溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“正則表達式的原理介紹”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“正則表達式的原理介紹”吧!
正則表達式可能大部分人都用過,但是大家在使用的時候,有沒有想過正則表達式背后的原理,又或者當我告訴你正則表達式可能存在性能問題導致線上掛掉,你會不會覺得特別吃驚?
我們先來看看7月初,因為一個正則表達式,導致線上事故的例子。
https://blog.cloudflare.com/d...
簡單來說就是一個有性能問題的正則表達式,引起了災難性回溯,導致cpu滿載。
性能問題的正則
先看看出問題的正則

引起性能問題的關鍵部分是 .*(?:.*=.*) ,這里我們先不管那個非捕獲組,將性能問題的正則看做 .*.*=.* 。
其中 . 表示匹配除了換行以外的任意字符(很多人把這里搞錯,容易出bug), .* 表示貪婪匹配任意字符任意次。
什么是回溯
在使用貪婪匹配或者惰性匹配或者或匹配進入到匹配路徑選擇的時候,遇到失敗的匹配路徑,嘗試走另外一個匹配路徑的這種行為,稱作回溯。
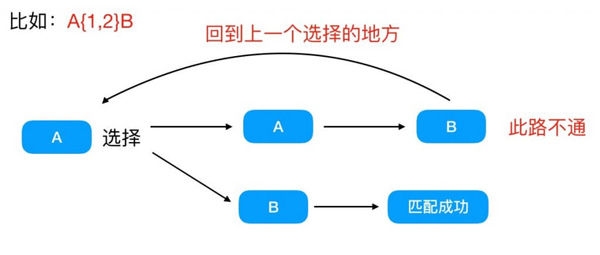
可以理解為走迷宮,一條路走到底,發現無路可走就回到上一個三岔口選擇另外的路。
回溯現象
// 性能問題正則 // 將下面代碼粘貼到瀏覽器控制臺運行試試 const regexp = `[A-Z]+\\d+(.*):(.*)+[A-Z]+\\d+`; const str = `A1:B$1,C$1:D$1,E$1:F$1,G$1:H$1` const reg = new RegExp(regexp); start = Date.now(); const res = reg.test(str); end = Date.now(); console.log('常規正則執行耗時:' + (end - start))現在來看看回溯究竟是怎么一回事
假設我們有一段正則 (.*)+\d ,這個時候輸入字符串為 abcd ,注意這個時候僅僅輸入了一個長度為4的字符串,我們來分析一下匹配回溯的過程:
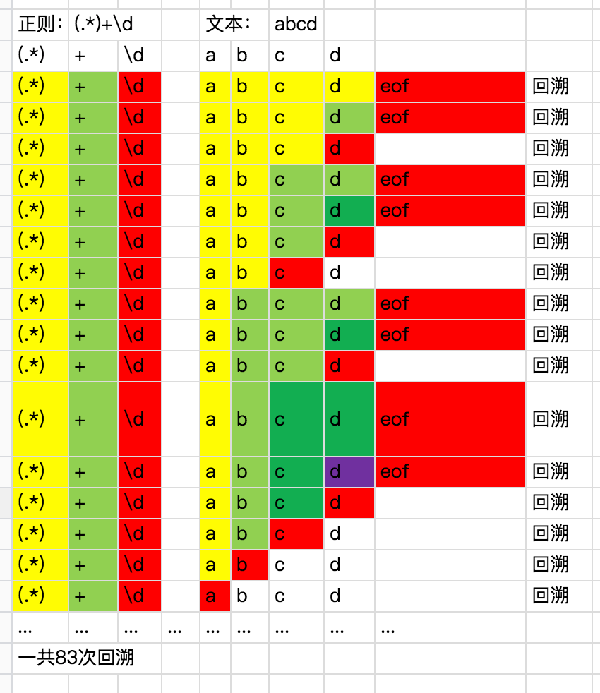
上面展示了一個回溯的匹配過程,大概描述一下前三輪匹配。
注意 (.*)+ 這里可以先暫且看成多次執行 .* 。 (.*){1,}
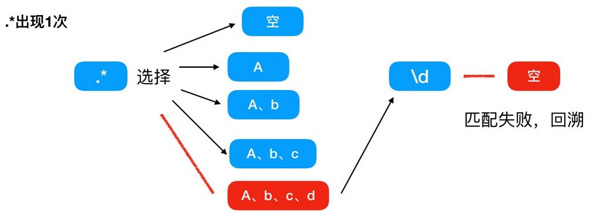
