溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1. 字符在內存中都是以unicode類型存在。
2. 當數據要保存到磁盤或者網絡傳輸時,會轉為utf-8等編碼再保存或傳輸。
3. 在python文件第一行指定的編碼方式用于向python解釋器指出解碼方式。
4. Python中字符的存儲類型有bytes和unicode,在py2.x中被稱為str和unicode, 在py3.x中被稱為bytes和str.
5. Py2.x和py3.x中字符的類型都為str, 因此在py2.x中是bytes類型,在py3.x中是unicode類型。
6. py2.x中文件默認解碼方式(即python文件第一行不指定時)為ASCII, py3.x中為UTF-8. 使用sys.getdefaultencoding()獲得。
7. 編碼、解碼過程。
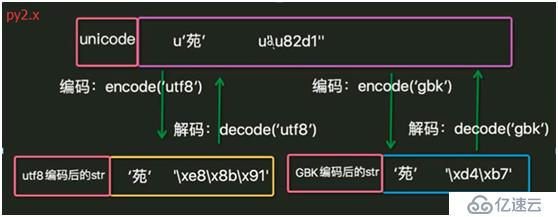
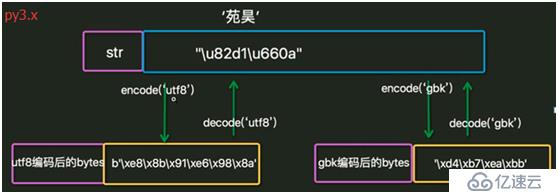
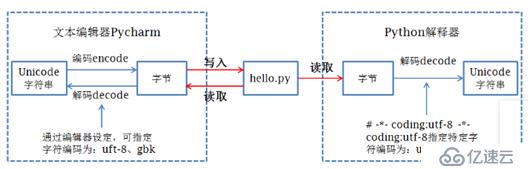
8. IDE在程序運行前先按文檔屬性設定的編碼方式把數據保存到磁盤,然后python解釋器按文件第一行的解碼方式把磁盤中存儲的二進制序列讀取并解碼為unicode加載到內存中。
編碼:把人類發明的文字及符號轉化為計算機能夠識別的二進制序列的過程。
解碼:把計算機內部存儲的二進制序列轉化為人類能夠認識的文字及符號的過程。
ASCII: 占一個字節,保留最高位,其余7位組成了128個字符的字符集。
unicode: unicode編碼了世界上所有的文字。
utf-8: 對unicode進行了壓縮和優化。ASCII碼中的內容用1個字節保存、歐洲的字符用2個字節保存,東亞的字符用3個字節保存。
GBK: 漢字的國標碼,用2個字節保存。
1. 驗證Py2.x中的字符類型。
Py2.x: #coding:utf-8 s = '中國hello' print s print type(s) print len(s) print repr(s) 執行結果: 中國hello <type 'str'> 11 '\xe4\xb8\xad\xe5\x9b\xbdhello'
可見是str類型,即bytes類型。len()是占用的字節數。
Py2.x: #coding:utf-8 s = u'中國hello' print s print type(s) print len(s) print repr(s) 執行結果: 中國hello <type 'unicode'> 7 u'\u4e2d\u56fdhello'
指定了使用unicode類型。 u4e2d是unicode字符集中字符“中”的代碼。len()是字符的個數。
2. bytes和unicode的轉換。
#coding:utf-8
s = '中國'
print type(s)
print len(s)
s2 = s.decode('utf-8')
type(s2)
print len(s2)
執行結果:
<type 'str'>
6
<type 'unicode'>
23. 不同編碼類型的字符串拼接。
Py2.x: #coding:utf-8 print 'cisco'+u'google' 執行結果: ciscogoogle 之所以英文字符可以把兩種類型的進行拼接,是因為在python2.x中,只要數據全部是 ASCII 的話,python解釋器自動把 byte 轉換為 unicode 。但是一旦一個非 ASCII 字符偷偷進入你的程序,那么默認的解碼將會失效,從而造成 UnicodeDecodeError 的錯誤。python2.x編碼讓程序在處理 ASCII 的時候更加簡單。你付出的代價就是在處理非 ASCII 的時候將會失敗。 Py2.x: #coding:utf-8 s = 'hello'+'china' print s print type(s) print repr(s) 執行結果: hellochina <type 'str'> 'hellochina' 查看不同編碼類型拼接后的存儲類型: Py2.x: #coding:utf-8 s = 'hello'+u'china' print s print type(s) print repr(s) 執行結果: hellochina <type 'unicode'> u'hellochina' 可見Py2.x進行了自動轉換。 Py2.x: #coding:utf-8 print '中國'+'美國' 執行結果: 中國美國 Py2.x: #coding:utf-8 print '中國'+u'美國' 執行結果: Traceback (most recent call last): File "E:\python\study\test\index.py", line 14, in <module> print '中國'+u'美國' UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
Py3.x中即使都是ASCII范圍內,也不能進行拼接:
#coding:utf-8 s1 = 'cisco' print(type(s1)) s2 = b'google' print(type(s2)) print(s1+s2) 執行結果: <class 'str'> <class 'bytes'> Traceback (most recent call last): File "E:\python\study\test\index.py", line 6, in <module> print(s1+s2) TypeError: can only concatenate str (not "bytes") to str
1. 驗證Py3.x中的字符類型。
#coding:utf-8
import json
s1 = '中國'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
執行結果:
<class 'str'>
2
"\u4e2d\u56fd"
中國
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'#coding:utf-8 s = u'中' print(s) print(type(s)) print(len(s)) print(repr(s)) print(ord(s)) print(bin(ord(s))) 中 <class 'str'> 1 '中' 20013 0b100111000101101
2. bytes和unicode的轉換。除了encode和decode的轉換方法,還可以:
#coding:utf-8 s1 = '中國' print(type(s1)) s2 = bytes(s1,encoding='utf-8') print(type(s2)) s3 = str(s2,encoding='utf-8') print(type(s3)) 執行結果: <class 'str'> <class 'bytes'> <class 'str'>
1. py2.x中默認的解碼方式是ASCII, py3.x中默認的是utf-8, 當在py2.x中指定解碼方式為utf-8時,py2.x和py3.x應該是沒有區別,可為何在py2.x中默認的字符類型是bytes, 而在py3.x中確是unicode, 都是utf-8,不應該都是bytes嗎?或者既然都加載在內存了,不該都是unicode嗎?
