溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么解決分布式session問題”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
session說到 session,我相信每個程序員都不陌生,或多或少在項目中使用過。session 這個詞,其實是一個抽象的概念,它不像 Cookie 那樣有著明確的定義。當大多數程序員談論 session 的時候,可能指的是服務端存儲數據的 session 對象,例如,用戶登錄成功之后把用戶信息存儲在 session 中,類似于這樣的程序。
Session["UserName"] = new User(); public class User{ public int UserId {get ;set ;} public string UserName {get ;set;} }而在計算機中,尤其是網絡應用中,session 被定義為“會話”,可以把它看做客戶端和服務端的一條通道連接,同一個用戶的請求使用同一個 session 會話。在大多數應用中,主要用于用戶的識別,通俗來講,服務端可以通過 session 來記錄每一個用戶的狀態信息。那我們就以最常用的服務端 session 對象來啰嗦幾句
單機 session
session 是存儲在服務端的,這是一個很重要的概念。這意味著它需要占用服務器的內存,并且它需要一種釋放的機制來保證服務器內存不會被撐爆(例如 LRU)。
在項目初期,為了快速上線,服務器的部署很多情況下只有一臺服務器,記錄用戶的登錄狀態普遍使用 session 機制。請不要說這樣做不合理,至少在項目初期這種做法是最簡單而且最快速的方案。隨著項目的不斷迭代升級,用戶量的不斷增加,你會發現單機系統成為了項目的最大性能瓶頸,這個時候多數架構師會選擇水平擴展方案。
其實說到底,系統性能的提升都圍繞著一個“分”字,無論是數據庫的分庫分表,還是現在興起的微服務,始終在圍繞著一個領域進行切分
當單機的 session 機制進行水平擴展就面臨著必須要要解決的問題:session 的親和性(粘性)要怎么樣去解決?
分布式 session
一個單機系統擴展為一個分布式系統,就會面臨著分布式 CAP 理論中 AP 和 CP 的選擇
談到分布式 session 的一致性問題,其實主要是要解決用戶 session 的親和性,同一個用戶的請求怎么樣才能保證到達正確存儲 session 信息的服務器呢?
session 復制
最初的方案是采用 session 復制方案,整體的流程非常簡單:假設現在有三臺服務器,當一個 session 在其中一臺服務器上被創建,則同時把這個 session 復制到其他兩臺服務器上。這樣當用戶的請求無論到達哪臺服務器,都會有相應的 session 數據。
這種方案的優勢在于服務器可以任意水平擴展,每個服務器都保留著所有的 session 信息,當加入一臺服務器只需要把所有的 session 信息復制過去即可。但是劣勢更加明顯
每個服務器上都保存著全部的 session 信息,服務器占用的資源大大增加。
session 同步需要占用網絡帶寬,最重要的是如果采用的異步復制方式,數據會有短暫性的不一致,可能會導致用戶訪問失敗。
session 復制的方案現在已經很少有人使用了
負載均衡方案
當一臺服務器擴展為多臺服務器,目前最常用的方案是在流量的入口添加負載均衡器,大體的部署圖是這樣的
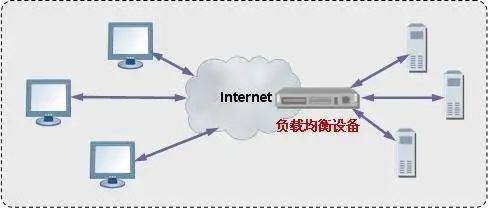
image
如果負載均衡器能夠利用某種手段來實現 session 的粘性就能實現分布式 session。目前主流的 nginx 可以根據“hash_ip”算法將同一個 IP 的請求固定到某臺服務器,這樣來自于同一個 ip 的 session 請求總是請求到同樣的服務器。
這種方式比 session 同步方式要好很多,每臺服務器只存儲對應的 session 數據,這大大節省了內存資源,而且服務器之間沒有數據同步過程。當有新服務器加入的時候,只需要修改負載均衡器的配置即可,這樣很方便就支持了服務器水平擴展。但是,同時也面臨著一些不足
服務器重啟意味著對應的 session 信息丟失,這在一些重要的業務場景中是不允許的
服務器的水平擴展需要修改負載均衡器的配置,修改之后可能會導致之前的 session 重新分布,這樣會導致一部分用戶路由不到正確的 session
session 剝離
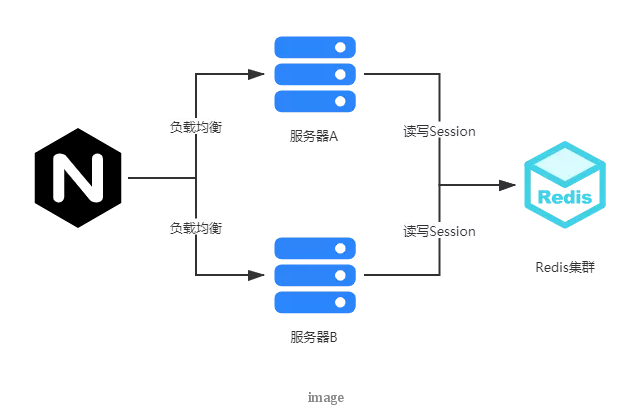
現在應用更廣泛的分布式 session 技術是把 session 數據徹底從業務服務器中剝離,單獨存儲在其他外部設備中,而這些外部設備可以采用主備或者主從,甚至集群的模式來達到高可用。比如現在最常用的方案是把 session 數據存儲在 redis 中,雖然從 redis 讀寫 session 數據需要花費一定的網絡耗時,但是對于一般的應用來說在可以接受范圍之內。
這種方案好處是整體架構更加清晰,也更加靈活,應用的服務器整體擴展能力再也不用考慮 session 的影響,而 session 的問題被轉移到外部設備,通常可以利用內存性 NOSql 來解決性能問題,而這些外部設備一般都會有對應的分布式集群方案,例如 redis,可以利用主從或者哨兵模式甚至集群來提供更大規模的數據支撐能力。
Actor 模型
Actor 模型解決這種用戶粘性問題會更加優雅,它天生就自帶了對象識別功能,簡單來說,同一個 key 的請求,總能到達正確的 actor 實例,這不是我們想要的結果嗎?而且 actor 模型下不用加鎖就能處理并發問題,為什么沒人用呢?而且采用 acotr 模型就可以利用進程內緩存的形式,比請求局域網 redis 的網絡延遲要低很多。
“怎么解決分布式session問題”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





