溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中怎么實現同步和異步,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一、同步與異步
#同步編程(同一時間只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #異步編程 (可以近似的理解成同一時間有多個事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_url--> <--j_url-->
模板
import asyncio #函數名:做現在的任務時不等待,能繼續做別的任務。 async def donow_meantime_dontwait(url): response = await requests.get(url) #函數名:快速高效的做任務 async def fast_do_your_thing(): await asyncio.wait([donow_meantime_dontwait(url) for url in urls]) #下面兩行都是套路,記住就好 loop = asyncio.get_event_loop() loop.run_until_complete(fast_do_your_thing())
tips:
await表達式中的對象必須是awaitable
requests不支持非阻塞
aiohttp是用于異步請求的庫
代碼
import asyncio import requests import time import aiohttp urls = ['https://book.douban.com/tag/小說','https://book.douban.com/tag/科幻', 'https://book.douban.com/tag/漫畫','https://book.douban.com/tag/奇幻', 'https://book.douban.com/tag/歷史','https://book.douban.com/tag/經濟學'] async def requests_meantime_dont_wait(url): print(url) async with aiohttp.ClientSession() as session: async with session.get(url) as resp: print(resp.status) print("{url} 得到響應".format(url=url)) async def fast_requsts(urls): start = time.time() await asyncio.wait([requests_meantime_dont_wait(url) for url in urls]) end = time.time() print("Complete in {} seconds".format(end - start)) loop = asyncio.get_event_loop() loop.run_until_complete(fast_requsts(urls))gevent簡介
gevent是一個python的并發庫,它為各種并發和網絡相關的任務提供了整潔的API。
gevent中用到的主要模式是greenlet,它是以C擴展模塊形式接入Python的輕量級協程。 greenlet全部運行在主程序操作系統進程的內部,但它們被協作式地調度。
猴子補丁
requests庫是阻塞式的,為了將requests同步更改為異步。只有將requests庫阻塞式更改為非阻塞,異步操作才能實現。
而gevent庫中的猴子補丁(monkey patch),gevent能夠修改標準庫里面大部分的阻塞式系統調用。這樣在不改變原有代碼的情況下,將應用的阻塞式方法,變成協程式的(異步)。
代碼
from gevent import monkey import gevent import requests import time monkey.patch_all() def req(url): print(url) resp = requests.get(url) print(resp.status_code,url) def synchronous_times(urls): """同步請求運行時間""" start = time.time() for url in urls: req(url) end = time.time() print('同步執行時間 {} s'.format(end-start)) def asynchronous_times(urls): """異步請求運行時間""" start = time.time() gevent.joinall([gevent.spawn(req,url) for url in urls]) end = time.time() print('異步執行時間 {} s'.format(end - start)) urls = ['https://book.douban.com/tag/小說','https://book.douban.com/tag/科幻', 'https://book.douban.com/tag/漫畫','https://book.douban.com/tag/奇幻', 'https://book.douban.com/tag/歷史','https://book.douban.com/tag/經濟學'] synchronous_times(urls) asynchronous_times(urls)gevent:異步理論與實戰
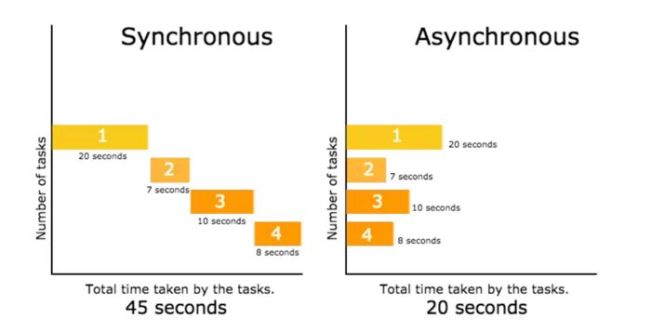
gevent庫中使用的最核心的是Greenlet-一種用C寫的輕量級python模塊。在任意時間,系統只能允許一個Greenlet處于運行狀態
一個greenlet遇到IO操作時,比如訪問網絡,就自動切換到其他的greenlet,等到IO操作完成,再在適當的時候切換回來繼續執行。由于IO操作非常耗時,經常使程序處于等待狀態,有了gevent為我們自動切換協程,就保證總有greenlet在運行,而不是等待IO。
串行和異步
高并發的核心是讓一個大的任務分成一批子任務,并且子任務會被被系統高效率的調度,實現同步或者異步。在兩個子任務之間切換,也就是經常說到的上下文切換。
同步就是讓子任務串行,而異步有點影分身之術,但在任意時間點,真身只有一個,子任務并不是真正的并行,而是充分利用了碎片化的時間,讓程序不要浪費在等待上。這就是異步,效率杠桿的。
gevent中的上下文切換是通過yield實現。在這個例子中,我們會有兩個子任務,互相利用對方等待的時間做自己的事情。這里我們使用gevent.sleep(0)代表程序會在這里停0秒。
import gevent def foo(): print('Running in foo') gevent.sleep(0) print('Explicit context switch to foo again') def bar(): print('Explicit context to bar') gevent.sleep(0) print('Implicit context switch back to bar') gevent.joinall([ gevent.spawn(foo), gevent.spawn(bar) ])運行的順序:
Running in foo Explicit context to bar Explicit context switch to foo again Implicit context switch back to bar
同步異步的順序問題
同步運行就是串行,123456...,但是異步的順序是隨機的任意的(根據子任務消耗的時間而定)
代碼
import gevent import random def task(pid): """ Some non-deterministic task """ gevent.sleep(random.randint(0,2)*0.001) print('Task %s done' % pid) #同步(結果更像串行) def synchronous(): for i in range(1,10): task(i) #異步(結果更像亂步) def asynchronous(): threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print('Synchronous同步:') synchronous() print('Asynchronous異步:') asynchronous()輸出
