溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹HTTP中有哪些規范,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
1.Referer
HTTP 標準把 Referrer 寫成 Referer(少些了一個 r),可以說是計算機歷史上最著名的一個錯別字了。
Referer 的主要作用是攜帶當前請求的來源地址,常用在反爬蟲和防盜鏈上。前段時間鬧的沸沸揚揚的新浪圖床掛圖事件,就是因為新浪圖床突然開始檢查 HTTP Referer 頭,非新浪域名就不返回圖片,導致很多蹭流量的中小博客圖都掛了。
雖然 HTTP 標準里把 Referer 寫錯了,但是其它可以控制 Referer 的標準并沒有將錯就錯。
例如禁止網頁自動攜帶 Referer 頭的 <meta> 標簽,相關關鍵字拼寫就是正確的:
<!-- 全局禁止發送 referrer --> <meta name="referrer" content="no-referrer" />
還有一個值得注意的是瀏覽器的網絡請求。從安全性和穩定性上考慮,Referer 等請求頭在網絡請求時,只能由瀏覽器控制,不能直接操作,我們只能通過一些屬性進行控制。比如說 Fetch 函數,我們可以通過 referrer 和 referrerPolicy 控制,而它們的拼寫也是正確的:
fetch('/page', { headers: { "Content-Type": "text/plain;charset=UTF-8" }, referrer: "https://demo.com/anotherpage", // <- referrerPolicy: "no-referrer-when-downgrade", // <- });一句話總結:
凡是涉及到 Referrer 的,除了 HTTP 字段是錯的,瀏覽器的相關配置字段拼寫都是正確的。
二.「靈異」的空格
1.%20 還是 + ?
這個是個史詩級的大坑,我曾經被這個協議沖突坑了一天。
開始講解前先看個小測試,在瀏覽器里輸入 blank test( blank 和 test 間有個空格),我們看看瀏覽器如何處理的:

從動圖可以看出瀏覽器把空格解析為一個加號「+」。
是不是感覺有些奇怪?我們再做個測試,用瀏覽器提供的幾個函數試一下:
encodeURIComponent("blank test") // "blank%20test" encodeURI("q=blank test") // "q=blank%20test" new URLSearchParams("q=blank test").toString() // "q=blank+test"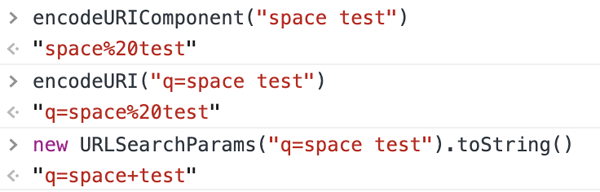
代碼是不會說謊的,其實上面的結果都是正確的,encode 結果不一樣,是因為 URI 規范和 W3C 規范沖突了,才會搞出這種讓人疑惑的烏龍事件。
2.沖突的協議
我們首先看看 URI 中的保留字,這些保留字不參與編碼。保留字符一共有兩大類:
gen-delims:: / ? # [ ] @
sub-delims:! $ & ' ( ) * + , ; =
URI 的編碼規則也很簡單,先把非限定范圍的字符轉為 16 進制,然后前面加百分號。
空格這種不安全字符轉為十六進制就是 0x20,前面再加上百分號 % 就是 %20:
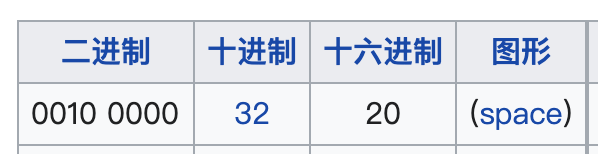
所以這時候再看 encodeURIComponent 和 encodeURI 的編碼結果,就是完全正確的。
既然空格轉為%20 是正確的,那轉為 + 是怎么回事?這時候我們就要了解一下 HTML form 表單的歷史。
早期的網頁沒有 AJAX 的時候,提交數據都是通過 HTML 的 form 表單。form 表單的提交方法可以用 GET 也可以用 POST,大家可以在 MDN form 詞條上測試:
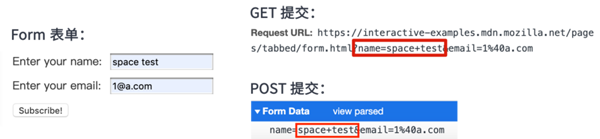
經過測試我們可以看出表單提交的內容中,空格都是轉為加號的,這種編碼類型就是 application/x-www-form-urlencoded,在 WHATWG 規范里是這樣定義的:

到這里基本上就破案了,URLSearchParams 做 encode 的時候,就按這個規范來的。我找到了 URLSearchParams 的 Polyfill 代碼,里面就做了 %20 到 + 的映射:
replace = { '!': '%21', "'": '%27', '(': '%28', ')': '%29', '~': '%7E', '%20': '+', // <= 就是這個 '%00': '\x00' }規范里對這個編碼類型還有解釋說明:
The application/x-www-form-urlencoded format is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices. In particular, readers are cautioned to pay close attention to the twisted details involving repeated (and in some cases nested) conversions between character encodings and byte sequences. Unfortunately the format is in widespread use due to the prevalence of HTML forms.
