溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹怎么利用Python爬取了運維招聘信息,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
對于本文的敘述,我們分以下三步為大家講解。
爬蟲部分
數據清洗
數據可視化及分析
本文主要爬取的是 51job 上面,關于運維相關崗位的數據,網站解析主要使用的是Xpath,數據清洗用的是 Pandas 庫,而可視化主要使用的是 Pyecharts 庫。
相關注釋均已在代碼中注明,為方便閱讀,這里只展示部分代碼,完整代碼可查看文末部分進行獲取。
# 1、崗位名稱 job_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@title') # 2、公司名稱 company_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t2"]/a[@target="_blank"]/@title') # 3、工作地點 address = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t3"]/text()') # 4、工資 salary_mid = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t4"]') salary = [i.text for i in salary_mid] # 5、發布日期 release_time = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t5"]/text()') # 6、獲取二級網址url deep_url = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@href') # 7、爬取經驗、學歷信息,先合在一個字段里面,以后再做數據清洗。命名為random_all random_all = dom_test.xpath('//div[@class="tHeader tHjob"]//div[@class="cn"]/p[@class="msg ltype"]/text()') # 8、崗位描述信息 job_describe = dom_test.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/p/text()') # 9、公司類型 company_type = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[1]/@title') # 10、公司規模(人數) company_size = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[2]/@title') # 11、所屬行業(公司) industry = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[3]/@title')1)讀取數據
# 下面使用到的相關庫,在這里展示一下 import pandas as pd import numpy as np import re import jieba df = pd.read_csv("only_yun_wei.csv",encoding="gbk",header=None) df.head()2)為數據設置新的行、列索引
# 為數據框指定行索引 df.index = range(len(df)) # 為數據框指定列索引 df.columns = ["崗位名","公司名","工作地點","工資","發布日期","經驗與學歷","公司類型","公司規模","行業","工作描述"] df.head()
3)去重處理
# 去重之前的記錄數 print("去重之前的記錄數",df.shape) # 記錄去重 df.drop_duplicates(subset=["公司名","崗位名","工作地點"],inplace=True) # 去重之后的記錄數 print("去重之后的記錄數",df.shape)4)對崗位名字段的處理
# ① 崗位字段名的探索 df["崗位名"].value_counts() df["崗位名"] = df["崗位名"].apply(lambda x:x.lower()) # ② 構造想要分析的目標崗位,做一個數據篩選 df.shape target_job = ['運維','Linux運維','運維開發','devOps','應用運維','系統運維','數據庫運維','運維安全','網絡運維','桌面運維'] index = [df["崗位名"].str.count(i) for i in