溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Python中怎么刪除目錄下的相同文件,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
# -*- coding: cp936 -*- import md5 import os from time import clock as now def getmd5(filename): file_txt = open(filename,'rb').read() m = md5.new(file_txt) return m.hexdigest() def main(): path = raw_input("path: ") all_md5=[] total_file=0 total_delete=0 start=now() for file in os.listdir(path): total_file += 1; real_path=os.path.join(path,file) if os.path.isfile(real_path) == True: filemd5=getmd5(real_path) if filemd5 in all_md5: total_delete += 1 print '刪除',file else: all_md5.append(filemd5) end = now() time_last = end - start print '文件總數:',total_file print '刪除個數:',total_delete print '耗時:',time_last,'秒' if __name__=='__main__': main()上面的程序原理很簡單,就是依次讀取每個文件,計算md5,如果md5在md5列表不存在,就把這個md5加到md5列表里面去,如果存在的話,我們就認為這個md5對應的文件已經出現過,這個圖片就是多余的,然后我們就可以把這個圖片刪除了。下面是程序的運行截圖:
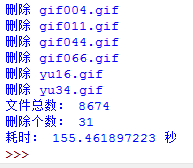
我們可以看到,在這個文件夾下面有8674個文件,有31個是重復的,找到所有重復文件共耗時155.5秒。效率不算高,能不能進行優化呢?我分析了一下,我的程序里面有兩個功能比較耗時間,一個是計算每個文件的md5,這個占了大部分時間,還有就是在列表中查找md5是否存在,也比較費時間的。從這兩方面入手,我們可以進一步優化。
首先我想的是解決查找問題,或許我們可以對列表中的元素先排一下序,然后再去查找,但是列表是變化的,每次都排序的話效率就比較低了。我想的是利用字典進行優化。字典最顯著的特點是一個key對應一個值我們可以把md5作為key,key對應的值就不需要了,在變化的情況下字典的查找效率比序列效率高,因為序列是無序的,而字典是有序的,查找起來當然更快。這樣我們只要判斷md5值是否在所有的key中就可以了。下面是改進后的代碼:
# -*- coding: cp936 -*- import md5 import os from time import clock as now def getmd5(filename): file_txt = open(filename,'rb').read() m = md5.new(file_txt) return m.hexdigest() def main(): path = raw_input("path: ") all_md5={} total_file=0 total_delete=0 start=now() for file in os.listdir(path): total_file += 1; real_path=os.path.join(path,file) if os.path.isfile(real_path) == True: filemd5=getmd5(real_path) if filemd5 in all_md5.keys(): total_delete += 1 print '刪除',file else: all_md5[filemd5]='' end = now() time_last = end - start print '文件總數:',total_file print '刪除個數:',total_delete print '耗時:',time_last,'秒' if __name__=='__main__': main()再看看運行截圖
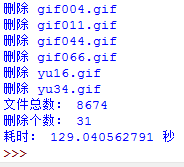
從時間上看,確實比原來快了一點,但是還不理想。下面還要進行優化。還有什么可以優化呢?md5!上面的程序,每個文件都要計算md5,非常費時間,是不是每個文件都需要計算md5呢?能不能想辦法減少md5的計算次數呢?我想到了一種方法:上面分析時我們提到,可以通過比較文件大小的方式來判斷圖片是否完全相同,速度快,但是這種方法是不準確的,md5是準確的,我們能不能把兩者結合一下?答案是肯定的。我們可以認定:如果兩個文件完全相同,那么這兩個文件的大小和md5一定相同,如果兩個文件的大小不同,那么這兩個文件肯定不同!這樣的話,我們只需要先查看文件的大小是否存在在size字典中,如果不存在,就將它加入到size字典中,如果大小存在的話,這說明有至少兩張圖片大小相同,那么我們只要計算文件大小相同的文件的md5,如果md5相同,那么這兩個文件肯定完全一樣,我們可以刪除,如果md5不同,我們把它加到列表里面,避免重復計算md5.具體代碼實現如下:
# -*- coding: cp936 -*- import md5 import os from time import clock as now def getmd5(filename): file_txt = open(filename,'rb').read() m = md5.new(file_txt) return m.hexdigest() def main(): path = raw_input("path: ") all_md5 = {} all_size = {} total_file=0 total_delete=0 start=now() for file in os.listdir(path): total_file += 1 real_path=os.path.join(path,file) if os.path.isfile(real_path) == True: size = os.stat(real_path).st_size name_and_md5=[real_path,''] if size in all_size.keys(): new_md5 = getmd5(real_path) if all_size[size][1]=='': all_size[size][1]=getmd5(all_size[size][0]) if new_md5 in all_size[size]: print '刪除',file total_delete += 1 else: all_size[size].append(new_md5) else: all_size[size]=name_and_md5 end = now() time_last = end - start print '文件總數:',total_file print '刪除個數:',total_delete print '耗時:',time_last,'秒' if __name__=='__main__': main()時間效率怎樣呢?看下圖:
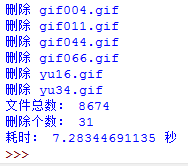
以上就是Python中怎么刪除目錄下的相同文件,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





