溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么編寫Python代碼讓數據處理快4倍”,在日常操作中,相信很多人在怎么編寫Python代碼讓數據處理快4倍問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么編寫Python代碼讓數據處理快4倍”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
比方說:
我們有一個全是圖像數據的文件夾,想用Python為每張圖像創建縮略圖。
下面是一個短暫的腳本:
用Python的內置glob函數獲取文件夾中所有JPEG圖像的列表,
然后用Pillow圖像處理庫為每張圖像保存大小為128像素的縮略圖:
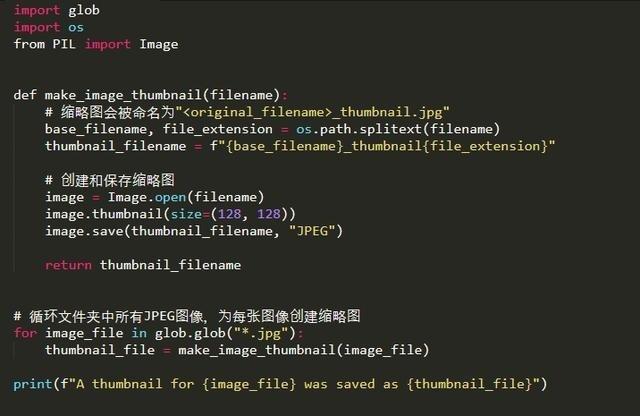
這段腳本沿用了一個簡單的模式
你會在數據處理腳本中經常見到這種方法:
首先獲得你想處理的文件(或其它數據)的列表
寫一個輔助函數,能夠處理上述文件的單個數據
使用for循環調用輔助函數,處理每一個單個數據,一次一個。
咱們用一個包含1000張JPEG圖像的文件夾測試一下這段腳本,
看看運行完要花多長時間:

運行程序花了8.9秒,但是電腦的真實工作強度怎樣呢?
我們再運行一遍程序
看看程序運行時的活動監視器情況:

電腦有75%的處理資源處于閑置狀態!這是什么情況?
這個問題的原因就是我的電腦有4個CPU,但Python只使用了一個。
所以程序只是卯足了勁用其中一個CPU,另外3個卻無所事事。
因此我需要一種方法能將工作量分成4個我能并行處理的單獨部分。
幸運的是,Python中有個方法很容易能讓我們做到!
下面是一種可以讓我們并行處理數據的方法:
將JPEG文件劃分為4小塊。運行Python解釋器的4個單獨實例。
讓每個Python實例處理這4塊數據中的一塊。
將這4部分的處理結果合并,獲得結果的最終列表。
4個Python拷貝程序在4個單獨的CPU上運行,
處理的工作量應該能比一個CPU大約高出4倍,
對吧?
最妙的是,Python已經替我們做完了最麻煩的那部分工作。
我們只需告訴它想運行哪個函數以及使用多少實例就行了,剩下的工作它會完成。
整個過程我們只需要改動3行代碼。
首先
我們需要導入concurrent.futures庫
這個庫就內置在Python中:

接著,我們需要告訴Python啟動4個額外的Python實例。
我們通過讓Python創建一個Process Pool來完成這一步:

默認情況下:
它會為你電腦上的每個CPU創建一個Python進程,
所以如果你有4個CPU,就會啟動4個Python進程。
***一步:
讓創建的Process Pool用這4個進程在數據列表上執行我們的輔助函數。
完成這一步,我們要將已有的for循環:

替換為新的調用executor.map():
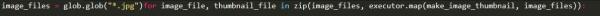
該executor.map()函數調用時需要輸入輔助函數和待處理的數據列表。
這個函數能幫我完成所有麻煩的工作
包括將列表分為多個子列表、將子列表發送到每個子進程、運行子進程以及合并結果等。
干得漂亮!
這也能為我們返回每個函數調用的結果。
Executor.map()函數會按照和輸入數據相同的順序返回結果。
所以我用了Python的zip()函數作為捷徑,一步獲取原始文件名和每一步中的匹配結果。
這里是經過這三步改動后的程序代碼:
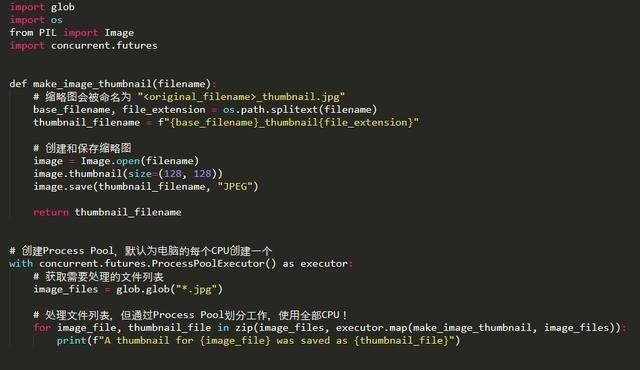
我們來運行一下這段腳本
看看它是否以更快的速度完成數據處理:

腳本在2.2秒就處理完了數據!比原來的版本提速4倍!
之所以能更快的處理數據
是因為我們使用了4個CPU而不是1個。
但是
如果你仔細看看,會發現“用戶”時間幾乎為9秒。
那為何程序處理時間為2.2秒,但不知怎么搞得運行時間還是9秒?
這似乎不太可能啊?
這是
因為“用戶”時間是所有CPU時間的總和,
我們最終完成工作的CPU時間總和一樣,都是9秒,
但我們使用4個CPU完成的,實際處理數據時間只有2.2秒!
注意:
啟用更多Python進程以及給子進程分配數據都會占用時間,因此靠這個方法并不能保證總是能大幅提高速度。
如果你有一列數據
并且每個數據都能單獨處理時,使用我們這里所說的Process Pools是一個提速的好方法。
下面是一些適合使用并行處理的例子:
從一系列單獨的網頁服務器日志里抓取統計數據。
從一堆XML,CSV和JSON文件中解析數據。
對大量圖片數據做預處理,建立機器學習數據集。
但也要記住,Process Pools并不是***的。
使用Process Pool需要在獨立的Python處理進程之間來回傳遞數據。
如果你要處理的數據不能在處理過程中被有效地傳遞,這種方法就行不通了。
簡而言之,你處理的數據必須是Python知道怎么應對的類型。
同時
也無法按照一個預想的順序處理數據。
如果你需要前一步的處理結果來進行下一步,這種方法也行不通。
那GIL的問題呢?
你可能知道Python有個叫全局解釋器鎖(Global Interpreter Lock)的東西,即GIL。
這意味著即使你的程序是多線程的,每個線程也只能執行一個Python指令。
GIL確保任何時候都只有一個Python線程執行。
換句話說:
多線程的Python代碼并不能真正地并行運行,從而無法充分利用多核CPU。
但是Process Pool能解決這個問題!
因為我們是運行單獨的Python實例,每個實例都有自己的GIL。
這樣我們獲得是真正能并行處理的Python代碼!
到此,關于“怎么編寫Python代碼讓數據處理快4倍”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