***次匹配,因為 .* 可以匹配任意個字符任意次,那么這里可以選擇匹配空、a、ab、abc、abcd,因為 * 的貪婪特性,所以 .* 直接匹配了 abcd 4個字符, + 因為后面沒有其他字符了,所以只看著 .* 吃掉 abcd 后就不匹配了,這里記錄 + 的值為1,然后 \d 沒有東西能夠匹配,所以匹配失敗,進行***次回溯。
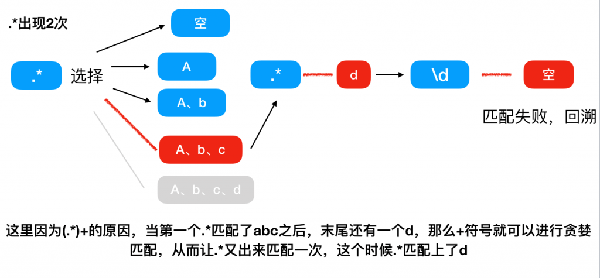
第二次匹配,因為進行了回溯,所以回到上一個匹配路徑選擇的時候,上次 .* 匹配的是 abcd ,并且路不通,那么這次只能嘗試匹配 abc ,這個時候末尾還有一個 d ,那么可以理解為 .* ***次匹配了 abc ,然后因為 (.*)+ 的原因, .* 可以進行第二次匹配,這里 .* 可以匹配 d ,這里記錄 + 的值為2,然后 \d 沒有東西能夠匹配,所以匹配失敗,進行第二次回溯。
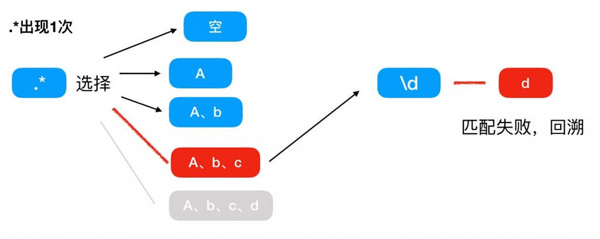
第三次匹配,因為進行了回溯,所以回到上一個匹配路徑選擇的時候,上次***個 .* 匹配的是 abc ,第二個 .* 匹配的是 d ,并且路不通,所以這里第二次的 .* 不進行匹配,這個時候末尾還有一個 d , \d 和 d 匹配失敗,進行第三次回溯。
如何減少或避免回溯
優化正則表達式:時刻注意回溯造成的性能影響。
使用DFA正則引擎的正則表達式
什么是DFA正則引擎
傳統正則引擎分為NFA(非確定性有限狀態自動機),和DFA(確定性有限狀態自動機)。
DFA
對于給定的任意一個狀態和輸入字符,DFA只會轉移到一個確定的狀態。并且DFA不允許出現沒有輸入字符的狀態轉移。
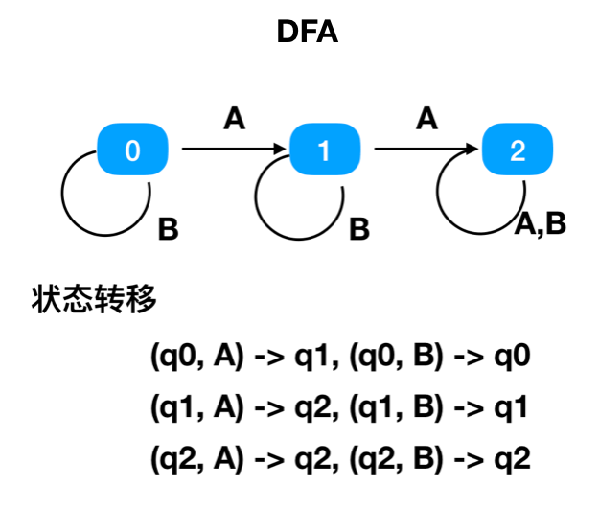
比如狀態0,在輸入字符A的時候,終點只有1個,只能到狀態1。
NFA
對于任意一個狀態和輸入字符,NFA所能轉移的狀態是一個非空集合。
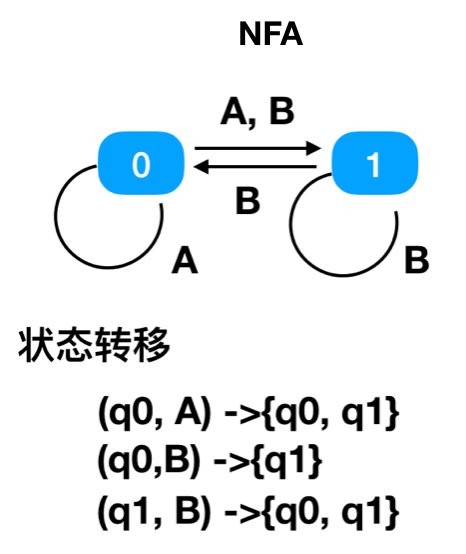
比如狀態0,在輸入字符A的時候,終點可以是多個,即能到狀態1,也能到狀態0。
DFA和NFA的正則引擎的區別
那么講了這么多之后,DFA和NFA正則引擎究竟有什么區別呢?或者說DFA和NFA是如何實現正則引擎的呢?
DFA
正則里面的DFA引擎實際上就是把正則表達式轉換成一個圖的鄰接表,然后通過跳表的形式判斷一個字符串是否匹配該正則。
