心問題都是相同的:垃圾回收。解決方案是使用一種具有內存管理更好的并且沒有垃圾回收的語言。那么可選擇的語言就到了Rust。
Rust
Rust不是垃圾收集的語言。Rust依賴于稱為變量生命周期和所有權的概念。所有權是Rust的最獨特功能,它使Rust無需垃圾收集器即可保證內存安全。
所有權是一個經常使Rust難以學習和編寫的概念,但又使它非常適合像這個項目遇到的情況。Rust中的每個值都有一個所有者變量,因此在內存中有一個分配點。一旦該變量超出范圍,內存將會立即釋放。
由于提取日志所需的代碼很小,應該非常值得嘗試。為了對此進行測試,通過問題的瓶頸:向Kinesis發送大量數據。第一個基準測試非常成功。
所以Rust最終成了救世主,最后決定將原型充實并在生產系統的部署。
在這些實驗過程中,并沒有直接使用Rust直接替換原始的Node.js服務,而是重構了日志提取的大部分架構。新服務的核心是通過Envoy代理,在其中Rust應用程序作為輔助工具。
新架構流程
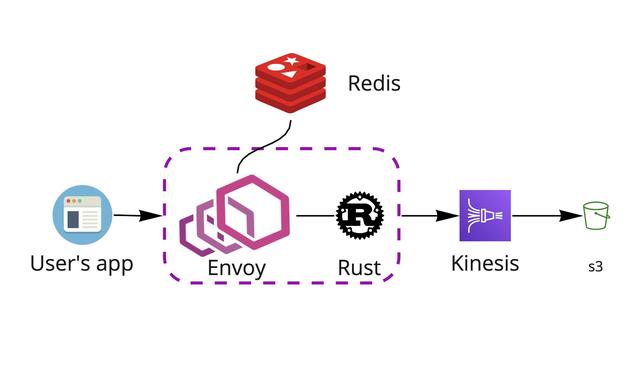
當用戶應用程序中Agent將日志數據發送到系統時,它將首先進入Envoy代理。Envoy查看請求并與Redis通信以檢查速率限制,授權詳細信息和使用配額之類的內容。接下來,與Envoy一起運行的Rust應用程序準備日志數據,并將其通過Kinesis傳遞到s3存儲桶中進行存儲。然后,S3觸發日志處理程序處理,Elastic Search開始對其進行索引。這樣,最終用戶就可以訪問儀表板中的數據。
性能和資源對比
新架構中使用了更少(更小)的服務器,但是可以處理更多數據,而不會出現任何之前的gc 5xx問題。
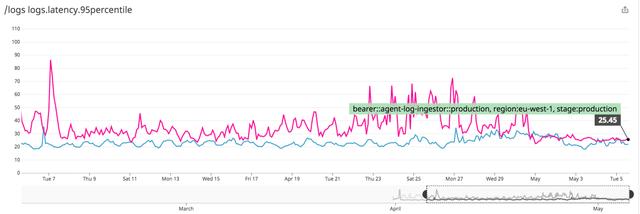
對比新舊架構的服務延遲。在舊的Node.js架構下服務的延遲數如下圖,可以看到平均響應時間接近1700ms的峰值:
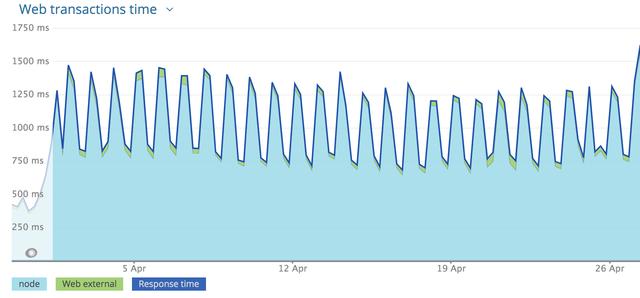
通過Rust服務的實施,新架構中,即使在最高峰期間,延遲也降至90ms以下,平均響應時間保持在40ms以下。
舊架構下Node.js應用程序在任何給定時間都會使用約1.5GB的內存,CPU的負載約為150%。
新架構下Rust服務使用了大約100MB的內存,而僅占用了2.5%的CPU負載。
關于Rust中怎么重構業務架構就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





