溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“服務器故障實例分析”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“服務器故障實例分析”文章能幫助大家解決問題。
沒辦法,干it這一行,就得天天面對故障,大家就是傳說中的消防員,到處救火。不過,這次的故障范圍有點大,宿主機都打不開了。
好在監控系統留下了一些證據。
證據發現,機器的CPU、內存、文件句柄,隨著業務的增長,持續的上升...上升....,直到監控也無法將信息收集上來。
要命的是,這些宿主機上,部署了非常多的Java進程。沒別的原因,就是為了節省成本,混部了應用。當宿主機表現出整體性的異常時,就難以找到罪魁禍首。
因為遠程登錄也Over,暴躁的運維只能重啟機器,重啟機器之后開始重啟應用。經過漫長的等待,所有的進程都活了,但是,僅僅過了片刻,宿主機又立即死去。
業務一直處于死翹翹的狀態,真是讓人惱火啊。也讓人心急。嘗試過幾次之后,運維崩潰了,啟動了緊急預案:回滾!
最近的上線記錄有點多,而且有開發人員私自上線部署的行為,運維蒙圈了:回滾哪些呢?還好有人腦瓜一亮,想起了還有find這個命令,那就找到最近更新的所有jar包,都給它來次回滾吧。
find /apps/deploy -mtime +3 | grep jar$
如果你不知道find這個命令,那可還真的是一場災難。還好有人知道。
把十來個jar包回滾,還好沒有碰到數據庫的schema變更,系統終于正常運行了。
沒別的辦法,查日志,進行代碼審查。
代碼審查要追溯到最近1周或者2周之內的代碼改動,因為有些功能代碼要沉淀一段時間,才能到線上風光一把。
看著滿屏的提交記錄“OK”,技術經理的臉都綠了。
“xjjdog說過,《80%的程序員,不會寫commit記錄》,我看你們是100%都不會寫”。
大家都靜悄悄的,忍著痛翻查歷史變更。經過大家的不懈努力,終于在屎山之間,找到了一些問題代碼。CxO親自建了個群,大家一股腦的把可能會出問題的代碼,扔到了群里面。
"系統服務中斷了接近一個小時,影響非常惡劣",CxO說,“務必把問題徹底解決掉,這個問題投資人非常關注”!
okokok,有了釘釘的助力,大家的手勢都變得整齊劃一。
代碼有點多,大家對問題代碼討論了老久。包括一些使用并行流的,還有套在lamba表達式里的炫技代碼,還重點排查了一些線程池的使用代碼。
最后大家決定還是對線程池的代碼再過一遍。其中有一段是這么寫的。
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(10), handler);
還別說,參數有模有樣的,甚至考慮到了拒絕策略。
Java的線程池,使得編程變的非常簡單。它有很多參數,如上圖,我們一一介紹一下,否則代碼是無法審查的。
corePoolSize:核心線程數,核心線程創建后會一直存活
maxPoolSize:最大線程數
keepAliveTime:線程空閑時間
workQueue:阻塞隊列
threadFactory:線程創建工廠
handler:拒絕策略
下面來介紹一下它們的關系。
當線程數小于核心線程數的時候,有新的任務到來,將會生成一個新的線程進行服務。當當前線程數大于核心線程數,而且阻塞隊列未滿的時候,將會把任務放在阻塞隊列中。當線程數大于核心線程數,而且阻塞隊列滿了的時候,將會創建新的線程進行服務,直到線程數到達maximumPoolSize的大小。此時,如果還有新的任務,將觸發拒絕策略。
再說一下拒絕策略。jdk默認實現了4種策略,默認實現的是AbortPolicy,也就是直接拋出異常。下面介紹其他幾種。
DiscardPolicy 比abort更加激進,直接丟掉任務,連異常信息都沒有
CallerRunsPolicy 由調用的線程來處理這個任務。比如一個web應用中,線程池資源占滿后,新進的任務將會在tomcat線程中運行。這種方式能夠延緩部分任務的執行壓力,但在更多情況下,會直接阻塞主線程的運行
DiscardOldestPolicy 丟棄隊列最前面的任務,然后重新嘗試執行任務
這段線程池的代碼是新加的,參數設置還算正常,并沒有什么大的問題。唯一有可能的風險,就是使用DiscardOldestPolicy 的拒絕策略。當任務非常多的時候,這個拒絕策略會造成任務排隊,請求超時。
當然不能放過這種風險,說實話也是到現在為之能夠找到的最可能的風險代碼了。
"把DiscardOldestPolicy 改成默認的AbortPolicy吧,重新打包上線一下試試“。技術大牛在群里說。
結果,服務灰度上線之后,宿主機不多時,就死掉了。是它的原因沒跑了,但是why?
線程池的大小 ,最小100,最大200,說什么也不過分。阻塞隊列的容量只有10,說什么也不會造成問題。你要說是這個線程池造成的原因,打死我都不信。
但是業務部門反饋,這段代碼加上就死,不加就沒事。技術大牛們抓耳撓腮百思不得其姐。
到最后,終于有人忍不住了,下載下業務的代碼打算調試一下。
當他打開Idea的時候,瞬間懵逼了,又瞬間領悟了。他終于明白了這段代碼為什么會產生問題了。
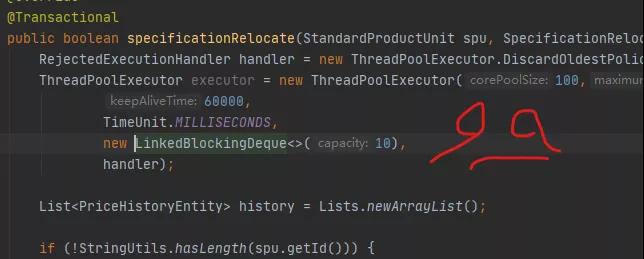
線程池,竟然是在方法里創建的!
當每一個請求到來的時候,它都會創建一個線程池,直到系統再也無法分配資源為止。
可真是霸道啊。
所有人都在關注線程池的參數是怎么設置的,但從來沒有人懷疑這段代碼所在的位置。
關于“服務器故障實例分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