// 大概模擬一下 function machine(input) { if (typeof input !== 'string') { console.log('輸入有誤'); return; } // 比如正則:/abc/ 轉換成DFA之后 // 這里我們定義了4種狀態,分別是0,1,2,3,初始狀態為0 const reg = { 0: { a: 1, }, 1: { b: 3, }, 2: { isEnd: true, }, 3: { c: 2, }, }; let status = 0; for (let i = 0; i < input.length; i++) { const inputinputChar = input[i]; status = reg[status][inputChar]; if (typeof status === 'undefined') { console.log('匹配失敗'); return false; } } const end = reg[status]; if (end && end.isEnd === true) { console.log('匹配成功'); return true; } else { console.log('匹配失敗'); return false; } } const input = 'abc'; machine(input);優點:不管正則表達式寫的再爛,匹配速度都很快
缺點:高級功能比如捕獲組和斷言都不支持
NFA
正則里面NFA引擎實際上就是在語法解析的時候,構造出的一個有向圖。然后通過深搜的方式,去一條路徑一條路徑的遞歸嘗試。
優點:功能強大,可以拿到匹配的上下文信息,支持各種斷言捕獲組環視之類的功能
缺點:對開發正則功底要求較高,需要注意回溯造成的性能問題
總結
現在回到問題的開頭,我們再來看看為什么他的正則會有性能問題
鴻蒙官方戰略合作共建——HarmonyOS技術社區
首先他的正則使用的NFA的正則引擎(大部分語言的正則引擎都是NFA的,js也是,所以要注意性能問題產生的影響)
他寫出了有性能問題的正則表達式,容易造成災難性回溯。
如果要避免此類的問題,要么提高開發對正則的性能問題的意識,要么改用DFA的正則引擎(速度快,功能弱,沒有補貨組斷言等功能)。
注意事項
在平常寫正則的時候,少寫模糊匹配,越精確越好,模糊匹配、貪婪匹配、惰性匹配都會帶來回溯問題,選一個影響盡可能小的方式就好。寫正則的時候有一個性能問題的概念在腦子里就行。
到此,相信大家對“正則表達式的原理介紹”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