答:python解釋器從磁盤讀取文件,以unicode編碼方式把整個代碼加載到內存中,然后逐條執行,當識別到字符串時,py2.x默認的str類型是bytes, 而py3.x默認的str類型是unicode, 但當有明確指定字符類型時,按指定的編碼,如py2.x中的u'china', py3.x中的b'google'.
2. Py2.x中不指定utf-8編碼方式時,print漢字會報錯:
Py2.x: s = '中國' print s 結果: File "E:\python\study\test\index.py", line 3 SyntaxError: Non-ASCII character '\xe4' in file E:\python\study\test\index.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
這是因為py2.x中默認的解碼方式為ASCII, 而文件保存的編碼方式為UTF-8, 兩者不匹配,因此報錯。
3. Py2.x中字符串s本來應該是字節類型,但為何print時卻顯示為明文了呢?
Py2.x中: >>> s = '中國' >>> s '\xd6\xd0\xb9\xfa' >>> print s 中國 >>>print '\xd6\xd0\xb9\xfa' 中國
這是因為print在執行時調用了str函數,str函數執行了bytes到unicode的操作。但py3.x中不存在這種現象:
#coding:utf-8
import json
s1 = '中國'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
執行結果:
<class 'str'>
2
"\u4e2d\u56fd"
中國
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'控制臺中: >>> s = '中國' >>> print(type(s)) <class 'str'> >>> s '中國' >>> print(s) 中國 >>> s1 = bytes(s,encoding='gbk') >>> s1 b'\xd6\xd0\xb9\xfa' >>> print(s1) b'\xd6\xd0\xb9\xfa' >>>
4. 以utf-8保存文件,在windows中執行,輸出不同:
#coding:utf-8 s = '中國' print(s) D:\Python37-32>python d:\index.py 中國 D:\Python27>python d:\index.py 涓浗
因為py3.x中字符串被識別為unicode, 傳給cmd.exe時被編碼為GBK,再以GBK解碼輸出。但py2.x中字符串被識別為bytes, utf-8編碼的兩個漢字有6個字節,傳給cmd.exe時按GBK解碼,識別成為了3個亂碼,再以GBK解碼輸出。
5. Py3.x使用open的r方法打開utf-8編碼的文件時會報錯:
#coding:utf-8
f = open('index.py','r')
print(f.read())
執行結果:
Traceback (most recent call last):
File "E:\python\study\test\test.py", line 5, in <module>
print(f.read())
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
使用rb時輸出:
b'\xe4\xb8\xad\xe5\x9b\xbd'py2.x中不會報錯。open()方法打開文件時,read()讀取的是str(py2.x中即是bytes),讀取后需要使用正確的編碼格式進行decode().
Py2.x:
f = open('index.py','r')
s = f.read()
print type(s)
print len(s)
print s
執行結果:
<type 'str'>
6
中國
可見,此處使用utf-8進行解碼,如果指定為GBK呢?
#coding:gbk
f = open('index.py','r')
s = f.read()
print s
輸出是涓浗,改為ASCII后同樣報錯。可查看py3.x使用的是GBK進行解碼:
Py3.x:
>>> f = open('index.py','r')
>>> f
<_io.TextIOWrapper name='index.py' mode='r' encoding='cp936'>
但py2.x沒有顯示編碼方式:
>>> f = open(r'e:\python\study\test\index.py','r')
>>> s = f.read()
>>> f
<open file 'e:\\python\\study\\test\\index.py', mode 'r' at 0x016BD1D8>可使用open('index.py','r',encoding='utf-8')指定編碼方式。
https://www.cnblogs.com/OldJack/p/6658779.html
http://www.cnblogs.com/yuanchenqi/articles/5938733.html
https://www.cnblogs.com/shine-lee/p/4504559.html
https://blog.csdn.net/nyyjs/article/details/56667626
https://blog.csdn.net/nyyjs/article/details/56670080
https://www.jianshu.com/p/19c74e76ee0a
https://www.jb51.net/article/59599.htm
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