這種編碼方式就不是個好的設計,不幸的是隨著 HTML form 表單的普及,這種格式已經推廣開了
其實上面一大段句話就是一個意思:這玩意兒設計的就是 ?,但積重難返,大家還是忍一下吧
3.一句話總結
URI 規范里,空格 encode 為 %20, application/x-www-form-urlencoded 格式里,空格 encode 為 +
實際業務開發時,最好使用業內成熟的 HTTP 請求庫封裝請求,這些雜活兒累活兒框架都干了;
如果非要使用原生 AJAX 提交 application/x-www-form-urlencoded 格式的數據,不要手動拼接參數,要用 URLSearchParams 處理數據,這樣可以避免各種惡心的編碼沖突。
三.X-Forwarded-For 拿到的就是真實 IP 嗎?
1.故事
在這個小節開始前,我先講一個開發中的小故事,可以加深一下大家對這個字段的理解。
前段時間要做一個和風控相關的需求,需要拿到用戶的 IP,開發后灰度了一小部分用戶,測試發現后臺日志里灰度的用戶 IP 全是異常的,哪有這么巧的事情。隨后測試發過來幾個異常 IP:
10.148.2.122 10.135.2.38 10.149.12.33 ...
一看 IP 特征我就明白了,這幾個 IP 都是 10 開頭的,屬于 A 類 IP 的私有 IP 范圍(10.0.0.0-10.255.255.255),后端拿到的肯定是代理服務器的 IP,而不是用戶的真實 IP。
2.原理
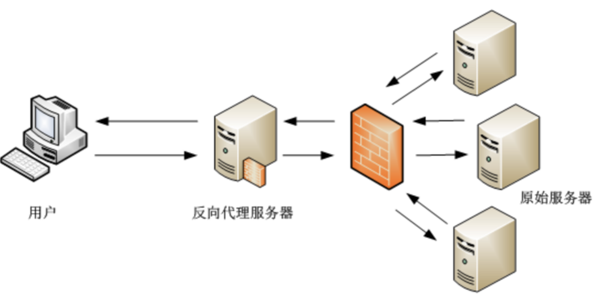
現在有些規模的網站基本都不是單點 Server 了,為了應對更高的流量和更靈活的架構,應用服務一般都是隱藏在代理服務器之后的,比如說 Nginx。
加入接入層后,我們就能比較容易的實現多臺服務器的負載均衡和服務升級,當然還有其他的好處,比如說更好的內容緩存和安全防護,不過這些不是本文的重點就不展開了。
網站加入代理服務器后,除了上面的幾個優點,同時引入了一些新的問題。比如說之前的單點 Server,服務器是可以直接拿到用戶的 IP 的,加入代理層后,如上圖所示,(應用)原始服務器拿到的是代理服務器的 IP,我前面講的故事的問題就出在這里。
Web 開發這么成熟的領域,肯定是有現成的解決辦法的,那就是 X-Forwarded-For 請求頭。
X-Forwarded-For 是一個事實標準,雖然沒有寫入 HTTP RFC 規范里,從普及程度上看其實可以算 HTTP 規范了。
這個標準是這樣定義的,每次代理服務器轉發請求到下一個服務器時,要把代理服務器的 IP 寫入 X-Forwarded-For 中,這樣在最末端的應用服務收到請求時,就會得到一個 IP 列表:
X-Forwarded-For: client, proxy1, proxy2
因為 IP 是一個一個依次 push 進去的,那么第一個 IP 就是用戶的真實 IP,取來用就好了。
但是,事實有這么簡單嗎?