target_job] index = np.array(index).sum(axis=0) > 0 job_info = df[index] job_info.shape job_list = ['linux運維','運維開發','devOps','應用運維','系統運維','數據庫運維' ,'運維安全','網絡運維','桌面運維','it運維','軟件運維','運維工程師'] job_list = np.array(job_list) def rename(x=None,job_list=job_list): index = [i in x for i in job_list] if sum(index) > 0: return job_list[index][0] else: return x job_info["崗位名"] = job_info["崗位名"].apply(rename) job_info["崗位名"].value_counts()[:10]
5)工資字段的處理
job_info["工資"].str[-1].value_counts() job_info["工資"].str[-3].value_counts() index1 = job_info["工資"].str[-1].isin(["年","月"]) index2 = job_info["工資"].str[-3].isin(["萬","千"]) job_info = job_info[index1 & index2] job_info["工資"].str[-3:].value_counts() def get_money_max_min(x): try: if x[-3] == "萬": z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)] elif x[-3] == "千": z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)] if x[-1] == "年": z = [i/12 for i in z] return z except: return x salary = job_info["工資"].apply(get_money_max_min) job_info["最低工資"] = salary.str[0] job_info["最高工資"] = salary.str[1] job_info["工資水平"] = job_info[["最低工資","最高工資"]].mean(axis=1)6)工作地點字段的處理
address_list = ['北京', '上海', '廣州', '深圳', '杭州', '蘇州', '長沙', '武漢', '天津', '成都', '西安', '東莞', '合肥', '佛山', '寧波', '南京', '重慶', '長春', '鄭州', '常州', '福州', '沈陽', '濟南', '寧波', '廈門', '貴州', '珠海', '青島', '中山', '大連','昆山',"惠州","哈爾濱","昆明","南昌","無錫"] address_list = np.array(address_list) def rename(x=None,address_list=address_list): index = [i in x for i in address_list] if sum(index) > 0: return address_list[index][0] else: return x job_info["工作地點"] = job_info["工作地點"].apply(rename) job_info["工作地點"].value_counts()
7)公司類型字段的處理
job_info.loc[job_info["公司類型"].apply(lambda x:len(x)<6),"公司類型"] = np.nan job_info["公司類型"] = job_info["公司類型"].str[2:-2] job_info["公司類型"].value_counts()
8)行業字段的處理
job_info["行業"] = job_info["行業"].apply(lambda x:re.sub(",","/",x)) job_info.loc[job_info["行業"].apply(lambda x:len(x)<6),"行業"] = np.nan job_info["行業"] = job_info["行業"].str[2:-2].str.split("/").str[0] job_info["行業"].value_counts()9)經驗與學歷字段的處理