Synchronous同步:
Task 1 done Task 2 done Task 3 done Task 4 done Task 5 done Task 6 done Task 7 done Task 8 done Task 9 done
Asynchronous異步:
Task 1 done Task 5 done Task 6 done Task 2 done Task 4 done Task 7 done Task 8 done Task 9 done Task 0 done Task 3 done
同步案例中所有的任務都是按照順序執行,這導致主程序是阻塞式的(阻塞會暫停主程序的執行)。
gevent.spawn會對傳入的任務(子任務集合)進行進行調度,gevent.joinall方法會阻塞當前程序,除非所有的greenlet都執行完畢,程序才會結束。
實戰
實現gevent到底怎么用,把異步訪問得到的數據提取出來。
在有道詞典搜索框輸入“hello”按回車。觀察數據請求情況 觀察有道的url構建。
分析url規律
#url構建只需要傳入word即可 url = "http://dict.youdao.com/w/eng/{}/".format(word)解析網頁數據
def fetch_word_info(word): url = "http://dict.youdao.com/w/eng/{}/".format(word) resp = requests.get(url,headers=headers) doc = pq(resp.text) pros = '' for pro in doc.items('.baav .pronounce'): pros+=pro.text() description = '' for li in doc.items('#phrsListTab .trans-container ul li'): description +=li.text() return {'word':word,'音標':pros,'注釋':description}因為requests庫在任何時候只允許有一個訪問結束完全結束后,才能進行下一次訪問。無法通過正規途徑拓展成異步,因此這里使用了monkey補丁
同步代碼
import requests from pyquery import PyQuery as pq import gevent import time import gevent.monkey gevent.monkey.patch_all() words = ['good','bad','cool', 'hot','nice','better', 'head','up','down', 'right','left','east'] def synchronous(): start = time.time() print('同步開始了') for word in words: print(fetch_word_info(word)) end = time.time() print("同步運行時間: %s 秒" % str(end - start)) #執行同步 synchronous()異步代碼
import requests from pyquery import PyQuery as pq import gevent import time import gevent.monkey gevent.monkey.patch_all() words = ['good','bad','cool', 'hot','nice','better', 'head','up','down', 'right','left','east'] def asynchronous(): start = time.time() print('異步開始了') events = [gevent.spawn(fetch_word_info,word) for word in words] wordinfos = gevent.joinall(events) for wordinfo in wordinfos: #獲取到數據get方法 print(wordinfo.get()) end = time.time() print("異步運行時間: %s 秒"%str(end-start)) #執行異步 asynchronous()我們可以對待爬網站實時異步訪問,速度會大大提高。我們現在是爬取12個詞語的信息,也就是說一瞬間我們對網站訪問了12次,這還沒啥問題,假如爬10000+個詞語,使用gevent的話,那幾秒鐘之內就給網站一股腦的發請求,說不定網站就把爬蟲封了。
解決辦法
將列表等分為若干個子列表,分批爬取。舉例我們有一個數字列表(0-19),要均勻的等分為4份,也就是子列表有5個數。下面是我在stackoverflow查找到的列表等分方案:
方法1
seqence = list(range(20)) size = 5 #子列表長度 output = [seqence[i:i+size] for i in range(0, len(seqence), size)] print(output)
方法2
chunks = lambda seq, size: [seq[i: i+size] for i in range(0, len(seq), size)] print(chunks(seq, 5))
方法3
def chunks(seq,size): for i in range(0,len(seq), size): yield seq[i:i+size] prinT(chunks(seq,5)) for x in chunks(req,5): print(x)
數據量不大的情況下,選哪一種方法都可以。如果特別大,建議使用方法3.
動手實現
import requests from pyquery import PyQuery as pq import gevent import time import gevent.monkey gevent.monkey.patch_all() words = ['good','bad','cool', 'hot','nice','better', 'head','up','down', 'right','left','east'] def fetch_word_info(word): url = "http://dict.youdao.com/w/eng/{}/".format(word) resp = requests.get(url,headers=headers) doc = pq(resp.text) pros = '' for pro in doc.items('.baav .pronounce'): pros+=pro.text() description = '' for li in doc.items('#phrsListTab .trans-container ul li'): description +=li.text() return {'word':word,'音標':pros,'注釋':description} def asynchronous(words): start = time.time() print('異步開始了') chunks = lambda seq, size: [seq[i: i + size] for i in range(0, len(seq), size)] for subwords in chunks(words,3): events = [gevent.spawn(fetch_word_info, word) for word in subwords] wordinfos = gevent.joinall(events) for wordinfo in wordinfos: # 獲取到數據get方法 print(wordinfo.get()) time.sleep(1) end = time.time() print("異步運行時間: %s 秒" % str(end - start)) asynchronous(words)看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