3.攻擊
從安全的角度上考慮,整個系統最不安全的就是人,用戶端都是最好攻破最好偽造的。有些用戶就開始鉆協議的漏洞:X-Forwarded-For 是代理服務器添加的,如果我一開始請求的 Header 頭里就加了 X-Forwarded-For ,不就騙過服務器了嗎?
1. 首先從客戶端發出請求,帶有 X-Forwarded-For 請求頭,里面寫一個偽造的 IP:
X-Forwarded-For: fakeIP
2. 服務端第一層代理服務收到請求,發現已經有 X-Forwarded-For,誤把這個請求當成代理服務器,于是向這個字段追加了客戶端的真實 IP:
X-Forwarded-For: fakeIP, client
3. 經過幾層代理后,最終的服務器拿到的 Header 是這樣的:
X-Forwarded-For: fakeIP, client, proxy1, proxy2
要是按照取 X-Forwarded-For 第一個 IP 的思路,你就著了攻擊者的道了,你拿到的是 fakeIP,而不是 client IP。
4.破招
服務端如何破招?上面三個步驟:
第一步是客戶端造假,服務器無法介入
第二步是代理服務器,可控,可防范
第三步是應用服務器,可控,可防范
第二步的破招我拿 Nginx 服務器舉例。
我們在最外層的 Nginx 上,對 X-Forwarded-For 的配置如下:
proxy_set_header X-Forwarded-For $remote_addr;
什么意思呢?就是最外層代理服務器不信任客戶端的 X-Forwarded-For 輸入,直接覆蓋,而不是追加。
非最外層的 Nginx 服務器,我們配置:
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
$proxy_add_x_forwarded_for 就是追加 IP 的意思。通過這招,就可以破除用戶端的偽造辦法。
第三步的破招思路也很容易,正常思路我們是取X-Forwarded-For 最左側的 IP,這次我們反其道而行之,從右邊數,減去代理服務器的數目,那么剩下的 IP 里,最右邊的就是真實 IP。
X-Forwarded-For: fakeIP, client, proxy1, proxy2
比如說我們已知代理服務有兩層,從右向左數,把 proxy1 和 proxy2 去掉,剩下的 IP 列表最右邊的就是真實 IP。
相關思路和代碼實現可參考 Egg.js 前置代理模式。
5.一句話總結總結
通過 X-Forwarded-For 獲取用戶真實 IP 時,最好不要取第一個 IP,以防止用戶偽造 IP。
四.略顯混亂的分隔符
1.HTTP 標準
HTTP 請求頭字段如果涉及到多個 value 時,一般來說每個 value 間是用逗號「,」分隔的,就連非 RFC 標準的 X-Forwarded-For,也是用逗號分隔 value 的:
Accept-Encoding: gzip, deflate, br cache-control: public, max-age=604800, s-maxage=43200 X-Forwarded-For: fakeIP, client, proxy1, proxy2
因為一開始用逗號分隔 value,后面想再用一個字段修飾 value 時,分隔符就變成了分號「;」,最典型的請求頭就是 Accept 了:
// q=0.9 修飾的是 application/xml,雖然它們之間用分號分隔 Accept: text/html, application/xml;q=0.9, */*;q=0.8
雖然 HTTP 協議易于閱讀,但是這個分隔符用的還是很不符合常識的。按常理來說,分號的斷句語氣是強于逗號的,但是在 HTTP 內容協商的相關字段里卻是反過來的。這里的定義可以看 RFC 7231,寫的還是比較清楚的。
2.Cookie 標準
和常規認識不同,Cookie 其實不算 HTTP 標準,定義 Cookie 的規范是 RFC 6265,所以分隔符規則也不一樣了。規范里定義的 Cookie 語法規則是這樣的:
cookie-header = "Cookie:" OWS cookie-string OWS cookiecookie-string = cookie-pair *( ";" SP cookie-pair )
多個 cookie 之間是用分號「;」分隔的,而不是逗號「,」。我隨便扒了個網站的 cookie,可見是用分號分隔的,這里需要特別注意一下:

關于HTTP中有哪些規范就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