job_info[“學歷”] = job_info[“經驗與學歷”].apply(lambda x:re.findall(“本科|大專|應屆生|在校生|碩士|博士”,x)) def func(x): if len(x) == 0: return np.nan elif len(x) == 1 or len(x) == 2: return x[0] else: return x[2] job_info[“學歷”] = job_info[“學歷”].apply(func) job_info[“學歷”].value_counts()
10)公司規模字段的處理
def func(x): if x == “[‘少于50人’]”: return “<50" elif x == "['50-150人']": return "50-150" elif x == "['150-500人']": return '150-500' elif x == "['500-1000人']": return '500-1000' elif x == "['1000-5000人']": return '1000-5000' elif x == "['5000-10000人']": return '5000-10000' elif x == "['10000人以上']": return ">10000” else: return np.nan job_info[“公司規模”] = job_info[“公司規模”].apply(func)
11)將處理好的數據,構造新數據,導出為新的 excel
feature = [“公司名”,”崗位名”,”工作地點”,”工資水平”,”發布日期”,”學歷”,”公司類型”,”公司規模”,”行業”,”工作描述”] final_df = job_info[feature] final_df.to_excel(r”可視化.xlsx”,encoding=”gbk”,index=None)
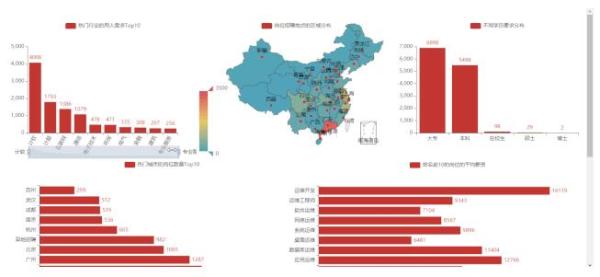
1)可視化大屏效果
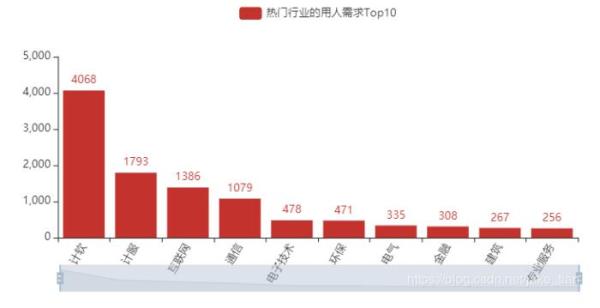
2)熱門行業的用人需求 Top10
從招聘行業的數據來看,計算機軟件,計算機服務,互聯網,通信行業用人需求相比其他行業占比會高。
3)熱門城市的崗位數量 Top10
從熱門城市來看,北上廣深的一線城市,用人崗位數占比較大,不過這里的異地招聘數據及結合過往經驗,偏外包性質的企業。
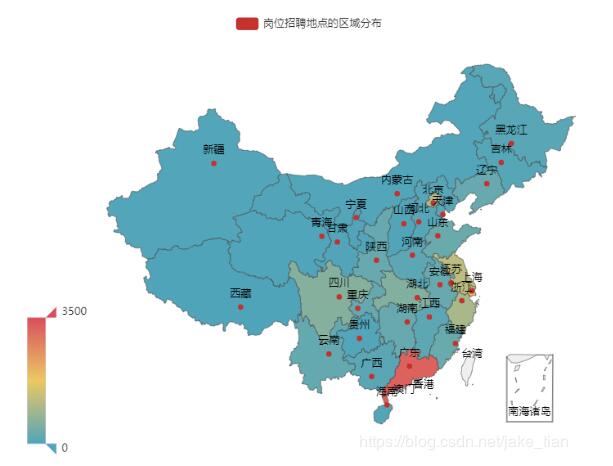
4)崗位的省份分布
崗位分布省份,通過最左側的顏色棒,我們可以看出顏色最深的地區崗位招聘數越集中,相反之下,最淺的也就是崗位招聘數越少的省份。從下圖來看,廣東省、江蘇省、上海及北京顏色相比其他省份占據分布會比較集中些。
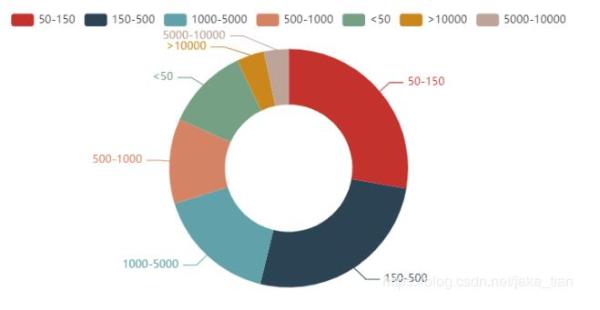
5)不同公司規模的用人情況
行業的不同,公司規模肯定是存在有差異的。公司規模是指按有關標準和規定劃分的公司規模,一般分為特大型、大型、中型、小型、微型。如下圖,公司規模人數在 50-500 范圍內占據 50% 以上,用人需求最高,1000-10000 范圍占據不到 50 %,不過這樣的公司規模已經是比較大的了。
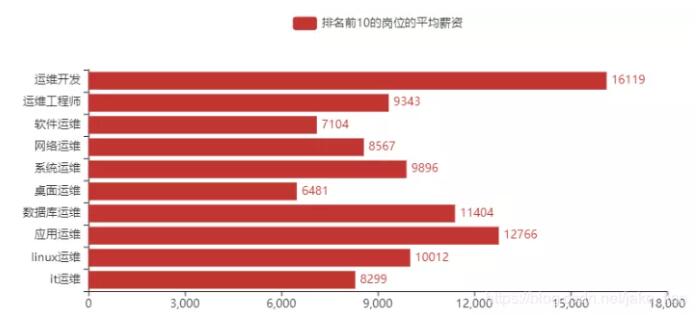
6)排名前 10 的崗位的平均薪資
根據我的了解,比如:系統工程師、軟件 / 實施工程師、運維專員 等一系列的崗位其實也是可以劃分在運維領域范疇之內的,每家公司對運維工作者的崗位名稱定義有所不同,為了能夠更精準的篩選分析,把那些崗位占時去掉了。留下了以下 10 個崗位名稱(運維開發、運維工程師、軟件運維、網絡運維、系統運維、桌面運維、數據庫運維、應用運維、Linux 運維、IT 運維)這些崗位名稱基本是我見過招聘信息內最多的。
排名前 10 的崗位平均薪資,運維開發、應用運維、數據庫運維、Linux 運維均在 1W 以上。因此,也可以看出運維開發在運維領域的優勢,是占據前沿位置。
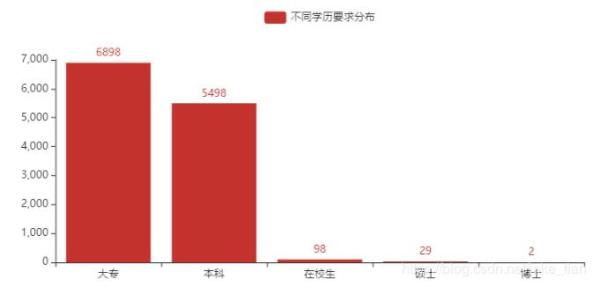
7)運維崗位的學歷要求分布
從學歷要求方面來看,大專及本科學歷占比居多。在校生、碩士、博士基本太少了,因此會有一些我的學生群體讀者會問我,對于一個應屆畢業生,找運維工作好找嗎?站在我個人的角度,我是不建議你畢業后去做運維的。因為運維對你個人的技術水平及工作經驗有些非常高的要求,而對于一個剛畢業的學生來說,沒有過多的實踐經驗,也不會有很大的優勢,除非是這個崗位對你有極大的興趣愛好,但凡你也可以嘗試下。
8)運維崗位需求的詞云圖分布
從運維崗位招聘需求詞云圖來看,詞頻最多的主要包括:運維、能力、系統、維護、經驗等等,因此也可以看出運維崗位對個人技術能力以及過往工作經驗是要求非常高的。當然了還有很多其他相關的詞頻,可通過下圖查看詳情。

以上是“怎么利用Python爬取了運維招聘信息”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





